+
+```
+
+### 2. Initialization script (Init notebook)
+
+Deepnote provides an optional feature to run custom Python initialization code every time your project hardware boots up. To utilize this capability, you will need to **include an 'Init' notebook** in your project.
+
+To create an 'Init' notebook:
+
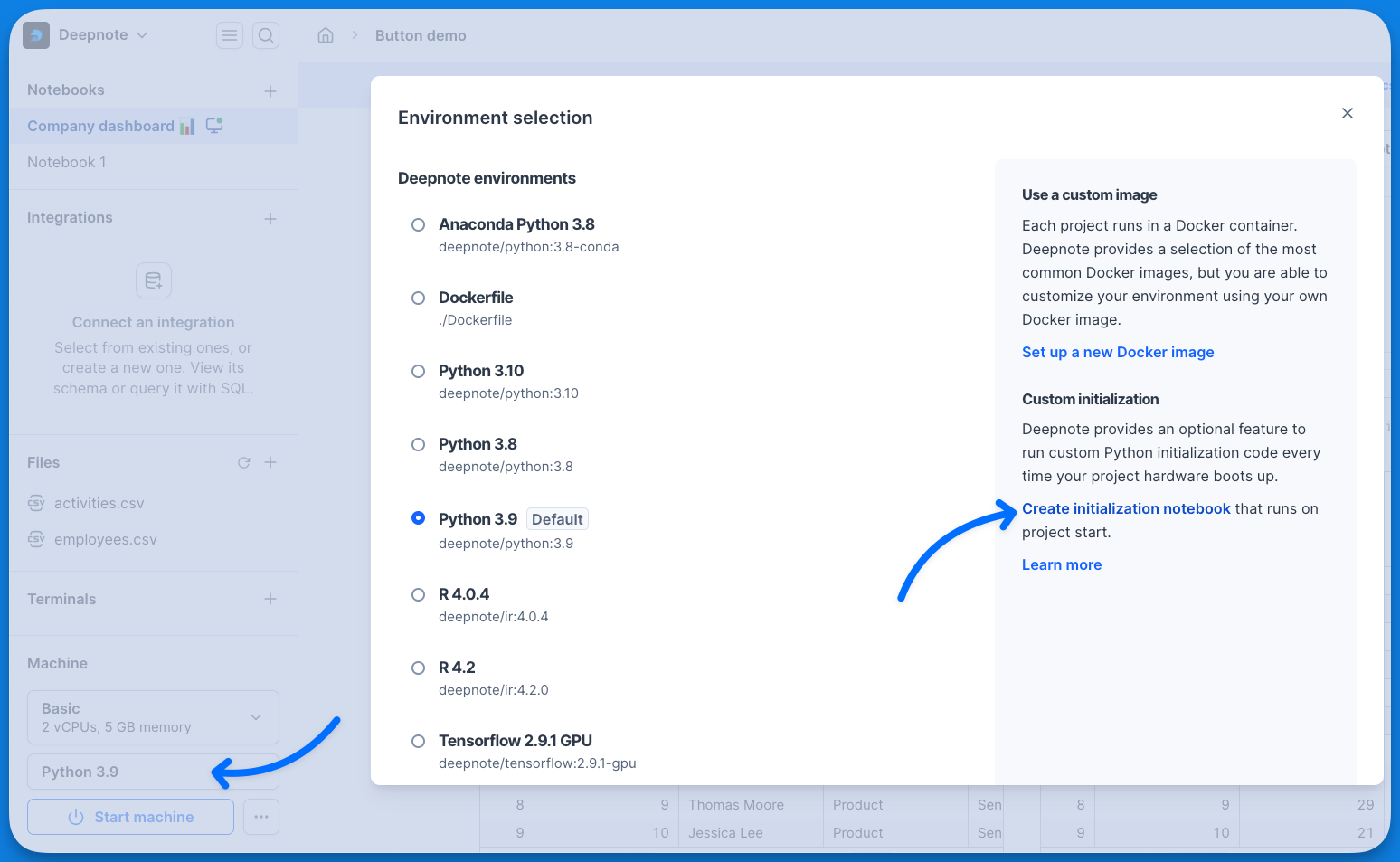
+Navigate to your project's **Machine** section in the project sidebar.
+
+- Click on the environment selection menu.
+- Click on the **Create initialization notebook** button.
+
+
+
+After creating it, the 'Init' notebook will be conveniently located at the top of your Notebook list. The contents of this notebook will automatically execute each time your project starts up, providing an ideal place to set up your preferred environment.
+
+By default, the 'Init' notebook installs any packages listed in **./requirements.txt**. However, you are free to customize this according to your project's needs.
+
+For a more detailed explanation of project initialization, follow this [link](https://deepnote.com/docs/project-initialization).
+
+### 3. Environments
+
+Deepnote environments are customizable runtime configurations powered by **Docker images**. Each environment defines the complete stack - from the Linux operating system to Python packages and binary dependencies.
+
+While Deepnote provides several pre-configured environments for common use cases, you can also create your own custom environment using any Docker image, giving you full control over your runtime setup.
+
+Read more about [default](https://deepnote.com/docs/default-environment) and [custom](https://deepnote.com/docs/custom-environment) environments.
diff --git a/docs/integrations.md b/docs/integrations.md
new file mode 100644
index 0000000000..781ede616a
--- /dev/null
+++ b/docs/integrations.md
@@ -0,0 +1,90 @@
+---
+title: Integrations
+description: Deepnote + your data stack = 💙
+noIndex: false
+noContent: false
+---
+
+Deepnote natively integrates with a substantial collection of databases, data warehouses, and other services. All integrations are plug-and-play, meaning they can be connected to any project in the workspace they were created in on an as-needed basis (click [here](/docs/team-permissions) to read more about integration permissions).
+
+Once created, integrations greatly simplify using Deepnote in conjunction with other tools in your data stack through, for instance, custom [SQL blocks](/docs/sql-cells). On top of all of that, Deepnote also takes care of credential management for you by encrypting and securely storing all integration-related credentials.
+
+### Supported integrations
+
+
+Missing an integration? [Let us know through Deepnote's Product Portal!](https://portal.productboard.com/deepnote/1-deepnote-product-portal/tabs/1-under-consideration/submit-idea)
+
+
+Learn more about any of Deepnote's currently supported integrations by selecting a specific integration from the left-hand sidebar or browsing integrations by category and jumping into a detailed walkthrough of connecting and using integrations.
+
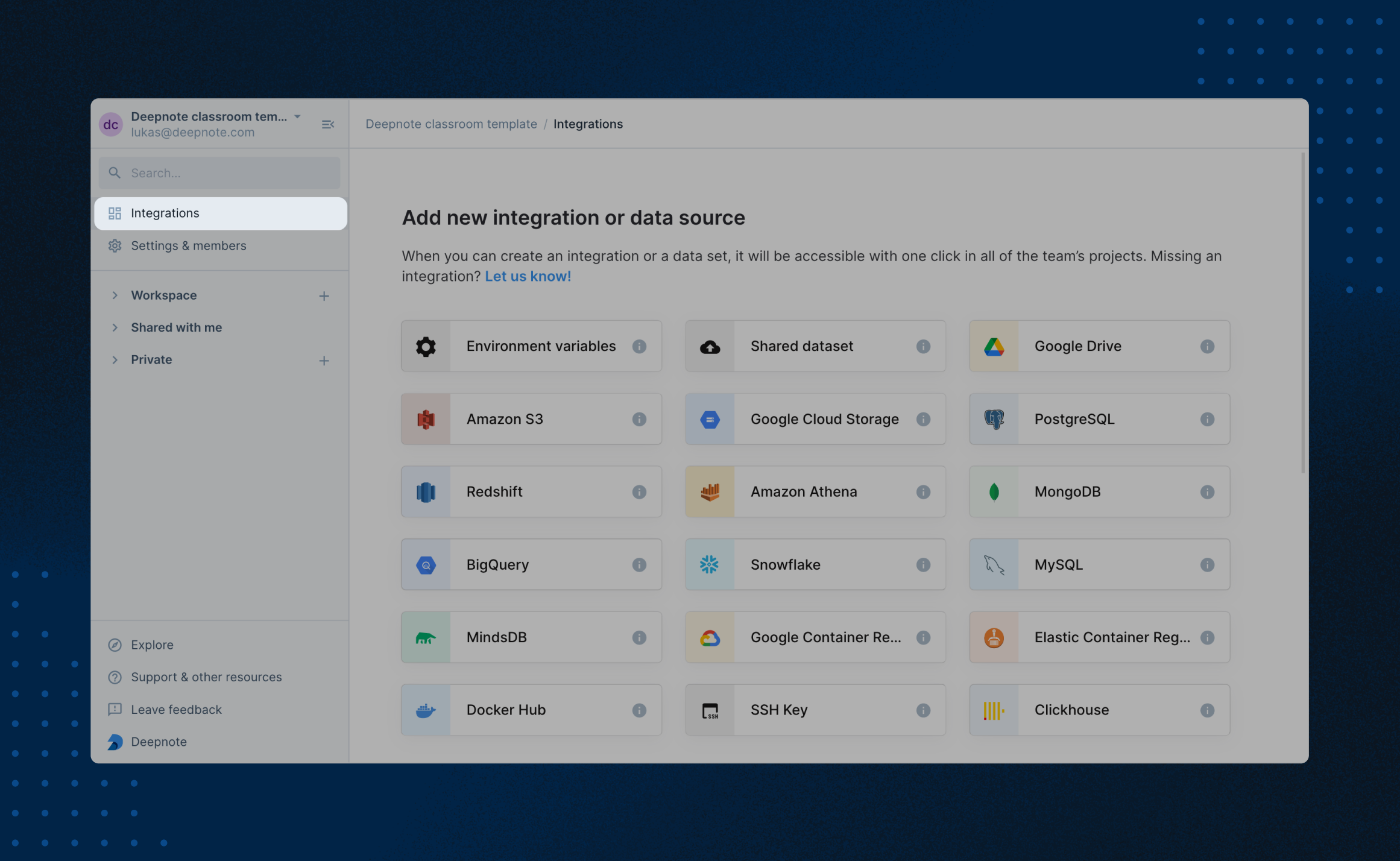
+### Creating & managing integrations
+
+To edit your existing integrations (and create new ones), open up the integrations overview from the left-hand sidebar. Alternatively, you can also find your way to the integrations overview via the integrations menu in the right-hand sidebar within each project.
+
+
+
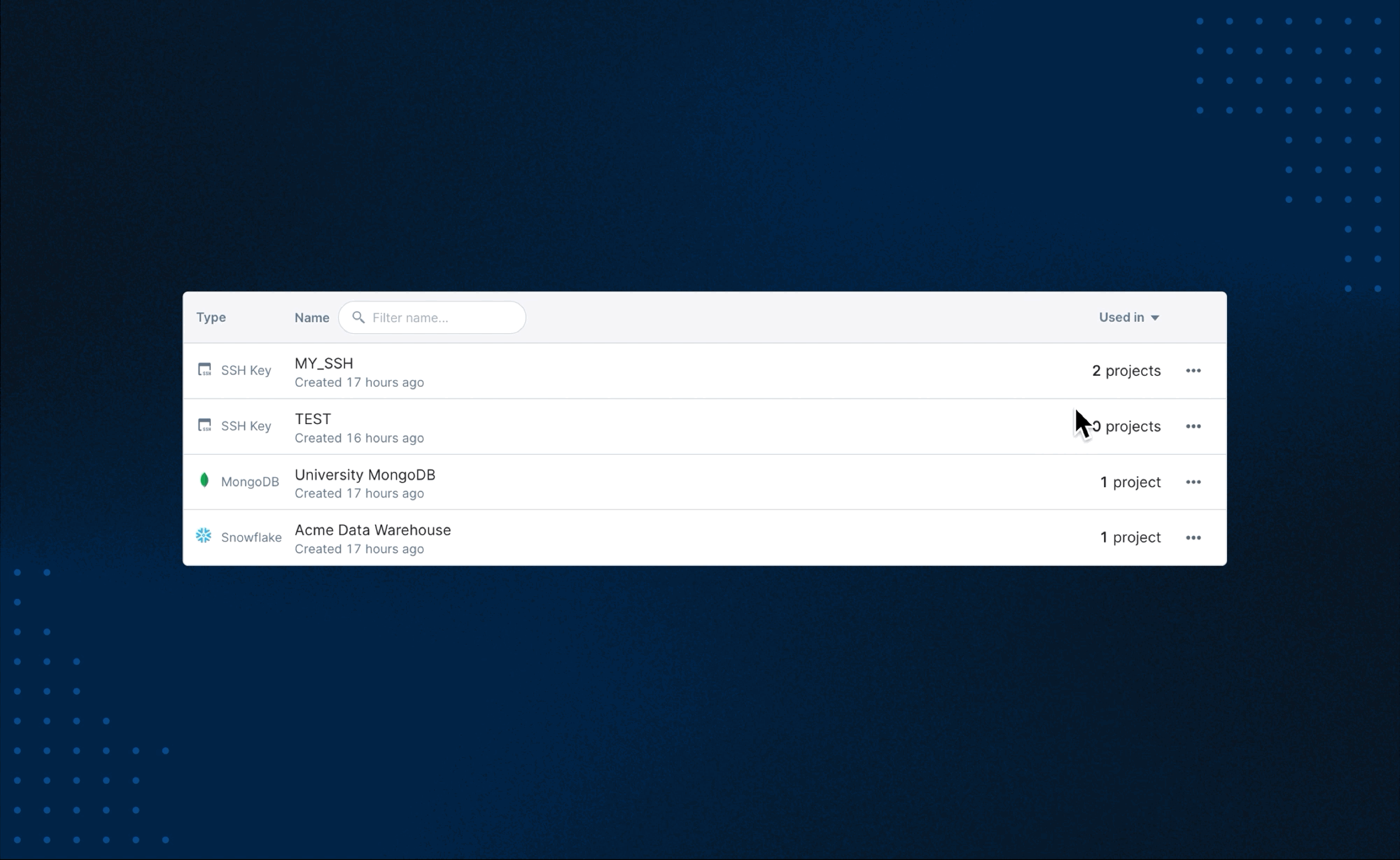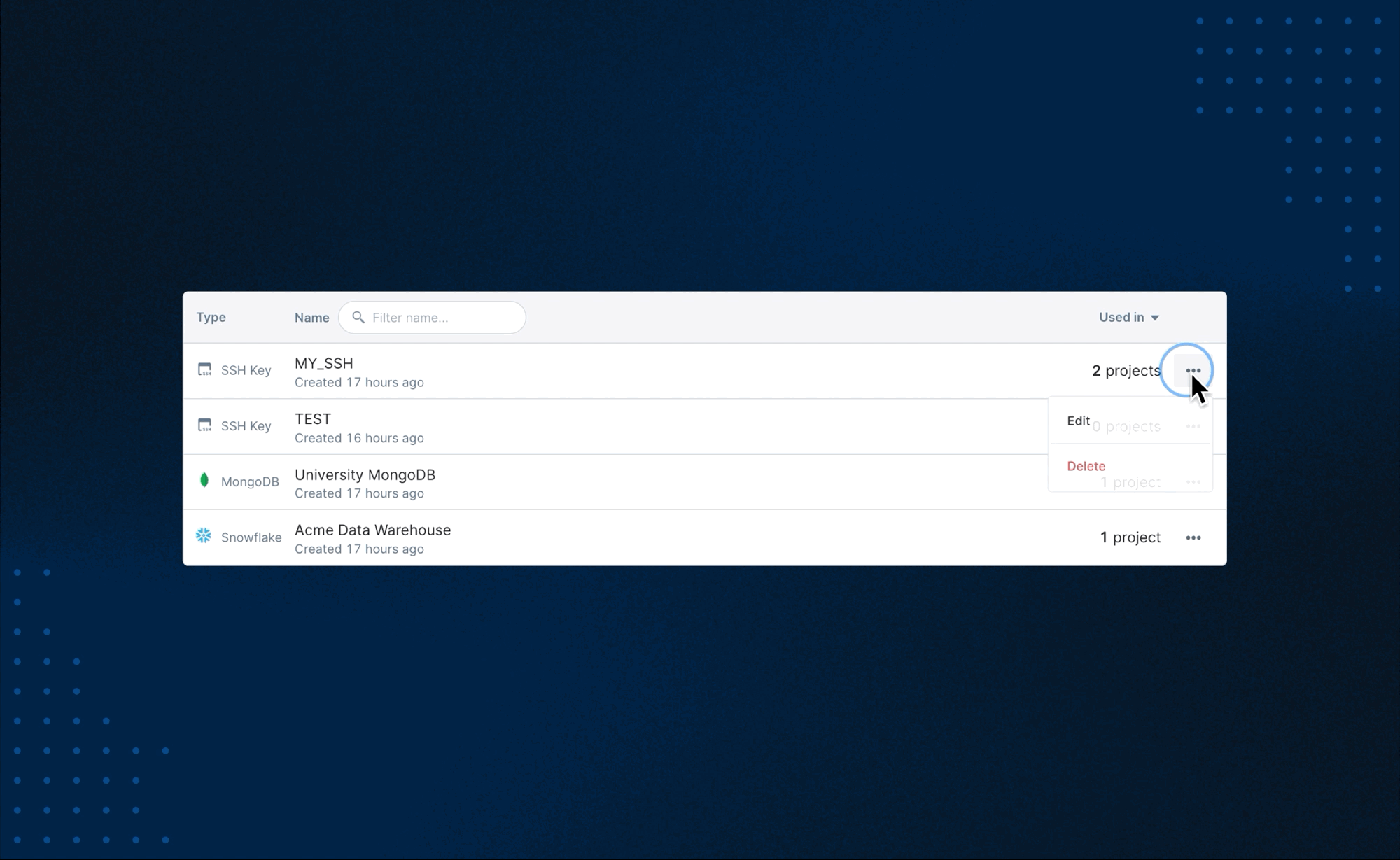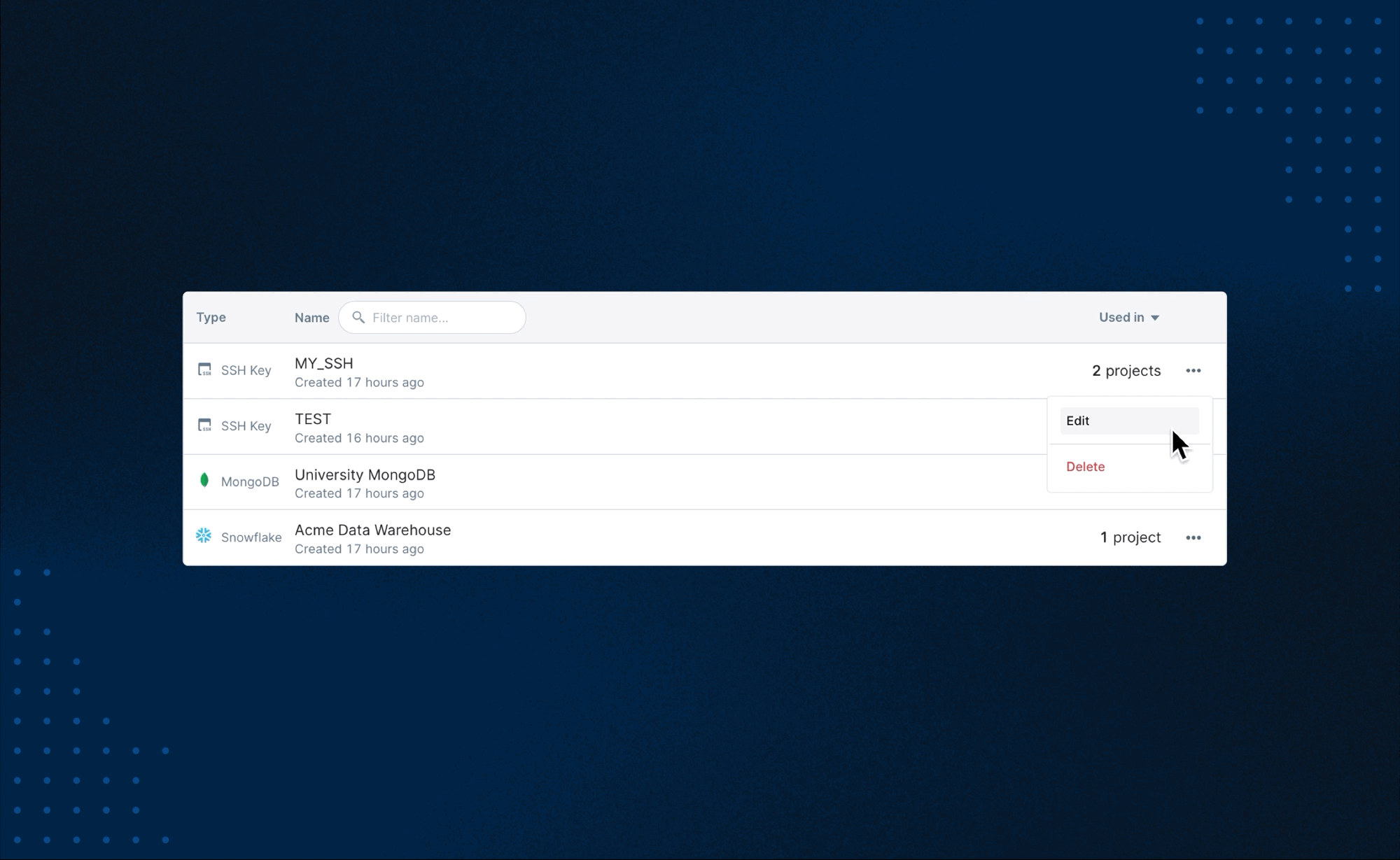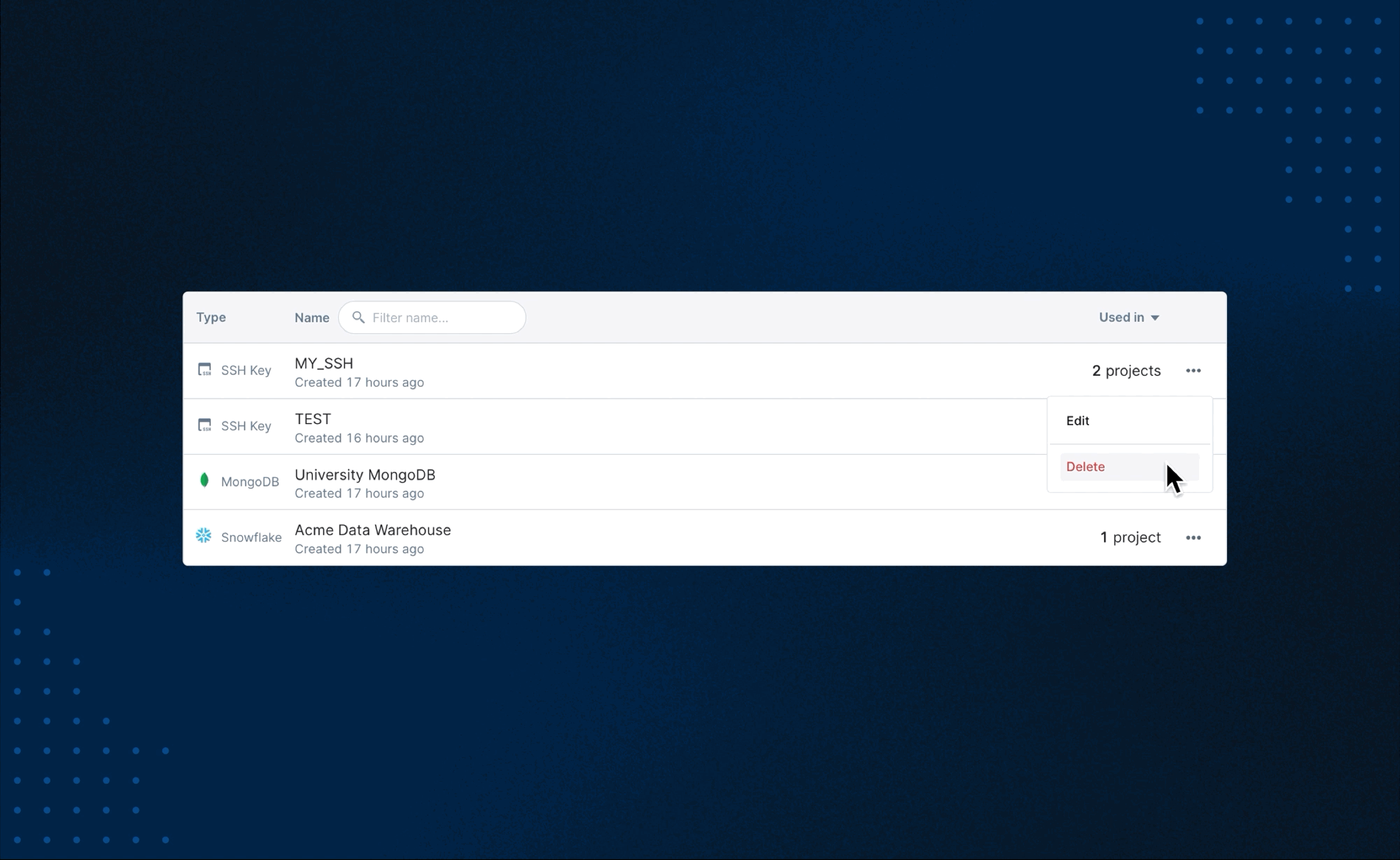
+As mentioned above, each integration can be connected to multiple projects within your workspace. It is important to remember that deleting an integration that is connected to multiple projects will remove the specified integration from all projects in that workspace.
+
+
+
+
+Some integrations require your machine to restart (don't fret, you will be warned in advance). Note that this will terminate all running processes in the project.
+
+
+To keep an integration available in your workspace and only remove it from a specific project, open up the right-hand sidebar and edit the integration in question in the integrations menu.
+
+### Integrations & collaboration
+
+Integrations are shared amongst all team members and can be connected to any of the projects in the workspace.
+
+### Integrations by category
+
+Explore integrations by category and dive deeper into any of the listed integrations.
+
+#### Databases
+
+- [PostgreSQL](/docs/postgresql)
+- [MySQL](/docs/mysql)
+- [MariaDB](/docs/mysql)
+- [MongoDB](/docs/mongodb)
+- [MindsDB](/docs/mindsdb)
+- [Supabase](/docs/supabase)
+- [ClickHouse](/docs/clickhouse)
+- [SQL Server (Azure SQL)](/docs/sql-server)
+
+#### Data warehouses
+
+- [AWS Redshift](/docs/redshift)
+- [Google BigQuery](/docs/google-bigquery)
+- [Snowflake](/docs/snowflake/)
+
+#### Object storage & querying services
+
+- [Amazon S3](/docs/amazon-s3)
+- [Amazon Athena](/docs/amazon-athena)
+- [Google Cloud Storage](/docs/google-cloud-storage)
+
+#### Drive storage services
+
+- [Google Drive](/docs/google-drive)
+- [Dropbox](/docs/dropbox)
+
+#### Container registries
+
+- [Amazon Elastic Container Registry](/docs/amazon-ecr)
+- [Google Container Registry](/docs/google-container-registry)
+- [DockerHub](/docs/docker-hub)
+
+#### Version control
+
+- [GitHub](/docs/github)
+
+#### Deepnote utilities
+
+- [Environment variables](/docs/environment-variables)
+- [Shared datasets for large files](/docs/deepnote-shared-datasets)
+- [SSH keys](/docs/ssh-key)
+
+### Next steps
+
+Jump right into Deepnote and [take a look at SQL blocks and MindsDB in action.](https://deepnote.com/workspace/Deepnote-Templates-71742312-24f2-4c10-9bf7-786d17280b92/project/Machine-Learning-With-SQL-c626fd30-cb3f-4eae-ac70-c9c4a4f626eb/%2Fmindsdb_demo.ipynb) You can also save yourself some setup work by hitting the `Duplicate` button in the top-right corner to start exploring on your own!
diff --git a/docs/intellectual-property.md b/docs/intellectual-property.md
new file mode 100644
index 0000000000..621e45b550
--- /dev/null
+++ b/docs/intellectual-property.md
@@ -0,0 +1,9 @@
+---
+title: Intellectual property
+noIndex: false
+noContent: false
+---
+
+The code you write on Deepnote is yours and Deepnote does not make any ownership claims. If you make your project public (either by sharing it with friends or by making it accessible by link), the people you share with will be able to access your project and see your code. It is your responsibility to make sure this is ok.
+
+If you are making the project public and sharing the link to it on some online platform (eg. a blog), we recommend you to include a LICENSE file to mitigate any possible disputes.
diff --git a/docs/ipywidgets-in-deepnote.md b/docs/ipywidgets-in-deepnote.md
new file mode 100644
index 0000000000..8c689c6f9a
--- /dev/null
+++ b/docs/ipywidgets-in-deepnote.md
@@ -0,0 +1,61 @@
+---
+title: IPyWidgets in Deepnote
+description: We do not support IPywidgets but we offer native alternatives like built-in input blocks for enhanced interactivity in data science notebooks and apps.
+noIndex: false
+noContent: false
+---
+
+Deepnote is a cloud-based data platform that transforms how data teams work together. Built for modern data science workflows, it combines the power of Jupyter notebooks with enterprise-grade collaboration features in a secure environment.
+
+A common tool many data scientists use is **IPywidget,** [an interactive widget library](https://ipywidgets.readthedocs.io/en/8.1.2/) that allows users to build rich, interactive GUIs in Jupyter notebooks. However, IPywidgets are not supported in Deepnote, and here is why, what alternatives you can use to enhance your productivity
+
+## Why IPywidgets are not supported in Deepnote
+
+The primary reason Deepnote doesn't support IPywidgets is security. The platform had to disable IPywidgets functionality due to potential security vulnerabilities that could arise from executing arbitrary JavaScript code in notebooks.
+
+## Alternatives to IPywidgets in Deepnote
+
+While IPywidgets provide an interactive experience, Deepnote offers **native features** and **visualization options** that can achieve the same goals but in a more streamlined manner. Below are some of the ways you can add interactivity and visualization to your Deepnote notebooks:
+
+### **Interactive charts and visualizations**
+
+Deepnote natively supports interactive libraries like **Plotly**, **Altair**, **Seaborn**, and **Matplotlib**, which allow for the creation of dynamic and interactive charts directly in notebooks. These libraries are lightweight and integrate seamlessly with Deepnote’s interface.
+
+- **Plotly** provides powerful charting tools that allow you to zoom, pan, and hover over data points for additional insights.
+- **Altair** is another declarative visualization library that automatically renders interactive charts with minimal code.
+- **Matplotlib** and **Seaborn** can be used for static charts, but with a bit of customization, you can add basic interactive elements.
+
+### **Deepnote's built-in blocks**
+
+Deepnote has its **blocks**(chart blocks, big numbers, input bloks and more) for interactivity, such as sliders, input boxes, and dropdowns, that can be added to notebooks. These blocks allow you to dynamically control parameters and variables without writing complex code, making them simpler alternatives to IPywidgets.
+
+**Example: Adding a slider to control variables**
+
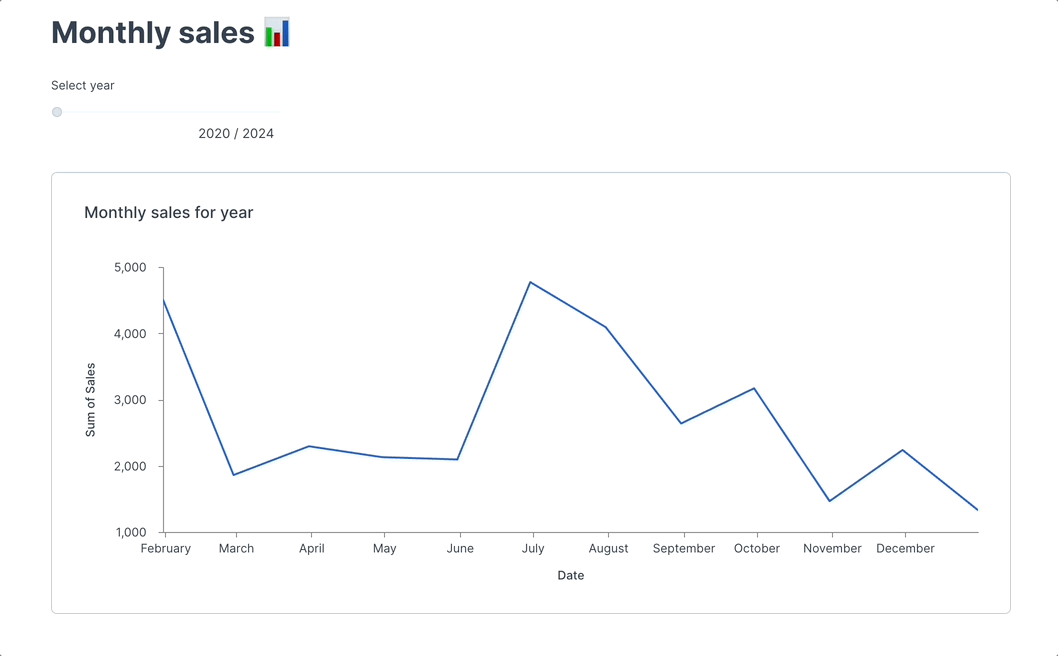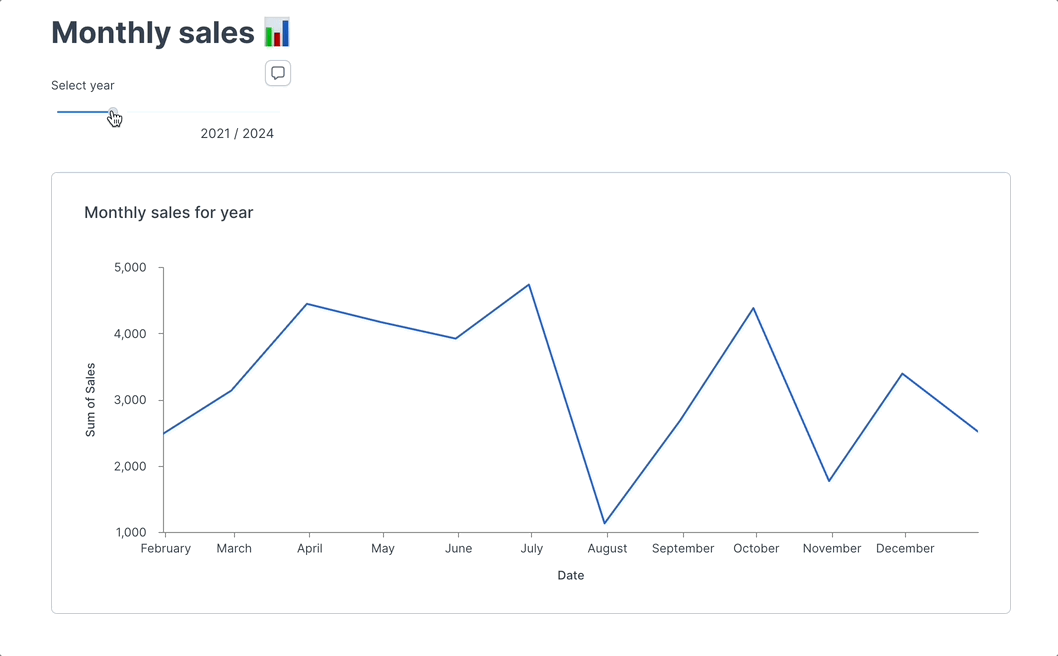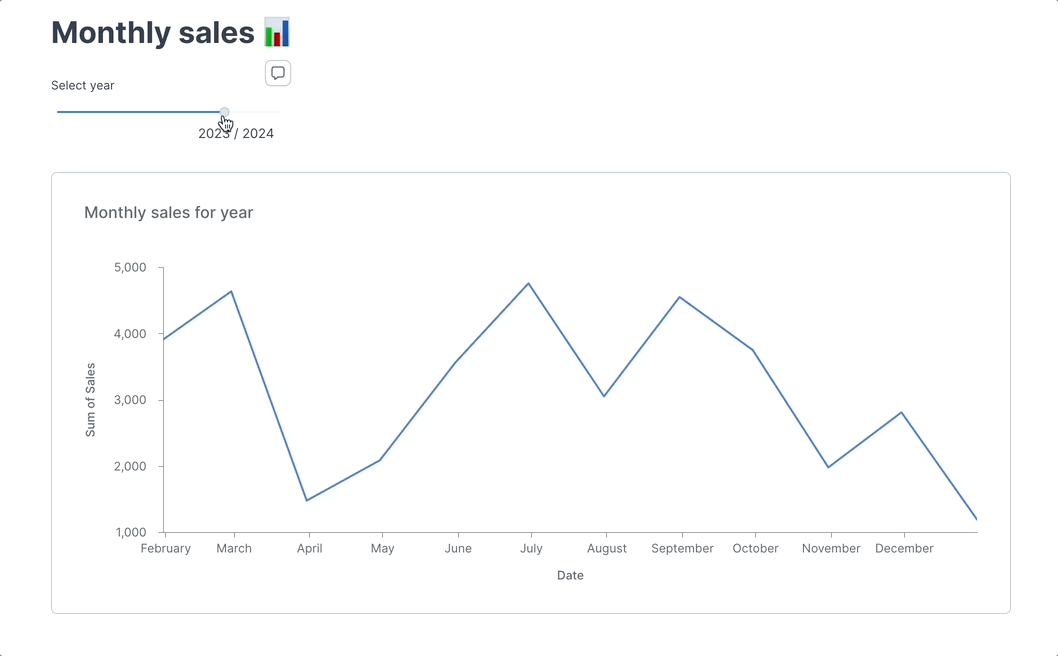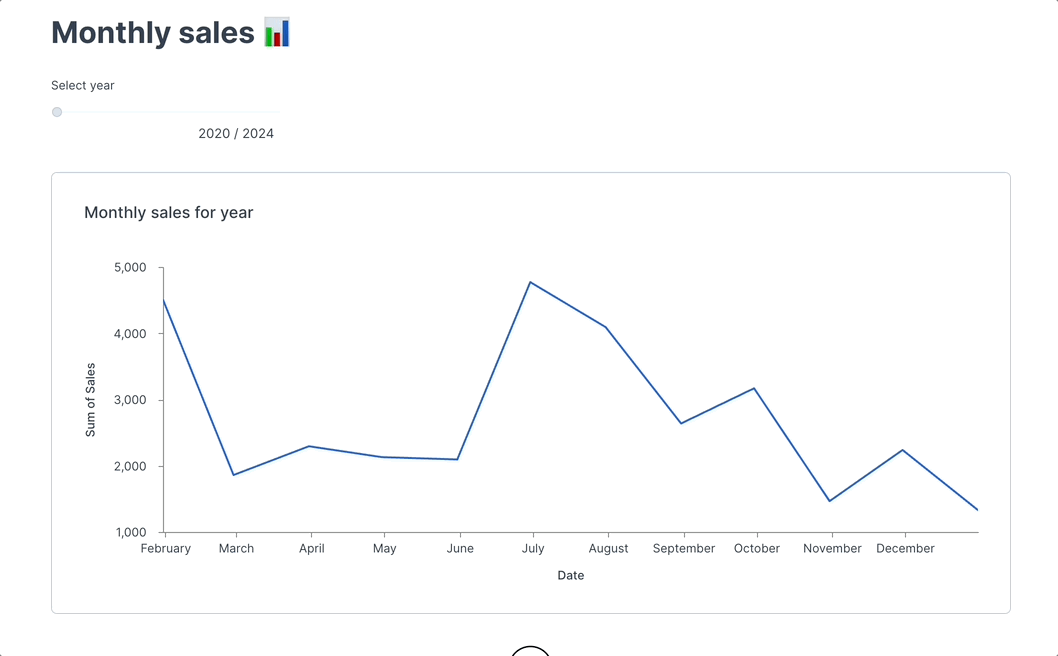
+Instead of using IPywidgets, you can add a native Deepnote slider to your notebook, which can adjust your data visualization dynamically.
+
+
+In Deepnote, you can insert a **slider input block** next to the code blocks and use that to control elements like the frequency of the sine wave or the range of the x-axis, checkout [app with example](https://deepnote.com/app/deepnote/Slider-example-adb7a9d5-5f07-44a2-9364-8b34714521ba?utm_source=app-settings&utm_medium=product-shared-content&utm_campaign=data-app&utm_content=adb7a9d5-5f07-44a2-9364-8b34714521ba).
+
+### **Parameterize notebook with Deepnote input blocks**
+
+Deepnote’s blocks parameters feature is a powerful way to create reusable and interactive notebooks without needing external libraries like IPywidgets. You can make a parameterised notebook that accepts different inputs to change the analysis or visualization dynamically.
+
+For example, by using dropdowns or text inputs, you can parameterize blocks to automatically update based on user selections.
+
+### **Native forms for collaboration**
+
+For data science teams collaborating in Deepnote, the platform allows users to build **forms** with inputs such as text boxes, sliders, and dropdowns, providing an easy way to make a notebook interactive for both technical and non-technical users. This is particularly useful for teams who may not want to dig into the code but still need to tweak parameters or adjust analyses.
+
+### **Deepnote’s text blocks**
+
+Text blocks in Deepnote allow you to embed **interactive tables, links, and visualizations** directly in your notebooks, making it easy to share your work with stakeholders. While Markdown isn't an exact replacement for IPywidgets, it does provide a clean, simple way to present interactive content without adding code-heavy widgets.
+
+### **Output blocks**
+
+Deepnote notebooks support **dynamic blocks outputs**, which allow you to show or hide certain results or outputs based on block execution. This can be used to create a pseudo-interactive environment similar to what you might achieve with IPywidgets.
+
+While IPywidgets are a popular tool for adding interactivity to Jupyter notebooks, Deepnote decided to do it differently with focus on simplicity, performance, and collaboration. Deepnote provides several powerful alternatives that allow you to build interactive and engaging notebooks and apps without needing to rely on third-party widget libraries.
+
+Whether you are building interactive charts with Plotly or creating parameterized blocks Deepnote ensures that you can add interactivity and dynamic content without sacrificing performance or ease of use.
+
+By exploring Deepnote's built-in tools, you’ll find that you can achieve all the interactivity you need—without the complexity of IPywidgets!
diff --git a/docs/jax-vs-pytorch.md b/docs/jax-vs-pytorch.md
new file mode 100644
index 0000000000..fc4c5c2a1b
--- /dev/null
+++ b/docs/jax-vs-pytorch.md
@@ -0,0 +1,48 @@
+---
+title: JAX vs. PyTorch
+noIndex: false
+noContent: false
+---
+
+# JAX vs. PyTorch
+
+The JAX vs. PyTorch is compared in this article - their performance, and the ideal use cases, helping to choose the best framework for machine learning projects.
+
+Specialized libraries make it easier to build complex models by handling the tough math and speeding up data processing with GPU power. Supported by vibrant communities, libraries like JAX and PyTorch bring people together, making it simple to experiment, collaborate, and drive AI forward.
+
+## PyTorch
+
+PyTorch is an open-source platform developed by Facebook's AI Research lab, famous for its user-friendly interface and powerful capabilities, making it ideal for researchers and developers. Users can create and modify neural networks in real-time thanks to its adaptable computation graph, which facilitates rapid experimentation and streamlines the debugging procedure.
+
+The library focuses on performance by using GPU-accelerated performance and a wide array of tools, making it a go-to choice for areas like computer vision and natural language processing. PyTorch's dynamic computation graphs enable making changes to neural network architectures in real-time, it's highly beneficial for research as it allows for rapid improvements in model performance, particularly in natural language processing and computer vision tasks.
+
+### Ideal use cases:
+
+- **Research and development:** Quick creation of cutting-edge algorithms through rapid prototyping.
+- **Computer vision:** Sophisticated image processing applications enabled by libraries such as torchvision.
+- **Natural language processing:** Effective management of ordered information for tasks such as sentiment analysis.
+
+### Example:
+
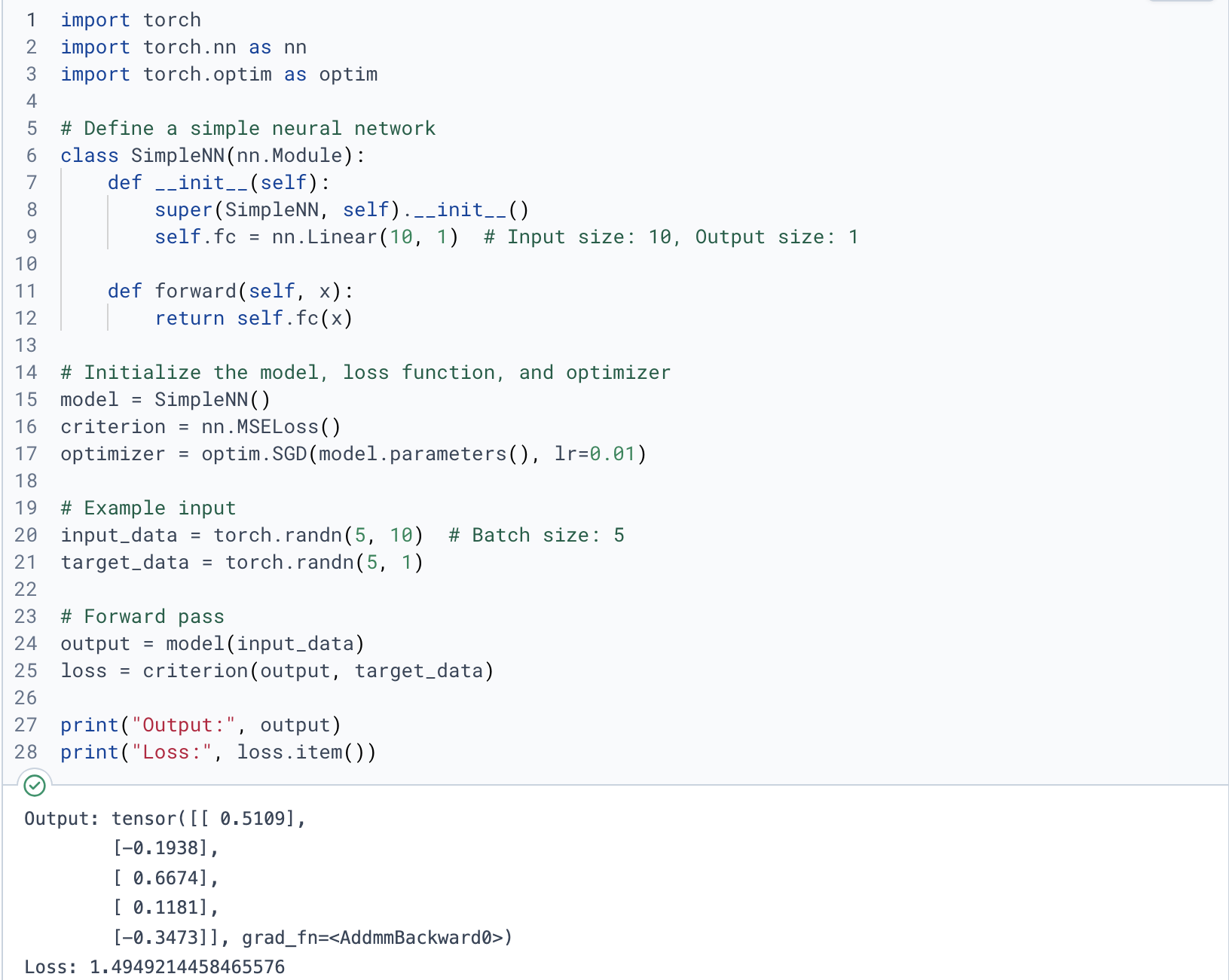
+This example shows how to build a simple neural network in PyTorch, using a fully connected layer to transform input data of size 10 to an output of size 1. A forward pass on random data calculates the mean squared error loss against target data.
+
+
+## JAX
+
+JAX is a open-source library created by Google that makes high-speed numerical computing and machine learning more accessible. It focuses on automatic differentiation and composability, allowing developers to build complex models easily. With its ability to work smoothly with NumPy and take advantage of GPUs and TPUs, JAX boosts performance during model training and inference.
+
+
+### Ideal use cases:
+
+- **Scientific research:** Speeding up simulations and model development in areas such as physics and biology.
+
+- **Machine learning:** Applying state-of-the-art algorithms with effective automatic differentiation.
+
+- **High-performance computing:** Utilizing JAX for complex computations that require enhanced performance.
+
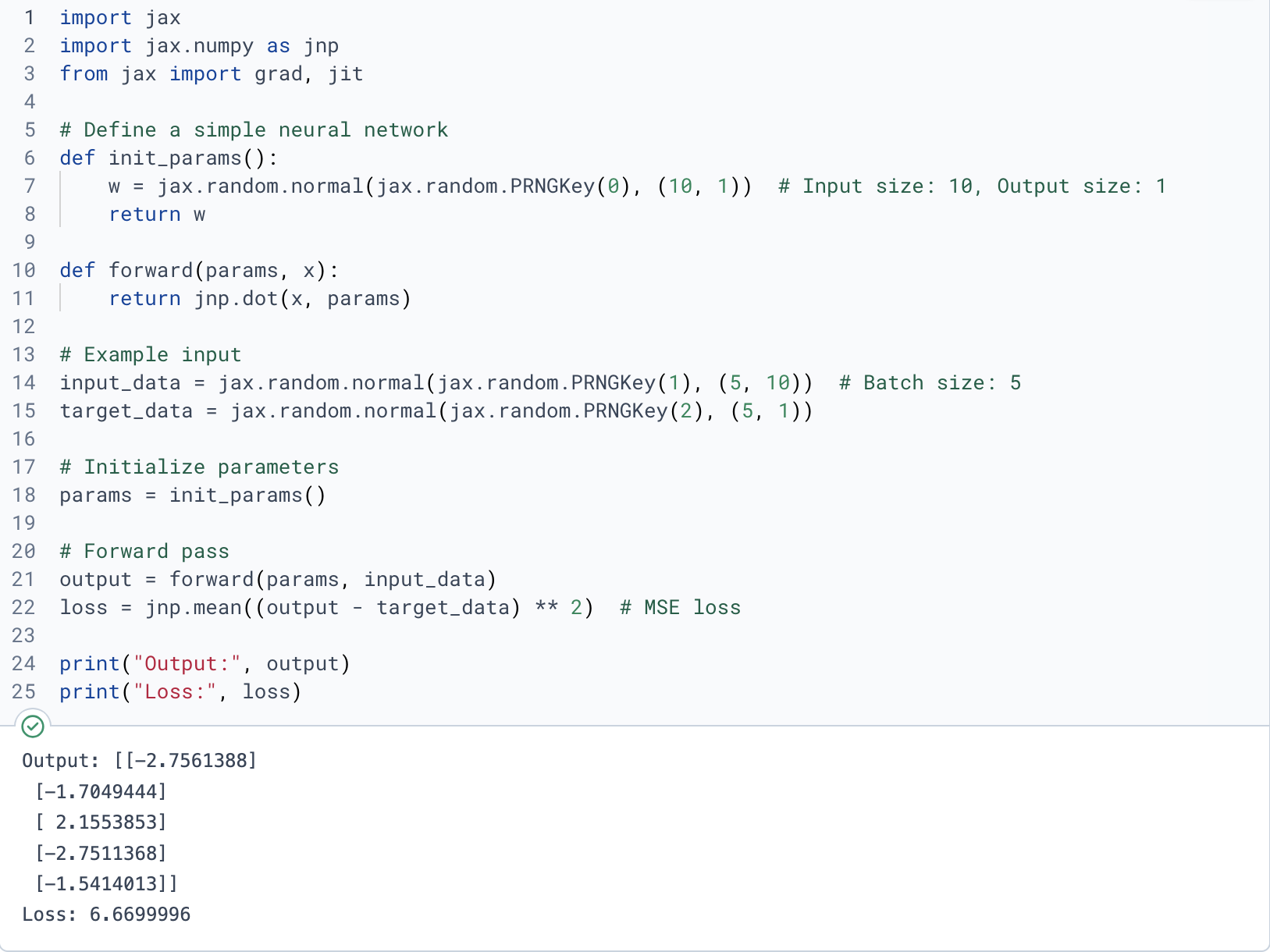
+This example shows a basic neural network in JAX using a functional approach, where a dot product computes output, random input and target data are generated, and mean squared error loss is calculated, highlighting JAX's efficiency.
+
+
+## PyTorch vs. JAX: A quick comparison
+
+This table outlines the key differences and strengths of PyTorch and JAX to help you choose the best fit for your deep learning project.
diff --git a/docs/keyboard-shortcuts.md b/docs/keyboard-shortcuts.md
new file mode 100644
index 0000000000..a463674f93
--- /dev/null
+++ b/docs/keyboard-shortcuts.md
@@ -0,0 +1,64 @@
+---
+title: Keyboard shortcuts
+noIndex: false
+noContent: false
+---
+
+### ⌨️ General
+
+| Mac | Windows & Linux | Action |
+| -------------------------- | ----------------------------- | ------------------------- |
+| ⌘ + P | ctrl + P | Show/Hide command palette |
+| ⌘ + K | ctrl + K | Open search bar |
+| ⌘ + . | ctrl + . | Hide/Show UI |
+| ⌘ + [ | ctrl + [ | Go back |
+| ⌘ + ] | ctrl + ] | Go forward |
+
+
+
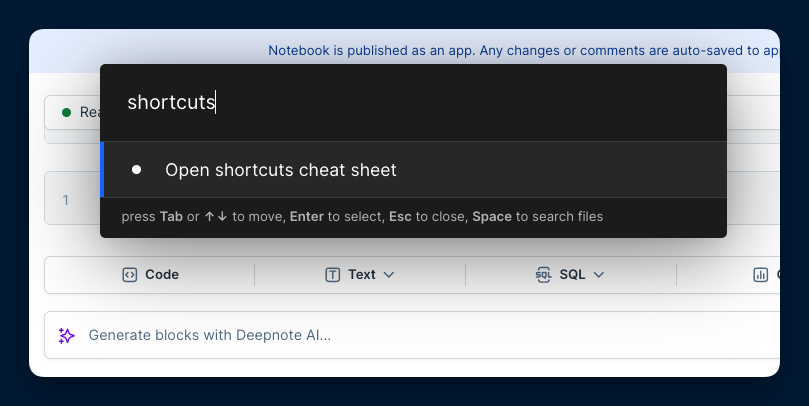
+If you need to quickly look up keyboard shortcuts in Deepnote, just start typing **shortcuts** in the command palette.
+
+
+
+### 🧱 Block actions
+
+| Mac | Windows & Linux | Action |
+| ------------------------------ | --------------------------------------------- | --------------------------------------------------------------------------------------------------------------- |
+| ⇧ + ↵ | shift + enter | Run current block and move cursor to next block
(creates a new cell if at the end of the notebook)
|
+| ⌥ + ↵ | alt + enter | Run block & create code block below |
+| ⌘ + ↵ | ctrl + enter | Run current block |
+| ⌘ + ⇧ + . | ctrl + shift + . | Stop execution |
+| ⌘ + ⌥ + H | ctrl + alt + H | Hide/Show block code |
+| ⌘ + ⇧ + H | ctrl + shift + H | Hide/Show block output |
+| ⌘ + ⇧ + M | ctrl + shift + M | Toggle between code and Markdown block |
+| ⌘ + ⇧ + ⌫ | ctrl + shift + backspace | Delete block |
+| ⌥ + ⇧ + ↑ | alt + shift + ↑ | Move block up |
+| ⌥ + ⇧ + ↓ | alt + shift + ↓ | Move block down |
+| ⌘ + ⇧ + D | ctrl + shift + D | Duplicate block |
+| ⌘ + J | ctrl + J | Add new code block below current one |
+| ⌘ + K | ctrl + K | Add new code block above current one |
+| ⌘ + Z | ctrl + Z | Undo |
+| ⌘ + ⇧ + Z | ctrl + shift + Z | Redo |
+| ⌘ + ⌥ + C | ctrl + alt + C | Add comment |
+| ⌘ + ' | ctrl + ' | More actions |
+| ⌘ + ⇧ + E | ctrl + shift + E | Edit code with AI |
+| ⌘ + ⇧ + I | ctrl + shift + I | Explain code with AI |
+
+### ✍️ Code editing
+
+| Mac | Windows & Linux | Action |
+| ------------------------------ | ------------------------------------ | ---------------------------------------------------------------------------------------------------------- |
+| ⌘ + D | ctrl + D | Expand selection (multiple cursors) |
+| tab | tab | When caret is at the beginning of a line, add indent
Otherwise, show autocomplete suggestions
|
+| ⇧ + tab | shift + tab | Decrease indent |
+| ⌘ + / | ctrl + / | Toggle line/selection comment |
+| ⌥ + ↓ | alt + ↓ | Move lines down |
+| ⌥ + ↑ | alt + ↑ | Move lines up |
+| ⌥ + ⇧ + F | alt + shift + F | Format code |
+
+### 🖥️ Terminal
+
+| Mac | Windows & Linux | Action |
+| -------------------------- | ------------------------------------- | ------------------ |
+| ⌘ + C | ctrl + shift + C | Copy selected text |
+| ⌘ + V | ctrl + shift + V | Paste |
diff --git a/docs/launch-repositories-in-deepnote.md b/docs/launch-repositories-in-deepnote.md
new file mode 100644
index 0000000000..4a189e279c
--- /dev/null
+++ b/docs/launch-repositories-in-deepnote.md
@@ -0,0 +1,125 @@
+---
+title: Launch repositories in Deepnote
+noIndex: false
+noContent: false
+---
+
+Deepnote supports launching repositories as Deepnote projects (so every user who clicks on the link will see a new project created just for them with the contents of the repository).
+
+[See examples on GitHub](https://github.com/SuNaden/deepnote-launch-example)
+
+### Launching repositories in Deepnote
+
+Deepnote supports launching repositories as Deepnote projects (so every user who clicks on the link will see a new project created just for them with the contents of the repository). Copy the link below and URL encode your repository link (you can use [https://www.urlencoder.io/](https://www.urlencoder.io/)).
+
+Example launch link (don't forget to URL encode the link you want to open)
+
+```
+https://deepnote.com/launch?url=
+```
+
+Full example with converting [`https://github.com/norvig/pytudes`](https://github.com/norvig/pytudes) to a Deepnote launch link
+
+```
+https://deepnote.com/launch?url=https%3A%2F%2Fgithub.com%2Fnorvig%2Fpytudes%2Fblob%2Fmaster%2Fipynb%2FAdvent-2018.ipynb
+```
+
+Example of a Deepnote launch link can be seen in the `README.md` of the [pytudes repository](https://github.com/norvig/pytudes)
+
+The url doesn't have to be a GitHub repository, it can also be a direct link to an `.ipynb` file. You can also add a name parameter in the url.
+
+```
+https://deepnote.com/launch?name=MyProject&url=https://company.com/link/to/static/notebook.ipynb
+```
+
+### Adding a Deepnote launch button
+
+[Github repository with button examples](https://github.com/SuNaden/deepnote-launch-example)
+
+#### Launch in Deepnote - Black
+
+Button link
+
+```
+// Large button
+https://deepnote.com/buttons/launch-in-deepnote.svg
+
+// Small (badge-style) button
+https://deepnote.com/buttons/launch-in-deepnote-small.svg
+```
+
+Example usage in a markdown file (e.g. `README.md`)
+
+```
+// Large button
+[ ](PROJECT_URL)
+
+// Small (badge-style) button
+[
](PROJECT_URL)
+
+// Small (badge-style) button
+[ ](PROJECT_URL)
+```
+
+#### Launch in Deepnote - White
+
+Button link
+
+```
+// Large button
+https://deepnote.com/buttons/launch-in-deepnote-white.svg
+
+// Small (badge-style) button
+https://deepnote.com/buttons/launch-in-deepnote-white-small.svg
+```
+
+Example usage in a markdown file (e.g. `README.md`)
+
+```
+// Large button
+[
](PROJECT_URL)
+```
+
+#### Launch in Deepnote - White
+
+Button link
+
+```
+// Large button
+https://deepnote.com/buttons/launch-in-deepnote-white.svg
+
+// Small (badge-style) button
+https://deepnote.com/buttons/launch-in-deepnote-white-small.svg
+```
+
+Example usage in a markdown file (e.g. `README.md`)
+
+```
+// Large button
+[ ](PROJECT_URL)
+
+// Small (badge-style) button
+[
](PROJECT_URL)
+
+// Small (badge-style) button
+[ ](PROJECT_URL)
+```
+
+#### **Try in a Jupyter notebook - Black**
+
+Button link
+
+```
+// Large button
+https://deepnote.com/buttons/try-in-a-jupyter-notebook.svg
+
+// Small (badge-style) button
+https://deepnote.com/buttons/try-in-a-jupyter-notebook-small.svg
+```
+
+Example usage in a markdown file (e.g. `README.md`)
+
+```
+// Large button
+[
](PROJECT_URL)
+```
+
+#### **Try in a Jupyter notebook - Black**
+
+Button link
+
+```
+// Large button
+https://deepnote.com/buttons/try-in-a-jupyter-notebook.svg
+
+// Small (badge-style) button
+https://deepnote.com/buttons/try-in-a-jupyter-notebook-small.svg
+```
+
+Example usage in a markdown file (e.g. `README.md`)
+
+```
+// Large button
+[ ](PROJECT_URL)
+
+// Small (badge-style) button
+[
](PROJECT_URL)
+
+// Small (badge-style) button
+[ ](PROJECT_URL)
+```
+
+#### **Try in a Jupyter notebook -**
+
+Button link
+
+```
+// Large button
+https://deepnote.com/buttons/try-in-a-jupyter-notebook-white.svg
+
+// Small (badge-style) button
+https://deepnote.com/buttons/try-in-a-jupyter-notebook-white-small.svg
+```
+
+Example usage in a markdown file (e.g. `README.md`)
+
+```
+// Large button
+[
](PROJECT_URL)
+```
+
+#### **Try in a Jupyter notebook -**
+
+Button link
+
+```
+// Large button
+https://deepnote.com/buttons/try-in-a-jupyter-notebook-white.svg
+
+// Small (badge-style) button
+https://deepnote.com/buttons/try-in-a-jupyter-notebook-white-small.svg
+```
+
+Example usage in a markdown file (e.g. `README.md`)
+
+```
+// Large button
+[ ](PROJECT_URL)
+
+// Small (badge-style) button
+[
](PROJECT_URL)
+
+// Small (badge-style) button
+[ ](PROJECT_URL)
+```
diff --git a/docs/lectures.md b/docs/lectures.md
new file mode 100644
index 0000000000..9aa8c3428f
--- /dev/null
+++ b/docs/lectures.md
@@ -0,0 +1,19 @@
+---
+title: Lectures
+noIndex: false
+noContent: false
+---
+
+Deepnote helps you bring lectures to life by allowing you to create interactive, dynamic lessons that engage and challenge your students. With Deepnote, you can easily incorporate code examples, interactive exercises, and visualizations into lectures, which helps students better understand complex concepts and ideas.
+
+Deepnote's cloud-based workspace means that students can access and work on lectures from anywhere, on any device, at any time. This can be particularly helpful for students who may not have access to a traditional classroom setting or who may need to review material on their own time.
+
+With a wide range of cell types at your disposal — including Markdown, headings, text, charts, sliders, and code — you can easily transform your entire curriculum into interactive lectures.
+
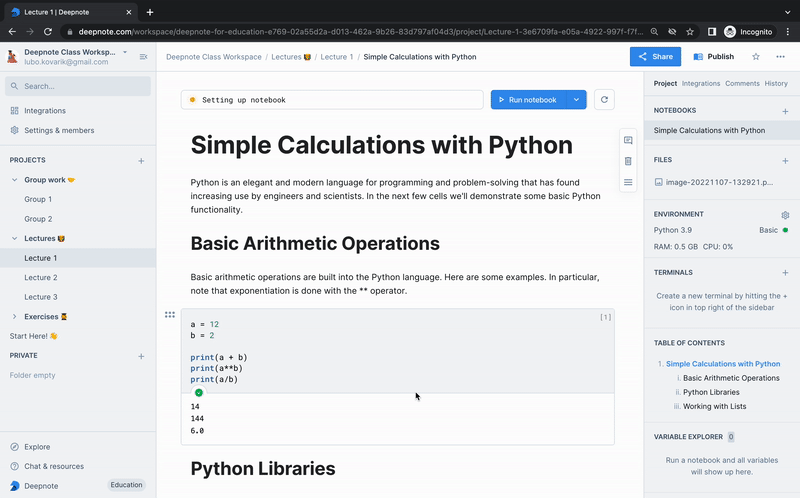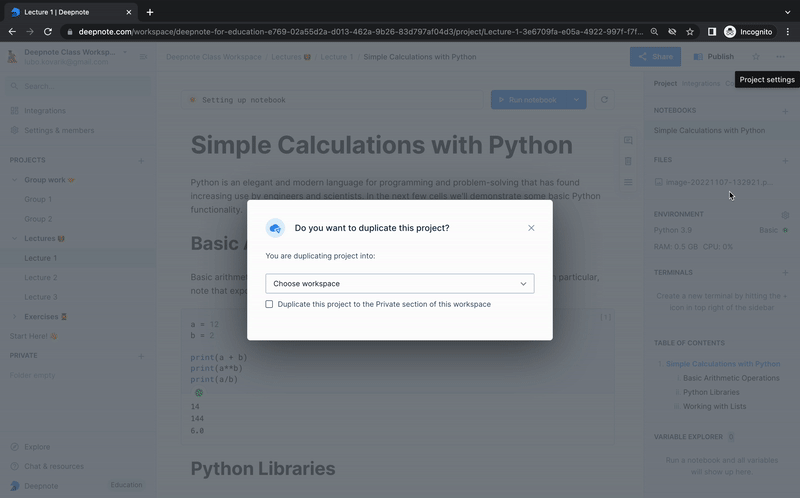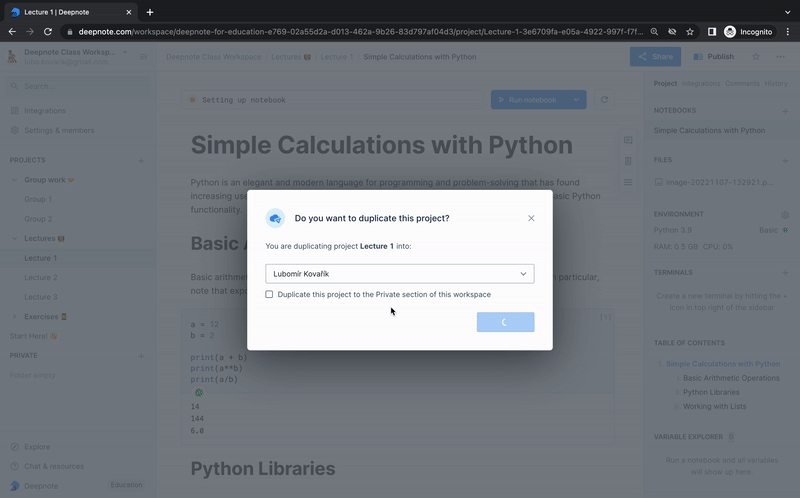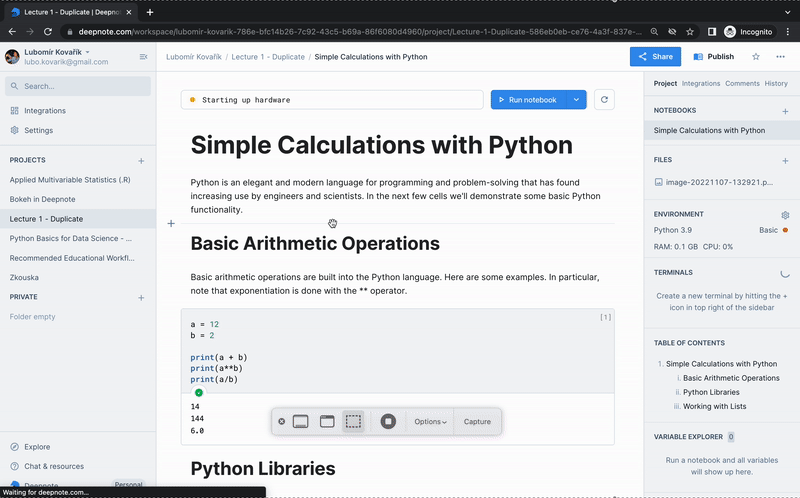
+And with Deepnote's workspaces and access control system, distributing your materials to your students is a breeze. Simply invite them as Viewers to your lecture workspace and allow them to duplicate the project in their own personal workspace for easy access and review.
+
+
+ Deepnote tip: Utilize our duplication feature when distributing your learning curriculum among your entire classroom.
+
+
+
diff --git a/docs/long-running-jobs.md b/docs/long-running-jobs.md
new file mode 100644
index 0000000000..67f6cbe046
--- /dev/null
+++ b/docs/long-running-jobs.md
@@ -0,0 +1,58 @@
+---
+title: Long-running jobs
+noIndex: false
+noContent: false
+---
+
+Deepnote is designed to support most data analysis workflows, many of which include long-running tasks. This page explains when the hardware for your projects can be turned off.
+
+### What it means for Deepnote to turn off the hardware for a project
+
+Simplifying a little bit, Deepnote has many machines (computers) running in the cloud (pods in a Kubernetes cluster if you want the real jargon). When you start the hardware in your project, we turn on one of these machines for you and run all your computations there. Once you're done with your computations, we turn off this machine for you just like you would turn off your own laptop at the end of your workday. Unlike with your laptop though, you can view the notebooks and files in your project even while the hardware for your project is turned off – you only need running hardware to execute computations. We automatically start this hardware whenever you start any execution in your project (e.g. when you run a block).
+
+After the hardware notebook is turned off, we store the outputs of cells, but the values of variables are gone (just like when you turn off your computer).
+
+To start your hardware back up after we turn off the hardware for your project, run any cell or click "Start machine" in the environment sidebar.
+
+### Automatic machine shut down
+
+Deepnote may turn off machines automatically for the following reasons:
+
+- the project was **inactive** for a certain period of time;
+
+- the project **exceeded the uptime limit** for **long-running executions**;
+
+- the project consumed all of the **hardware quota** available for the workspace
+
+#### Inactivity
+
+**All projects** get hardware turned off when no one is using them. We do this to help you avoid using up your free hardware hours unnecessarily or pay for the unused paid machines. The following two **conditions of inactivity** have to be met:
+
+1. **The project has no running cells in notebooks.** Code running in terminals does not prevent hardware from turning off.
+2. **There were no changes to the code or any execution for at least 15 minutes.** This maximum idle time is [customizable](/docs/long-running-jobs#custom-inactivity-grace-period) for projects in teams with a Team plan or higher.
+
+
+📖 **Example:** Bob is running a data analysis that takes 12 hours to complete. He starts the analysis and then closes Deepnote for the night. He comes back in the morning just before the analysis is complete and finds his notebook with all his variables is still live. Bob does some ad-hoc exploration and then goes to lunch with the notebook idle. After he comes back, he can still see all his outputs, but the variables and all other runtime objects are gone as the above conditions were met and the hardware for his project was turned off.
+
+
+#### Inactivity grace period
+
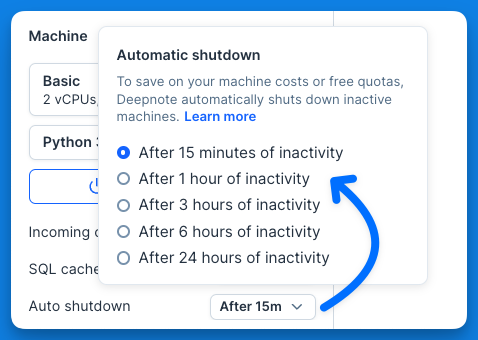
+A project is considered inactive when there are no code changes or executions within a specified period. Once this period of inactivity ends, the hardware is turned off. By default, this grace period is set to 15 minutes.
+
+Users on **Team plan or higher** can customize the behavior above and prevent the hardware being automatically turned off after 15 minutes of inactivity. This can be useful if you're unsure when your long-running job finishes and want to keep its state preserved (such as Python variables or terminal outputs). You can currently set the grace period to one of the following options:
+
+
+
+#### Long-running executions
+
+Hardware of **projects running on the Free plan** gets turned off automatically after running continuously for **8 hours**. Any running computation is interrupted. In extraordinary circumstances, we also reserve the right to turn off the hardware for the project earlier. In this case, you will see a message "Your hardware was shut down" next time you visit the project.
+
+Projects **running on the Team plan or higher** have a runtime limit of **48 hours**, with an additional 1-hour grace period. As the shutdown time approaches, a message is displayed offering the possibility of a 1-hour extension.
+
+#### Hardware quotas
+
+Finally, hardware of **projects running on the Free plan** is turned off if their owner runs out of free quota and they don't have a paying method set up. In this case, an info message will also appear next time you visit the notebook, notifying you about running out of the free quota.
+
+
+**Notebook size:** Keep in mind that the maximum size of a notebook, together with outputs generated by long running cell executions, is 30MB.
+
diff --git a/docs/machine-hours.md b/docs/machine-hours.md
new file mode 100644
index 0000000000..07a8c1e917
--- /dev/null
+++ b/docs/machine-hours.md
@@ -0,0 +1,31 @@
+---
+title: Additional machine hours
+noIndex: false
+noContent: false
+---
+
+Every workspace in Deepnote has free machine hours that replenish every month. If you need additional machine hours or more powerful machines, you can always upgrade your hardware.
+
+###### **What are machine hours?**
+
+When you run your notebooks, we use cloud-based hardware to execute your code. Machine hours are the total amount of hours our hardware was running to execute this code.
+
+###### **How many machine hours are offered for free?**
+
+Our goal is to provide an unlimited number of free machine hours for all workspaces. However, in certain cases we might limit a workspace’s compute hours when we detect irregular activity or extremely high usage. In case this happens, we will be in touch with you.
+
+###### **How can I add more machine hours?**
+
+In the rare occasion that a workspace exceeds the free machine hours we provide, workspaces on the Team and Enterprise plans can purchase additional machine hours. The hourly cost of these machines can be found in the Machines menu.
+
+
+
+###### **How can I upgrade to more RAM or CPU?**
+
+Workspaces on the Team and Enterprise plans can choose to switch to stronger machines, with higher computation power and RAM. The hourly cost of these machines can be found in the Machines menu.
+
+
+
+###### **How much will I be charged for machines?**
+
+If you decide to purchase machine hours beyond the free machine hours we provide, you will be charged at an hourly rate, calculated on a per-minute basis. So if you use a machine that costs $1/hr for 30 minutes, you will be charged $0.50. You can find the hourly rates for each machine in the Machines menu.
diff --git a/docs/materialize.md b/docs/materialize.md
new file mode 100644
index 0000000000..425f08e8b1
--- /dev/null
+++ b/docs/materialize.md
@@ -0,0 +1,27 @@
+---
+title: Materialize
+description: Available to teams and users on all plans
+noIndex: false
+noContent: false
+coverImage: 7AGIkclfQWCUivwJLnEg
+---
+
+### Materialize
+
+Deepnote now supports a first-class built-in integration with Materialize. Materialize is an operational data warehouse that shines for use cases where an analytical data warehouse would be too slow, and a stream processor would be too complicated.
+
+Using SQL and your bare hands, Materialize allows you to build real-time automation, engaging customer experiences, and interactive data products that drive value for your business while reducing the cost of data freshness.
+
+If you need to speed up queries that run frequently, or trigger actions as soon as events happen, Materialize can help. Rather than recalculate results from scratch, or serve stale cached results, Materialize continually ingests data and keeps results up-to-date as new data arrives.
+
+# Setup
+
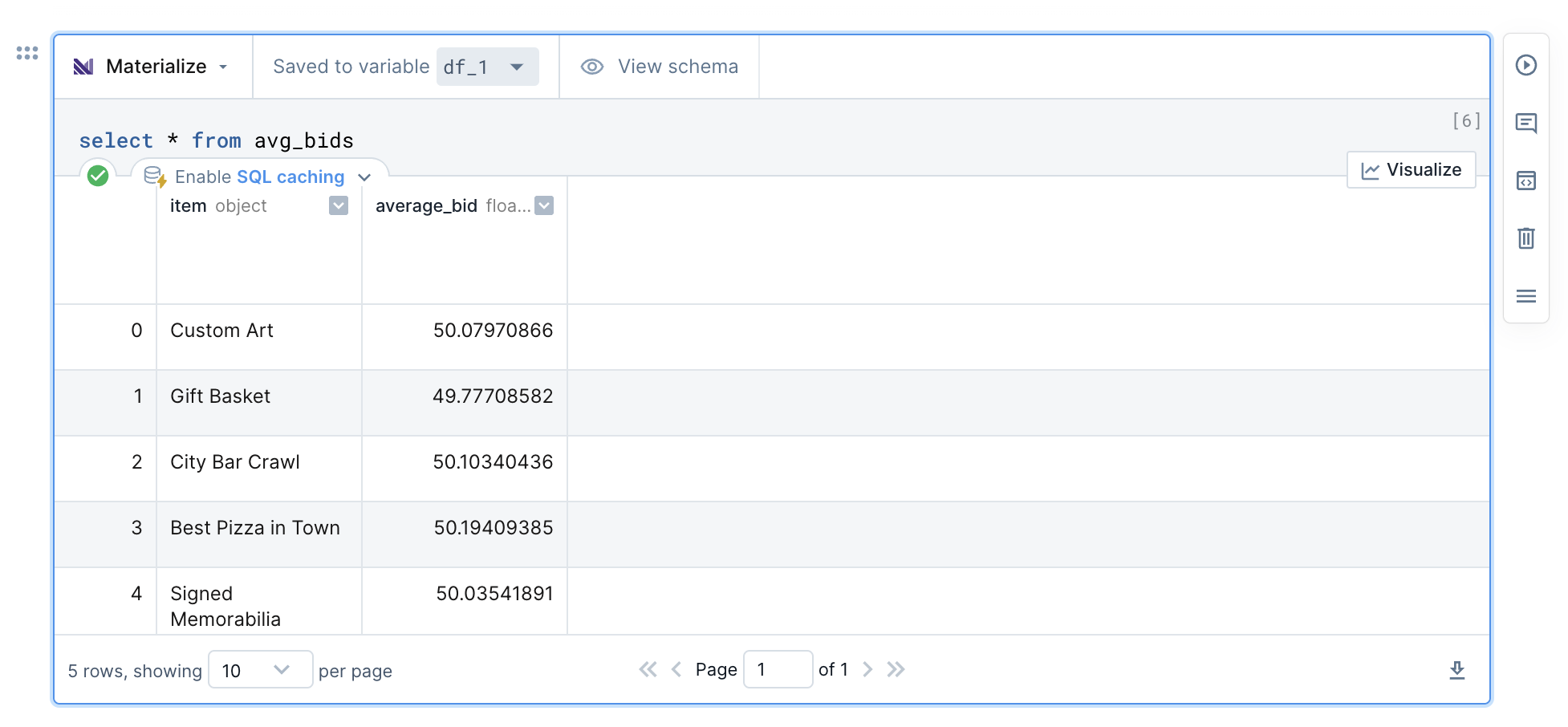
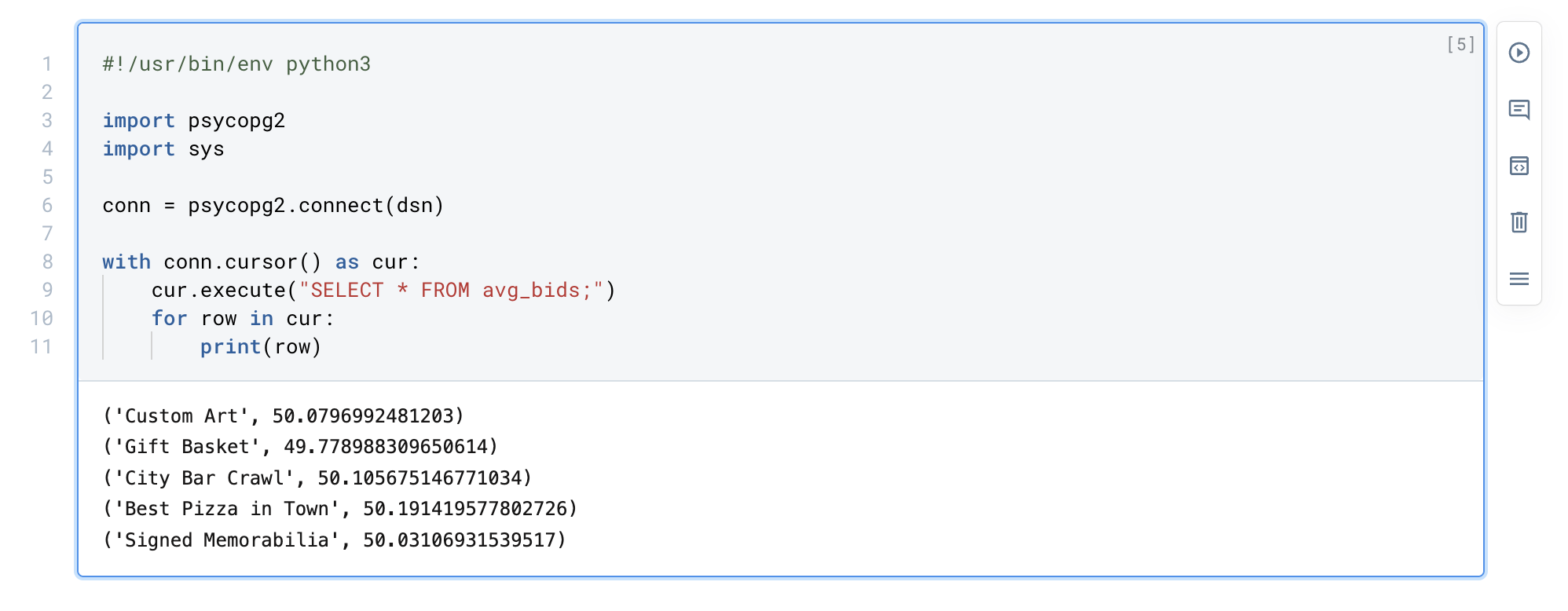
+Add a Materialize integration from the sidebar, and simply fill in your connection info. You may now use supported Postgres functionality of Materialize from Python or Deepnote's SQL Blocks
+
+
+
+
+
+# Materialize documentation
+
+You may find information about compatibilities and advanced usage of Materialize in their [documentation](https://materialize.com/docs/).
diff --git a/docs/mindsdb.md b/docs/mindsdb.md
new file mode 100644
index 0000000000..e2699be230
--- /dev/null
+++ b/docs/mindsdb.md
@@ -0,0 +1,19 @@
+---
+title: MindsDB
+noIndex: false
+noContent: false
+---
+
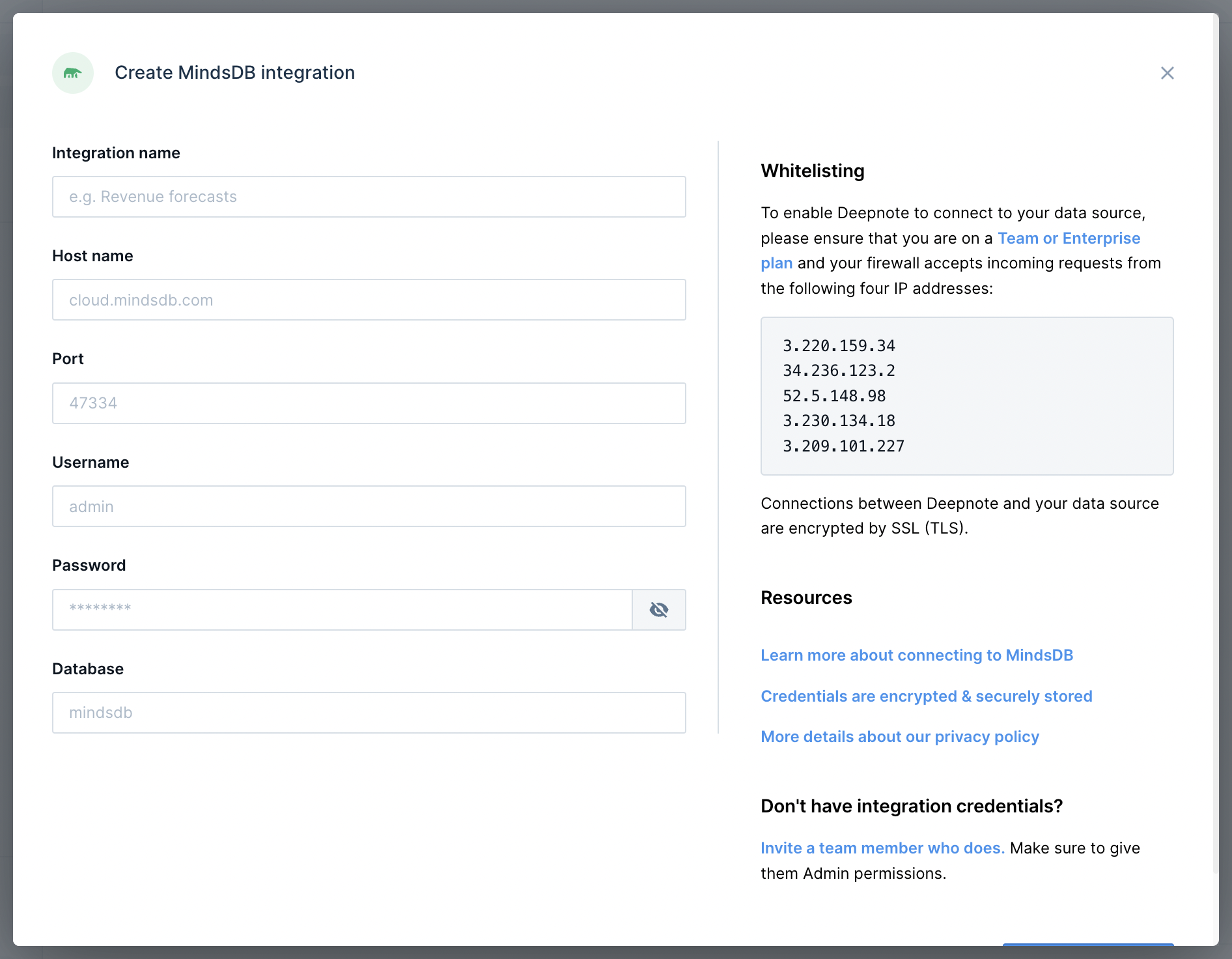
+Integration with MindsDB requires an account at [MindsDB Cloud](https://cloud.mindsdb.com/). Follow the steps there to connect MindsDB Cloud to your database instance. In Deepnote, choose the MindsDB integration from the dashboard and enter the credentials to MindsDB Cloud (these are visible in the MindsDB cloud dashboard).
+
+
+
+After that's done, you can connect the new integration to your project.
+
+### Usage
+
+The easiest way to query MindsDB is to use [SQL cells](/docs/sql-cells).
+
+### Secure connections
+
+Deepnote supports securing connections to MindsDB via optional [SSL & SSH tunnels](/docs/secure-connections).
diff --git a/docs/modules.md b/docs/modules.md
new file mode 100644
index 0000000000..5eb207881b
--- /dev/null
+++ b/docs/modules.md
@@ -0,0 +1,129 @@
+---
+title: Modules
+description: Turn notebooks into reusable workflows
+noIndex: false
+noContent: false
+---
+
+Modules in Deepnote allow you to **transform your notebooks into reusable workflows** that can be shared across your workspace. This powerful feature solves the common challenge of code fragmentation and inconsistent analysis by enabling you to package essential elements—code snippets, SQL queries, data transformations, and visualizations—into standardized, reusable components.
+
+With modules, you can adopt a "build once, use everywhere" approach, ensuring your team leverages consistent tools and methodologies without duplicating efforts. Whether you're working with complex data cleaning routines or custom visualization functions, modules make your best work instantly accessible throughout your workspace.
+
+
+
+## Use Cases
+
+Modules open up numerous possibilities for streamlining your data workflows:
+
+- **Semantic layer for KPIs**: Ensure everyone calculates metrics like churn rate or weekly active users consistently
+- **Modular ETL pipelines**: Break complex transformations into logical steps that are easier to maintain and debug
+- **Code reusability**: Share common functions, visualization code, and data processing logic across projects
+- **ML experimentation**: Package machine learning models to test consistently across different datasets and parameters
+
+## Creating a Module
+
+Turning a notebook into a module is a straightforward process:
+
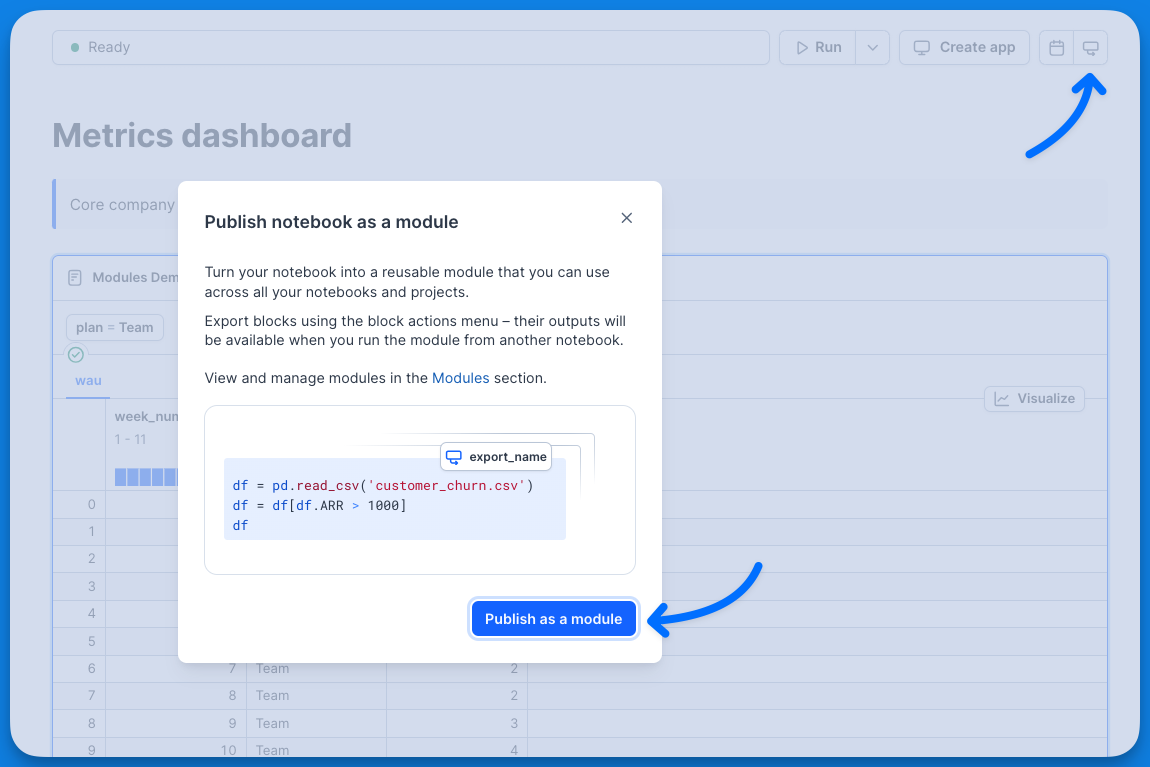
+Open the notebook you want to convert into a module and click the **create module button** in the notebook's upper right corner. Confirm your intent by pressing the ‘**Publish as a module**’ button.
+
+
+
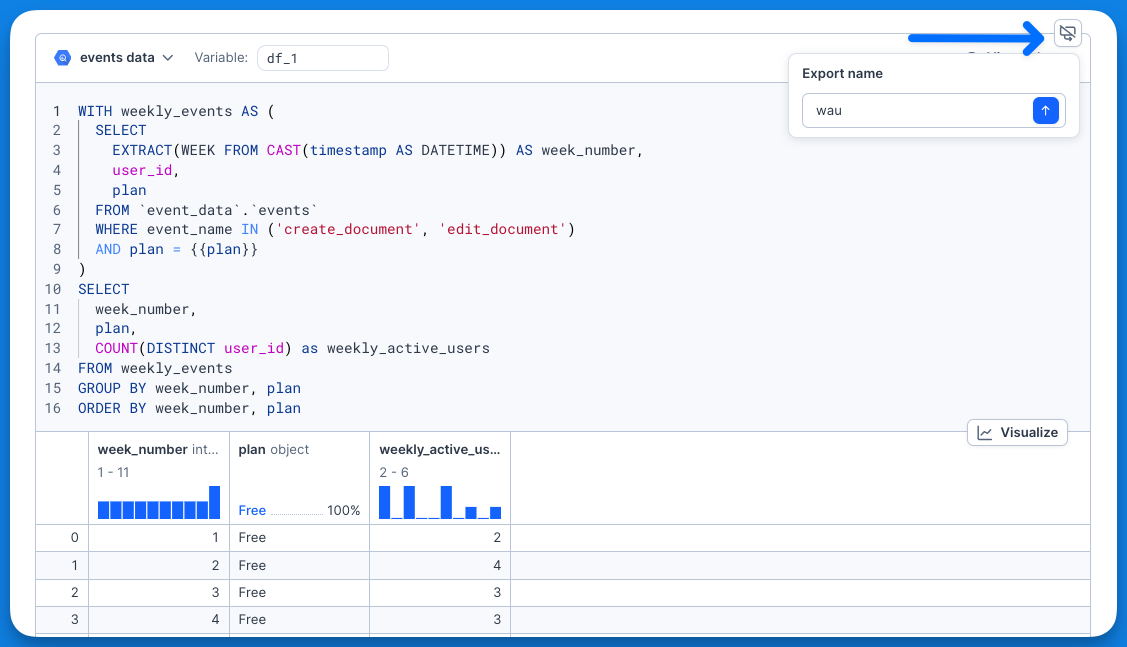
+At this point, your notebook is turned into a module! However, to make it useful, there’s an extra step needed: you need to **select which blocks you want to export** as the output of the module. You can do this by going to a code or SQL block and clicking the **export block** action.
+
+Then you can give the exported block a descriptive name and you’re done!
+
+
+
+You can export as many blocks as you wish from a single module. The **output of all exported blocks will be available** when others import your module.
+
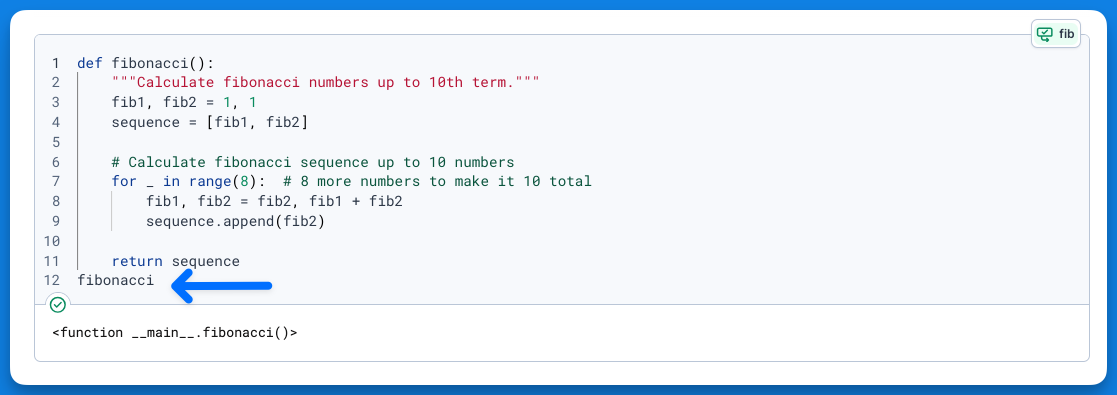
+It's important to note that exported outputs can differ based on the given block's type:
+
+- If you export a SQL block, the returned output will always be a DataFrame
+- In case of code blocks, the output will be the last returned variable within the code block
+- When exporting a function, ensure the function object is returned on the last line of the code block
+
+
+
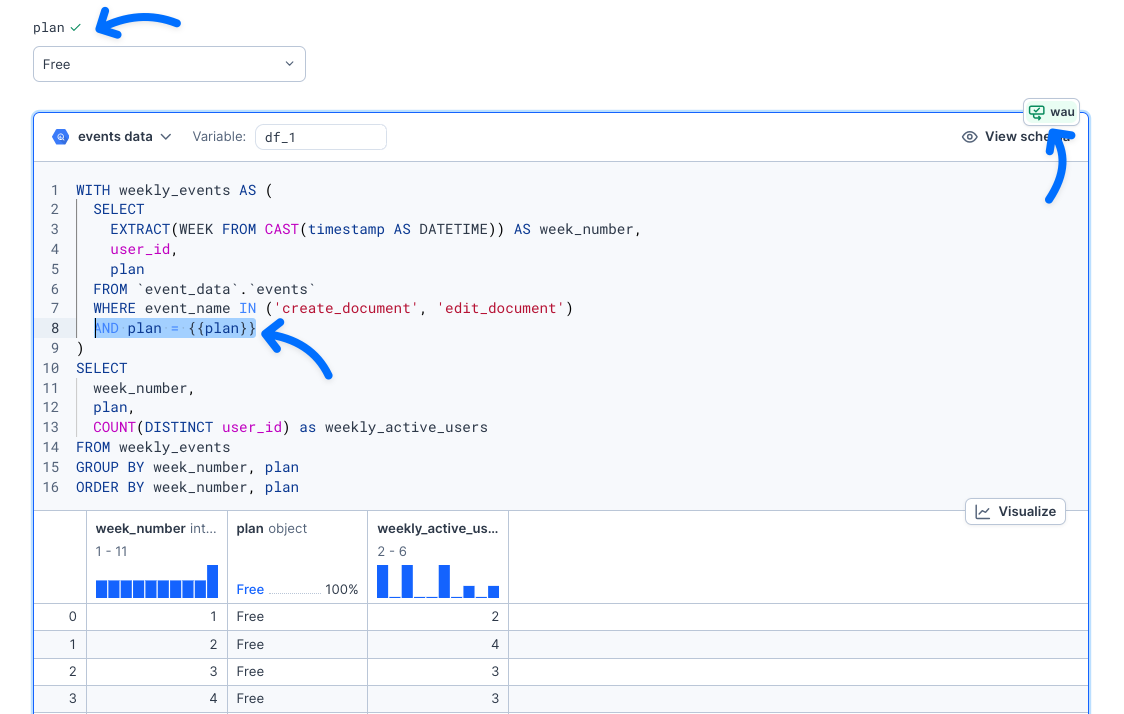
+**Adding Parameters**
+
+To make your module configurable, include input blocks in your notebook. These will automatically become parameters that users can set when importing your module. For example, if you add a select input linked to a SQL block, users of the module will be able to customize the returned results based on their selection (such as filtering by pricing plan).
+
+
+
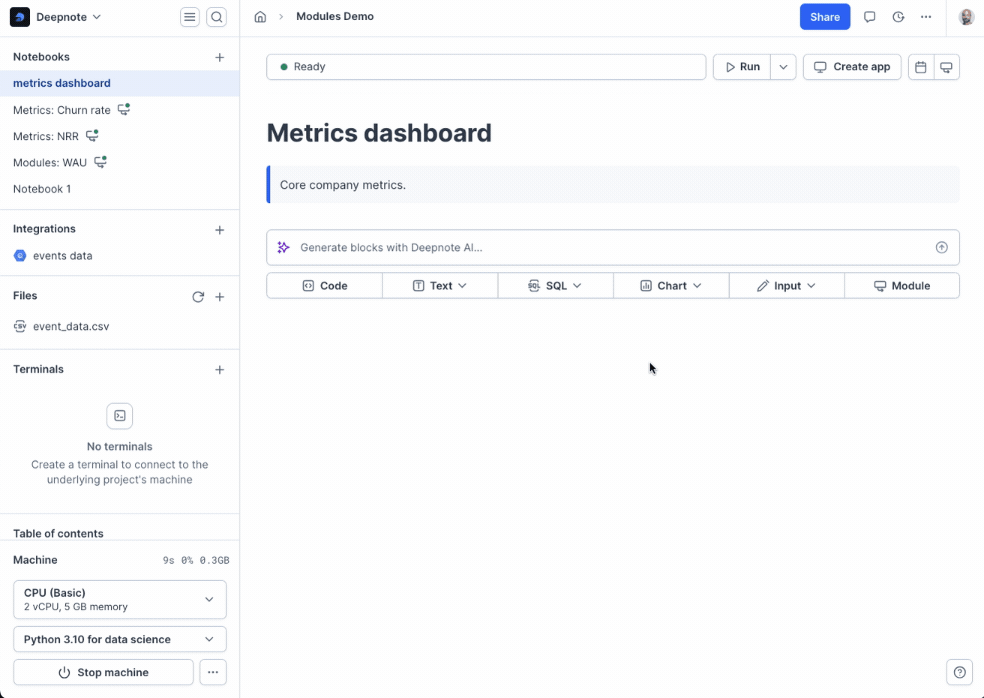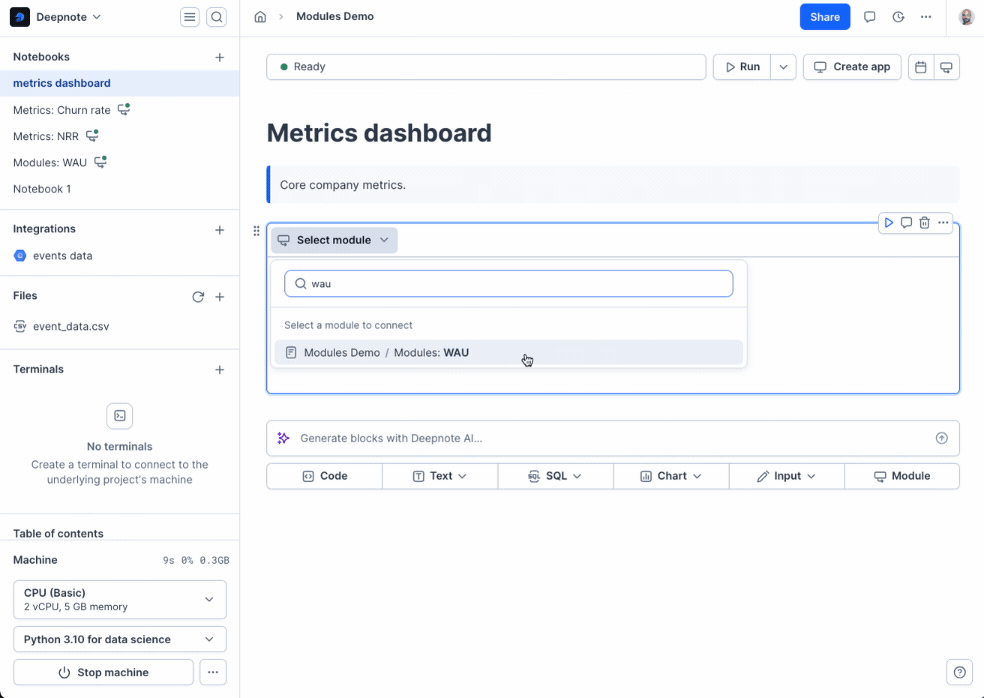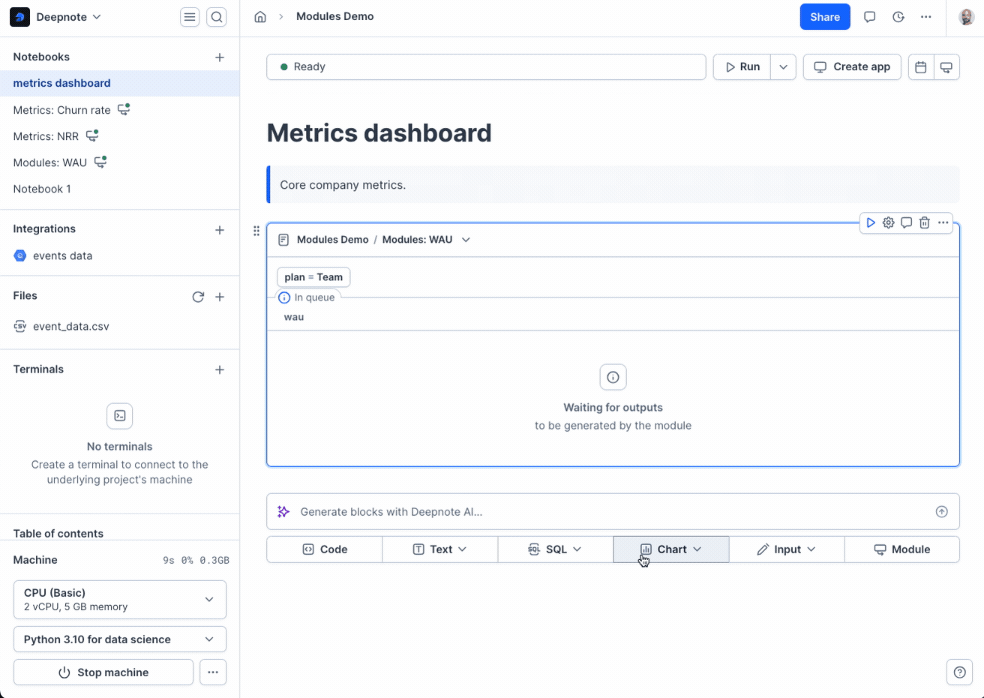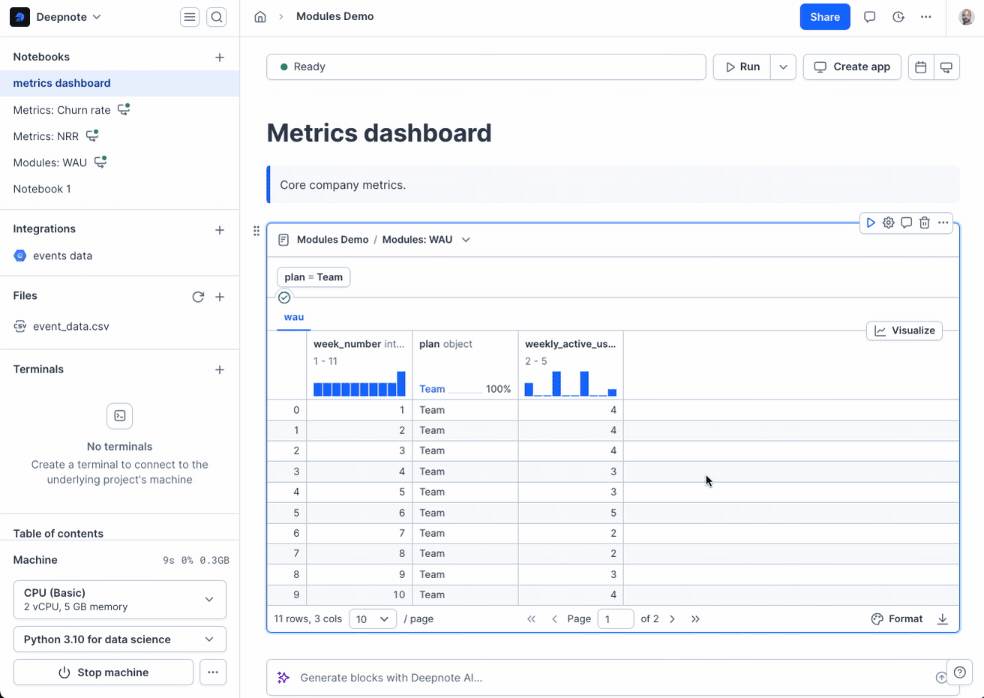
+## Importing a Module
+
+Using modules in your own notebooks is simple:
+
+1. Click the **module button** in the notebook footer
+2. Search for the module by project or notebook title
+3. Configure the module:
+ - Set any required input parameters
+ - Choose which exported blocks to import
+ - Optionally rename returned variables to fit your current notebook's naming conventions
+
+
+
+When you run the module block, it executes in a **separate environment** and returns your selected exports. All returned variables are automatically added to your current notebook's memory, seamlessly integrating with your existing work.
+
+**Special note on functions**
+
+When importing a Python function from a module, it's important to understand that **the function is executed in the context of the consuming notebook**. This means that global variables, integrations, and other environmental elements from the source module used within the imported functions may not be available in your current notebook.
+
+Make sure any dependencies required by your imported functions are either:
+
+- Explicitly passed as parameters to the function
+- Explicitly imported within the function itself
+- Already available in your current notebook environment
+
+This behavior differs from other module exports which execute in the module's own environment before returning their results.
+
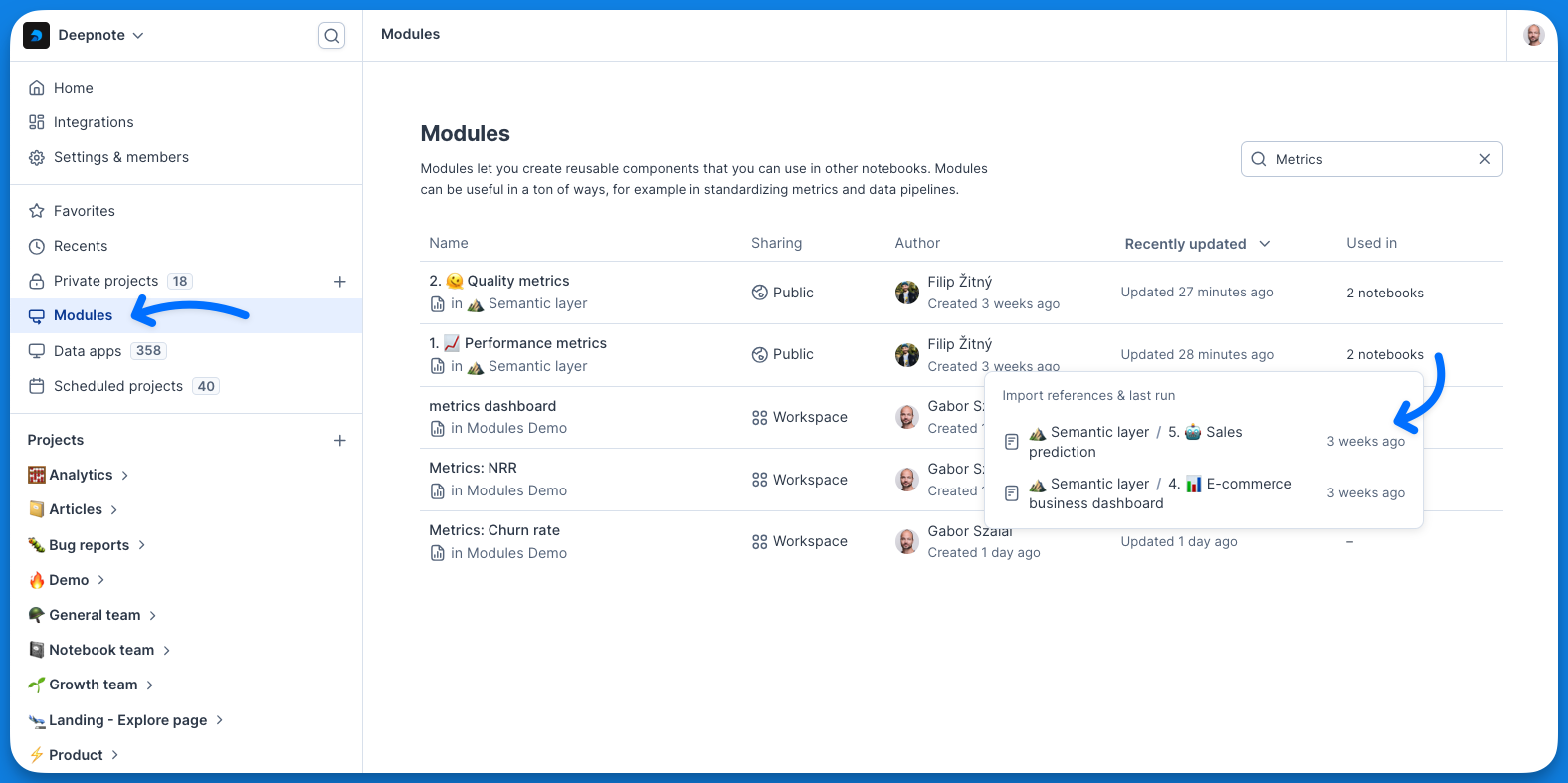
+## Module Library
+
+Access all published modules through the **Modules section** in your workspace navigation sidebar. This centralized location makes it easy to discover and utilize the collective knowledge and tools created by your team.
+
+
+
+The module library provides valuable information about each module:
+
+- Source project and notebook
+- Creator
+- Projects currently using the module
+
+This visibility helps you understand the impact and reach of each module across your workspace.
+
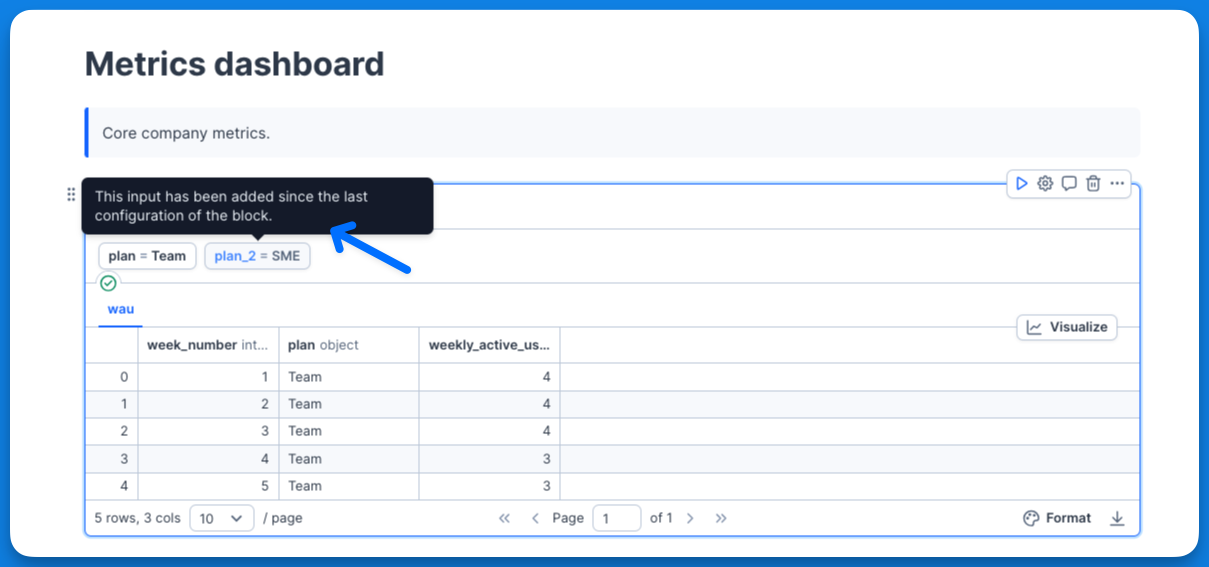
+## Updating modules
+
+If you wish to update a module, you can do so easily by modifying the source notebook. Any changes you make will be **automatically propagated** to all other notebooks that import the updated module upon its execution.
+
+In case there's a change affecting the configuration of the module (for instance, a new input parameter), these changes will be flagged visually in the module block before execution, giving you an opportunity to review and adjust the configuration as needed.
+
+
+
+## AI Support for Modules
+
+Deepnote AI seamlessly integrates with modules, enhancing analytical capabilities while maintaining consistency across your workspace.
+
+### Teaching Deepnote AI with Your Modules
+
+When you build a semantic layer with modules—defining your KPIs and metrics in a trusted, consistent way—you're not just helping your team, you're also teaching Deepnote AI. This integration creates a powerful workflow where AI leverages your established definitions rather than calculating metrics from scratch.
+
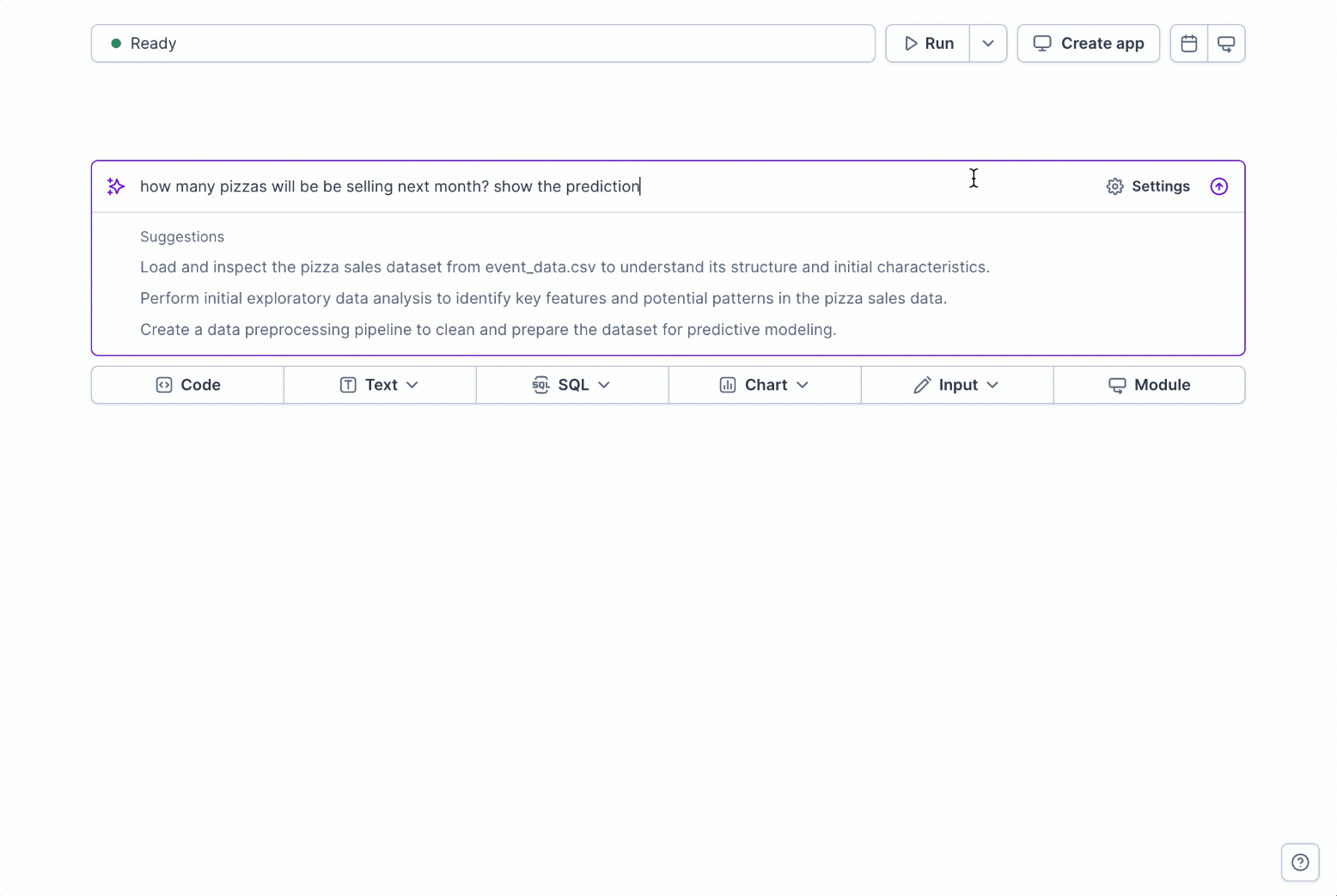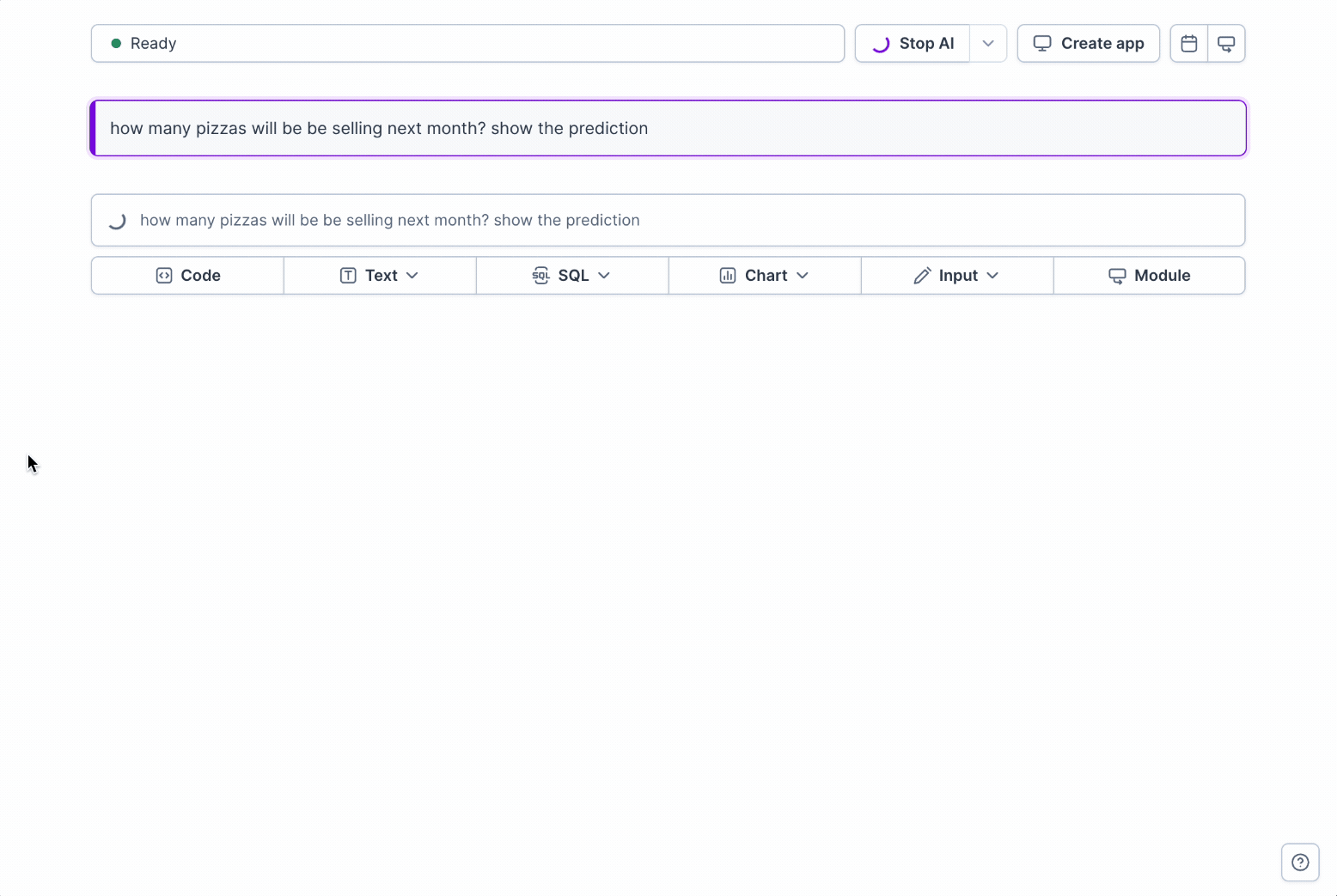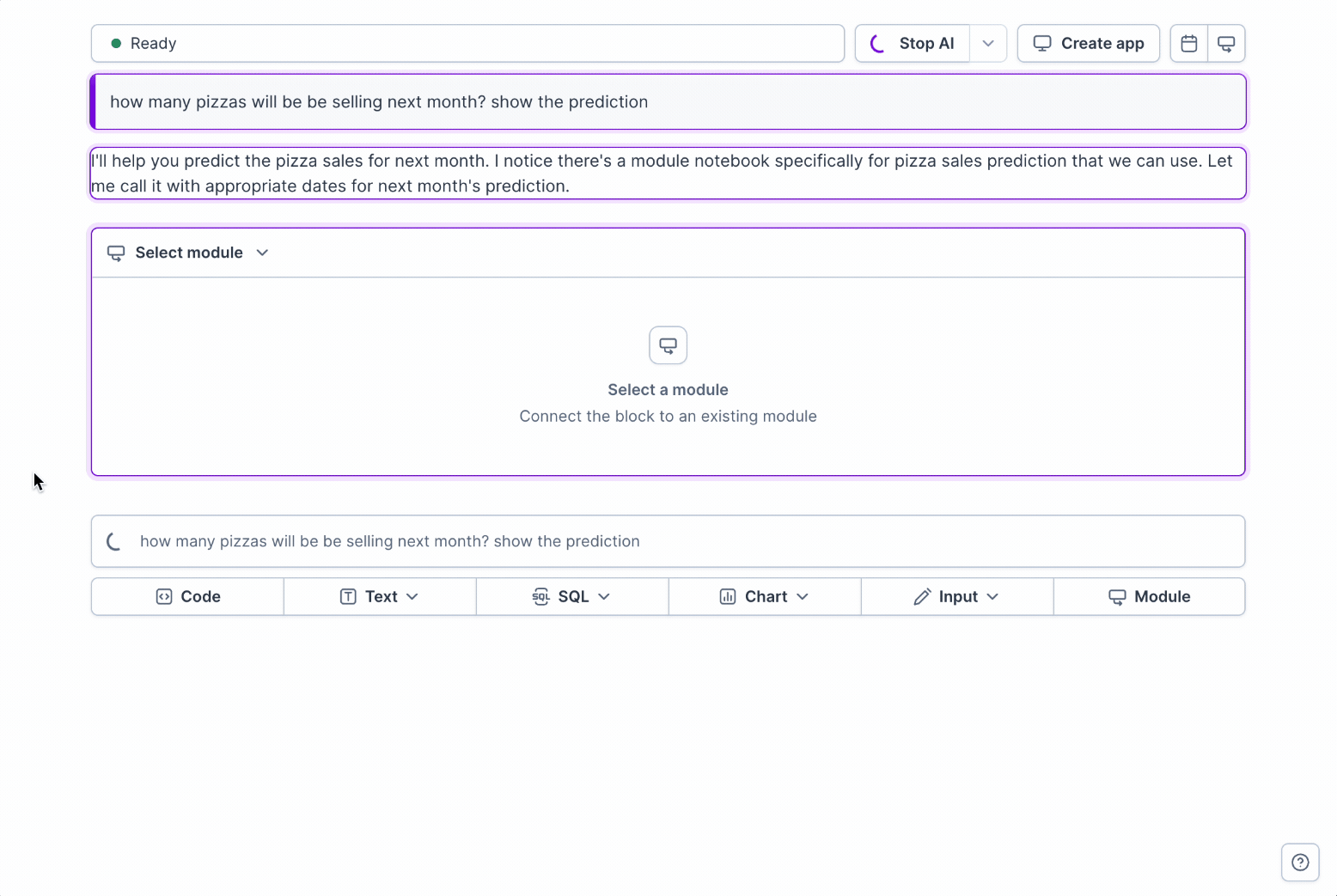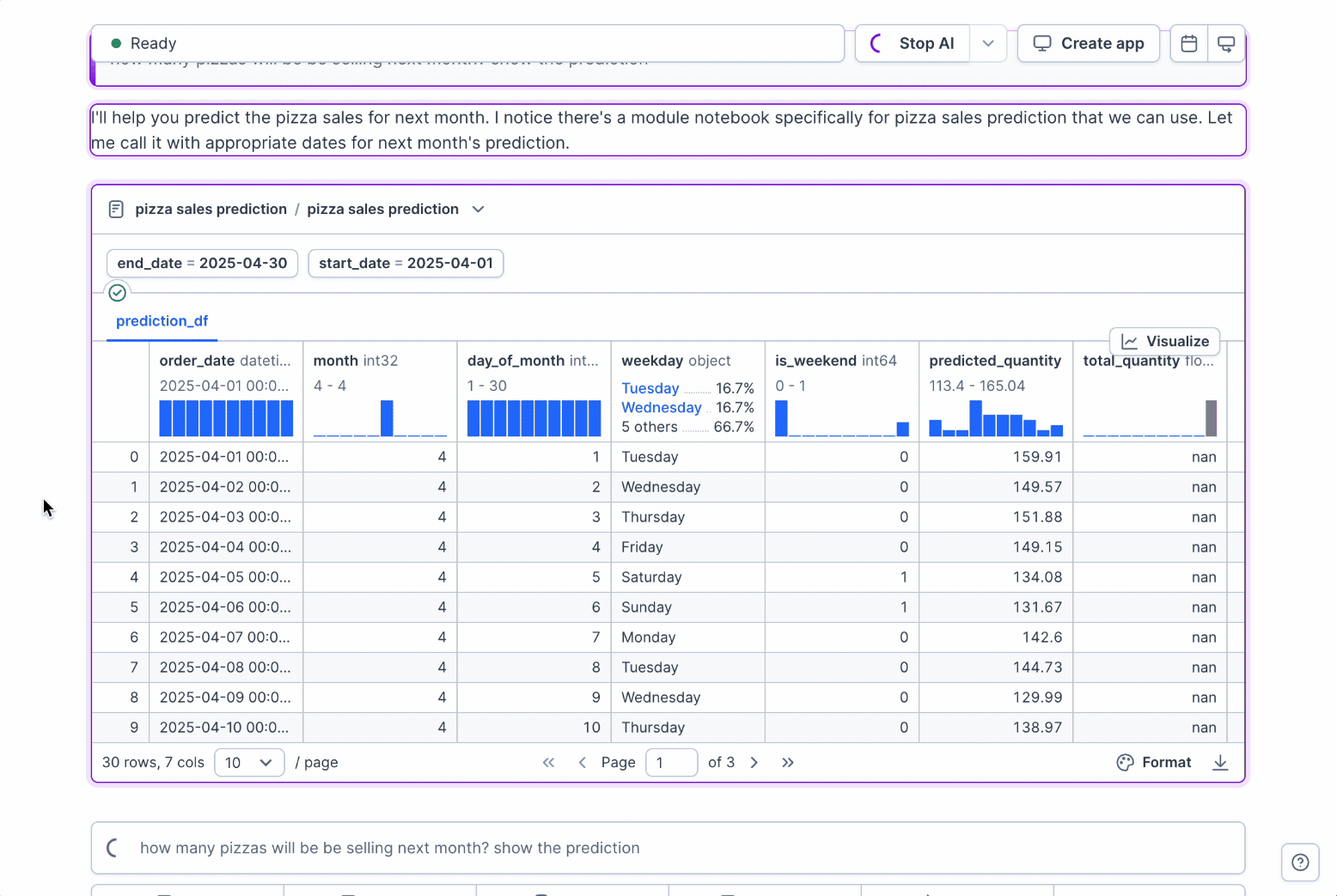
+
+
+### How It Works
+
+When you ask analytical questions in Deepnote AI, the system follows a thoughtful approach:
+
+1. **Module Library Check**: AI first checks your module library for existing trusted definitions relevant to your query
+2. **Automatic Module Selection**: It identifies and selects the appropriate module for your analytical needs
+3. **Parameter Adjustment**: Parameters are automatically configured based on your specific question
+4. **Foundation-Based Analysis**: The analysis is built upon your established modules rather than creating new calculations
+
+## Current Limitations
+
+While we continue to enhance modules, there are a few current limitations to be aware of:
+
+1. **Caching**: Imported modules always run with each execution, with no option to cache results. This feature is on our roadmap.
+2. **Passing data to modules**: Currently, you can only pass parameters based on input blocks in the notebook. For cases where you need to pass a DataFrame to a module (such as a charting function), the current solution is to import the function first and then call it on your DataFrame in the current notebook.
+3. **Output types**: Exports are currently limited to variables. This means you cannot export HTML outputs like charts directly as module outputs. We're working on expanding the supported output types.
+
+We're actively working on addressing these limitations in future updates based on user feedback.
diff --git a/docs/mongodb.md b/docs/mongodb.md
new file mode 100644
index 0000000000..5b570efa49
--- /dev/null
+++ b/docs/mongodb.md
@@ -0,0 +1,29 @@
+---
+title: MongoDB
+noIndex: false
+noContent: false
+---
+
+
+Available on Team and Enterprise plans
+
+
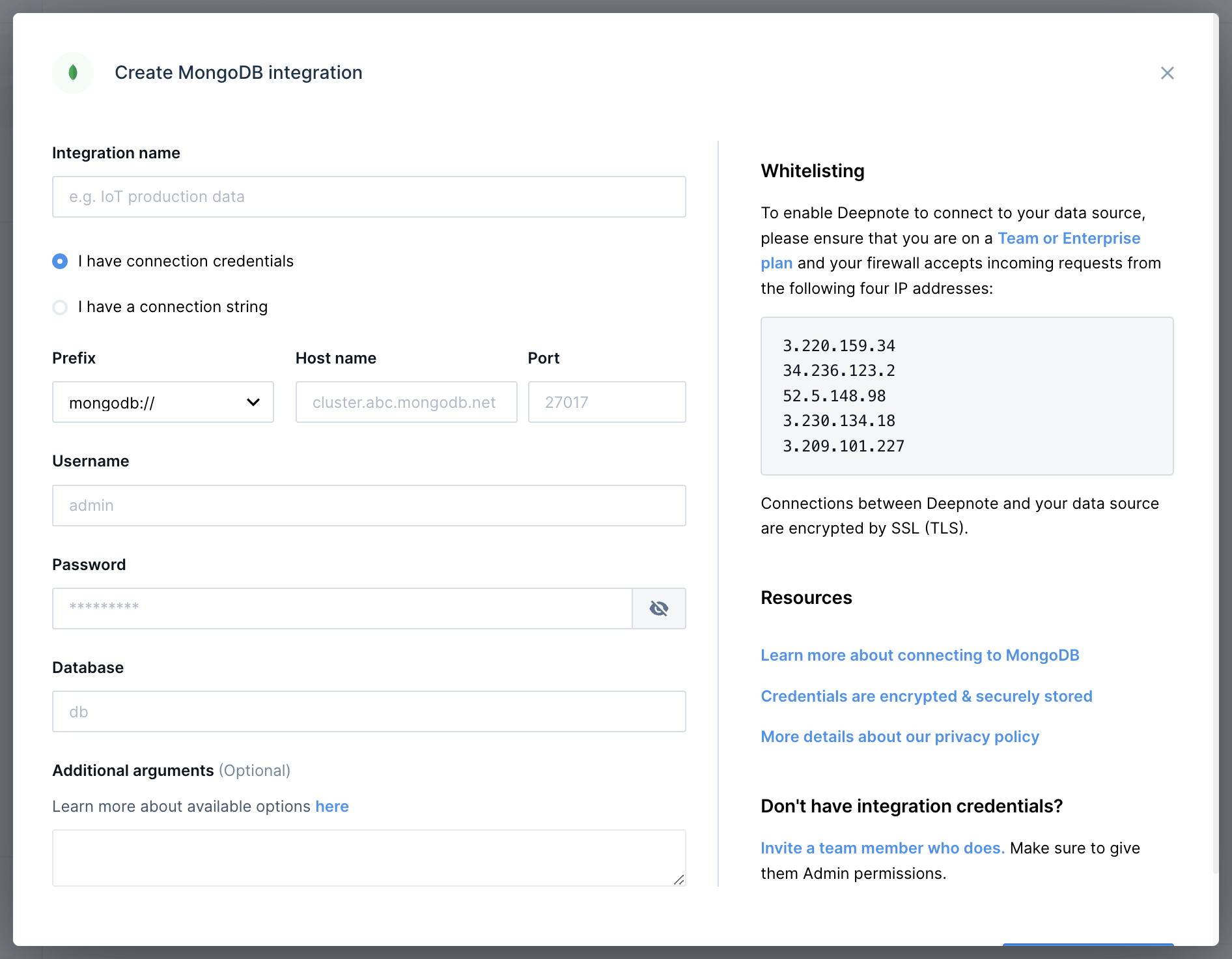
+To add a connection to MongoDB, go to **Integrations** via the left sidebar, create a new MongoDB integration and enter your credentials:
+
+
+
+Don't forget to connect the newly created "MongoDB" integration in the Integrations sidebar.
+
+### Secure connections
+
+Deepnote simplifies connecting to MongoDB via SSH via optional [SSH tunnel integration](/docs/securing-connections?#ssh-tunnel-integration).
+
+#### Troubleshooting SSH connections for MongoDB
+
+If you are encountering the following error
+
+```
+Could not reach any servers in X
+```
+
+try adding `directConnection=true` to the connection URL.
diff --git a/docs/monitoring-machine-learning-models.md b/docs/monitoring-machine-learning-models.md
new file mode 100644
index 0000000000..21042380c1
--- /dev/null
+++ b/docs/monitoring-machine-learning-models.md
@@ -0,0 +1,45 @@
+---
+title: Monitoring machine learning models
+noIndex: false
+noContent: false
+---
+
+Monitoring machine learning models is a crucial aspect of the model lifecycle that ensures their continued performance, reliability, and effectiveness. While tools like Deepnote provide excellent environments for model training and deployment, integrating monitoring practices is essential to maintain model integrity in production. This article explores key aspects of ML model monitoring, tools, and best practices.
+
+## Importance of model monitoring
+
+Once an ML model is deployed, it enters a production environment where real-world data, which may differ significantly from training data, is processed. Monitoring helps detect issues like data drift, model degradation, and performance anomalies, ensuring that models continue to perform as expected. Early detection of these issues is critical for maintaining the trustworthiness and accuracy of predictions, particularly in high-stakes applications such as finance, healthcare, and autonomous systems.
+
+## Key aspects of ML model monitoring
+
+- **Performance Metrics**: Continuously tracking metrics such as accuracy, precision, recall, F1-score, and AUC-ROC helps assess how well the model is performing. Monitoring these metrics over time can reveal trends or sudden drops in performance, signaling potential issues.
+
+- **Data drift**: Data drift occurs when the statistical properties of the input data change over time, potentially rendering the model's predictions less accurate. Monitoring input data distribution and comparing it to the training data distribution can help detect data drift early.
+
+- **Concept drift**: Concept drift refers to changes in the underlying relationship between input data and the target variable. Unlike data drift, which focuses on the input data alone, concept drift affects the actual model behavior. Continuous evaluation of model predictions against true outcomes is essential to detect concept drift.
+
+- **Latency and throughput**: Especially relevant for real-time applications, monitoring the latency (time taken to make a prediction) and throughput (number of predictions made in a given period) ensures the system meets performance requirements.
+
+## Tools for model monitoring
+
+Several tools can be integrated with Deepnote to monitor ML models effectively:
+
+- **TensorBoard**: TensorBoard provides a suite of visualizations and metrics tracking that can be particularly useful during both training and post-deployment monitoring. It helps visualize metrics over time, inspect weights, and understand the model's decision-making process. You can use TensorBoard in Deepnote after [enabling Incoming connections](https://deepnote.com/docs/incoming-connections) to your Deepnote environment.
+- **Weights & Biases**: W&B offers comprehensive tracking of experiments and models, including performance metrics, hyperparameters, and datasets. Its visualization capabilities are useful for tracking model health and detecting anomalies. Learn more about [Weights & Biases in Deepnote](https://deepnote.com/docs/weights-and-biases).
+- **Comet.ml**: Similar to W&B, Comet.ml provides real-time monitoring and logging of metrics, hyperparameters, and experiments. It supports collaboration by allowing teams to share and compare results. Learn more about [Comet.ml in Deepnote](https://deepnote.com/docs/cometml).
+
+- **MLflow**: MLflow is an open-source platform that manages the ML lifecycle, including experimentation, reproducibility, and deployment. Its monitoring capabilities include logging metrics, parameters, and output files, making it easier to track model performance over time.
+
+- **Seldon Core**: For Kubernetes-based deployments, Seldon Core offers monitoring features, including logging and metric tracking, to ensure model reliability and performance in production environments.
+
+## Best practices for model monitoring
+
+Automated Alerts: Implement automated alerts for anomalies in key metrics. This ensures that data scientists and engineers are immediately informed of potential issues.
+
+- **Regular retraining**: Set up a schedule for model retraining, especially if the model's environment is prone to rapid changes. This helps mitigate the effects of data and concept drift.
+
+- **Audit logging**: Maintain comprehensive logs of model inputs, outputs, and decision-making processes. This is crucial for debugging, compliance, and auditing purposes.
+
+- **Cross-validation and A/B testing**: Use cross-validation and A/B testing techniques to validate model updates before full deployment. This reduces the risk of introducing underperforming models into production.
+
+Effective monitoring of machine learning models is vital for maintaining their performance and reliability in production. By integrating monitoring tools with platforms like Deepnote and adhering to best practices, data scientists can ensure that their models continue to deliver accurate and reliable results, thereby sustaining the value they provide to businesses and end-users.
diff --git a/docs/mysql.md b/docs/mysql.md
new file mode 100644
index 0000000000..c94a752055
--- /dev/null
+++ b/docs/mysql.md
@@ -0,0 +1,19 @@
+---
+title: MySQL / MariaDB
+noIndex: false
+noContent: false
+---
+
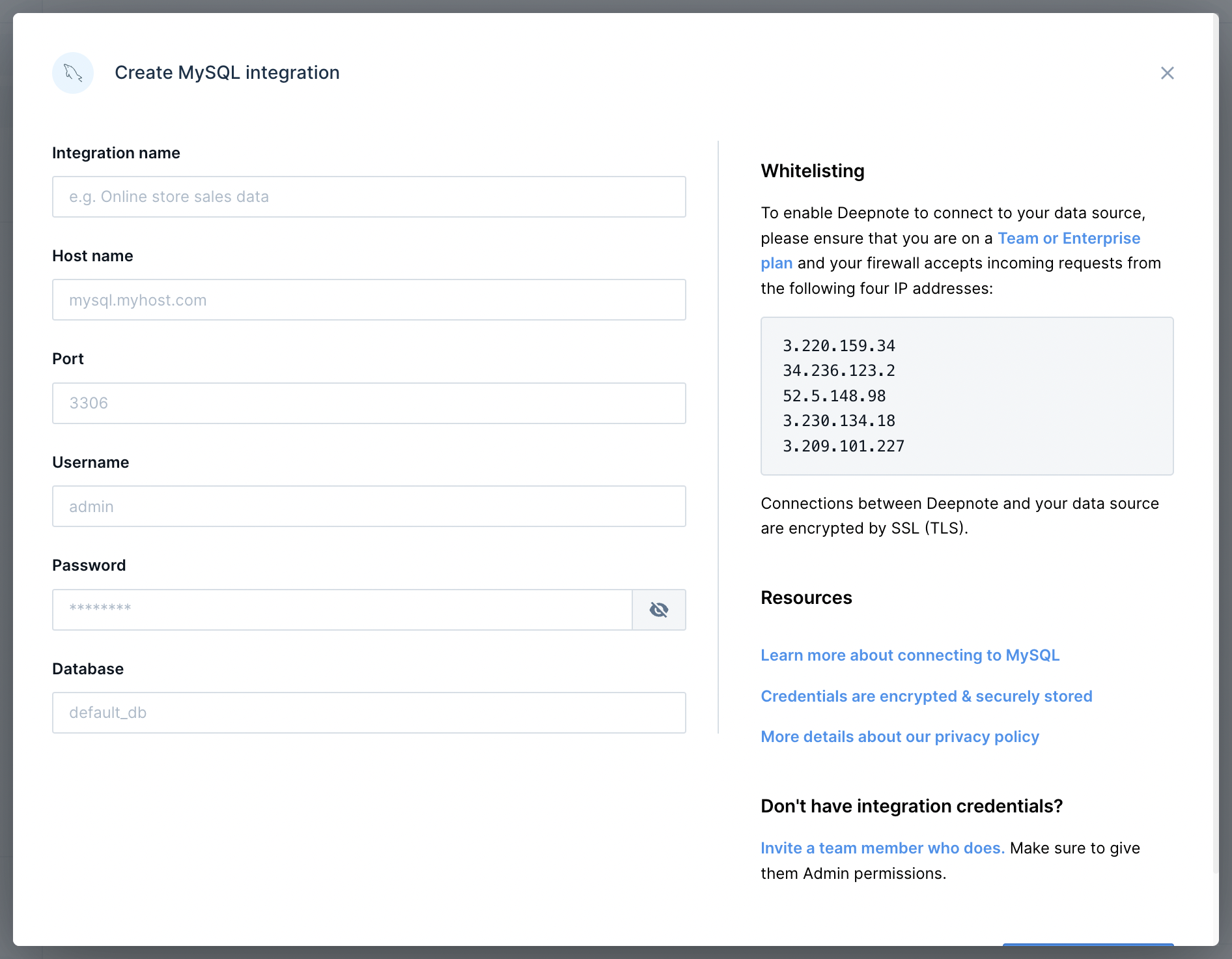
+To add a connection to MySQL or MariaDB, go to **Integrations** via the **right** sidebar, create a new MySQL integration and enter your credentials:
+
+
+
+After that's done, connect the new integration to your project using the Integrations sidebar.
+
+### Usage
+
+The easiest way to query MySQL is to use [SQL cells](/docs/sql-cells).
+
+### Secure connections
+
+Deepnote supports securing connections to MySQL and MariaDB via optional [SSL & SSH tunnels](/docs/secure-connections).
diff --git a/docs/neptuneai.md b/docs/neptuneai.md
new file mode 100644
index 0000000000..05e45c78b9
--- /dev/null
+++ b/docs/neptuneai.md
@@ -0,0 +1,9 @@
+---
+title: Neptune.ai
+noIndex: false
+noContent: false
+---
+
+[Neptune](https://neptune.ai/) is a lightweight experiment management tool that helps you keep track of your machine learning experiments.
+
+To get started with Neptune tracking in Deepnote notebooks, follow [this guide](https://neptune.ai/blog/monitoring-machine-learning-experiments-guide).
diff --git a/docs/notebook-locking.md b/docs/notebook-locking.md
new file mode 100644
index 0000000000..aab0637737
--- /dev/null
+++ b/docs/notebook-locking.md
@@ -0,0 +1,17 @@
+---
+title: Notebook locking
+noIndex: false
+noContent: false
+---
+
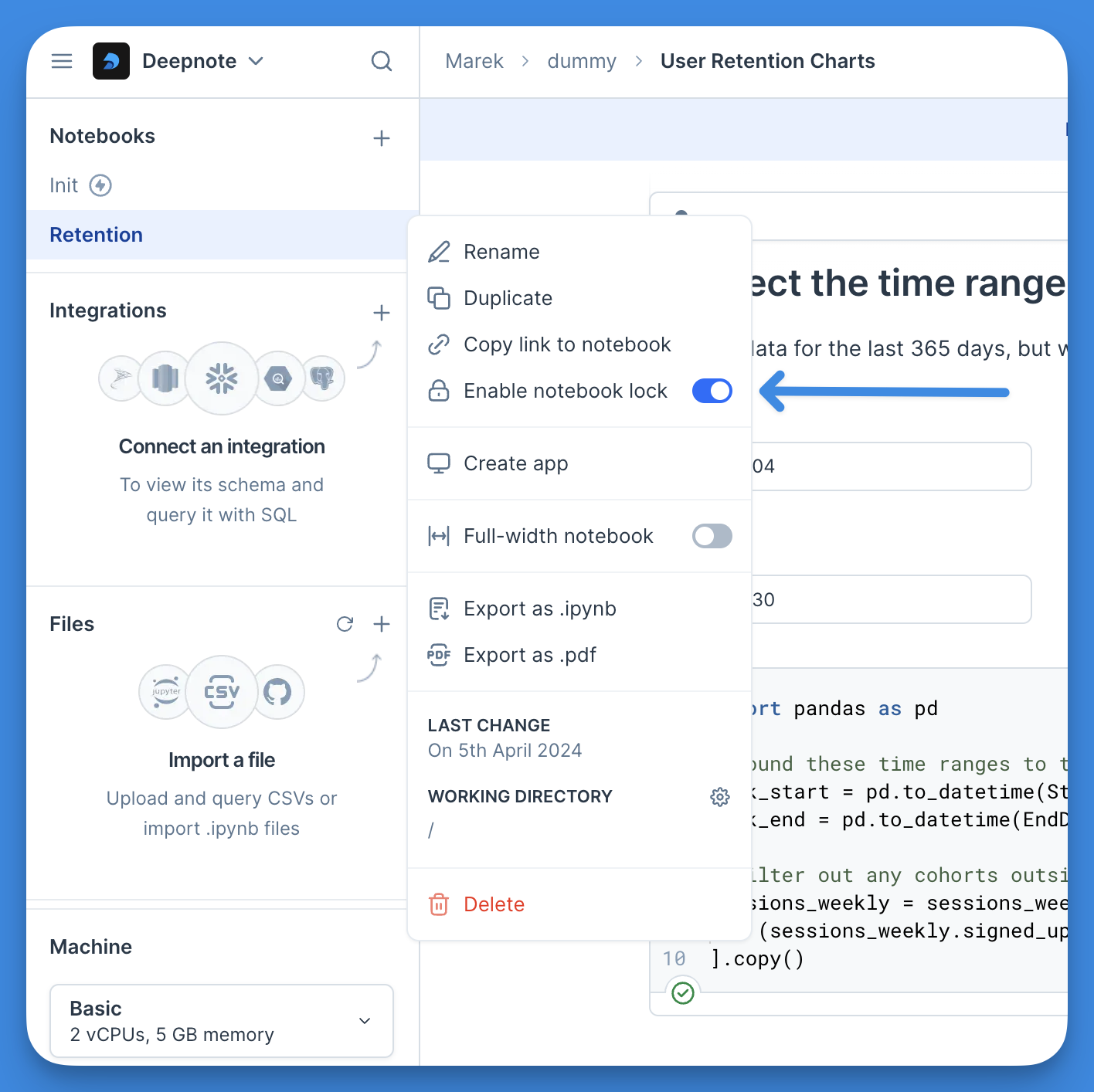
+Accidental edits of notebooks happen, especially when the number of people in your workspace increases. Once a notebook is published as an app or is part of a running pipeline, such unintended changes can have serious consequences. To prevent these accidental edits, you can lock the notebook.
+
+You can enable the notebook lock from the notebook's context menu.
+
+
+
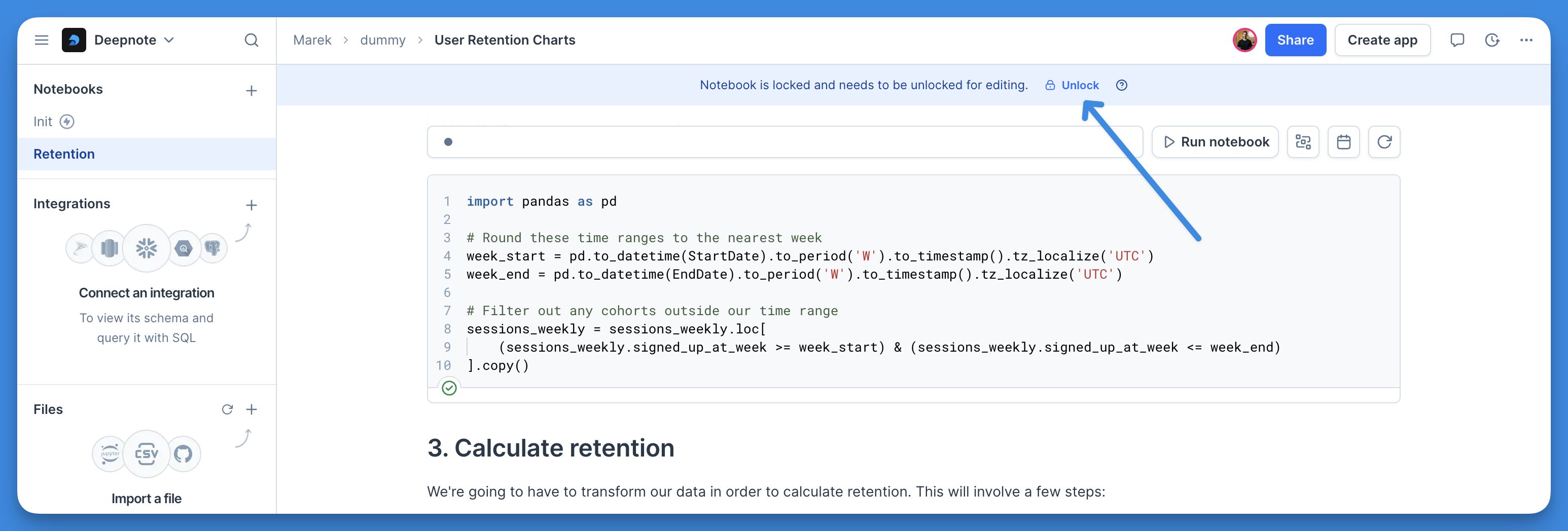
+The content of the locked notebook cannot be edited in any way, but it can still be run, shared, or commented on.
+
+All users who wish to edit the notebook must manually unlock it. The notebook is unlocked only for the specific user, meaning it remains locked for others. The notebook will revert to its locked state once the user navigates away or refreshes the browser.
+
+
diff --git a/docs/notebooks.md b/docs/notebooks.md
new file mode 100644
index 0000000000..9bfef9532f
--- /dev/null
+++ b/docs/notebooks.md
@@ -0,0 +1,48 @@
+---
+title: Notebooks
+description: Notebooks are computational documents that combine code, visualizations, and text. They changed data forever, and they've become even more powerful in Deepnote.
+noIndex: false
+noContent: false
+---
+
+## What is a notebook in Deepnote?
+
+Beyond being a powerful computational medium, Deepnote notebooks are fully collaborative documents. They combine SQL, Python, and no-code tools into an analytics environment suitable for data teams.
+
+### Composing with building blocks
+
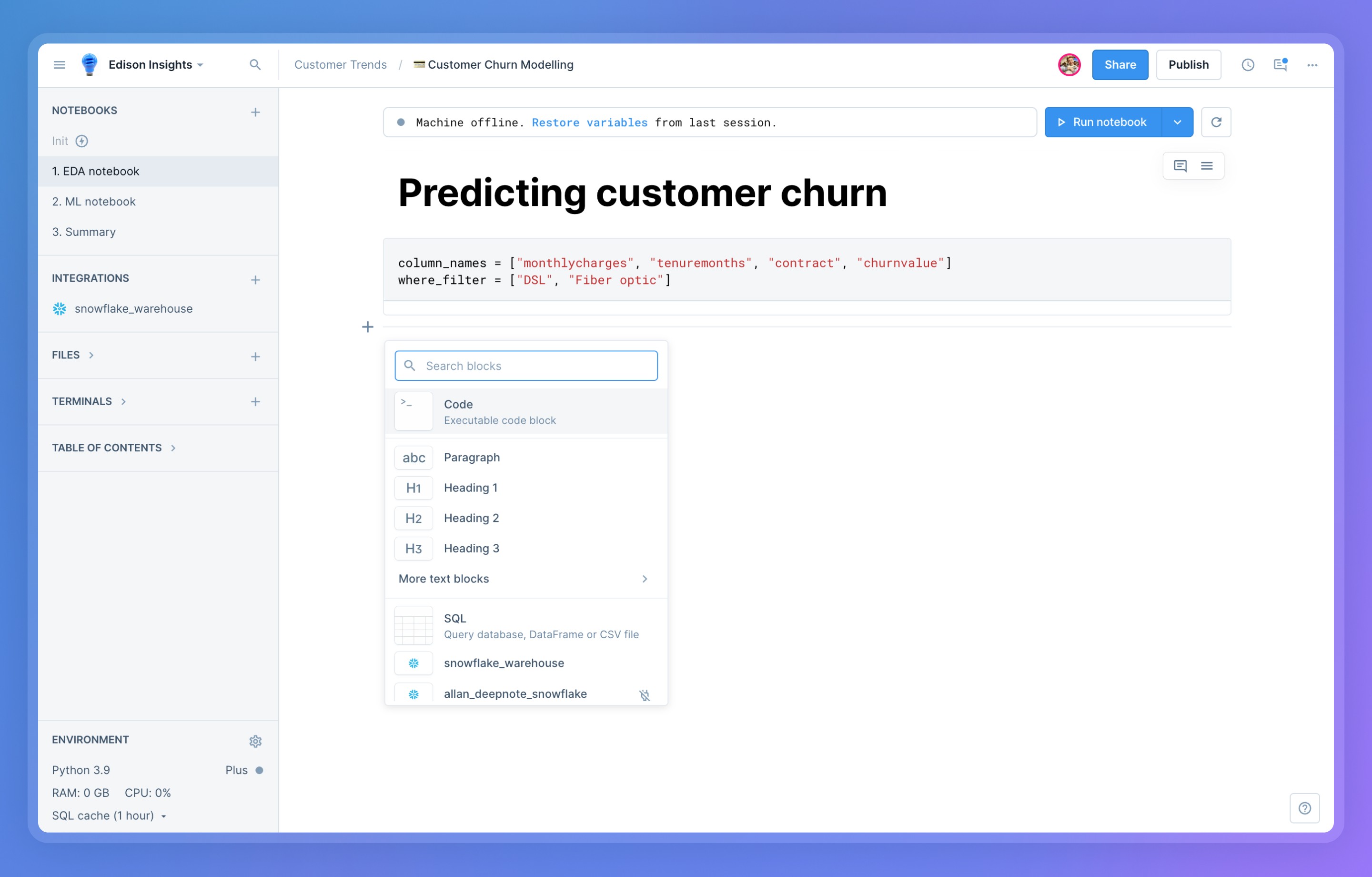
+Notebooks are made up of a series of blocks. Each major type of content or action you can perform has its own block type:
+
+- Code blocks enable you to write and execute Python code (or [other languages](https://deepnote.com/docs/running-your-own-kernel)).
+- [SQL blocks](https://deepnote.com/docs/sql-cells) are used to write SQL queries against databases, pandas DataFrames, and CSV files.
+- [Text blocks](https://deepnote.com/docs/text-editing) allow you to compose richly formatted text.
+- [Chart blocks](https://deepnote.com/docs/chart-blocks) provide you with a point-and-click charting tool for efficient data visualizations.
+- [Input blocks](https://deepnote.com/docs/input-blocks) are interactive widgets that capture user inputs and pass them as variables to your Python code and SQL queries.
+
+Blocks can easily be added to your notebook via the **add block** (**+**) menu or by selecting a block category from the bottom of your notebook.
+
+
+
+### Executing blocks to generate results
+
+In order to see output from your code, you need to execute the corresponding block. You can do this in three ways:
+
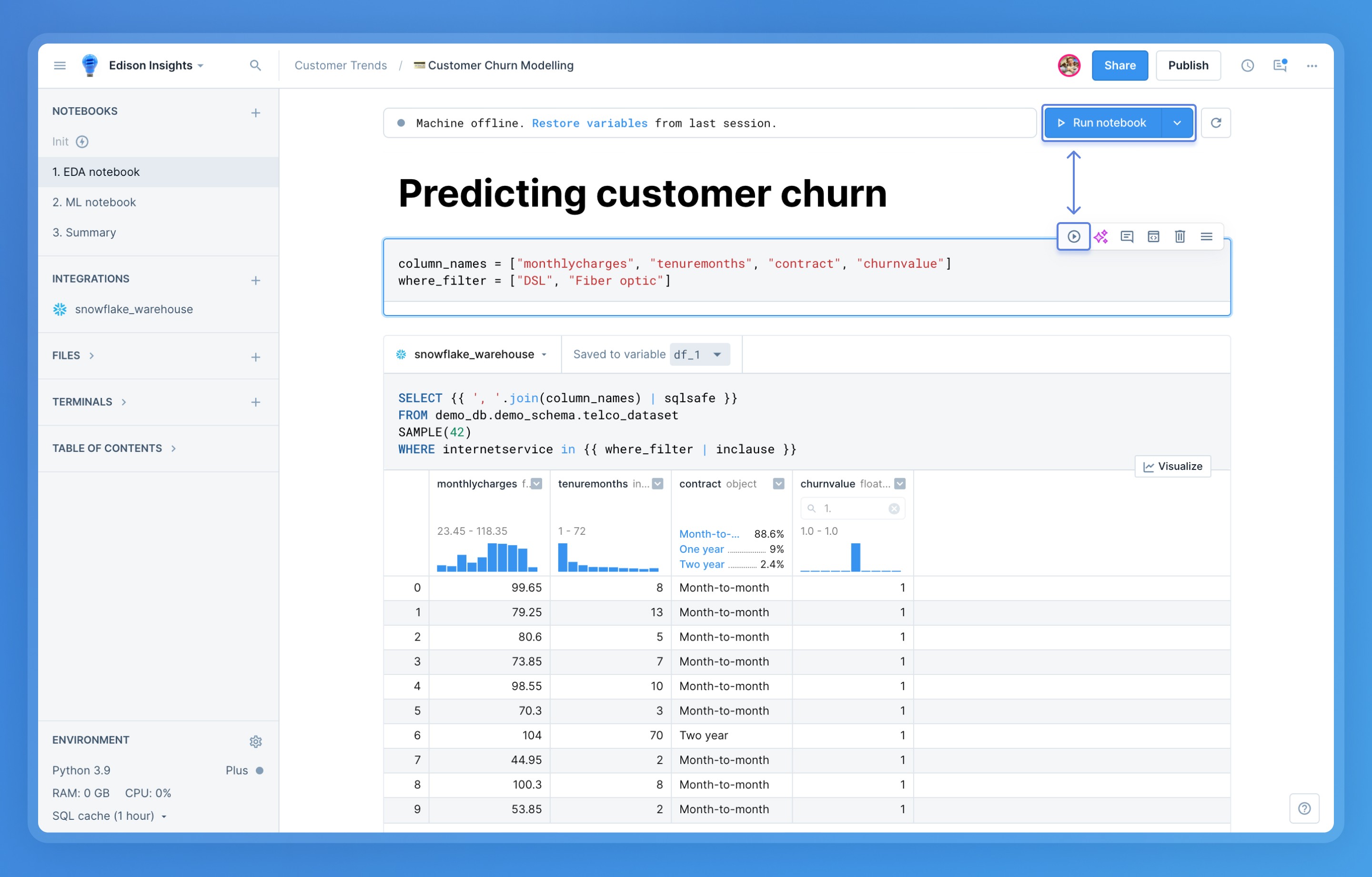
+- Click the **Run notebook** button at the top of the notebook. This will execute all blocks from top to bottom. Execution will stop at any block that produces an error.
+- Click the **Run** button on the block's sidebar menu.
+- Press **Cmd/Ctrl** + **Enter** on your keyboard while focused on a block.
+
+
+
+### Exploring helpful block operations
+
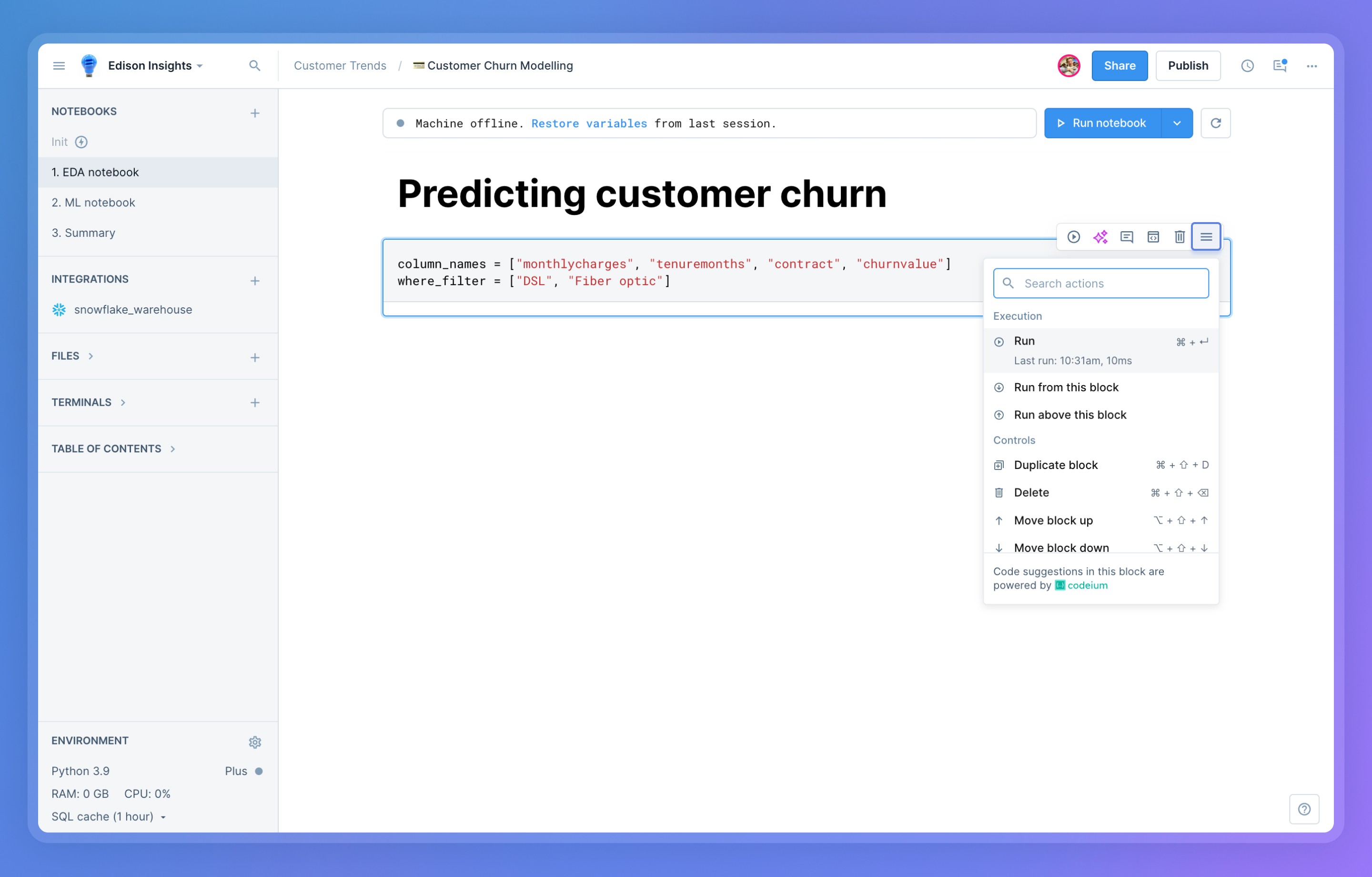
+You can access a set of standard block operations in the block's sidebar menu. Besides executing them, you can also comment, share, and delete blocks. Even more options are available in the **block actions** menu, including duplicating or moving blocks up and down. Options can be specific to the given block type, so it’s always worth exploring this menu.
+
+
+
+### Changing the working directory of a notebook
+
+By default, the working directory of your notebook is the same as the root of the file system in the right sidebar. Its absolute path is `/work`. To change a notebook's working directory, click its context menu, scroll down to **WORKING DIRECTORY** and click the ⚙️ symbol.
+
+
+If you have [imported a Jupyter notebook](https://deepnote.com/docs/importing-and-exporting-jupyter-notebooks) and you want to execute it, make sure you place it in the dedicated **Notebooks** section. Jupyter files that exist in the **Files** section are "read-only."
+
diff --git a/docs/notion.md b/docs/notion.md
new file mode 100644
index 0000000000..5c5168d417
--- /dev/null
+++ b/docs/notion.md
@@ -0,0 +1,88 @@
+---
+title: Notion
+description: Available to teams and users on all plans.
+noIndex: false
+noContent: false
+coverImage: w2F4ok5iRlyQ4maT5G3m
+---
+
+
+**Want to get started right away?** Jump right in and explore [this hands-on example](https://deepnote.notion.site/Bringing-analytics-to-Notion-with-Deepnote-d6ad9e9cf62f4b0ab425eec25c3f8f4b) of querying Notion databases using Deepnote and embedding the results on Notion.
+
+
+Notion is an all-in-one workspace that allows for everything from simple note-taking to building knowledge libraries for entire organizations. Since Notion stores data in databases, you can actually query the data stored in Notion and analyze it using Deepnote. After visualizing your data, you can then go full-circle by bringing the plots back into Notion by embedding your Deepnote blocks into Notion pages.
+
+
+
+### How to set it up
+
+The first step in querying your Notion databases is retrieving your Notion API key and the ID of the database you would like to query. To gather all necessary information, head on over to [Notion's brilliant documentation](https://developers.notion.com/docs/getting-started) that offers a step-by-step walkthrough. To find your database ID, open up the Notion page containing the database and take a look at the URL. It should take the form of `https://www.notion.so/?v=`, where `` is your database ID and `` is the view ID.\
+
+Once you've set up Notion's API, consider storing both the API key and database ID as an [environment variable](/docs/environment-variables). Environment variables in Deepnote are encrypted and provide a secure way of storing sensitive data.
+
+### How to use
+
+#### Query Notion databases
+
+Once you've stored your Notion API key and database ID as environment variables, you can start querying. The code below queries a Notion database and saves it as a Pandas DataFrame that you can then use for further analyses.
+
+```python
+import os
+import requests
+import pandas as pd
+
+# keys are stored in env vars to be hidden from users
+api_key = os.environ["NOTION_API_KEY"]
+database_id = os.environ["DATABASE_ID"]
+
+# define request to Notion API
+headers = {
+ "Authorization": f"Bearer {api_key}",
+ "Notion-Version": "2021-08-16",
+ "Content-Type": "application/json",
+}
+
+# load first page
+response = requests.post(
+ f"https://api.notion.com/v1/databases/{database_id}/query", headers=headers
+).json()
+
+# iteratively load all pages
+records = response["results"]
+while response["has_more"]:
+ response = requests.post(
+ f"https://api.notion.com/v1/databases/{database_id}/query",
+ json={"start_cursor": response["next_cursor"]},
+ headers=headers,
+ ).json()
+
+# define a helper function to transform the JSON to a Pandas DF
+def get_raw_value(item):
+ item_type = item['type']
+ if type(item[item_type]) is list:
+ if item[item_type][0]['type'] == 'text':
+ return item[item_type][0]['plain_text']
+ return item[item_type]
+
+# create Pandas DF
+all_values = []
+for record in records:
+ properties = record['properties']
+ all_values.append({
+ 'Name': get_raw_value(properties['Name']),
+ 'Total': get_raw_value(properties['Total']),
+ })
+
+df = pd.DataFrame(all_values)
+df
+```
+
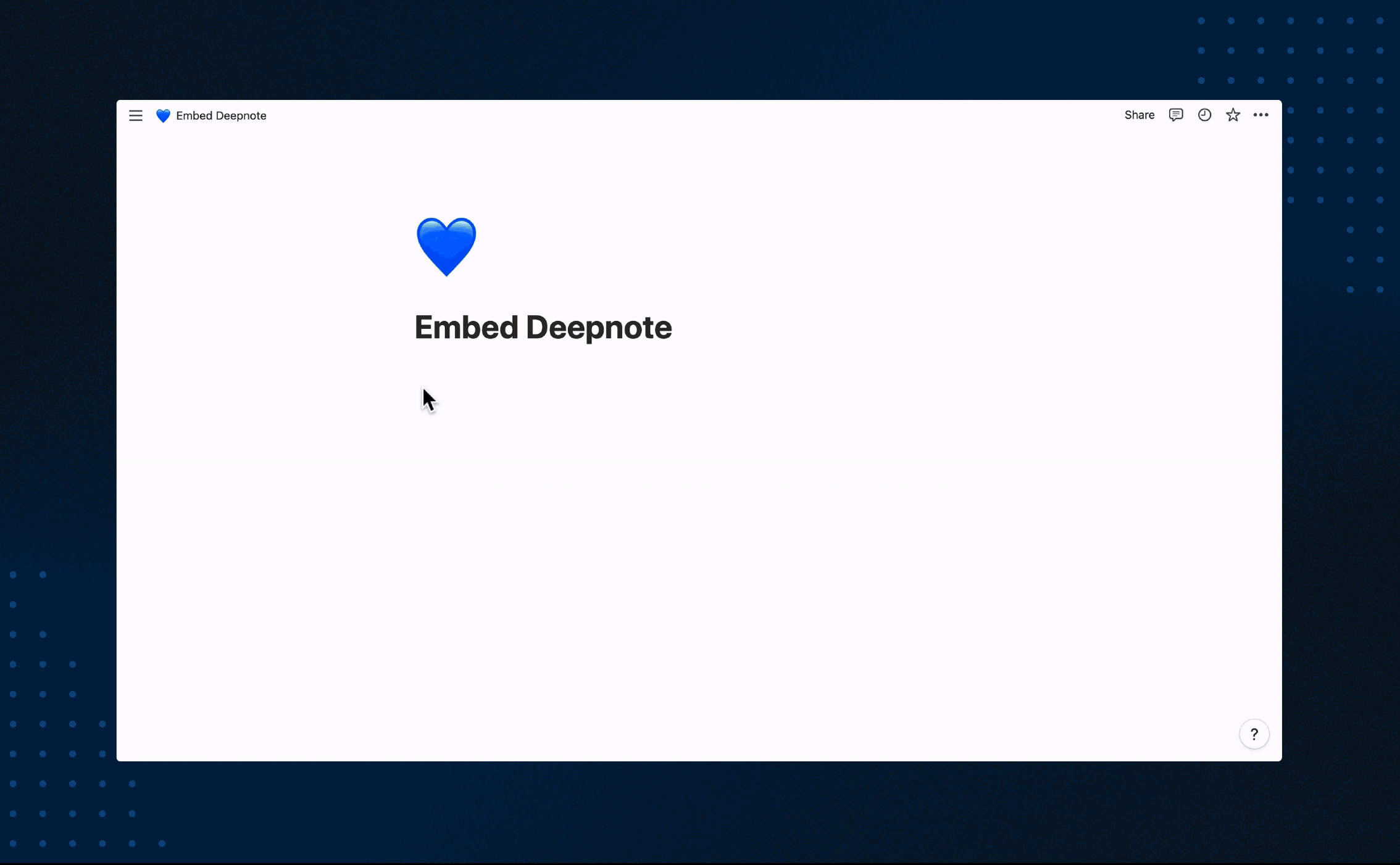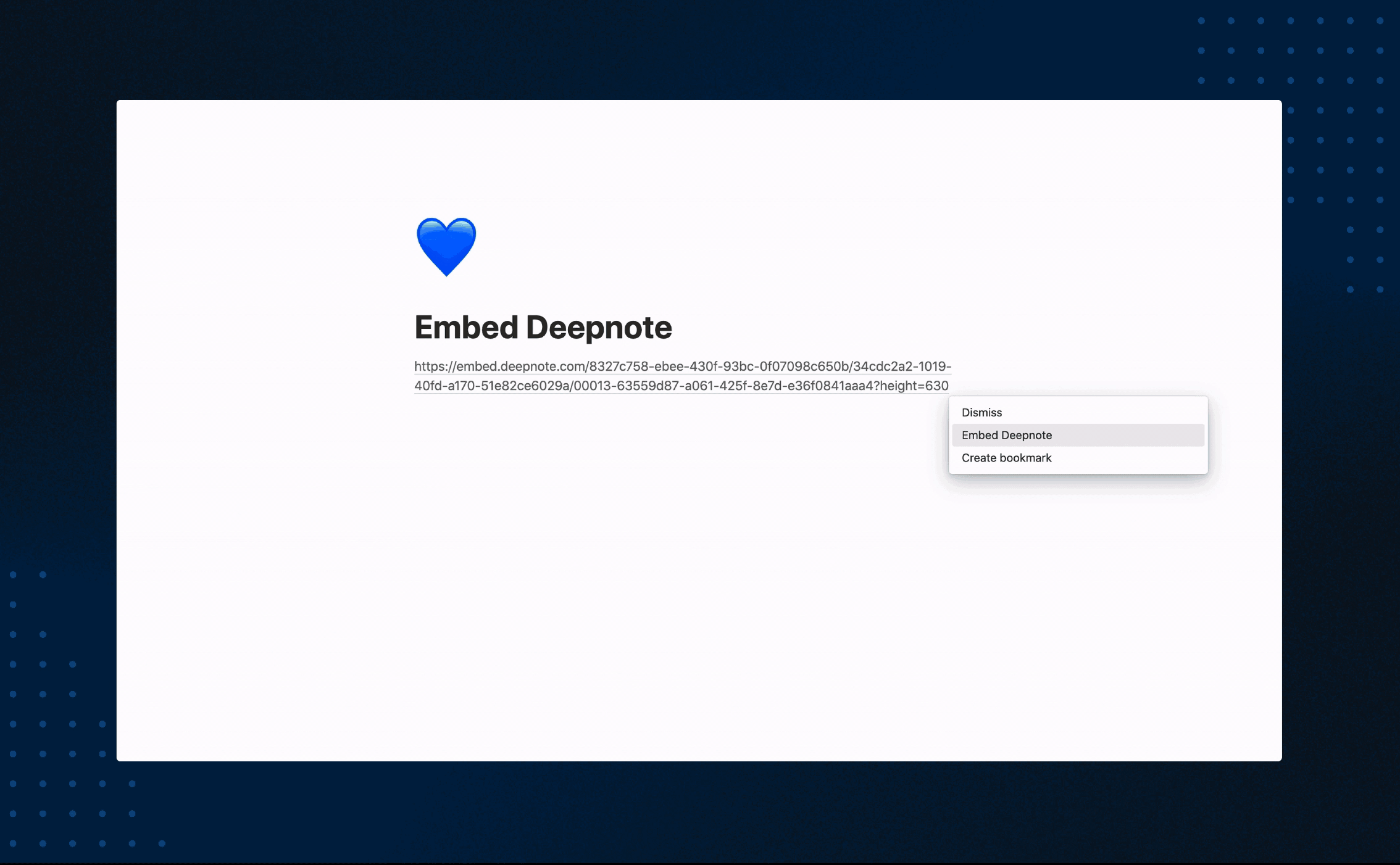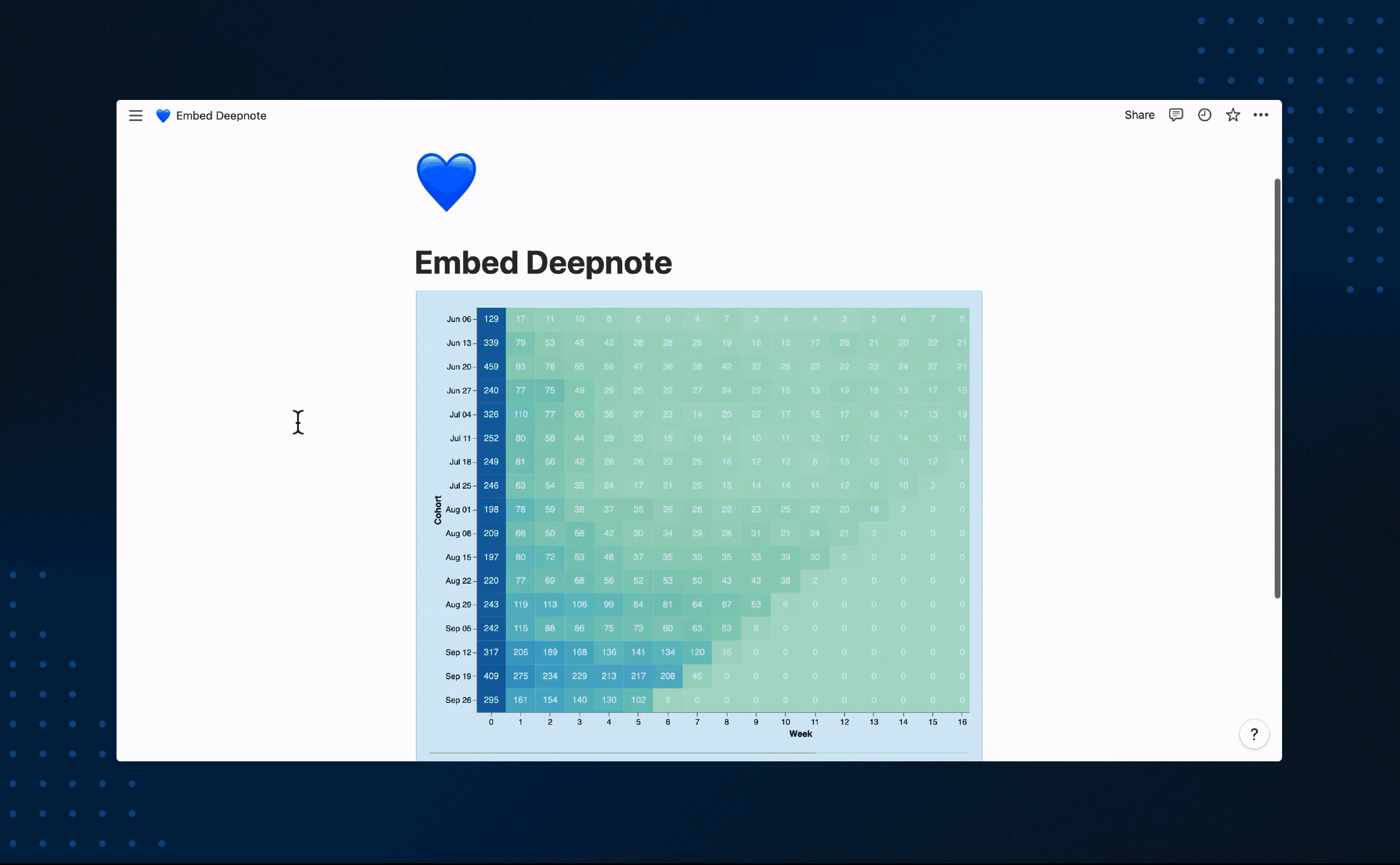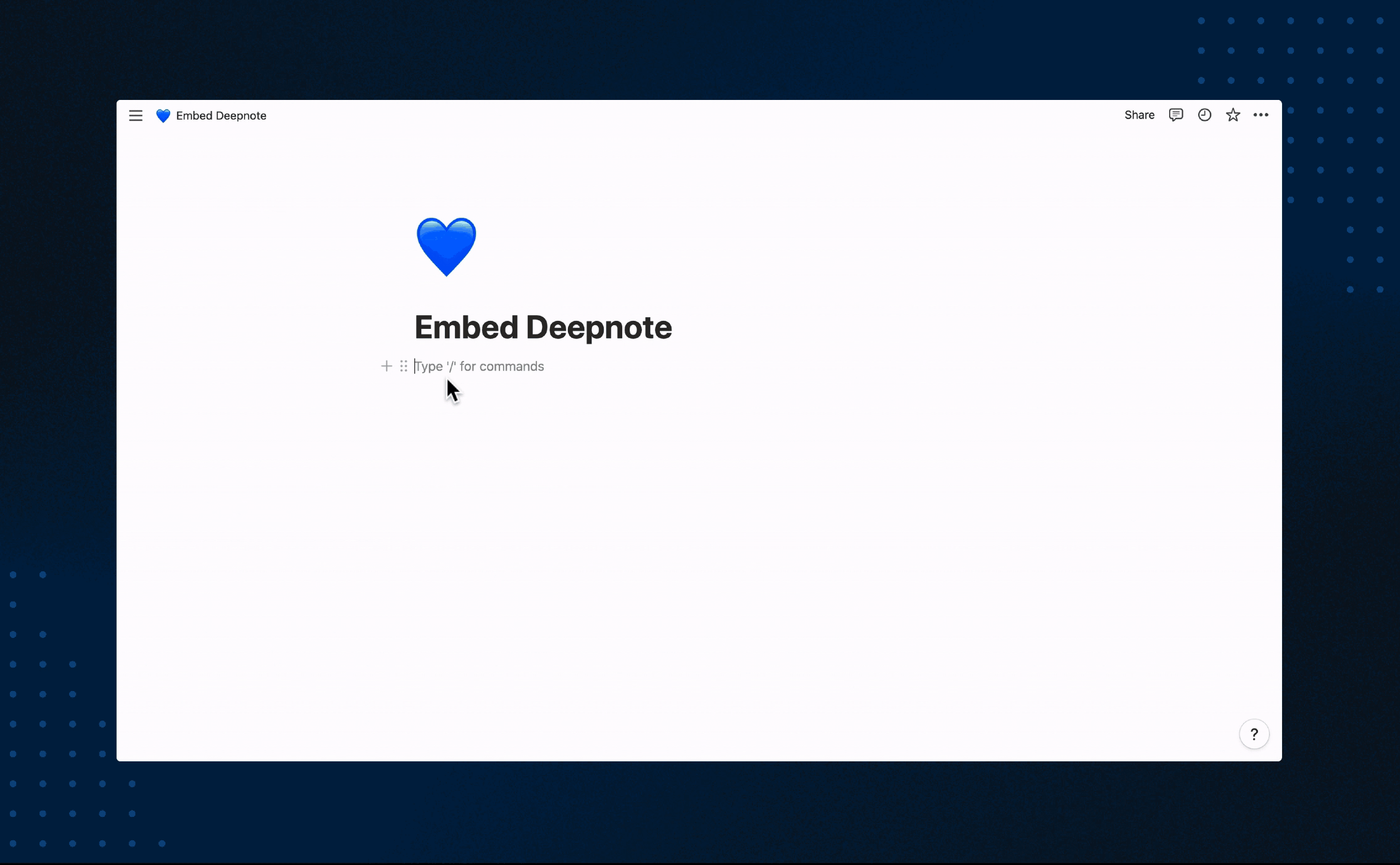
+#### Embed Deepnote blocks into Notion pages
+
+After reading your Notion databases, performing analyses using the data, and creating visualizations, you might want to bring your Notion blocks back into Notion. That's where [shared blocks](/docs/sharing-and-embedding-blocks) come into play. Deepnote allows for the sharing and embedding of individual blocks. It's up to you whether you want to include the code and output or only one of the two.
+
+
+
+### Next steps
+
+Jump right in and explore [this hands-on example](https://deepnote.notion.site/Bringing-analytics-to-Notion-with-Deepnote-d6ad9e9cf62f4b0ab425eec25c3f8f4b) of querying Notion databases using Deepnote and embedding the results on Notion. You can also save yourself some setup work by copying the workflow used in the example to start querying your own Notion databases!
diff --git a/docs/onedrive.md b/docs/onedrive.md
new file mode 100644
index 0000000000..d6029958e5
--- /dev/null
+++ b/docs/onedrive.md
@@ -0,0 +1,40 @@
+---
+title: Microsoft OneDrive
+noIndex: false
+noContent: false
+coverImage: 2WgnsVCRS8esbCqGc2lO
+---
+
+Deepnote can fetch files from OneDrive, for example, Excel files that you collaborate on with your team. Follow these docs to create your own notebook to pull files from OneDrive, query data, and visualize it.
+
+### 1. Duplicate the OneDrive template
+
+[Open the template by following this link ->](https://deepnote.com/workspace/Deepnote-Templates-71742312-24f2-4c10-9bf7-786d17280b92/project/Fetch-OneDrive-files-in-Deepnote-7c6d212e-b26d-48ca-a3d0-fcd63f888999/%2Fnotebook.ipynb)
+
+
+
+Click the "duplicate" button on the top right corner to do this. Once you've got the template in your Deepnote workspace, you can download files from OneDrive.
+
+### 2. Share files with Deepnote from OneDrive
+
+You need to create a public sharing link so Deepnote can download the file. [Follow these instructions from Microsoft](https://support.microsoft.com/en-us/office/create-a-shareable-link-8257f6da-d5db-4207-a654-925644e3f35c) making sure that anyone with the link can at least **view** the file.
+
+Change the variable `ONEDRIVE_SHARE_LINK` in the notebook to link to the file you just made.
+
+### 3. Fetch OneDrive files from Deepnote
+
+The template notebook has a function called `get_onedrive_download`, which takes a share link and creates a URL that will download that file directly. You can use a library like `requests` to fetch the file or pass it to `pandas` to read a CSV or Excel file directly. In the below example, the shared file is an Excel file.
+
+```python
+ONEDRIVE_SHARE_LINK = "https://1drv.ms/x/s!AjP7y6eiYDDSafV7BusEaDHrI0o?e=cL0Fqi"
+df = pd.read_excel(get_onedrive_download(ONEDRIVE_SHARE_LINK))
+df
+```
+
+When executing the code above, Deepnote will visualize the output DataFrame, as we see in the example below.
+
+
+
+### What's next?
+
+Now that you're querying data, you can share it with your team. You can even turn your charts [into a shareable dashboard](/docs/publish-projects).
diff --git a/docs/postgresql.md b/docs/postgresql.md
new file mode 100644
index 0000000000..1aa1c6ab3a
--- /dev/null
+++ b/docs/postgresql.md
@@ -0,0 +1,77 @@
+---
+title: PostgreSQL
+noIndex: false
+noContent: false
+---
+
+## Setup
+
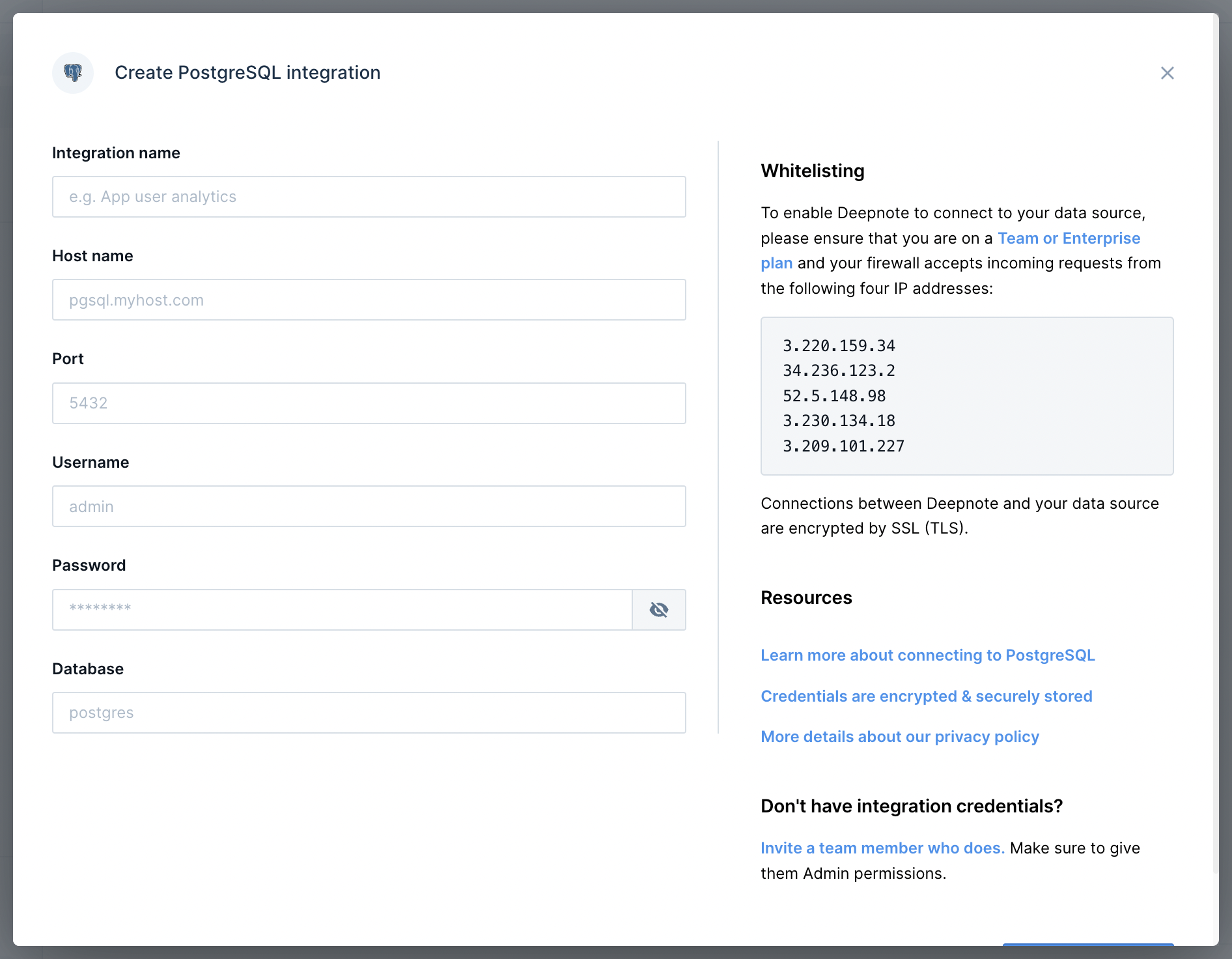
+To add a connection to PostgreSQL, go to **Integrations** via the **right-hand sidebar**, create a new PostgreSQL integration and enter credentials:
+
+
+
+Don't forget to connect the newly created "PostgreSQL" integration in the Integrations sidebar.
+
+### Authorizing Deepnote's IP addresses for security reasons
+
+
+If your connection is protected, you might need to add Deepnote's IP addresses to your allowlist. [Read more here](/docs/authorize-deepnote-ip-addresses)
+
+
+## Usage
+
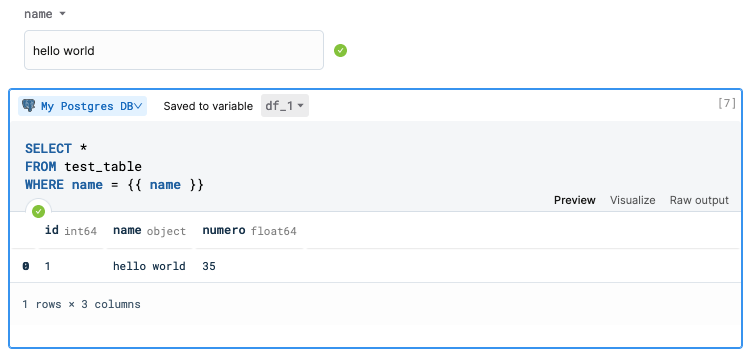
+The fastest way to query your connected postgres database is to use a [SQL cell](/docs/sql-cells). You can create one by clicking "+ Block" or at the bottom of a notebook.
+
+
+
+A text input cell and a SQL cell work together
+
+## Advanced usage
+
+Alternatively, if you want to use python to access the database, access the connection details via environment variables with a common prefix that's generated from the name of your Postgres integration:
+
+- `_HOST`
+- `_DATABASE`
+- `_PORT`
+- `_USER`
+- `_PASSWORD`
+
+Then you'll be able to connect to a database like this:
+
+```python
+import psycopg2
+import os
+
+try:
+ connection = psycopg2.connect(
+ user=os.environ["MY_INTEGRATION_USER"],
+ password=os.environ["MY_INTEGRATION_PASSWORD"],
+ host=os.environ["MY_INTEGRATION_HOST"],
+ port=os.environ["MY_INTEGRATION_PORT"],
+ database=os.environ["MY_INTEGRATION_DATABASE"])
+
+ with connection.cursor() as cursor:
+ cursor.execute("SELECT version();")
+ record = cursor.fetchone()
+ print("You are connected to - ", record)
+
+except (Exception, psycopg2.Error) as error:
+ print ("Error while connecting to database", error)
+```
+
+You can now use `connection` and `connection.cursor()` like shown in example above to run queries against the database. Here's how you can run a query and see its output:
+
+```python
+import pandas as pd
+
+query = """
+SELECT *
+FROM users
+"""
+df = pd.io.sql.read_sql_query(query, connection)
+df
+```
+
+### Secure connections
+
+PostgreSQL supports [SSL & SSH connections](/docs/secure-connections).
diff --git a/docs/pre-installed-packages.md b/docs/pre-installed-packages.md
new file mode 100644
index 0000000000..fa98e2eb2e
--- /dev/null
+++ b/docs/pre-installed-packages.md
@@ -0,0 +1,39 @@
+---
+title: Pre-installed packages
+noIndex: false
+noContent: false
+---
+
+Deepnote provides key data analytics and ML Python libraries off the shelf, in the most recent version. All you have to do is import them into your project.
+
+#### The current list of pre-installed packages:
+
+- `agate`
+- `arrow`
+- `datascience`
+- `dill`
+- `fiona`
+- `jsonify`
+- `keras`
+- `matplotlib`
+- `nltk`
+- `numpy`
+- `pandas`
+- `psycopg2-binary`
+- `requests`
+- `scikit-learn`
+- `scipy`
+- `scrapy`
+- `seaborn`
+- `six`
+- `spacy`
+- `squarify`
+- `sympy`
+- `tabulate`
+- `tensorflow`
+- `textblob`
+- `torch`
+- `torchvision`
+- `urllib3`
+
+Click [here](/docs/python-requirements) to learn how to install packages in Deepnote.
diff --git a/docs/pricing.md b/docs/pricing.md
new file mode 100644
index 0000000000..60529f14dc
--- /dev/null
+++ b/docs/pricing.md
@@ -0,0 +1,43 @@
+---
+title: Plans and billing
+description: Questions & answers about plans and pricing
+noIndex: false
+noContent: false
+---
+
+Deepnote currently offers 3 plans: Free, Team, and Enterprise. You can read more about the features of each plan on our [Pricing page](https://deepnote.com/pricing).
+
+###### **How do I upgrade my plan?**
+
+You can upgrade or downgrade your plan from the Plans page in your workspace settings. If you need to upgrade to the Enterprise plan, you can schedule a quick chat with our customer success team here.
+
+###### **How much will I be charged when I upgrade**
+
+When you upgrade to a paid plan, you will be charged per editor and admin seat in your workspace. For example, if you have 1 Admin seat and 4 Editor seats, you will be charged for 5 total seats. You will not be charged for other roles, such as Viewers.
+
+###### **Can I still add or remove seats in my workspace after upgrading?**
+
+Yes! While on a paid plan, you can add or remove Editor/Admin seats at any time. At the start of the next subscription period, you will be billed for the number of Editor/Admin seats present at the time of billing. If you are on annual billing, you will be charged for the added seats a prorated price for remaining time of the annual billing period. All charges when adding new seats are billed when the added users accept the invites.
+
+_Example 1_: You created a workspace with 1 admin and 3 editors on the 1st of the month. On the 15th, you added 3 more editors. On the 1st of the next month, you will be charged for 1 admin and 6 editors.
+
+_Example 2_: You created a workspace with 1 admin and 3 editors on January 1st 2023 and selected yearly billing. At the beginning of the year, you paid for 4 seats. In June, you decided to add 1 more editor. When the new editor accepted your invite, your card was charged for the remaining 6 months for this user. On January 1st 2024 you will be charged for 5 seats. If you decide to remove one of the members at any point during the annual period, the seat that you paid for will stay available for anyone else to join. If you then add a new editor again, you will not be charged during the current billing period.
+
+###### **How do I downgrade or cancel my plan?**
+
+You can downgrade or cancel your plan from the Plans page in your workspace settings. Once you downgrade, you will receive a refund for any unused days.
+
+###### **Will I receive a refund if I downgrade or cancel my plan?**
+
+If you remove a paid seat, we won’t issue a prorated refund. However, someone else at your company can use their paid seat when it becomes available.
+If you downgrade or cancel your subscription, we will refund you a prorated amount for any unused days of the month. For example, if you cancel your subscription 15 days into the billing period, we will refund you 50% of the amount you were charged.
+
+###### **Do you offer any plans or discounts for schools and NGOs?**
+
+Members of educational institutions, such as students, teachers, and researchers, are all eligible for our Education plan. The Education plan has almost all the same features of the Team plan, except that it’s completely free! To find out more about the Education plan, visit our website and sign up with your educational email.
+
+
+
+Are you part of another community and don’t have an academic email? You might still qualify for the Education plan. [Get in touch with us](mailto:help@deepnote.com).
+
+
diff --git a/docs/product-portal.md b/docs/product-portal.md
new file mode 100644
index 0000000000..1649230b29
--- /dev/null
+++ b/docs/product-portal.md
@@ -0,0 +1,8 @@
+---
+title: Product portal
+description: See what Deepnote has launched, what is coming soon, and vote on new features.
+noIndex: false
+noContent: false
+---
+
+[Check out our product portal](https://portal.productboard.com/deepnote).
diff --git a/docs/project-initialization.md b/docs/project-initialization.md
new file mode 100644
index 0000000000..474e975e16
--- /dev/null
+++ b/docs/project-initialization.md
@@ -0,0 +1,32 @@
+---
+title: Project initialization
+noIndex: false
+noContent: false
+---
+
+Deepnote provides an optional feature to run custom Python initialization code every time your project hardware boots up. To utilize this capability, you will need to **include an 'Init' notebook** in your project.
+
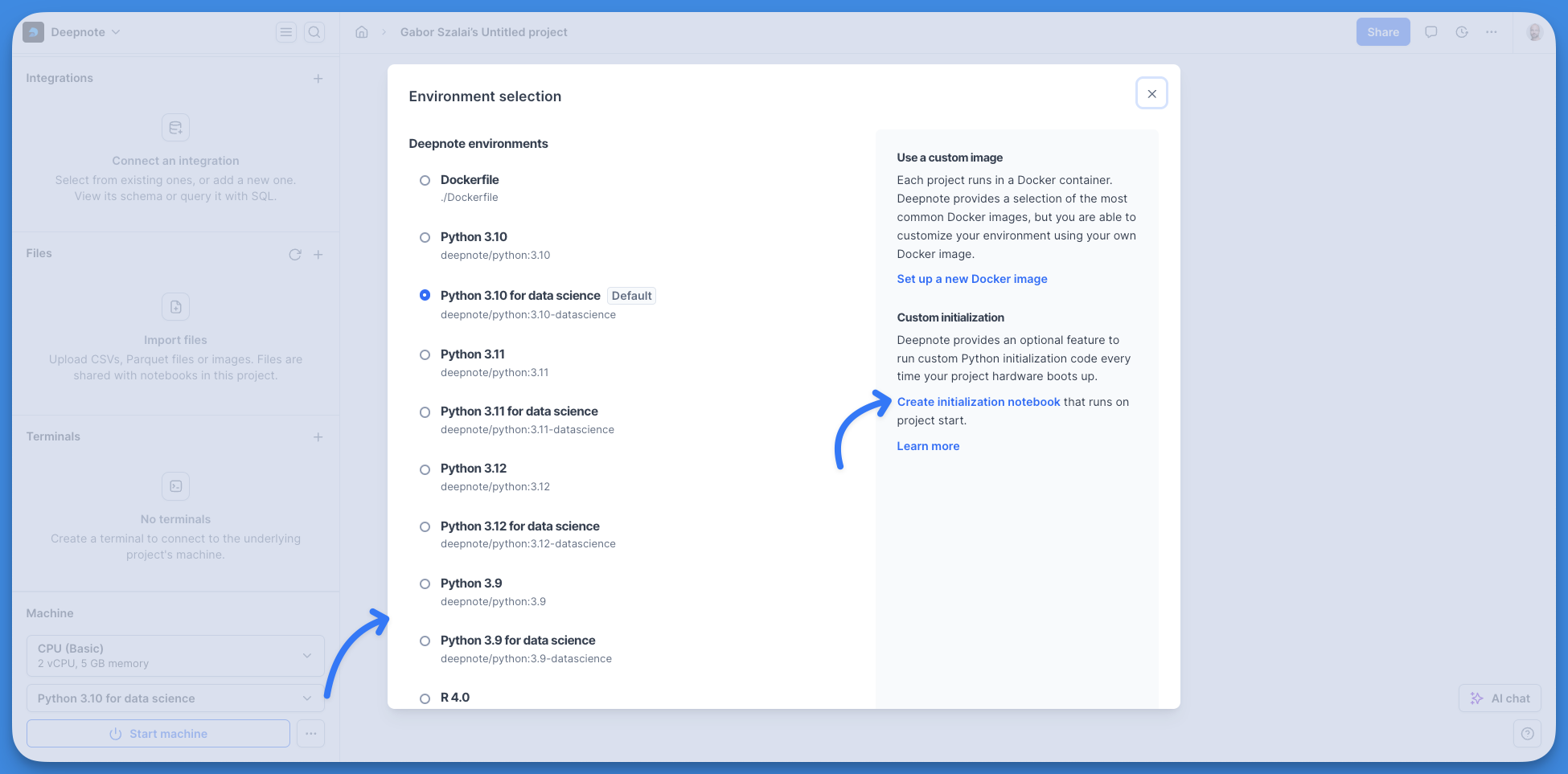
+To create an 'Init' notebook:
+
+- Click on the **Environment** selector in the project sidebar.
+- Click on the **Create an initialization notebook** button at the **Custom initialization** section on the right.
+
+
+
+Alternatively, you can also simply create a new notebook by pressing the plus button in your Notebook list and name it as 'Init'.
+
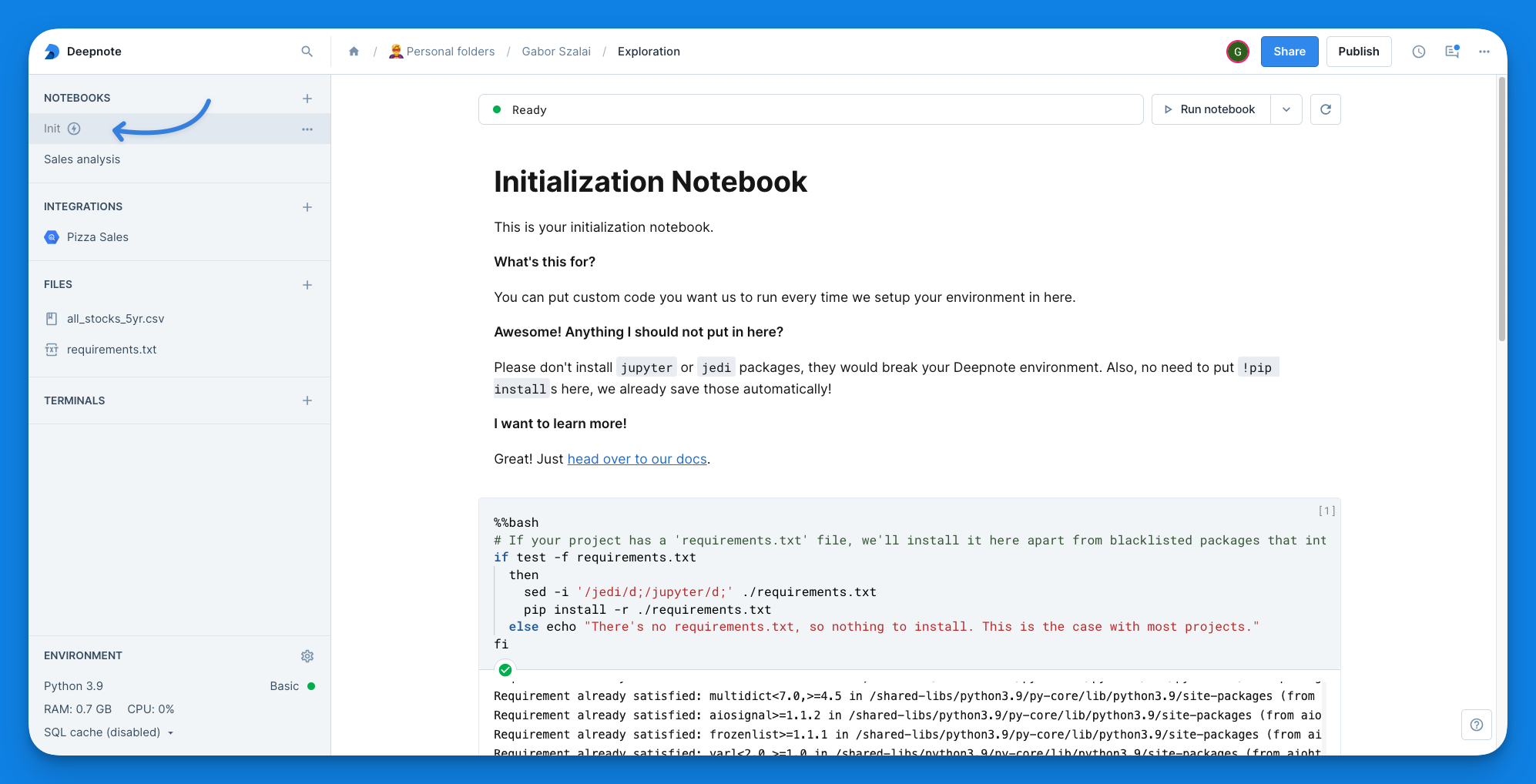
+After creating it, the 'Init' notebook will be conveniently located at the top of your Notebook list.
+
+
+
+The contents of this notebook will automatically execute each time your project starts up, providing an ideal place to set up your preferred environment.
+
+Please note: the 'Init' notebook will only act as an initialization notebook if it's called '**Init**' and it is marked by the configuration notebook symbol (lightning icon). For instance, if you create a notebook called 'init', that won't be automatically run at project startup.
+
+By default, the 'Init' notebook installs any packages listed in ./requirements.txt. This provides a convenient option to ensure you have all package dependencies ready. However, you are free to add any other code into the 'Init' notebook according to your project's needs.
+
+
+
+**There are 2 packages on the disallowlist:** `jupyter` and `jedi`. These are packages that interfere with the way Deepnote works and their installation would break your environment. In the 'Init' notebook , we scan the requirements files for those packages and skip their installation if they are there.
+
+
diff --git a/docs/projects.md b/docs/projects.md
new file mode 100644
index 0000000000..82ff58237a
--- /dev/null
+++ b/docs/projects.md
@@ -0,0 +1,90 @@
+---
+title: Projects
+description: You have a very specific task that requires a coding environment, notebooks, and data. That's where projects come in — a collaborative container for everything you need to complete your analysis.
+noIndex: false
+noContent: false
+---
+
+## What can you do with projects?
+
+Projects do a lot, from shared data sources across multiple notebooks to native version control. Here are some highlights:
+
+- Projects contain notebooks and therefore can be used to organize related work (e.g., EDA notebook, ML notebook)
+- Projects define your environment — including the Python version, required libraries, and the machine specifications (i.e., RAM, number of cores).
+- Projects have their own file system and provide access to database integrations.
+
+### Creating a project
+
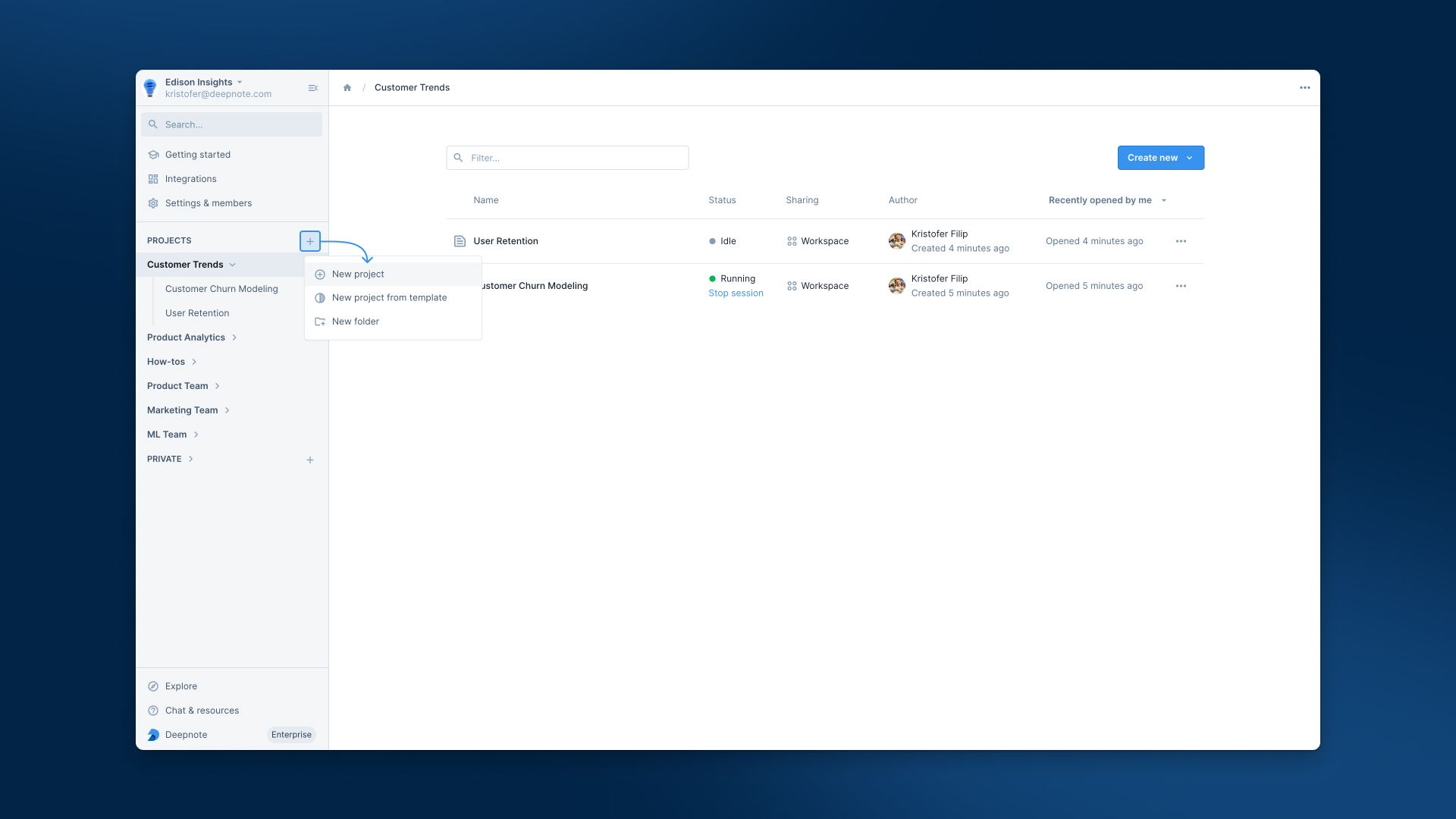
+From the left panel in your Workspace, you can click the **"+"** symbol next to **PROJECTS** to create a new project, either from scratch or from Deepnote's built-in templates. In addition, clicking on the ellipses beside a project will provide options for creating, duplicating, and moving projects (and more).
+
+Don't forget that you can arrange your projects into folders here, too. Just drag and drop them to suit how you like to organize your work.
+
+
+
](PROJECT_URL)
+```
diff --git a/docs/lectures.md b/docs/lectures.md
new file mode 100644
index 0000000000..9aa8c3428f
--- /dev/null
+++ b/docs/lectures.md
@@ -0,0 +1,19 @@
+---
+title: Lectures
+noIndex: false
+noContent: false
+---
+
+Deepnote helps you bring lectures to life by allowing you to create interactive, dynamic lessons that engage and challenge your students. With Deepnote, you can easily incorporate code examples, interactive exercises, and visualizations into lectures, which helps students better understand complex concepts and ideas.
+
+Deepnote's cloud-based workspace means that students can access and work on lectures from anywhere, on any device, at any time. This can be particularly helpful for students who may not have access to a traditional classroom setting or who may need to review material on their own time.
+
+With a wide range of cell types at your disposal — including Markdown, headings, text, charts, sliders, and code — you can easily transform your entire curriculum into interactive lectures.
+
+And with Deepnote's workspaces and access control system, distributing your materials to your students is a breeze. Simply invite them as Viewers to your lecture workspace and allow them to duplicate the project in their own personal workspace for easy access and review.
+
+
+ Deepnote tip: Utilize our duplication feature when distributing your learning curriculum among your entire classroom.
+
+
+
diff --git a/docs/long-running-jobs.md b/docs/long-running-jobs.md
new file mode 100644
index 0000000000..67f6cbe046
--- /dev/null
+++ b/docs/long-running-jobs.md
@@ -0,0 +1,58 @@
+---
+title: Long-running jobs
+noIndex: false
+noContent: false
+---
+
+Deepnote is designed to support most data analysis workflows, many of which include long-running tasks. This page explains when the hardware for your projects can be turned off.
+
+### What it means for Deepnote to turn off the hardware for a project
+
+Simplifying a little bit, Deepnote has many machines (computers) running in the cloud (pods in a Kubernetes cluster if you want the real jargon). When you start the hardware in your project, we turn on one of these machines for you and run all your computations there. Once you're done with your computations, we turn off this machine for you just like you would turn off your own laptop at the end of your workday. Unlike with your laptop though, you can view the notebooks and files in your project even while the hardware for your project is turned off – you only need running hardware to execute computations. We automatically start this hardware whenever you start any execution in your project (e.g. when you run a block).
+
+After the hardware notebook is turned off, we store the outputs of cells, but the values of variables are gone (just like when you turn off your computer).
+
+To start your hardware back up after we turn off the hardware for your project, run any cell or click "Start machine" in the environment sidebar.
+
+### Automatic machine shut down
+
+Deepnote may turn off machines automatically for the following reasons:
+
+- the project was **inactive** for a certain period of time;
+
+- the project **exceeded the uptime limit** for **long-running executions**;
+
+- the project consumed all of the **hardware quota** available for the workspace
+
+#### Inactivity
+
+**All projects** get hardware turned off when no one is using them. We do this to help you avoid using up your free hardware hours unnecessarily or pay for the unused paid machines. The following two **conditions of inactivity** have to be met:
+
+1. **The project has no running cells in notebooks.** Code running in terminals does not prevent hardware from turning off.
+2. **There were no changes to the code or any execution for at least 15 minutes.** This maximum idle time is [customizable](/docs/long-running-jobs#custom-inactivity-grace-period) for projects in teams with a Team plan or higher.
+
+
+📖 **Example:** Bob is running a data analysis that takes 12 hours to complete. He starts the analysis and then closes Deepnote for the night. He comes back in the morning just before the analysis is complete and finds his notebook with all his variables is still live. Bob does some ad-hoc exploration and then goes to lunch with the notebook idle. After he comes back, he can still see all his outputs, but the variables and all other runtime objects are gone as the above conditions were met and the hardware for his project was turned off.
+
+
+#### Inactivity grace period
+
+A project is considered inactive when there are no code changes or executions within a specified period. Once this period of inactivity ends, the hardware is turned off. By default, this grace period is set to 15 minutes.
+
+Users on **Team plan or higher** can customize the behavior above and prevent the hardware being automatically turned off after 15 minutes of inactivity. This can be useful if you're unsure when your long-running job finishes and want to keep its state preserved (such as Python variables or terminal outputs). You can currently set the grace period to one of the following options:
+
+
+
+#### Long-running executions
+
+Hardware of **projects running on the Free plan** gets turned off automatically after running continuously for **8 hours**. Any running computation is interrupted. In extraordinary circumstances, we also reserve the right to turn off the hardware for the project earlier. In this case, you will see a message "Your hardware was shut down" next time you visit the project.
+
+Projects **running on the Team plan or higher** have a runtime limit of **48 hours**, with an additional 1-hour grace period. As the shutdown time approaches, a message is displayed offering the possibility of a 1-hour extension.
+
+#### Hardware quotas
+
+Finally, hardware of **projects running on the Free plan** is turned off if their owner runs out of free quota and they don't have a paying method set up. In this case, an info message will also appear next time you visit the notebook, notifying you about running out of the free quota.
+
+
+**Notebook size:** Keep in mind that the maximum size of a notebook, together with outputs generated by long running cell executions, is 30MB.
+
diff --git a/docs/machine-hours.md b/docs/machine-hours.md
new file mode 100644
index 0000000000..07a8c1e917
--- /dev/null
+++ b/docs/machine-hours.md
@@ -0,0 +1,31 @@
+---
+title: Additional machine hours
+noIndex: false
+noContent: false
+---
+
+Every workspace in Deepnote has free machine hours that replenish every month. If you need additional machine hours or more powerful machines, you can always upgrade your hardware.
+
+###### **What are machine hours?**
+
+When you run your notebooks, we use cloud-based hardware to execute your code. Machine hours are the total amount of hours our hardware was running to execute this code.
+
+###### **How many machine hours are offered for free?**
+
+Our goal is to provide an unlimited number of free machine hours for all workspaces. However, in certain cases we might limit a workspace’s compute hours when we detect irregular activity or extremely high usage. In case this happens, we will be in touch with you.
+
+###### **How can I add more machine hours?**
+
+In the rare occasion that a workspace exceeds the free machine hours we provide, workspaces on the Team and Enterprise plans can purchase additional machine hours. The hourly cost of these machines can be found in the Machines menu.
+
+
+
+###### **How can I upgrade to more RAM or CPU?**
+
+Workspaces on the Team and Enterprise plans can choose to switch to stronger machines, with higher computation power and RAM. The hourly cost of these machines can be found in the Machines menu.
+
+
+
+###### **How much will I be charged for machines?**
+
+If you decide to purchase machine hours beyond the free machine hours we provide, you will be charged at an hourly rate, calculated on a per-minute basis. So if you use a machine that costs $1/hr for 30 minutes, you will be charged $0.50. You can find the hourly rates for each machine in the Machines menu.
diff --git a/docs/materialize.md b/docs/materialize.md
new file mode 100644
index 0000000000..425f08e8b1
--- /dev/null
+++ b/docs/materialize.md
@@ -0,0 +1,27 @@
+---
+title: Materialize
+description: Available to teams and users on all plans
+noIndex: false
+noContent: false
+coverImage: 7AGIkclfQWCUivwJLnEg
+---
+
+### Materialize
+
+Deepnote now supports a first-class built-in integration with Materialize. Materialize is an operational data warehouse that shines for use cases where an analytical data warehouse would be too slow, and a stream processor would be too complicated.
+
+Using SQL and your bare hands, Materialize allows you to build real-time automation, engaging customer experiences, and interactive data products that drive value for your business while reducing the cost of data freshness.
+
+If you need to speed up queries that run frequently, or trigger actions as soon as events happen, Materialize can help. Rather than recalculate results from scratch, or serve stale cached results, Materialize continually ingests data and keeps results up-to-date as new data arrives.
+
+# Setup
+
+Add a Materialize integration from the sidebar, and simply fill in your connection info. You may now use supported Postgres functionality of Materialize from Python or Deepnote's SQL Blocks
+
+
+
+
+
+# Materialize documentation
+
+You may find information about compatibilities and advanced usage of Materialize in their [documentation](https://materialize.com/docs/).
diff --git a/docs/mindsdb.md b/docs/mindsdb.md
new file mode 100644
index 0000000000..e2699be230
--- /dev/null
+++ b/docs/mindsdb.md
@@ -0,0 +1,19 @@
+---
+title: MindsDB
+noIndex: false
+noContent: false
+---
+
+Integration with MindsDB requires an account at [MindsDB Cloud](https://cloud.mindsdb.com/). Follow the steps there to connect MindsDB Cloud to your database instance. In Deepnote, choose the MindsDB integration from the dashboard and enter the credentials to MindsDB Cloud (these are visible in the MindsDB cloud dashboard).
+
+
+
+After that's done, you can connect the new integration to your project.
+
+### Usage
+
+The easiest way to query MindsDB is to use [SQL cells](/docs/sql-cells).
+
+### Secure connections
+
+Deepnote supports securing connections to MindsDB via optional [SSL & SSH tunnels](/docs/secure-connections).
diff --git a/docs/modules.md b/docs/modules.md
new file mode 100644
index 0000000000..5eb207881b
--- /dev/null
+++ b/docs/modules.md
@@ -0,0 +1,129 @@
+---
+title: Modules
+description: Turn notebooks into reusable workflows
+noIndex: false
+noContent: false
+---
+
+Modules in Deepnote allow you to **transform your notebooks into reusable workflows** that can be shared across your workspace. This powerful feature solves the common challenge of code fragmentation and inconsistent analysis by enabling you to package essential elements—code snippets, SQL queries, data transformations, and visualizations—into standardized, reusable components.
+
+With modules, you can adopt a "build once, use everywhere" approach, ensuring your team leverages consistent tools and methodologies without duplicating efforts. Whether you're working with complex data cleaning routines or custom visualization functions, modules make your best work instantly accessible throughout your workspace.
+
+
+
+## Use Cases
+
+Modules open up numerous possibilities for streamlining your data workflows:
+
+- **Semantic layer for KPIs**: Ensure everyone calculates metrics like churn rate or weekly active users consistently
+- **Modular ETL pipelines**: Break complex transformations into logical steps that are easier to maintain and debug
+- **Code reusability**: Share common functions, visualization code, and data processing logic across projects
+- **ML experimentation**: Package machine learning models to test consistently across different datasets and parameters
+
+## Creating a Module
+
+Turning a notebook into a module is a straightforward process:
+
+Open the notebook you want to convert into a module and click the **create module button** in the notebook's upper right corner. Confirm your intent by pressing the ‘**Publish as a module**’ button.
+
+
+
+At this point, your notebook is turned into a module! However, to make it useful, there’s an extra step needed: you need to **select which blocks you want to export** as the output of the module. You can do this by going to a code or SQL block and clicking the **export block** action.
+
+Then you can give the exported block a descriptive name and you’re done!
+
+
+
+You can export as many blocks as you wish from a single module. The **output of all exported blocks will be available** when others import your module.
+
+It's important to note that exported outputs can differ based on the given block's type:
+
+- If you export a SQL block, the returned output will always be a DataFrame
+- In case of code blocks, the output will be the last returned variable within the code block
+- When exporting a function, ensure the function object is returned on the last line of the code block
+
+
+
+**Adding Parameters**
+
+To make your module configurable, include input blocks in your notebook. These will automatically become parameters that users can set when importing your module. For example, if you add a select input linked to a SQL block, users of the module will be able to customize the returned results based on their selection (such as filtering by pricing plan).
+
+
+
+## Importing a Module
+
+Using modules in your own notebooks is simple:
+
+1. Click the **module button** in the notebook footer
+2. Search for the module by project or notebook title
+3. Configure the module:
+ - Set any required input parameters
+ - Choose which exported blocks to import
+ - Optionally rename returned variables to fit your current notebook's naming conventions
+
+
+
+When you run the module block, it executes in a **separate environment** and returns your selected exports. All returned variables are automatically added to your current notebook's memory, seamlessly integrating with your existing work.
+
+**Special note on functions**
+
+When importing a Python function from a module, it's important to understand that **the function is executed in the context of the consuming notebook**. This means that global variables, integrations, and other environmental elements from the source module used within the imported functions may not be available in your current notebook.
+
+Make sure any dependencies required by your imported functions are either:
+
+- Explicitly passed as parameters to the function
+- Explicitly imported within the function itself
+- Already available in your current notebook environment
+
+This behavior differs from other module exports which execute in the module's own environment before returning their results.
+
+## Module Library
+
+Access all published modules through the **Modules section** in your workspace navigation sidebar. This centralized location makes it easy to discover and utilize the collective knowledge and tools created by your team.
+
+
+
+The module library provides valuable information about each module:
+
+- Source project and notebook
+- Creator
+- Projects currently using the module
+
+This visibility helps you understand the impact and reach of each module across your workspace.
+
+## Updating modules
+
+If you wish to update a module, you can do so easily by modifying the source notebook. Any changes you make will be **automatically propagated** to all other notebooks that import the updated module upon its execution.
+
+In case there's a change affecting the configuration of the module (for instance, a new input parameter), these changes will be flagged visually in the module block before execution, giving you an opportunity to review and adjust the configuration as needed.
+
+
+
+## AI Support for Modules
+
+Deepnote AI seamlessly integrates with modules, enhancing analytical capabilities while maintaining consistency across your workspace.
+
+### Teaching Deepnote AI with Your Modules
+
+When you build a semantic layer with modules—defining your KPIs and metrics in a trusted, consistent way—you're not just helping your team, you're also teaching Deepnote AI. This integration creates a powerful workflow where AI leverages your established definitions rather than calculating metrics from scratch.
+
+
+
+### How It Works
+
+When you ask analytical questions in Deepnote AI, the system follows a thoughtful approach:
+
+1. **Module Library Check**: AI first checks your module library for existing trusted definitions relevant to your query
+2. **Automatic Module Selection**: It identifies and selects the appropriate module for your analytical needs
+3. **Parameter Adjustment**: Parameters are automatically configured based on your specific question
+4. **Foundation-Based Analysis**: The analysis is built upon your established modules rather than creating new calculations
+
+## Current Limitations
+
+While we continue to enhance modules, there are a few current limitations to be aware of:
+
+1. **Caching**: Imported modules always run with each execution, with no option to cache results. This feature is on our roadmap.
+2. **Passing data to modules**: Currently, you can only pass parameters based on input blocks in the notebook. For cases where you need to pass a DataFrame to a module (such as a charting function), the current solution is to import the function first and then call it on your DataFrame in the current notebook.
+3. **Output types**: Exports are currently limited to variables. This means you cannot export HTML outputs like charts directly as module outputs. We're working on expanding the supported output types.
+
+We're actively working on addressing these limitations in future updates based on user feedback.
diff --git a/docs/mongodb.md b/docs/mongodb.md
new file mode 100644
index 0000000000..5b570efa49
--- /dev/null
+++ b/docs/mongodb.md
@@ -0,0 +1,29 @@
+---
+title: MongoDB
+noIndex: false
+noContent: false
+---
+
+
+Available on Team and Enterprise plans
+
+
+To add a connection to MongoDB, go to **Integrations** via the left sidebar, create a new MongoDB integration and enter your credentials:
+
+
+
+Don't forget to connect the newly created "MongoDB" integration in the Integrations sidebar.
+
+### Secure connections
+
+Deepnote simplifies connecting to MongoDB via SSH via optional [SSH tunnel integration](/docs/securing-connections?#ssh-tunnel-integration).
+
+#### Troubleshooting SSH connections for MongoDB
+
+If you are encountering the following error
+
+```
+Could not reach any servers in X
+```
+
+try adding `directConnection=true` to the connection URL.
diff --git a/docs/monitoring-machine-learning-models.md b/docs/monitoring-machine-learning-models.md
new file mode 100644
index 0000000000..21042380c1
--- /dev/null
+++ b/docs/monitoring-machine-learning-models.md
@@ -0,0 +1,45 @@
+---
+title: Monitoring machine learning models
+noIndex: false
+noContent: false
+---
+
+Monitoring machine learning models is a crucial aspect of the model lifecycle that ensures their continued performance, reliability, and effectiveness. While tools like Deepnote provide excellent environments for model training and deployment, integrating monitoring practices is essential to maintain model integrity in production. This article explores key aspects of ML model monitoring, tools, and best practices.
+
+## Importance of model monitoring
+
+Once an ML model is deployed, it enters a production environment where real-world data, which may differ significantly from training data, is processed. Monitoring helps detect issues like data drift, model degradation, and performance anomalies, ensuring that models continue to perform as expected. Early detection of these issues is critical for maintaining the trustworthiness and accuracy of predictions, particularly in high-stakes applications such as finance, healthcare, and autonomous systems.
+
+## Key aspects of ML model monitoring
+
+- **Performance Metrics**: Continuously tracking metrics such as accuracy, precision, recall, F1-score, and AUC-ROC helps assess how well the model is performing. Monitoring these metrics over time can reveal trends or sudden drops in performance, signaling potential issues.
+
+- **Data drift**: Data drift occurs when the statistical properties of the input data change over time, potentially rendering the model's predictions less accurate. Monitoring input data distribution and comparing it to the training data distribution can help detect data drift early.
+
+- **Concept drift**: Concept drift refers to changes in the underlying relationship between input data and the target variable. Unlike data drift, which focuses on the input data alone, concept drift affects the actual model behavior. Continuous evaluation of model predictions against true outcomes is essential to detect concept drift.
+
+- **Latency and throughput**: Especially relevant for real-time applications, monitoring the latency (time taken to make a prediction) and throughput (number of predictions made in a given period) ensures the system meets performance requirements.
+
+## Tools for model monitoring
+
+Several tools can be integrated with Deepnote to monitor ML models effectively:
+
+- **TensorBoard**: TensorBoard provides a suite of visualizations and metrics tracking that can be particularly useful during both training and post-deployment monitoring. It helps visualize metrics over time, inspect weights, and understand the model's decision-making process. You can use TensorBoard in Deepnote after [enabling Incoming connections](https://deepnote.com/docs/incoming-connections) to your Deepnote environment.
+- **Weights & Biases**: W&B offers comprehensive tracking of experiments and models, including performance metrics, hyperparameters, and datasets. Its visualization capabilities are useful for tracking model health and detecting anomalies. Learn more about [Weights & Biases in Deepnote](https://deepnote.com/docs/weights-and-biases).
+- **Comet.ml**: Similar to W&B, Comet.ml provides real-time monitoring and logging of metrics, hyperparameters, and experiments. It supports collaboration by allowing teams to share and compare results. Learn more about [Comet.ml in Deepnote](https://deepnote.com/docs/cometml).
+
+- **MLflow**: MLflow is an open-source platform that manages the ML lifecycle, including experimentation, reproducibility, and deployment. Its monitoring capabilities include logging metrics, parameters, and output files, making it easier to track model performance over time.
+
+- **Seldon Core**: For Kubernetes-based deployments, Seldon Core offers monitoring features, including logging and metric tracking, to ensure model reliability and performance in production environments.
+
+## Best practices for model monitoring
+
+Automated Alerts: Implement automated alerts for anomalies in key metrics. This ensures that data scientists and engineers are immediately informed of potential issues.
+
+- **Regular retraining**: Set up a schedule for model retraining, especially if the model's environment is prone to rapid changes. This helps mitigate the effects of data and concept drift.
+
+- **Audit logging**: Maintain comprehensive logs of model inputs, outputs, and decision-making processes. This is crucial for debugging, compliance, and auditing purposes.
+
+- **Cross-validation and A/B testing**: Use cross-validation and A/B testing techniques to validate model updates before full deployment. This reduces the risk of introducing underperforming models into production.
+
+Effective monitoring of machine learning models is vital for maintaining their performance and reliability in production. By integrating monitoring tools with platforms like Deepnote and adhering to best practices, data scientists can ensure that their models continue to deliver accurate and reliable results, thereby sustaining the value they provide to businesses and end-users.
diff --git a/docs/mysql.md b/docs/mysql.md
new file mode 100644
index 0000000000..c94a752055
--- /dev/null
+++ b/docs/mysql.md
@@ -0,0 +1,19 @@
+---
+title: MySQL / MariaDB
+noIndex: false
+noContent: false
+---
+
+To add a connection to MySQL or MariaDB, go to **Integrations** via the **right** sidebar, create a new MySQL integration and enter your credentials:
+
+
+
+After that's done, connect the new integration to your project using the Integrations sidebar.
+
+### Usage
+
+The easiest way to query MySQL is to use [SQL cells](/docs/sql-cells).
+
+### Secure connections
+
+Deepnote supports securing connections to MySQL and MariaDB via optional [SSL & SSH tunnels](/docs/secure-connections).
diff --git a/docs/neptuneai.md b/docs/neptuneai.md
new file mode 100644
index 0000000000..05e45c78b9
--- /dev/null
+++ b/docs/neptuneai.md
@@ -0,0 +1,9 @@
+---
+title: Neptune.ai
+noIndex: false
+noContent: false
+---
+
+[Neptune](https://neptune.ai/) is a lightweight experiment management tool that helps you keep track of your machine learning experiments.
+
+To get started with Neptune tracking in Deepnote notebooks, follow [this guide](https://neptune.ai/blog/monitoring-machine-learning-experiments-guide).
diff --git a/docs/notebook-locking.md b/docs/notebook-locking.md
new file mode 100644
index 0000000000..aab0637737
--- /dev/null
+++ b/docs/notebook-locking.md
@@ -0,0 +1,17 @@
+---
+title: Notebook locking
+noIndex: false
+noContent: false
+---
+
+Accidental edits of notebooks happen, especially when the number of people in your workspace increases. Once a notebook is published as an app or is part of a running pipeline, such unintended changes can have serious consequences. To prevent these accidental edits, you can lock the notebook.
+
+You can enable the notebook lock from the notebook's context menu.
+
+
+
+The content of the locked notebook cannot be edited in any way, but it can still be run, shared, or commented on.
+
+All users who wish to edit the notebook must manually unlock it. The notebook is unlocked only for the specific user, meaning it remains locked for others. The notebook will revert to its locked state once the user navigates away or refreshes the browser.
+
+
diff --git a/docs/notebooks.md b/docs/notebooks.md
new file mode 100644
index 0000000000..9bfef9532f
--- /dev/null
+++ b/docs/notebooks.md
@@ -0,0 +1,48 @@
+---
+title: Notebooks
+description: Notebooks are computational documents that combine code, visualizations, and text. They changed data forever, and they've become even more powerful in Deepnote.
+noIndex: false
+noContent: false
+---
+
+## What is a notebook in Deepnote?
+
+Beyond being a powerful computational medium, Deepnote notebooks are fully collaborative documents. They combine SQL, Python, and no-code tools into an analytics environment suitable for data teams.
+
+### Composing with building blocks
+
+Notebooks are made up of a series of blocks. Each major type of content or action you can perform has its own block type:
+
+- Code blocks enable you to write and execute Python code (or [other languages](https://deepnote.com/docs/running-your-own-kernel)).
+- [SQL blocks](https://deepnote.com/docs/sql-cells) are used to write SQL queries against databases, pandas DataFrames, and CSV files.
+- [Text blocks](https://deepnote.com/docs/text-editing) allow you to compose richly formatted text.
+- [Chart blocks](https://deepnote.com/docs/chart-blocks) provide you with a point-and-click charting tool for efficient data visualizations.
+- [Input blocks](https://deepnote.com/docs/input-blocks) are interactive widgets that capture user inputs and pass them as variables to your Python code and SQL queries.
+
+Blocks can easily be added to your notebook via the **add block** (**+**) menu or by selecting a block category from the bottom of your notebook.
+
+
+
+### Executing blocks to generate results
+
+In order to see output from your code, you need to execute the corresponding block. You can do this in three ways:
+
+- Click the **Run notebook** button at the top of the notebook. This will execute all blocks from top to bottom. Execution will stop at any block that produces an error.
+- Click the **Run** button on the block's sidebar menu.
+- Press **Cmd/Ctrl** + **Enter** on your keyboard while focused on a block.
+
+
+
+### Exploring helpful block operations
+
+You can access a set of standard block operations in the block's sidebar menu. Besides executing them, you can also comment, share, and delete blocks. Even more options are available in the **block actions** menu, including duplicating or moving blocks up and down. Options can be specific to the given block type, so it’s always worth exploring this menu.
+
+
+
+### Changing the working directory of a notebook
+
+By default, the working directory of your notebook is the same as the root of the file system in the right sidebar. Its absolute path is `/work`. To change a notebook's working directory, click its context menu, scroll down to **WORKING DIRECTORY** and click the ⚙️ symbol.
+
+
+If you have [imported a Jupyter notebook](https://deepnote.com/docs/importing-and-exporting-jupyter-notebooks) and you want to execute it, make sure you place it in the dedicated **Notebooks** section. Jupyter files that exist in the **Files** section are "read-only."
+
diff --git a/docs/notion.md b/docs/notion.md
new file mode 100644
index 0000000000..5c5168d417
--- /dev/null
+++ b/docs/notion.md
@@ -0,0 +1,88 @@
+---
+title: Notion
+description: Available to teams and users on all plans.
+noIndex: false
+noContent: false
+coverImage: w2F4ok5iRlyQ4maT5G3m
+---
+
+
+**Want to get started right away?** Jump right in and explore [this hands-on example](https://deepnote.notion.site/Bringing-analytics-to-Notion-with-Deepnote-d6ad9e9cf62f4b0ab425eec25c3f8f4b) of querying Notion databases using Deepnote and embedding the results on Notion.
+
+
+Notion is an all-in-one workspace that allows for everything from simple note-taking to building knowledge libraries for entire organizations. Since Notion stores data in databases, you can actually query the data stored in Notion and analyze it using Deepnote. After visualizing your data, you can then go full-circle by bringing the plots back into Notion by embedding your Deepnote blocks into Notion pages.
+
+
+
+### How to set it up
+
+The first step in querying your Notion databases is retrieving your Notion API key and the ID of the database you would like to query. To gather all necessary information, head on over to [Notion's brilliant documentation](https://developers.notion.com/docs/getting-started) that offers a step-by-step walkthrough. To find your database ID, open up the Notion page containing the database and take a look at the URL. It should take the form of `https://www.notion.so/?v=`, where `` is your database ID and `` is the view ID.\
+
+Once you've set up Notion's API, consider storing both the API key and database ID as an [environment variable](/docs/environment-variables). Environment variables in Deepnote are encrypted and provide a secure way of storing sensitive data.
+
+### How to use
+
+#### Query Notion databases
+
+Once you've stored your Notion API key and database ID as environment variables, you can start querying. The code below queries a Notion database and saves it as a Pandas DataFrame that you can then use for further analyses.
+
+```python
+import os
+import requests
+import pandas as pd
+
+# keys are stored in env vars to be hidden from users
+api_key = os.environ["NOTION_API_KEY"]
+database_id = os.environ["DATABASE_ID"]
+
+# define request to Notion API
+headers = {
+ "Authorization": f"Bearer {api_key}",
+ "Notion-Version": "2021-08-16",
+ "Content-Type": "application/json",
+}
+
+# load first page
+response = requests.post(
+ f"https://api.notion.com/v1/databases/{database_id}/query", headers=headers
+).json()
+
+# iteratively load all pages
+records = response["results"]
+while response["has_more"]:
+ response = requests.post(
+ f"https://api.notion.com/v1/databases/{database_id}/query",
+ json={"start_cursor": response["next_cursor"]},
+ headers=headers,
+ ).json()
+
+# define a helper function to transform the JSON to a Pandas DF
+def get_raw_value(item):
+ item_type = item['type']
+ if type(item[item_type]) is list:
+ if item[item_type][0]['type'] == 'text':
+ return item[item_type][0]['plain_text']
+ return item[item_type]
+
+# create Pandas DF
+all_values = []
+for record in records:
+ properties = record['properties']
+ all_values.append({
+ 'Name': get_raw_value(properties['Name']),
+ 'Total': get_raw_value(properties['Total']),
+ })
+
+df = pd.DataFrame(all_values)
+df
+```
+
+#### Embed Deepnote blocks into Notion pages
+
+After reading your Notion databases, performing analyses using the data, and creating visualizations, you might want to bring your Notion blocks back into Notion. That's where [shared blocks](/docs/sharing-and-embedding-blocks) come into play. Deepnote allows for the sharing and embedding of individual blocks. It's up to you whether you want to include the code and output or only one of the two.
+
+
+
+### Next steps
+
+Jump right in and explore [this hands-on example](https://deepnote.notion.site/Bringing-analytics-to-Notion-with-Deepnote-d6ad9e9cf62f4b0ab425eec25c3f8f4b) of querying Notion databases using Deepnote and embedding the results on Notion. You can also save yourself some setup work by copying the workflow used in the example to start querying your own Notion databases!
diff --git a/docs/onedrive.md b/docs/onedrive.md
new file mode 100644
index 0000000000..d6029958e5
--- /dev/null
+++ b/docs/onedrive.md
@@ -0,0 +1,40 @@
+---
+title: Microsoft OneDrive
+noIndex: false
+noContent: false
+coverImage: 2WgnsVCRS8esbCqGc2lO
+---
+
+Deepnote can fetch files from OneDrive, for example, Excel files that you collaborate on with your team. Follow these docs to create your own notebook to pull files from OneDrive, query data, and visualize it.
+
+### 1. Duplicate the OneDrive template
+
+[Open the template by following this link ->](https://deepnote.com/workspace/Deepnote-Templates-71742312-24f2-4c10-9bf7-786d17280b92/project/Fetch-OneDrive-files-in-Deepnote-7c6d212e-b26d-48ca-a3d0-fcd63f888999/%2Fnotebook.ipynb)
+
+
+
+Click the "duplicate" button on the top right corner to do this. Once you've got the template in your Deepnote workspace, you can download files from OneDrive.
+
+### 2. Share files with Deepnote from OneDrive
+
+You need to create a public sharing link so Deepnote can download the file. [Follow these instructions from Microsoft](https://support.microsoft.com/en-us/office/create-a-shareable-link-8257f6da-d5db-4207-a654-925644e3f35c) making sure that anyone with the link can at least **view** the file.
+
+Change the variable `ONEDRIVE_SHARE_LINK` in the notebook to link to the file you just made.
+
+### 3. Fetch OneDrive files from Deepnote
+
+The template notebook has a function called `get_onedrive_download`, which takes a share link and creates a URL that will download that file directly. You can use a library like `requests` to fetch the file or pass it to `pandas` to read a CSV or Excel file directly. In the below example, the shared file is an Excel file.
+
+```python
+ONEDRIVE_SHARE_LINK = "https://1drv.ms/x/s!AjP7y6eiYDDSafV7BusEaDHrI0o?e=cL0Fqi"
+df = pd.read_excel(get_onedrive_download(ONEDRIVE_SHARE_LINK))
+df
+```
+
+When executing the code above, Deepnote will visualize the output DataFrame, as we see in the example below.
+
+
+
+### What's next?
+
+Now that you're querying data, you can share it with your team. You can even turn your charts [into a shareable dashboard](/docs/publish-projects).
diff --git a/docs/postgresql.md b/docs/postgresql.md
new file mode 100644
index 0000000000..1aa1c6ab3a
--- /dev/null
+++ b/docs/postgresql.md
@@ -0,0 +1,77 @@
+---
+title: PostgreSQL
+noIndex: false
+noContent: false
+---
+
+## Setup
+
+To add a connection to PostgreSQL, go to **Integrations** via the **right-hand sidebar**, create a new PostgreSQL integration and enter credentials:
+
+
+
+Don't forget to connect the newly created "PostgreSQL" integration in the Integrations sidebar.
+
+### Authorizing Deepnote's IP addresses for security reasons
+
+
+If your connection is protected, you might need to add Deepnote's IP addresses to your allowlist. [Read more here](/docs/authorize-deepnote-ip-addresses)
+
+
+## Usage
+
+The fastest way to query your connected postgres database is to use a [SQL cell](/docs/sql-cells). You can create one by clicking "+ Block" or at the bottom of a notebook.
+
+
+
+A text input cell and a SQL cell work together
+
+## Advanced usage
+
+Alternatively, if you want to use python to access the database, access the connection details via environment variables with a common prefix that's generated from the name of your Postgres integration:
+
+- `_HOST`
+- `_DATABASE`
+- `_PORT`
+- `_USER`
+- `_PASSWORD`
+
+Then you'll be able to connect to a database like this:
+
+```python
+import psycopg2
+import os
+
+try:
+ connection = psycopg2.connect(
+ user=os.environ["MY_INTEGRATION_USER"],
+ password=os.environ["MY_INTEGRATION_PASSWORD"],
+ host=os.environ["MY_INTEGRATION_HOST"],
+ port=os.environ["MY_INTEGRATION_PORT"],
+ database=os.environ["MY_INTEGRATION_DATABASE"])
+
+ with connection.cursor() as cursor:
+ cursor.execute("SELECT version();")
+ record = cursor.fetchone()
+ print("You are connected to - ", record)
+
+except (Exception, psycopg2.Error) as error:
+ print ("Error while connecting to database", error)
+```
+
+You can now use `connection` and `connection.cursor()` like shown in example above to run queries against the database. Here's how you can run a query and see its output:
+
+```python
+import pandas as pd
+
+query = """
+SELECT *
+FROM users
+"""
+df = pd.io.sql.read_sql_query(query, connection)
+df
+```
+
+### Secure connections
+
+PostgreSQL supports [SSL & SSH connections](/docs/secure-connections).
diff --git a/docs/pre-installed-packages.md b/docs/pre-installed-packages.md
new file mode 100644
index 0000000000..fa98e2eb2e
--- /dev/null
+++ b/docs/pre-installed-packages.md
@@ -0,0 +1,39 @@
+---
+title: Pre-installed packages
+noIndex: false
+noContent: false
+---
+
+Deepnote provides key data analytics and ML Python libraries off the shelf, in the most recent version. All you have to do is import them into your project.
+
+#### The current list of pre-installed packages:
+
+- `agate`
+- `arrow`
+- `datascience`
+- `dill`
+- `fiona`
+- `jsonify`
+- `keras`
+- `matplotlib`
+- `nltk`
+- `numpy`
+- `pandas`
+- `psycopg2-binary`
+- `requests`
+- `scikit-learn`
+- `scipy`
+- `scrapy`
+- `seaborn`
+- `six`
+- `spacy`
+- `squarify`
+- `sympy`
+- `tabulate`
+- `tensorflow`
+- `textblob`
+- `torch`
+- `torchvision`
+- `urllib3`
+
+Click [here](/docs/python-requirements) to learn how to install packages in Deepnote.
diff --git a/docs/pricing.md b/docs/pricing.md
new file mode 100644
index 0000000000..60529f14dc
--- /dev/null
+++ b/docs/pricing.md
@@ -0,0 +1,43 @@
+---
+title: Plans and billing
+description: Questions & answers about plans and pricing
+noIndex: false
+noContent: false
+---
+
+Deepnote currently offers 3 plans: Free, Team, and Enterprise. You can read more about the features of each plan on our [Pricing page](https://deepnote.com/pricing).
+
+###### **How do I upgrade my plan?**
+
+You can upgrade or downgrade your plan from the Plans page in your workspace settings. If you need to upgrade to the Enterprise plan, you can schedule a quick chat with our customer success team here.
+
+###### **How much will I be charged when I upgrade**
+
+When you upgrade to a paid plan, you will be charged per editor and admin seat in your workspace. For example, if you have 1 Admin seat and 4 Editor seats, you will be charged for 5 total seats. You will not be charged for other roles, such as Viewers.
+
+###### **Can I still add or remove seats in my workspace after upgrading?**
+
+Yes! While on a paid plan, you can add or remove Editor/Admin seats at any time. At the start of the next subscription period, you will be billed for the number of Editor/Admin seats present at the time of billing. If you are on annual billing, you will be charged for the added seats a prorated price for remaining time of the annual billing period. All charges when adding new seats are billed when the added users accept the invites.
+
+_Example 1_: You created a workspace with 1 admin and 3 editors on the 1st of the month. On the 15th, you added 3 more editors. On the 1st of the next month, you will be charged for 1 admin and 6 editors.
+
+_Example 2_: You created a workspace with 1 admin and 3 editors on January 1st 2023 and selected yearly billing. At the beginning of the year, you paid for 4 seats. In June, you decided to add 1 more editor. When the new editor accepted your invite, your card was charged for the remaining 6 months for this user. On January 1st 2024 you will be charged for 5 seats. If you decide to remove one of the members at any point during the annual period, the seat that you paid for will stay available for anyone else to join. If you then add a new editor again, you will not be charged during the current billing period.
+
+###### **How do I downgrade or cancel my plan?**
+
+You can downgrade or cancel your plan from the Plans page in your workspace settings. Once you downgrade, you will receive a refund for any unused days.
+
+###### **Will I receive a refund if I downgrade or cancel my plan?**
+
+If you remove a paid seat, we won’t issue a prorated refund. However, someone else at your company can use their paid seat when it becomes available.
+If you downgrade or cancel your subscription, we will refund you a prorated amount for any unused days of the month. For example, if you cancel your subscription 15 days into the billing period, we will refund you 50% of the amount you were charged.
+
+###### **Do you offer any plans or discounts for schools and NGOs?**
+
+Members of educational institutions, such as students, teachers, and researchers, are all eligible for our Education plan. The Education plan has almost all the same features of the Team plan, except that it’s completely free! To find out more about the Education plan, visit our website and sign up with your educational email.
+
+
+
+Are you part of another community and don’t have an academic email? You might still qualify for the Education plan. [Get in touch with us](mailto:help@deepnote.com).
+
+
diff --git a/docs/product-portal.md b/docs/product-portal.md
new file mode 100644
index 0000000000..1649230b29
--- /dev/null
+++ b/docs/product-portal.md
@@ -0,0 +1,8 @@
+---
+title: Product portal
+description: See what Deepnote has launched, what is coming soon, and vote on new features.
+noIndex: false
+noContent: false
+---
+
+[Check out our product portal](https://portal.productboard.com/deepnote).
diff --git a/docs/project-initialization.md b/docs/project-initialization.md
new file mode 100644
index 0000000000..474e975e16
--- /dev/null
+++ b/docs/project-initialization.md
@@ -0,0 +1,32 @@
+---
+title: Project initialization
+noIndex: false
+noContent: false
+---
+
+Deepnote provides an optional feature to run custom Python initialization code every time your project hardware boots up. To utilize this capability, you will need to **include an 'Init' notebook** in your project.
+
+To create an 'Init' notebook:
+
+- Click on the **Environment** selector in the project sidebar.
+- Click on the **Create an initialization notebook** button at the **Custom initialization** section on the right.
+
+
+
+Alternatively, you can also simply create a new notebook by pressing the plus button in your Notebook list and name it as 'Init'.
+
+After creating it, the 'Init' notebook will be conveniently located at the top of your Notebook list.
+
+
+
+The contents of this notebook will automatically execute each time your project starts up, providing an ideal place to set up your preferred environment.
+
+Please note: the 'Init' notebook will only act as an initialization notebook if it's called '**Init**' and it is marked by the configuration notebook symbol (lightning icon). For instance, if you create a notebook called 'init', that won't be automatically run at project startup.
+
+By default, the 'Init' notebook installs any packages listed in ./requirements.txt. This provides a convenient option to ensure you have all package dependencies ready. However, you are free to add any other code into the 'Init' notebook according to your project's needs.
+
+
+
+**There are 2 packages on the disallowlist:** `jupyter` and `jedi`. These are packages that interfere with the way Deepnote works and their installation would break your environment. In the 'Init' notebook , we scan the requirements files for those packages and skip their installation if they are there.
+
+
diff --git a/docs/projects.md b/docs/projects.md
new file mode 100644
index 0000000000..82ff58237a
--- /dev/null
+++ b/docs/projects.md
@@ -0,0 +1,90 @@
+---
+title: Projects
+description: You have a very specific task that requires a coding environment, notebooks, and data. That's where projects come in — a collaborative container for everything you need to complete your analysis.
+noIndex: false
+noContent: false
+---
+
+## What can you do with projects?
+
+Projects do a lot, from shared data sources across multiple notebooks to native version control. Here are some highlights:
+
+- Projects contain notebooks and therefore can be used to organize related work (e.g., EDA notebook, ML notebook)
+- Projects define your environment — including the Python version, required libraries, and the machine specifications (i.e., RAM, number of cores).
+- Projects have their own file system and provide access to database integrations.
+
+### Creating a project
+
+From the left panel in your Workspace, you can click the **"+"** symbol next to **PROJECTS** to create a new project, either from scratch or from Deepnote's built-in templates. In addition, clicking on the ellipses beside a project will provide options for creating, duplicating, and moving projects (and more).
+
+Don't forget that you can arrange your projects into folders here, too. Just drag and drop them to suit how you like to organize your work.
+
+
+
+
+Let's move to the newly created Project panel now. Notice that the left panel has changed and you are focused on the context of your Project.
+
+### Learning the most important bits
+
+The Project sidebar on the left contains sections for your notebooks, integrations, files, the environment, terminals, and more. Let's learn about each of these in detail.
+
+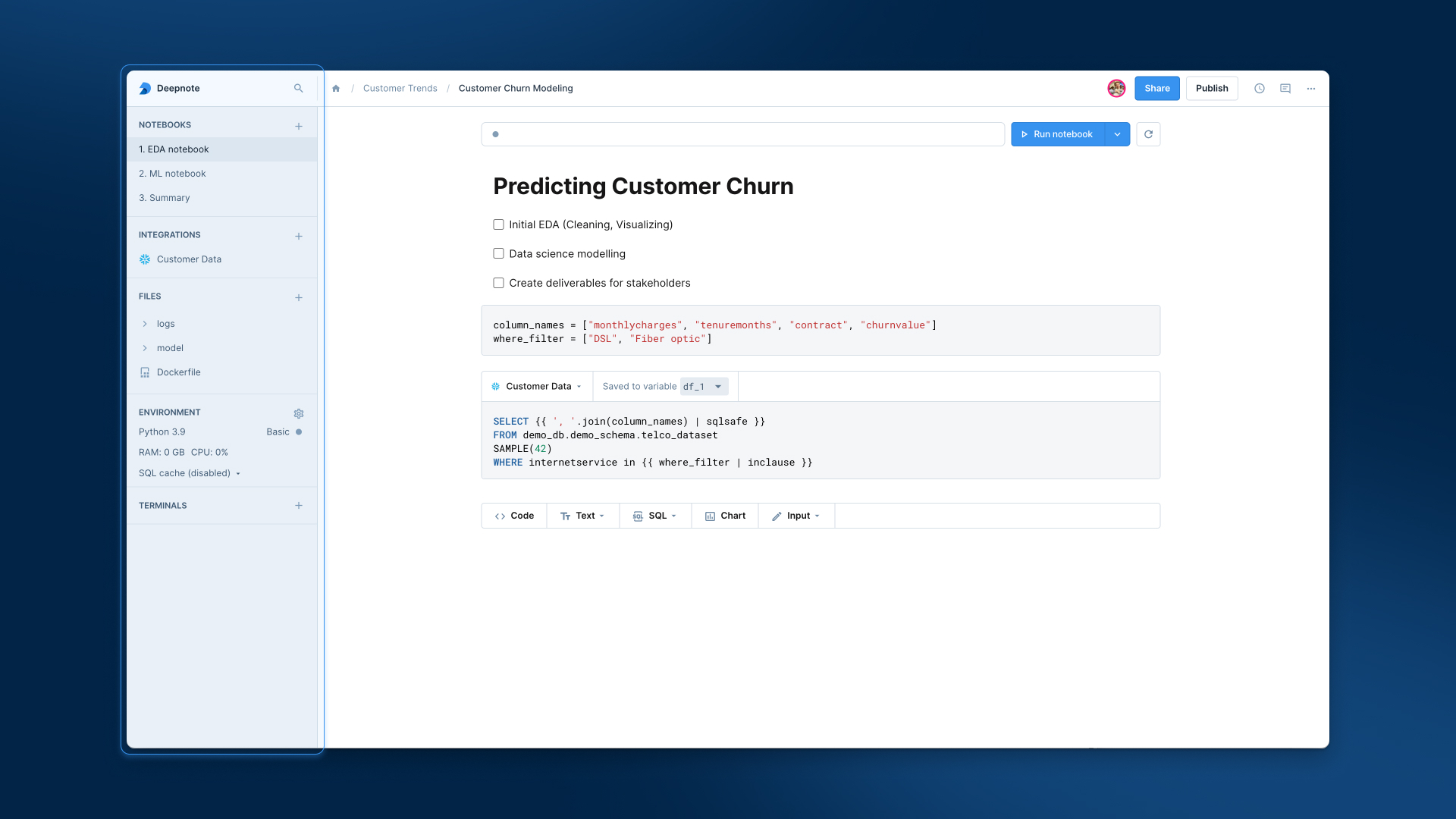
+
+
+#### Notebooks
+
+The **Notebooks** section can contain multiple notebooks. This is helpful since multiple notebooks are often needed to accomplish an overall goal. Read more about Deepnote's powerful notebooks [here](https://deepnote.com/docs/notebooks).
+
+#### Integrations
+
+The **Integrations** section is all about hooking up resources to your project. It's where you connect to [databases/warehouses](https://deepnote.com/docs/snowflake), [buckets](https://deepnote.com/docs/amazon-s3), [Docker container registries](https://deepnote.com/docs/amazon-ecr), and [secrets](https://deepnote.com/docs/environment-variables). Your collaborators can share these connections without having to bother with additional setup.
+
+#### Files
+
+Think of this section as your local computer's file system. It's snappy like that. Drag a CSV into it or upload the other scripts and files you need. The file system is a shared space for all notebooks within a single project. To learn more about working with the file system, read our general guidelines [here](https://deepnote.com/docs/importing-data-to-deepnote).
+
+
+
+Got a `requirements.txt` file? We create one for you when you `pip` install a package. And we automatically install the listed packages every time your machine starts up.
+
+
+
+#### Environment
+
+Time to get serious. You probably want to know how to configure your environment. Let's dive into what you can do in the **Environment** section.
+
+First, click on the ⚙️ icon. You should now see your environment configuration options (shown below). Follow me.
+
+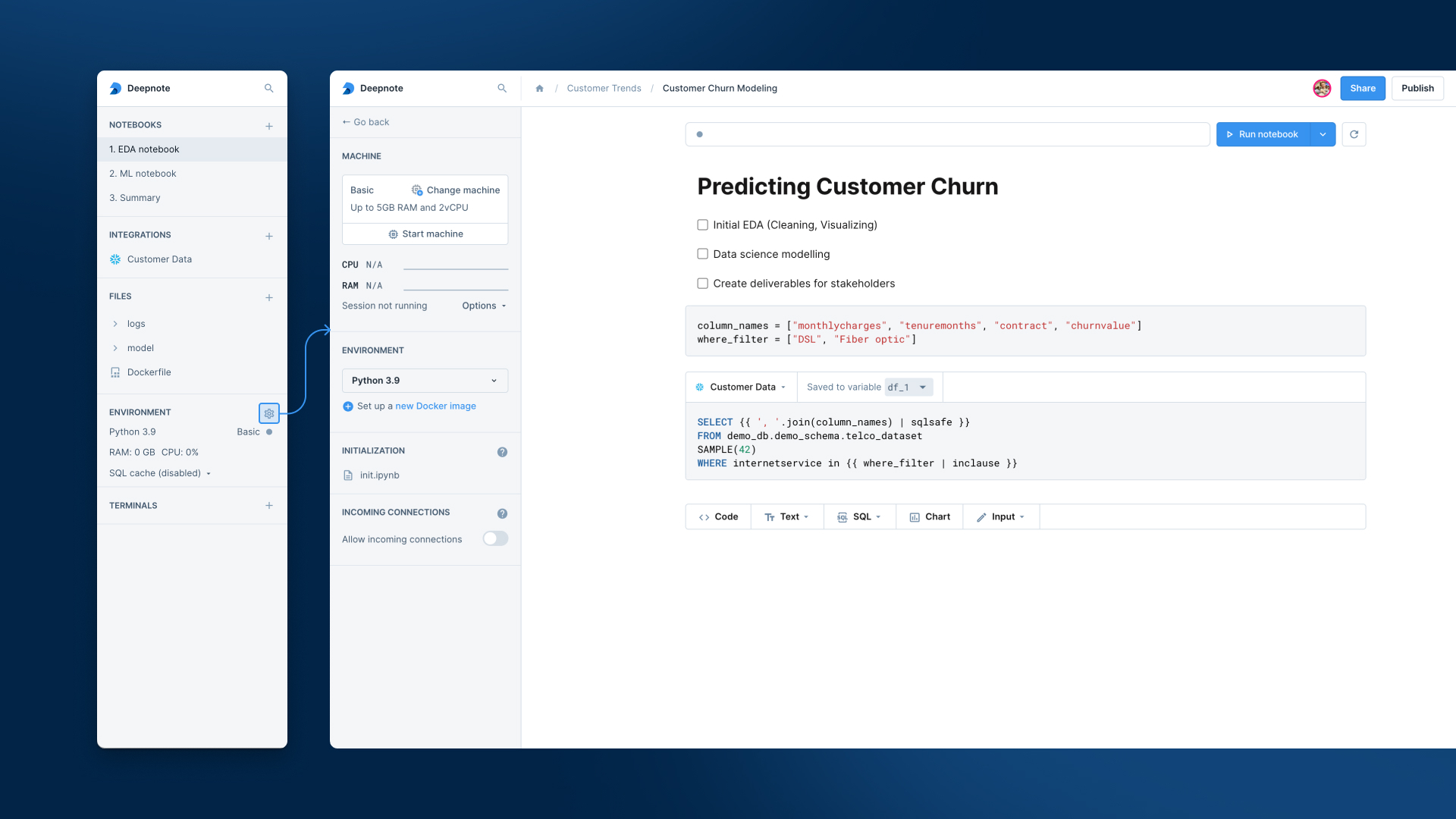
+
+**Machine:** If you need a "beefier" machine, this is where you can choose one. If you're on a Team or Enterprise plan, you get unlimited hours on a 16GB, 4vCPU machine. To learn more about machines in Deepnote, click [here](https://deepnote.com/docs/machine-hours).
+
+**Built-in environments:** From the dropdown menu (under **Environment**) you can choose between any of the built-in Python environments. They come [pre-installed with the most popular libraries](https://deepnote.com/docs/pre-installed-packages) so you can begin working immediately. The default environment is Python 3.9.
+
+
+
+🔥 If the built-in environments don't meet your needs, no problem. You may **define a local Dockerfile** or bring your own image from any registry (e.g., ECR, Docker Hub, etc.). To learn more about custom environments, [hop over here](https://deepnote.com/docs/custom-environments).
+
+
+
+**Initialization notebook:** There are times when you want to run some "starter" code before your notebook is used. You can place such code in a notebook called 'Init'. Read more about setting up custom [project initialization](https://deepnote.com/docs/project-initialization).
+
+**Incoming connections:** Toggle this switch if you need to [spin up a web server from Deepnote](https://deepnote.com/docs/incoming-connections). Yes, this is perfect for hosting the Airflow console, Streamlit apps, TensorBoard, and much more.
+
+#### Terminals
+
+We all need a CLI every now and then, even if we are notebook lovers. Well, you can create as many terminals as you like in the **Terminal** section. Read more about terminals [here](https://deepnote.com/docs/terminal).
+
+### Project templates
+
+In case you'll find yourself attaching the same integrations, or using the same environment in most of your projects, you can save the project as a template. To do that, click on the dropdown option of your project, and click "Add to templates".
+
+
+
+Under the hood, a project template is just a special type of project - this means that you can edit and execute notebooks in it. Once you convert a project to a template, you won't find it in the workspace sidebar anymore, but in the "New project from template" modal.
+
+
+
+## Going deeper with projects
+
+Projects can do so much more. We encourage you to check out how to use [comments](https://deepnote.com/docs/comments), how to [version projects](https://deepnote.com/docs/history) and view their history, and how to [connect to GitHub](https://deepnote.com/docs/github).
diff --git a/docs/prompting-tips-and-tricks.md b/docs/prompting-tips-and-tricks.md
new file mode 100644
index 0000000000..148a713841
--- /dev/null
+++ b/docs/prompting-tips-and-tricks.md
@@ -0,0 +1,102 @@
+---
+title: Prompting tips and tricks
+description: Learn how to effectively structure your prompts in order to get the most out of Deepnote AI and fully utilize its deep contextual awareness.
+noIndex: false
+noContent: false
+---
+
+# Fundamentals of effective prompting
+
+Deepnote AI is powered by OpenAI’s latest models. Here are a few general tips on how to improve your prompts for better results.
+
+### Be specific and include details
+
+Be as specific as possible when writing your instructions. By including details in your prompt, you minimize the chances of the model filling in too many blanks for you. Stating your higher level goal is as important as pointing out concrete methods or functions that you expect to be used. For example:
+
+1. Mention the specific Python package you want to use
+
+```python
+# ❌ Don't do
+Train a machine learning model
+
+# ✅ Instead do
+Train a logistic regression on the training data with sklearn
+```
+
+2. When plotting a chart, describe how you would like it to look like
+
+```python
+# ❌ Don't do
+Plot a chart of the data
+
+# ✅ Instead do
+Plot total_sales against time on a stacked line chart for every continent
+```
+
+3. Specify the length of the desired output
+
+```python
+# ❌ Don't do
+Read the CSV file
+
+# ✅ Instead do
+Read the first 100 rows from events.csv
+```
+
+### Use appropriate structure and formatting
+
+Leverage formatting for a clearer structure and highlighting the key parts of your prompt. For example, you can make use of operators to outline relationships between parts of the prompt or enclose a value in quotation marks to ask for literal values.
+
+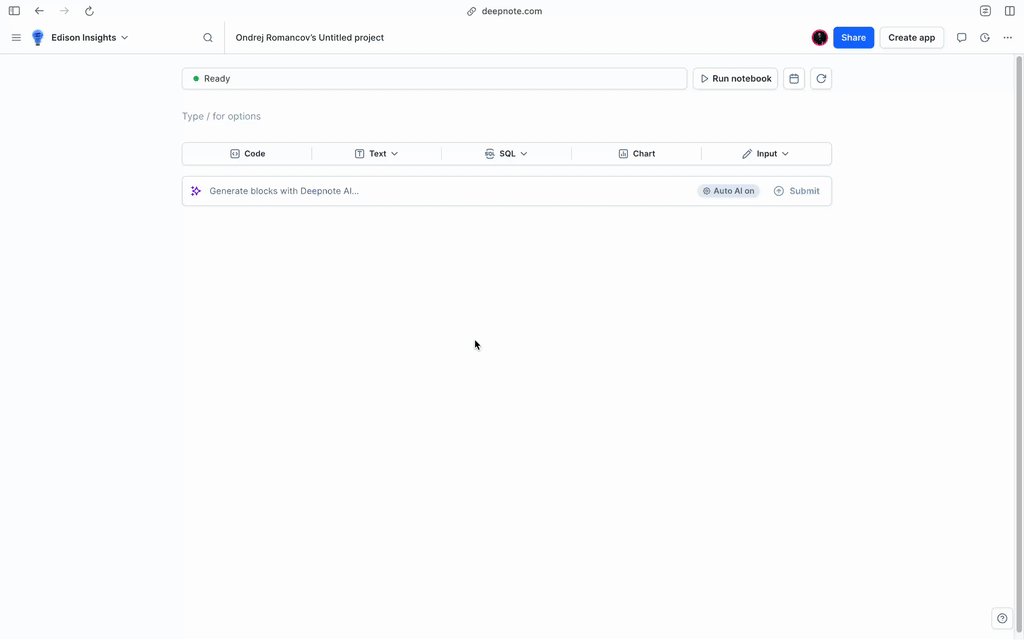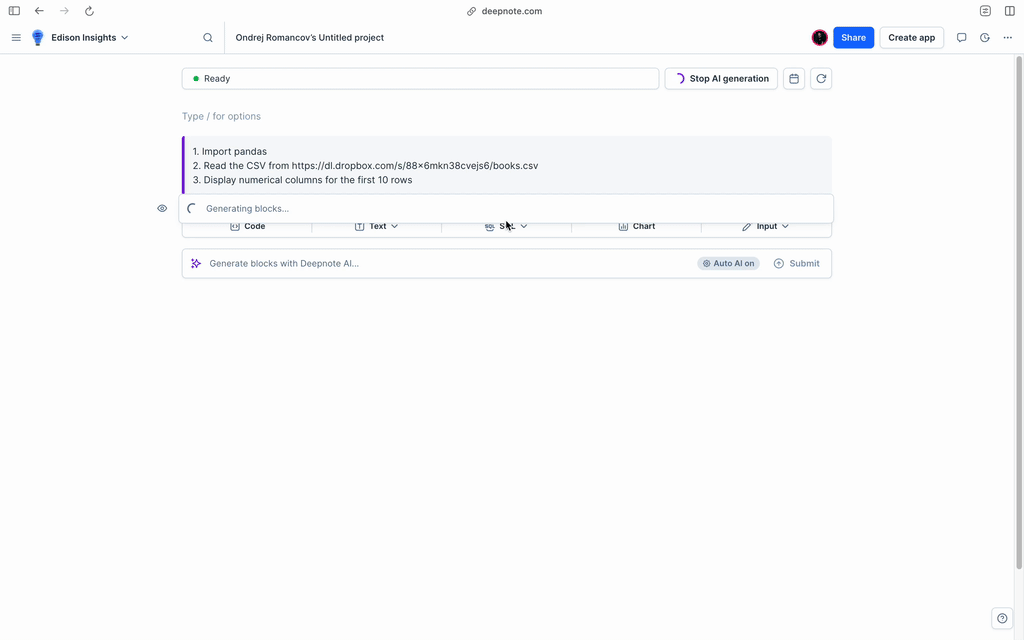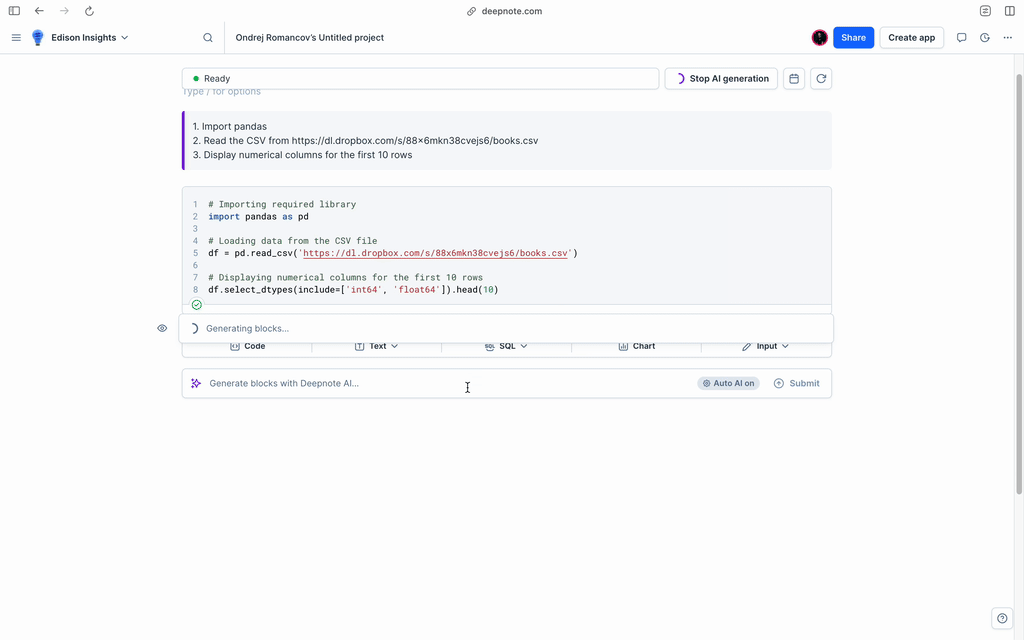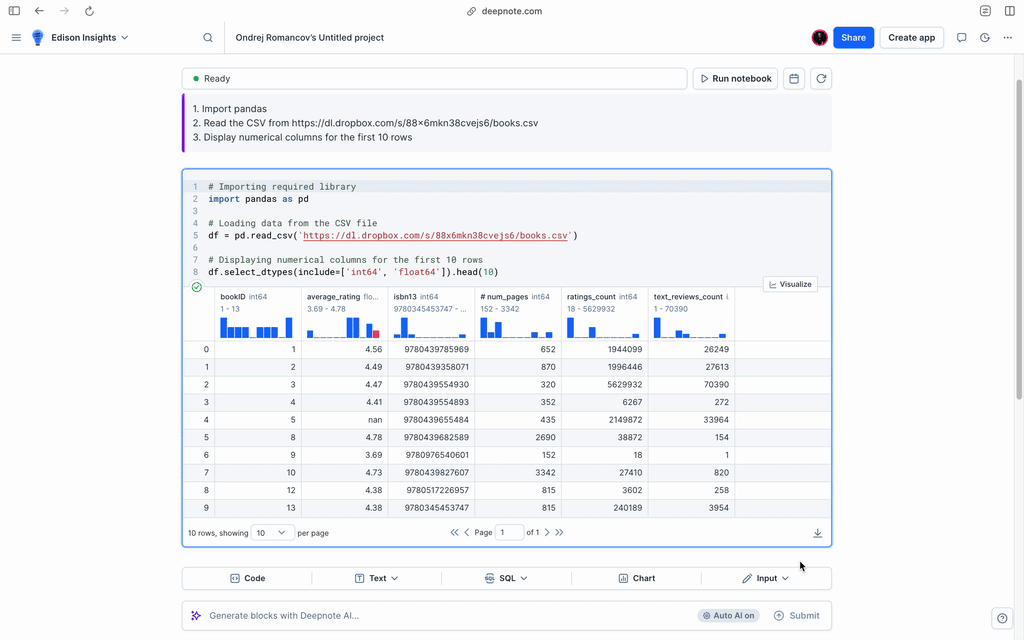
+
+If the problem is complex, you can point out the necessary steps as individual bullet points or numbered points if they need to be completed in a certain order. We recommend breaking down your problem into subproblems and tackling these with individual prompts instead of all at once.
+
+### Provide examples
+
+One of the most effective prompting techniques is “few-shot” prompting. This entails including relevant examples in your prompts that demonstrate to the AI exactly how it should approach solving your problem. This becomes especially useful when expecting a specific output from Deepnote AI, as it needs to understand the relevant schema beforehand.
+
+# Advanced prompt techniques
+
+Use the following advanced techniques to fully utilize Deepnote AI’s abilities to understand the context of your workspace.
+
+### Leveraging notebook contents
+
+Deepnote AI factors in the contents of your notebook in its outputs. You can take advantage of this and write out relevant semantic information or business logic directly into your notebook so that Deepnote AI can follow these instructions. Bonus tip: try placing the most important instructions closer to where Deepnote AI is working to prioritize them within its context. This strategy works especially well in SQL blocks. Notice how Deepnote AI picks up on our search query for companies in the financial sector:
+
+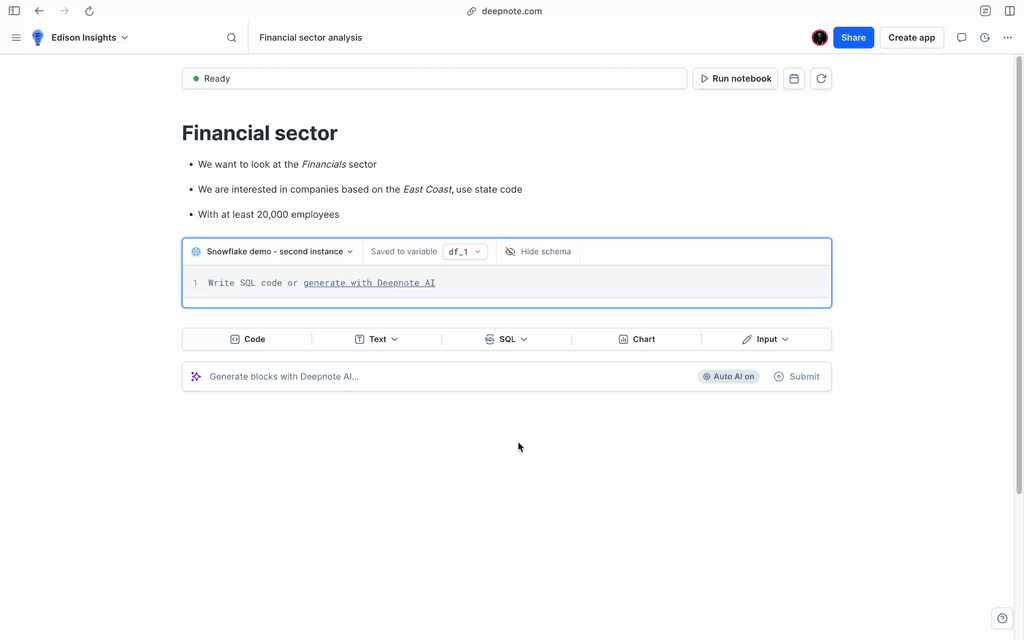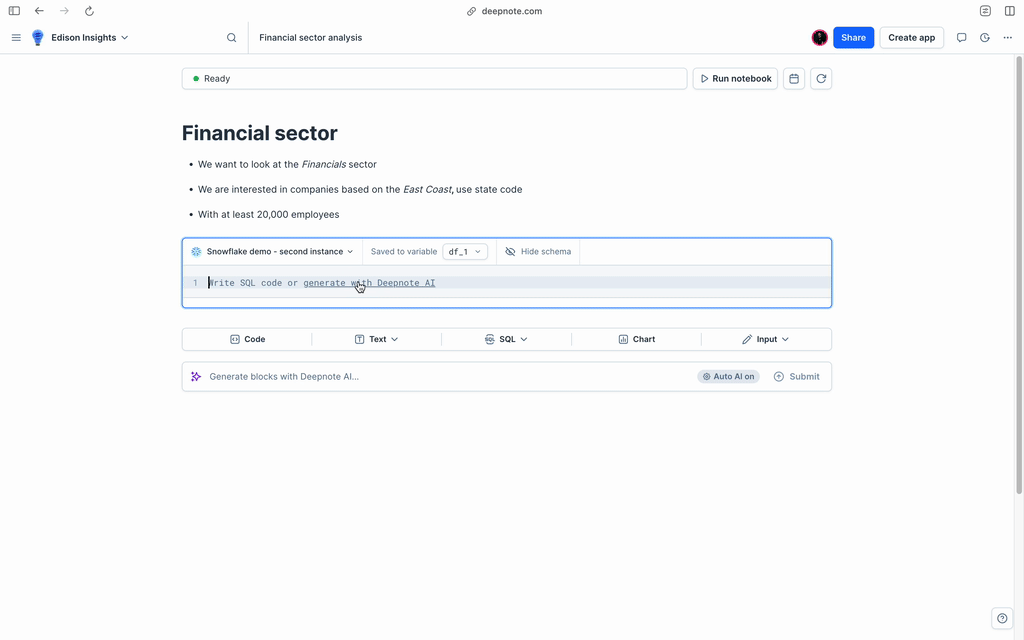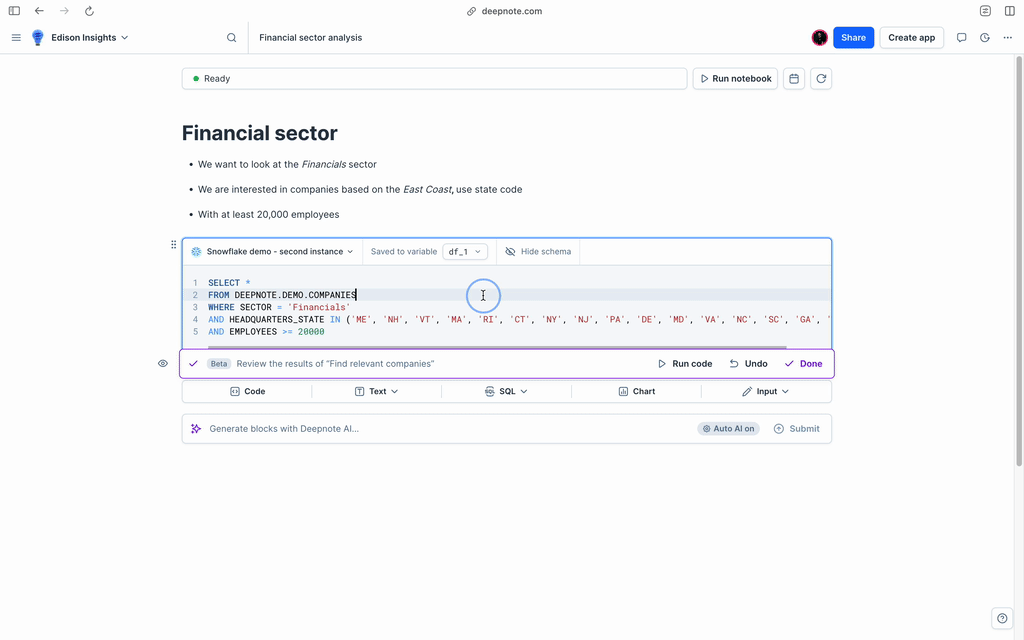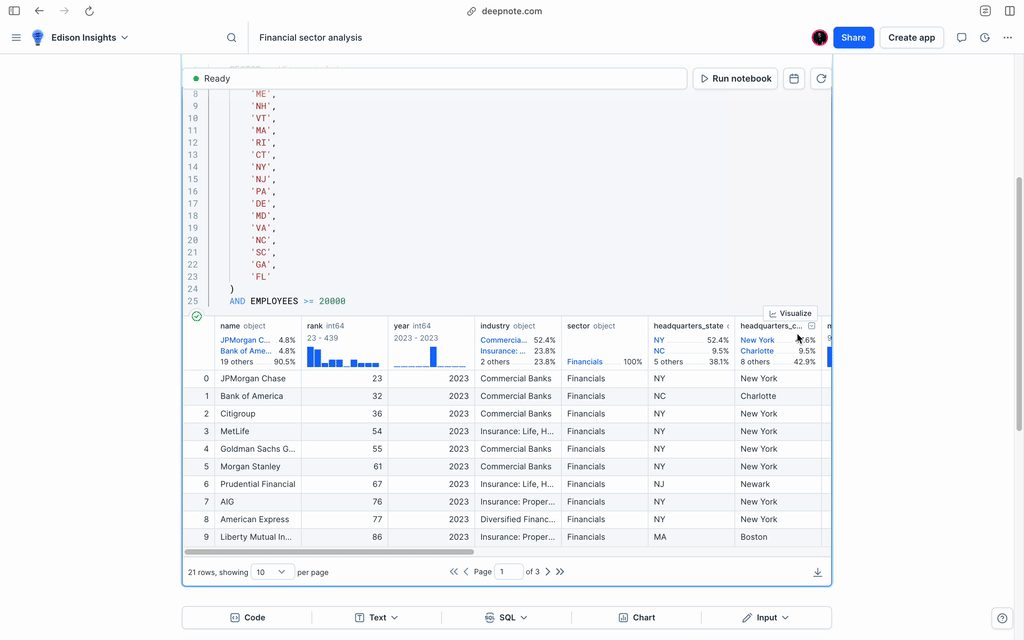
+
+### Referencing notebook variables and files
+
+One of the most powerful features of Deepnote AI is the ability to reference your existing variables and files directly in your prompts. Simply mention variables by name and Deepnote AI will pick them up, including their data type. In case of a DataFrame, Deepnote AI also has access to its columns and their respective data types. When referencing a file, Deepnote AI will check existing notebook variables and automatically import it if it’s missing.
+
+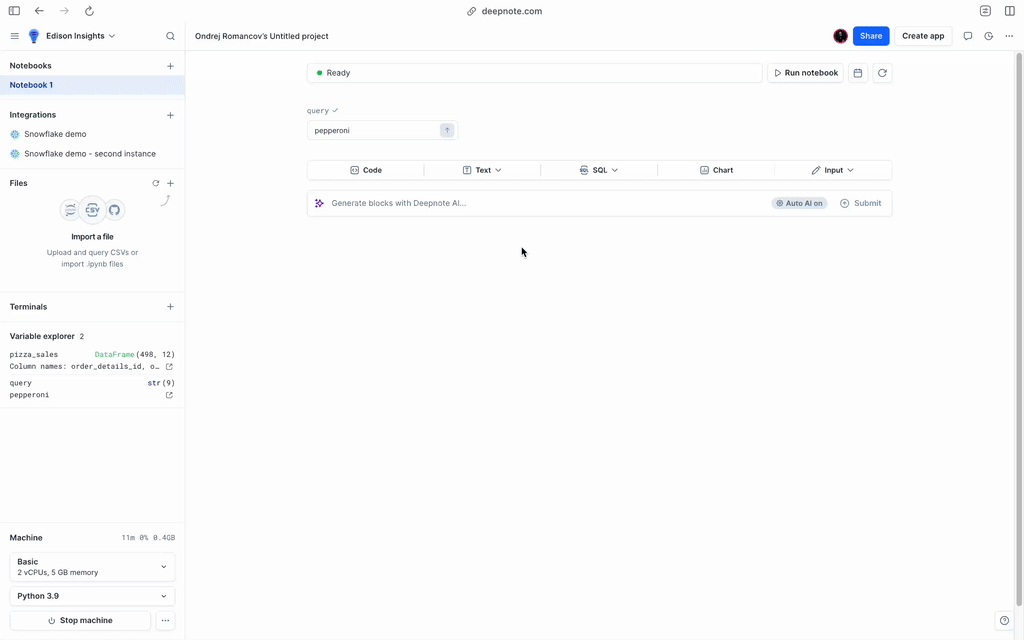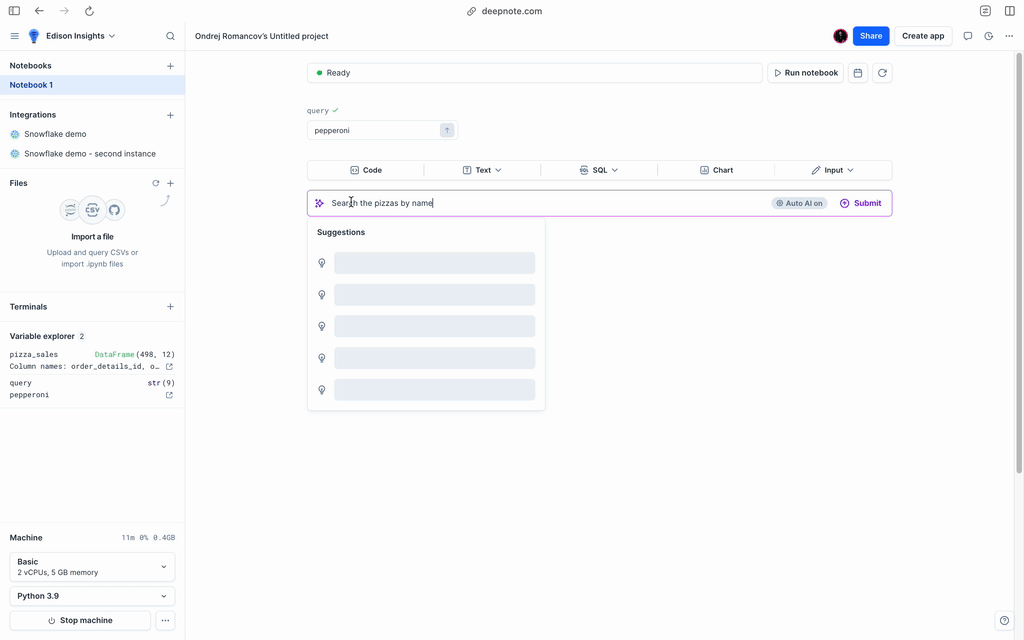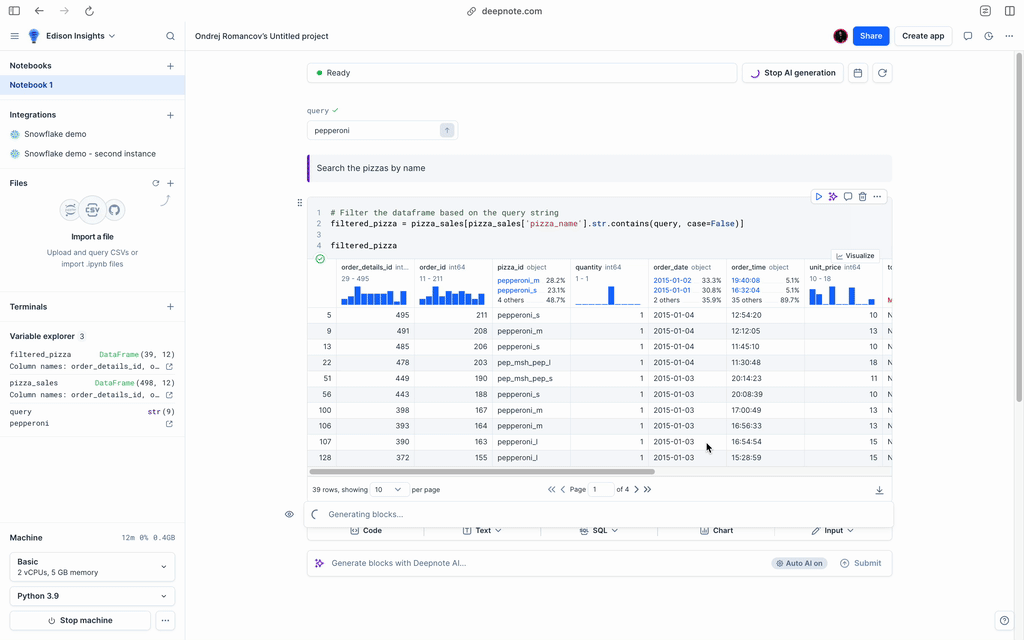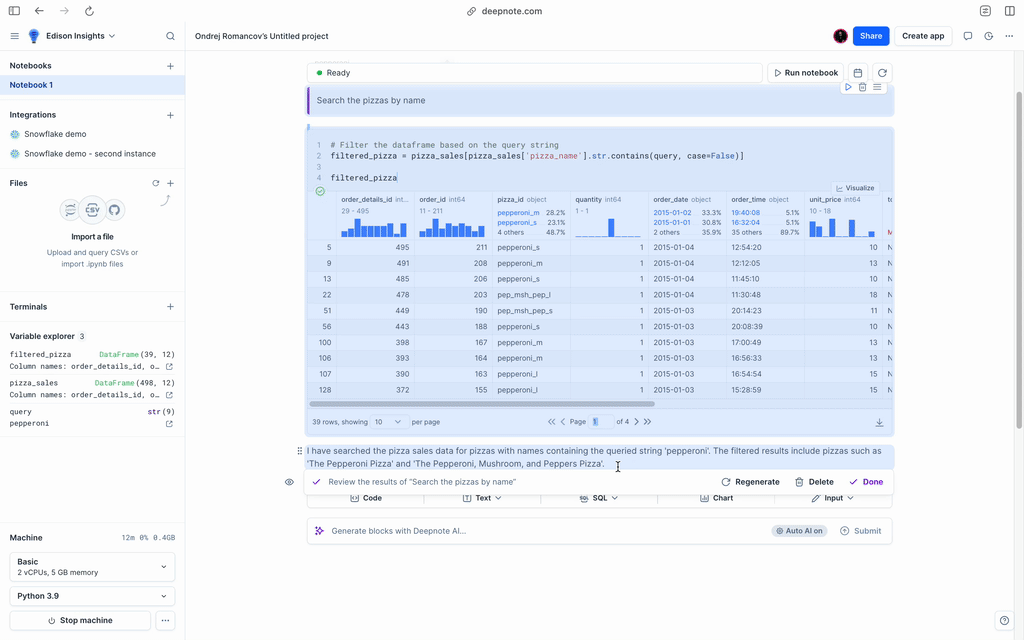
+
+### Iterative prompting
+
+It’s possible that Deepnote AI doesn’t get things right on its first try. If that’s the case, there are several ways you can iteratively achieve your desired output:
+
+1. **Adjust your current prompt**
+
+ Clicking _Undo_/_Delete blocks_ will take you a step back, giving you the ability to edit your prompt. This is perhaps the simplest way to make iterative changes.
+
+2. **Prompt Deepnote AI again**
+
+ If you want to start from scratch, you can always trigger Deepnote AI again in the next block. This is also useful when you want Deepnote AI to continue whatever it was working on prior.
+
+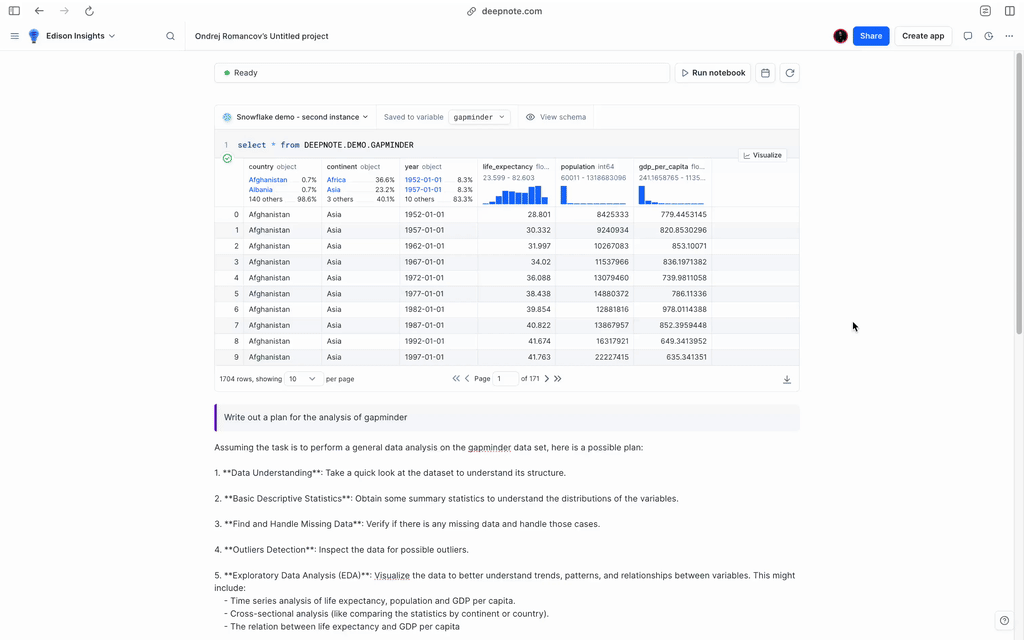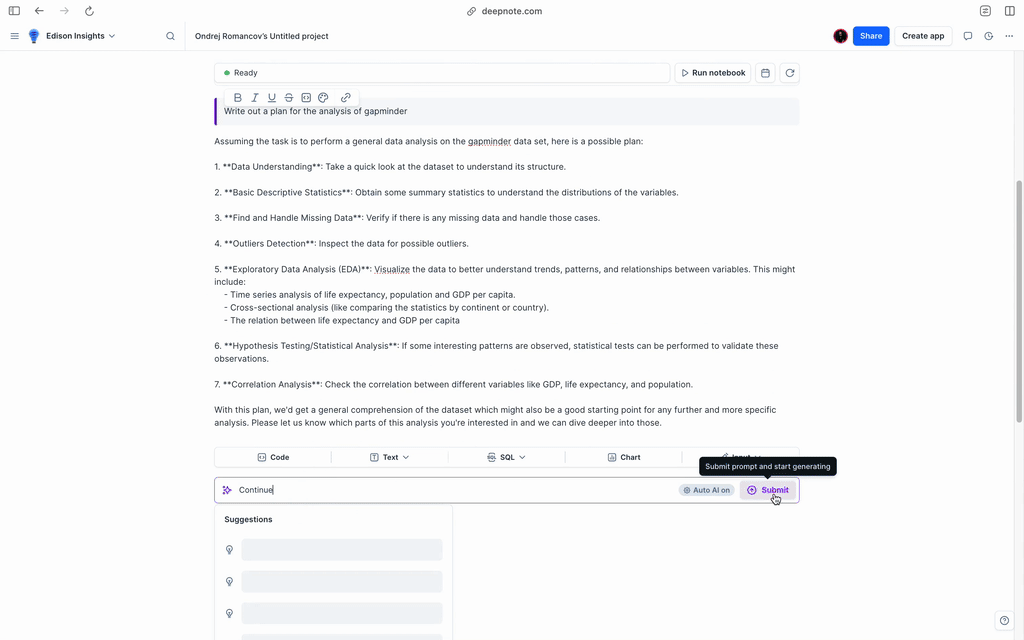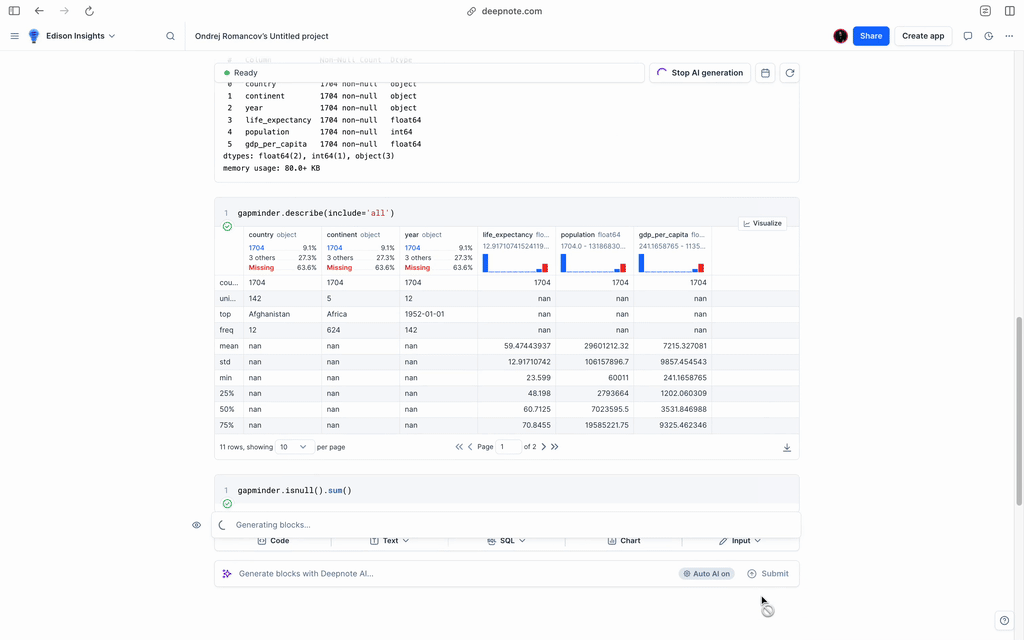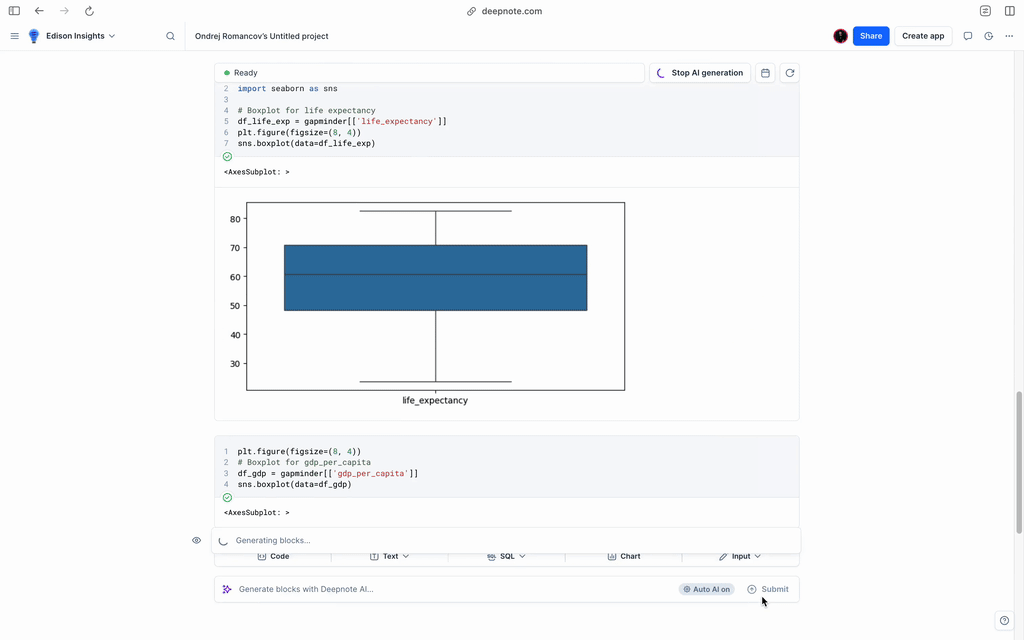
+
+3. **Follow up on your previous prompts**
+
+ In some cases, you may need Deepnote AI to remember its previous outputs. If you accept your previous Deepnote AI outputs, this will help Deepnote AI remember what it has already tried or you can point out yourself exactly what’s wrong with its previous approaches.
+
+4. **Provide more context**
+
+ Apart from these tips, Deepnote AI itself might ask for more information about your problem. In such a case, it’s valuable to utilize Deepnote AI’s thinking, accept the current generation by clicking _Accept/Done_ and ask Deepnote AI to continue in a follow up prompt.
+
+### Combining all Deepnote AI features
+
+Deepnote AI consists of several features, each tailored for a specific use case. To truly make the most out of Deepnote AI, make sure you’re using the strengths of each one.
+
+Auto AI shines in getting you started by generating multiple blocks as well as executing them. With a simple prompt, you will have a solid foundation to build from in no time. It’s also great for exploring possible solutions so you can then prompt it with your hypothesis and quickly check whether it’s worth pursuing further.
+
+Once you’re happy with exploration, you can use the Edit command for granular editing and polishing of your notebook.
diff --git a/docs/python-requirements.md b/docs/python-requirements.md
new file mode 100644
index 0000000000..9172be7016
--- /dev/null
+++ b/docs/python-requirements.md
@@ -0,0 +1,25 @@
+---
+title: Python requirements
+noIndex: false
+noContent: false
+---
+
+### Installing packages through pip
+
+If you install (or uninstall) a package thorough the `!pip` command in a notebook, a suggestion will show up to move that package to `requirements.txt`.
+
+### requirements.txt
+
+If your project contains a `requirements.txt` file in the root of the filesystem, Deepnote automatically installs those requirements when the hardware starts, using the [`init.ipynb`](/docs/project-initialization) notebook. If you manually edit the `requirements.txt`, you will need to run `pip install -r requirements.txt`, either in a notebook or in a terminal.
+
+### Unsupported packages
+
+Some packages are not fully supported yet. If you have problems with a package, please reach out through the support chat in the application.
+
+### Installing packages through a proxy
+
+If you have packages pulled from a custom registry which needs to have an IP allowlisted, Deepnote can route your pip download through a proxy. Simply add the `proxy` argument with our IP `http://34.68.180.189:3128/` to the pip install.
+
+```
+pip install -r requirements.txt --extra-index-url=http://something.com --proxy http://34.68.180.189:3128
+```
diff --git a/docs/real-time-collaboration.md b/docs/real-time-collaboration.md
new file mode 100644
index 0000000000..017ae62e5c
--- /dev/null
+++ b/docs/real-time-collaboration.md
@@ -0,0 +1,19 @@
+---
+title: Real-time collaboration
+noIndex: false
+noContent: false
+---
+
+Deepnote supports real-time collaboration. When team members [join your project](/docs/share-projects), you'll see their avatar appear in the top right. You and your team are now sharing the same execution environment at the same time.
+
+
+
+In order to prevent inadvertent code changes, two collaborators cannot write into the same block at the same time.
+
+
+
+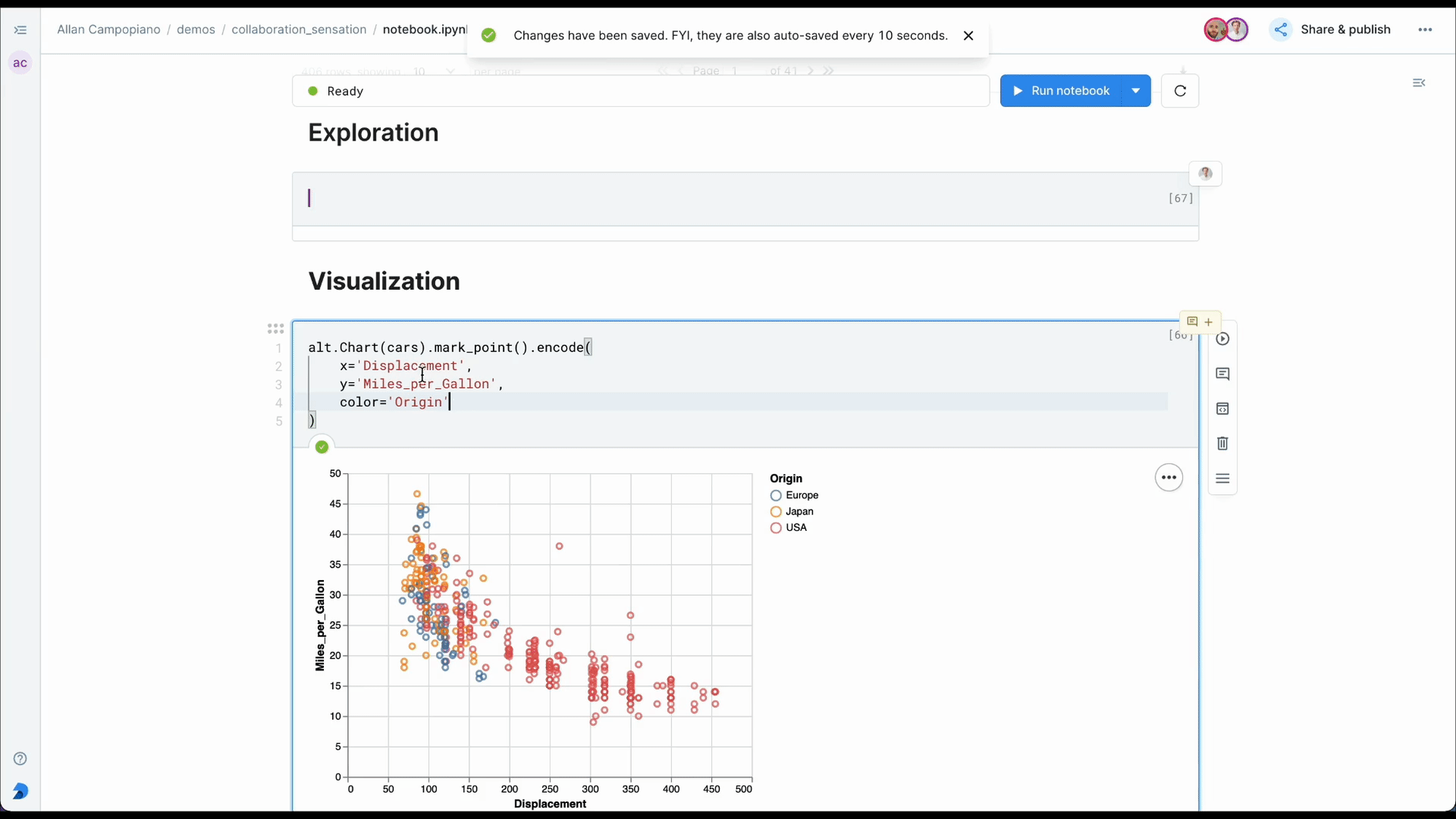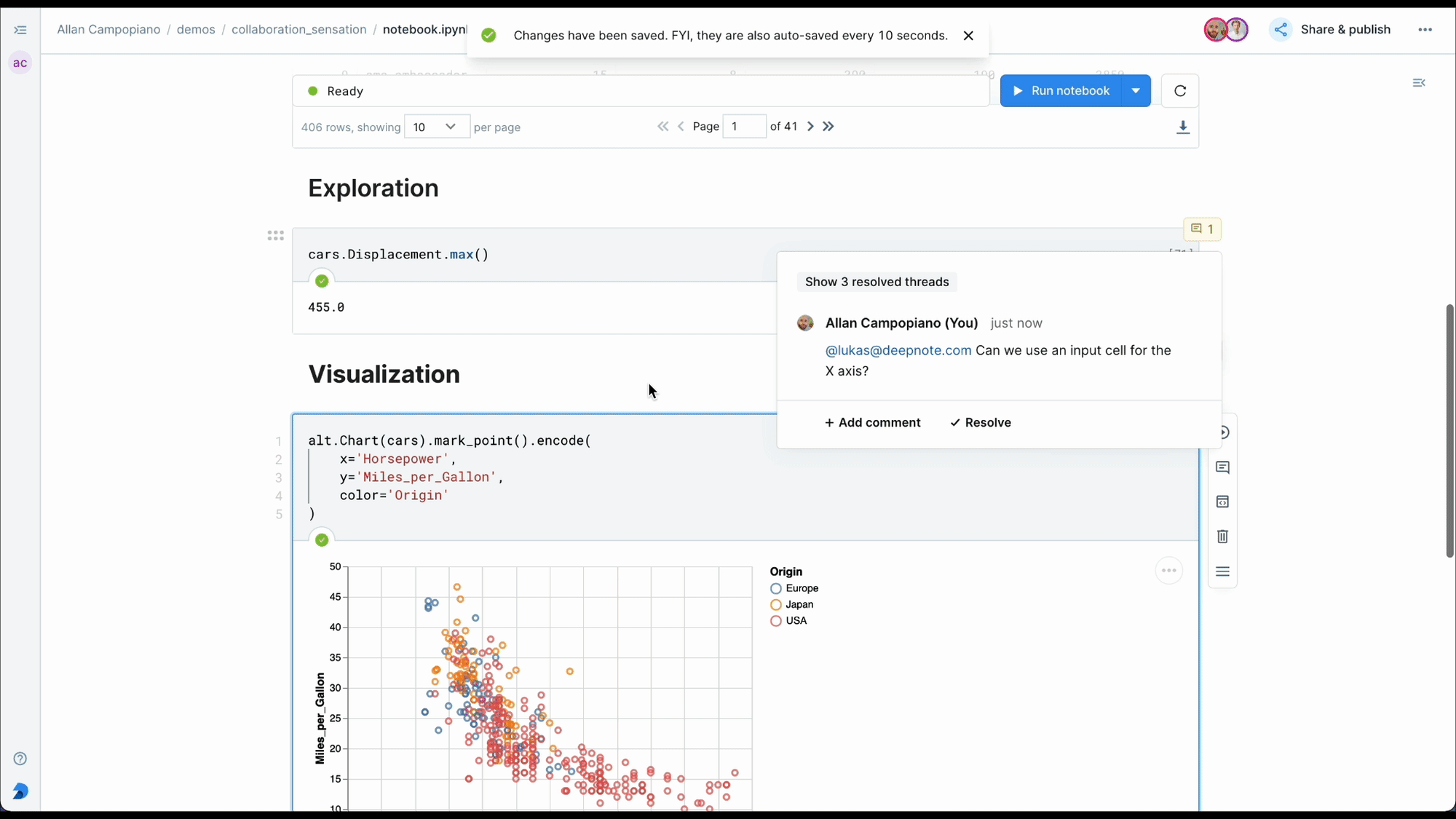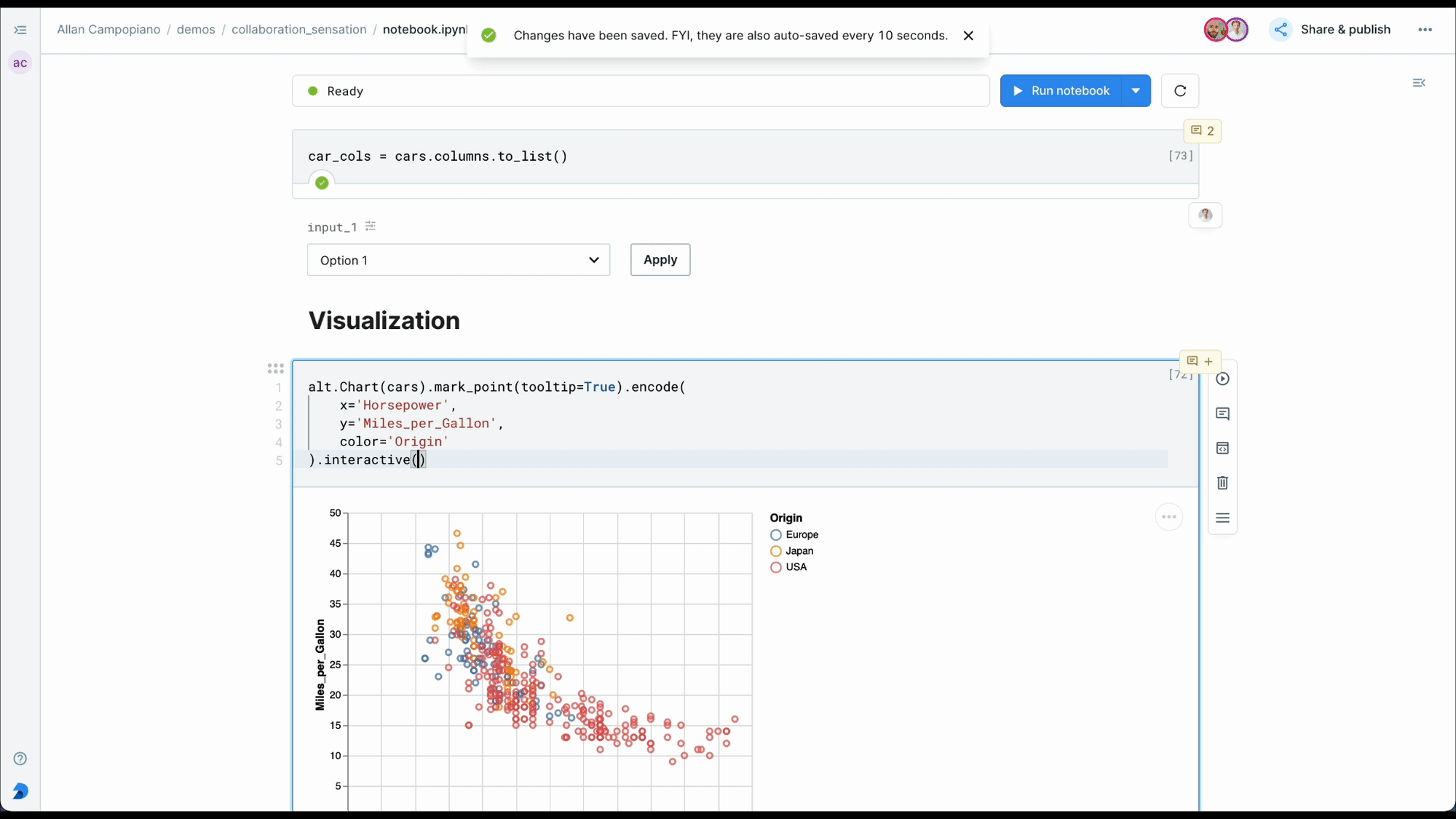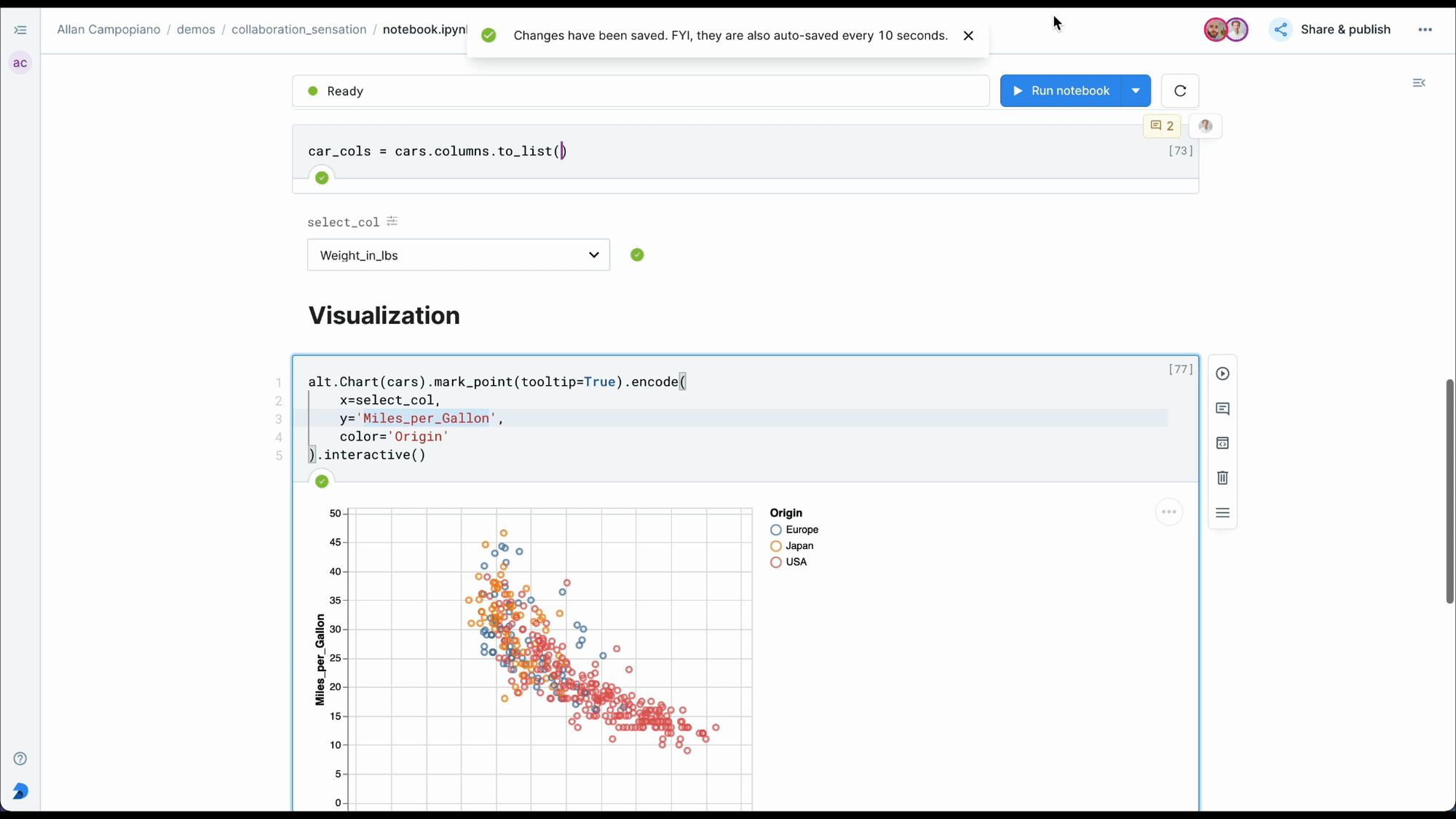
+
+### Jump to collaborator
+
+You can navigate to the place in the notebook that your collaborator is editing by clicking on their avatar in the top right corner 🙌.
diff --git a/docs/restoring-variables.md b/docs/restoring-variables.md
new file mode 100644
index 0000000000..71df8e29cb
--- /dev/null
+++ b/docs/restoring-variables.md
@@ -0,0 +1,19 @@
+---
+title: Restoring variables
+noIndex: false
+noContent: false
+---
+
+When you return to your notebook after your machine went offline (eg. due to a period of [inactivity](https://docs.deepnote.com/environment/long-running-jobs#how-deepnote-decides-when-to-turn-off-hardware-of-a-project)) you will usually have an option to restore variables from your previous session.
+
+If you wish to do so, click on the restore variables button displayed in the notebook's status bar at the top. This will restore **all the variables from your previous session** in the state they were at when your hardware was shut down.
+
+
+
+There are a couple of limitations to keep in mind:
+
+- **Restoring variables is not always possible**. We only display the restore option if we could successfully save all your variables in your previous session.
+ The most common reasons for not being able to save session context are:
+ - the given variable may be too large;
+ - the variable type is not supported (eg. `SparkContext`, and tensorflow `StackSummary`).
+- You can only restore variables **before starting your machine**. If you execute a block without restoring variables first then you will lose access to your previous context and your stored variables will be deleted.
diff --git a/docs/running-your-own-kernel.md b/docs/running-your-own-kernel.md
new file mode 100644
index 0000000000..4e3a77f023
--- /dev/null
+++ b/docs/running-your-own-kernel.md
@@ -0,0 +1,149 @@
+---
+title: Running your own kernel
+noIndex: false
+noContent: false
+---
+
+If you need to work with different language then Python, the Jupyter ecosystem provides you with a vast selection of other kernels. You can now run them in Deepnote!
+
+
+**Deepnote's support for other kernels is still in its early days.**
+
+Some features don't work yet. This includes including the variable explorer, SQL cells, input cells, and autocomplete.
+
+
+
+Deepnote uses the environment variable `DEFAULT_KERNEL_NAME` that you set in the Dockerfile and uses it to create new notebooks with that kernel.
+
+
+The best way to run a custom kernel is to find an existing image, for example on [Dockerhub](https://hub.docker.com/search?q=jupyter&type=image), and then set the environment variable `DEFAULT_KERNEL_NAME`. To override the default kernel, you must modify the metadata in the .ipynb file. An alternative method is to install the kernel into the default Deepnote image, see examples below.
+
+## R kernel
+
+In the right sidebar, pick your preferred version of R from the dropdown in the environment section. We recommended choosing the `deepnote/ir_with_libs` image. This will install R 4.2 and many common data science libraries for you (see the image details [here](https://hub.docker.com/r/deepnote/ir-with-libs)).
+
+### Installing R packages
+
+#### In the default R environments
+
+You can simply use the `install.packages` and `library` commands the way you normally would.
+
+R packages often take a long time to install. We install them to your `work` folder by setting your environment variable `R_LIBS_USER="~/work/.R/library"`, so they stay there during hardware restarts.
+
+#### In your custom environment
+
+If you're comfortable using your own Docker image, the preferred way would be to install the packages at build time, or pick from the large selection on Dockerhub.
+
+## Julia kernel
+
+Use custom Dockerfile in the environment tab, and build an image with the following code:
+
+```bash
+FROM deepnote/python:3.7
+
+RUN wget https://julialang-s3.julialang.org/bin/linux/x64/1.6/julia-1.6.2-linux-x86_64.tar.gz && \
+ tar -xvzf julia-1.6.2-linux-x86_64.tar.gz && \
+ mv julia-1.6.2 /usr/lib/ && \
+ ln -s /usr/lib/julia-1.6.2/bin/julia /usr/bin/julia && \
+ rm julia-1.6.2-linux-x86_64.tar.gz && \
+ julia -e "using Pkg;pkg\"add IJulia\""
+
+ENV DEFAULT_KERNEL_NAME "julia-1.6"
+```
+
+## Bash kernel
+
+Use custom Dockerfile in the environment tab, and build an image with the following code:
+
+```bash
+FROM deepnote/python:3.7
+
+RUN pip install --no-cache-dir notebook bash_kernel && \
+ python -m bash_kernel.install
+ENV DEFAULT_KERNEL_NAME "bash"
+```
+
+## Scala 2.12 kernel (Almond 0.13.2)
+
+Use a custom Dockerfile in the environment tab, and build an image with the following code:
+
+```bash
+FROM almondsh/almond:latest
+
+ENV DEFAULT_KERNEL_NAME "scala212"
+```
+
+## Racket kernel
+
+Use custom Dockerfile in the environment tab, and build an image with the following code:
+
+```bash
+FROM deepnote/python:3.7
+
+# The following snippet is licensed under MIT license
+# SEE: https://github.com/jackfirth/racket-docker
+
+RUN apt-get update && \
+ apt-get install -y libzmq5 && \
+ pip install --no-cache-dir notebook && \
+ apt-get purge -y --auto-remove && \
+ rm -rf /var/lib/apt/lists/*
+
+ENV RACKET_INSTALLER_URL=http://mirror.racket-lang.org/installers/7.8/racket-7.8-x86_64-linux-natipkg.sh
+ENV RACKET_VERSION=7.8
+
+RUN wget --output-document=racket-install.sh -q ${RACKET_INSTALLER_URL} && \
+ echo "yes\n1\n" | sh racket-install.sh --create-dir --unix-style --dest /usr/ && \
+ rm racket-install.sh
+
+ENV SSL_CERT_FILE="/etc/ssl/certs/ca-certificates.crt"
+ENV SSL_CERT_DIR="/etc/ssl/certs"
+
+RUN raco setup && \
+ raco pkg config --set catalogs \
+ "https://download.racket-lang.org/releases/${RACKET_VERSION}/catalog/" \
+ "https://pkg-build.racket-lang.org/server/built/catalog/" \
+ "https://pkgs.racket-lang.org" \
+ "https://planet-compats.racket-lang.org" && \
+ raco pkg install --auto iracket && \
+ raco iracket install
+
+ENV DEFAULT_KERNEL_NAME "racket"
+```
+
+Thanks, [@dkvasnickajr](https://twitter.com/dkvasnickajr/status/1321901316411711490?s=20) for [sharing this](https://gist.github.com/dkvasnicka/9e7f5c516e997d3f3f00b0256755b906)!
+
+You can [clone this project from Deepnote](https://deepnote.com/project/ead07c75-5f57-49c3-b2a9-3b1b62bd5c59#%2Fnotebook.ipynb).
+
+## Ruby
+
+Use custom Dockerfile in the environment tab, and build an image with the following code:
+
+```bash
+FROM deepnote/python:3.7
+
+RUN apt-get update -qq && \
+ apt-get install -y --no-install-recommends \
+ libtool libffi-dev libzmq3-dev libczmq-dev \
+ make ruby-full && \
+ gem install ffi-rzmq && \
+ gem install iruby --pre && \
+ apt-get purge -y --auto-remove && \
+ rm -rf /var/lib/apt/lists/*
+
+ENV DEFAULT_KERNEL_NAME=ruby
+```
+
+Then replace the content of your 'Init' notebook with following:
+
+```bash
+!iruby register --force
+```
+
+After resetting the project state, you should be able to use Ruby in your notebooks.
+
+### Ruby On Rails
+
+We have[ published a tutorial](https://deepnote.com/@deepnote/Ruby-on-Rails-in-Deepnote-QF-mn5foT7y3lfI_ItXf7g) to help your run an existing Ruby on Rails project in Deepnote. One of the use cases is querying your data based on the existing ActiveRecord models, theirs scopes and relations.
+
+##
diff --git a/docs/scheduling.md b/docs/scheduling.md
new file mode 100644
index 0000000000..1ee70bb57f
--- /dev/null
+++ b/docs/scheduling.md
@@ -0,0 +1,40 @@
+---
+title: Scheduling
+noIndex: false
+noContent: false
+---
+
+Deepnote lets you execute your notebooks on a daily, weekly, monthly or hourly basis, or with a custom cron string. This is useful if you want to process data or update a dashboard at a regular frequency.
+
+
+Scheduling is available on Team, Pro and Enterprise plans. Hourly and custom schedule is available on Enterprise plan only.
+
+
+### From exploratory analysis to production pipelines
+
+Deepnote makes it easy to take your explorations to production. For example:
+
+1. Imagine you build a churn prediction model and store it in the filesystem. You can add a second notebook to your project which runs on a weekly basis, fetches the activity data of your customers from the warehouse, runs a prediction, and triggers a retention campaign.
+2. You can build a lead scoring model, and [create an app](/docs/creating-apps) which displays the most promising leads to your account executives. However, since you have so many leads and a very advanced model, the process might take a bit of time. You can schedule the notebook to run just before the sales team comes to work, so that the app contains fresh info whenever as soon as they open it.
+
+### How to schedule a notebook
+
+1. Click the calendar icon **Schedule notebook**, which is at the top of the notebook, right next to the **Run notebook** button
+2. Configure the frequency at which you would like the notebook to run and then click **Save.**
+3. Additionally, you can also configure notifications for successful and failed runs, either by email or into Slack.
+
+
+
+### How to know if your scheduled notebook ran successfully
+
+If an exception is raised during the run, the run is considered as failed, otherwise it's successful. Please note that if an error is raised in a block, the subsequent blocks are not executed. In addition, you will find a log and snapshot of successful and/or failed runs in the _Version history_ Tab.
+
+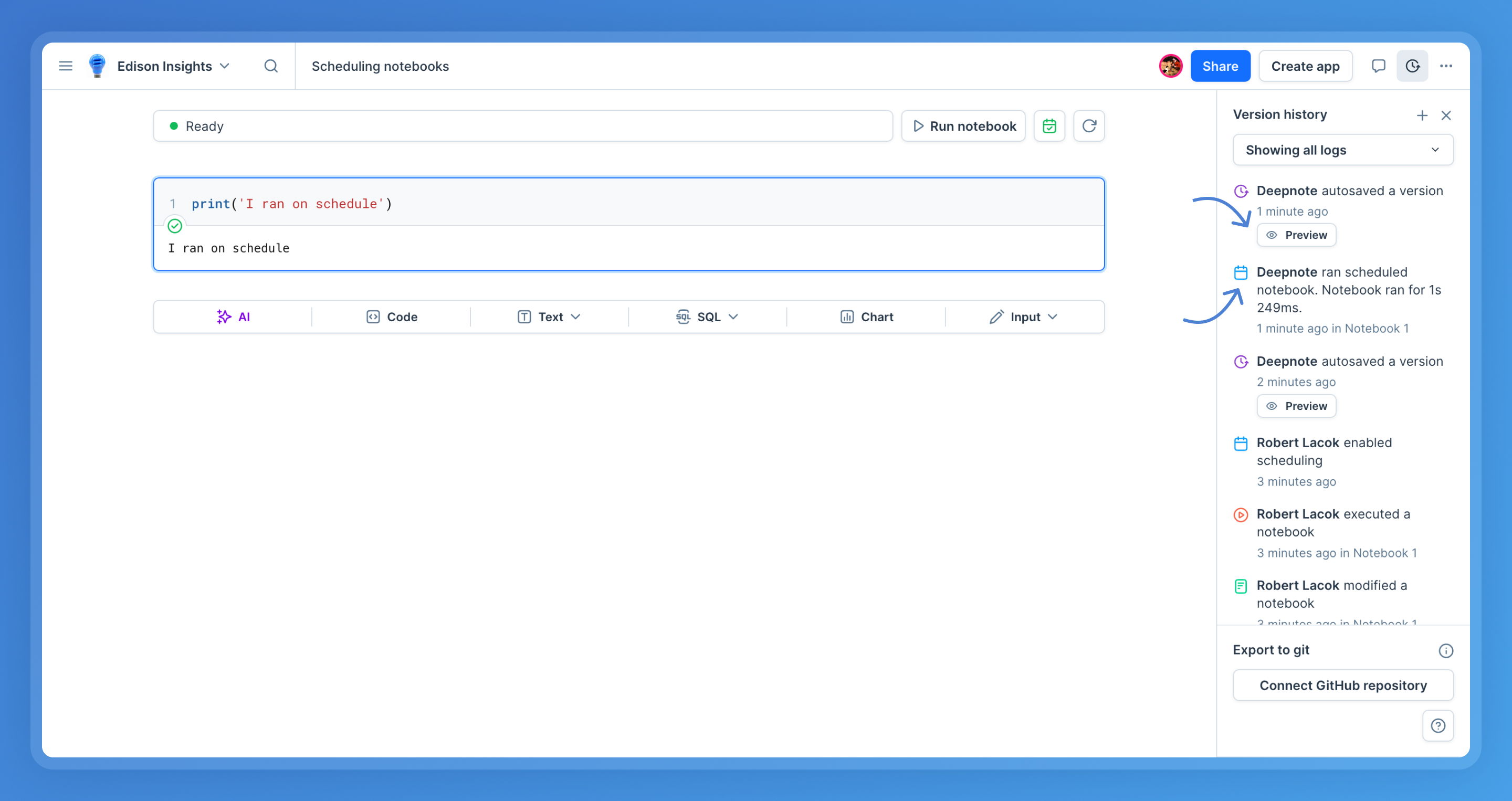
+
+### Alerts
+
+You can use the scheduled notebook to periodically check the consistency of your data and use the notification system to alert you when the notebook fails (i.e. the consistency check fails).
+
+### Current limitations
+
+- Only one scheduled notebook per project is supported. If you need to schedule more, we recommend splitting the work across multiple projects.
diff --git a/docs/schema-browser.md b/docs/schema-browser.md
new file mode 100644
index 0000000000..4639314f86
--- /dev/null
+++ b/docs/schema-browser.md
@@ -0,0 +1,74 @@
+---
+title: Schema browser
+description: Explore the structure of your data with Deepnote's built-in schema browser.
+noIndex: false
+noContent: false
+---
+
+## Exploring the structure of your databases
+
+What comes before a great query? A thoughtful, high-level exploration of your database's tables and columns. Our native schema browser makes it easy to navigate the structure of your data warehouse/database, directly from the notebook. It also features a number of handy shortcut actions which can help you compose your SQL queries more efficiently.
+
+### Opening the schema browser
+
+Once you have connected a data warehouse or database to your project, you can open the schema browser in two ways.
+
+1. Add an SQL block to the notebook and click on the block’s **View schema** button.
+2. Alternatively, you can click on a connected integration in the **Integrations** section in the right side bar.
+
+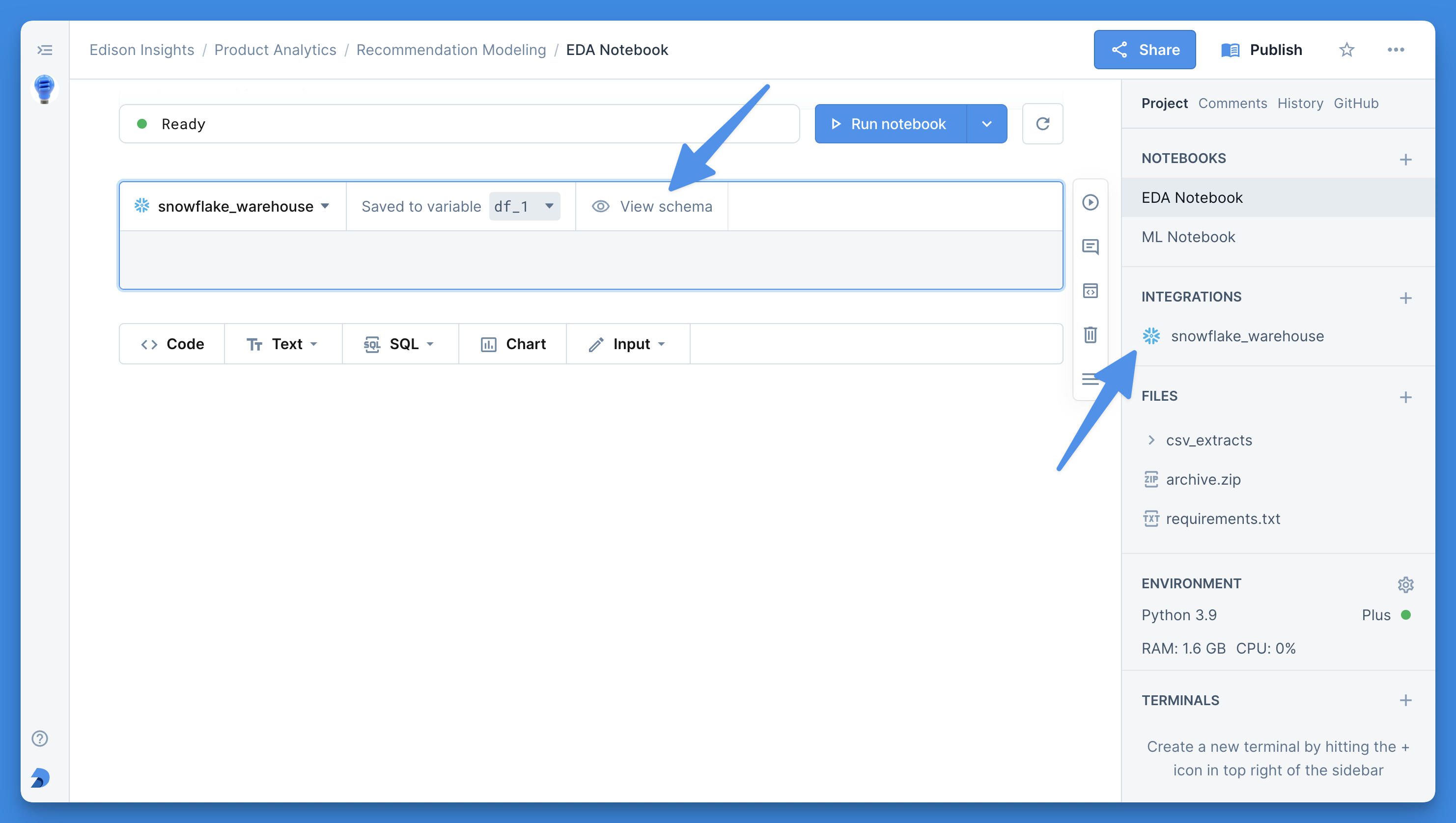
+
+
+
+The following native SQL integrations currently support schema browsing: [Snowflake](https://deepnote.com/docs/snowflake), [Google BigQuery](https://deepnote.com/docs/google-bigquery), [Amazon Redshift](https://deepnote.com/docs/redshift), [PostgreSQL](https://deepnote.com/docs/postgresql), [Microsoft SQL Server](https://deepnote.com/docs/sql-server), [Trino](https://deepnote.com/docs/trino), [Amazon Athena](https://deepnote.com/docs/amazon-athena), [Clickhouse](https://deepnote.com/docs/clickhouse).
+
+
+
+### Navigating the schema
+
+The schema browser has three main components: the search bar, the schema tree, and the table details.
+
+#### Search bar
+
+Simply start typing to find matching **tables and columns** from across all your databases and schemas within the given integration. The matching items will be highlighted in the search results. The search results are divided into two separate tabs: tables and columns.
+
+Once you click on a result, the corresponding table’s info will open up in the table details panel at the bottom.
+
+
+For extremely large schemas (> than 2k tables), column search will be disabled. You can still search for table names in these cases.
+
+
+
+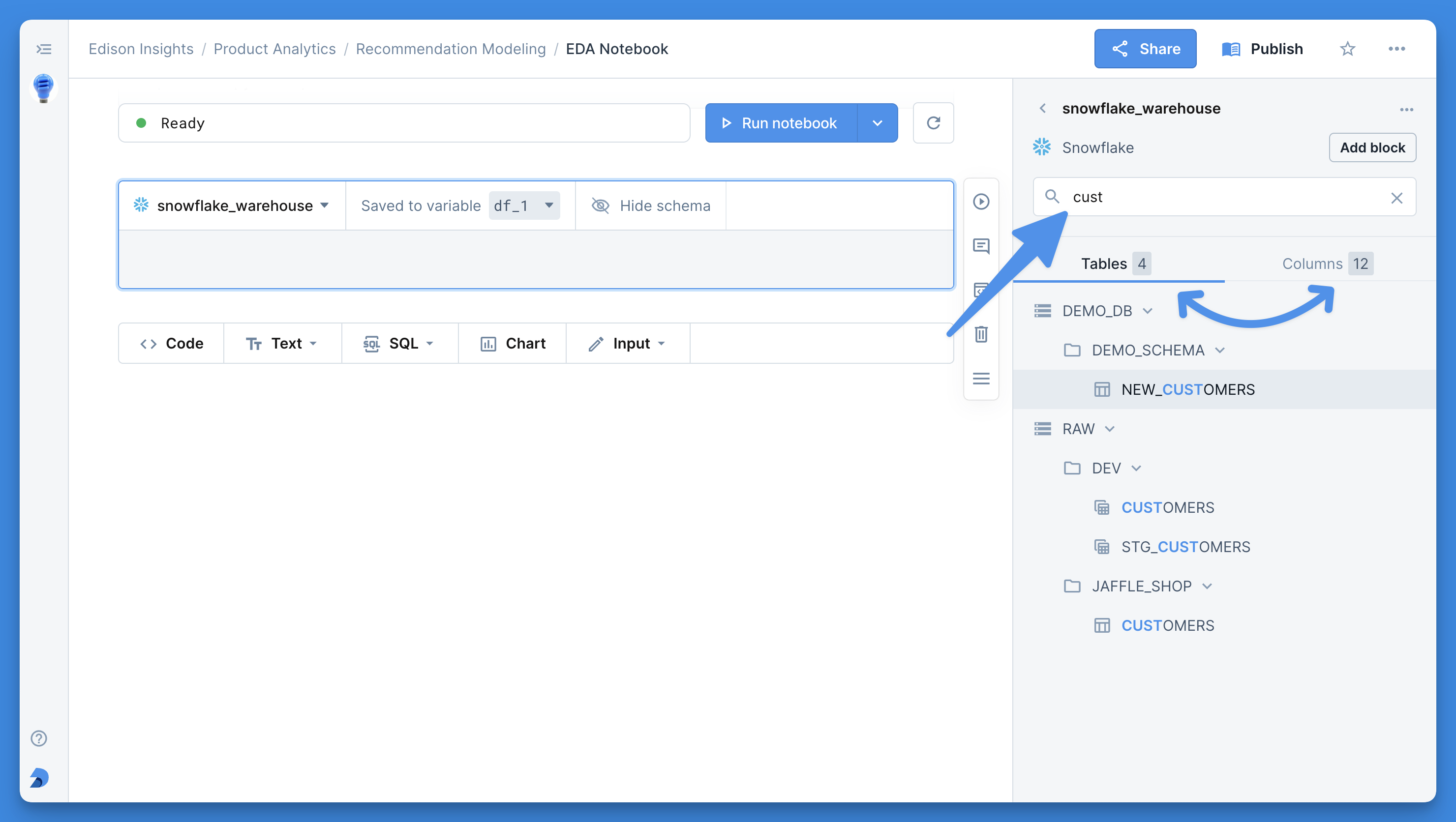
+
+#### Schema tree
+
+You can freely navigate your schema by opening and collapsing the various objects. Click on a table to view its columns and other details in the table details panel.
+
+You can also access other useful table actions via the context menu when you hover over a table. For example,
+
+- **Query table:** adds a new SQL block to your notebook with a pre-populated query for the given table (shown below). This is particularly useful for quickly previewing the contents of the table.
+- **Copy qualified table name:** copies the name of the table to your clipboard including its full path in the schema. You can then simply insert it into your SQL block to start querying the table.
+
+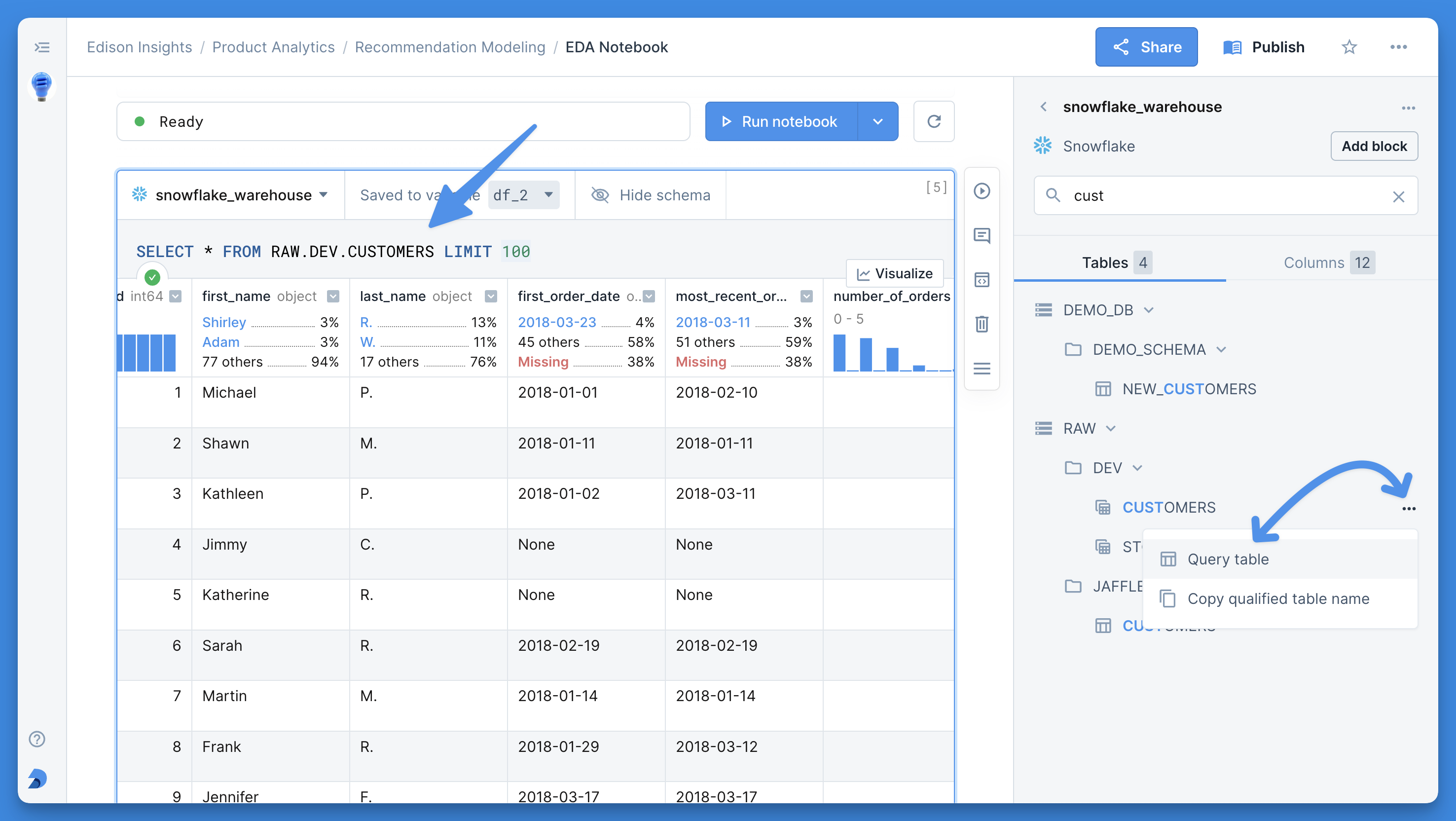
+
+#### Table details
+
+The bottom panel shows you details about the selected table.
+
+You can see a list of all the columns and their associated data types. You can hover over a column and click on the copy icon to copy the column’s name to the clipboard.
+
+The context menu in the upper right corner offers helpful table actions. These are identical to those available in the schema tree, with a couple of additions:
+
+- **Copy all columns**: copy a list of comma-separated columns names
+- **Go to table in tree view**: clicking on this will navigate to the table in the schema tree. This can be useful if you opened a table in the search results and would like to quickly jump to its place within your schema hierarchy.
+
+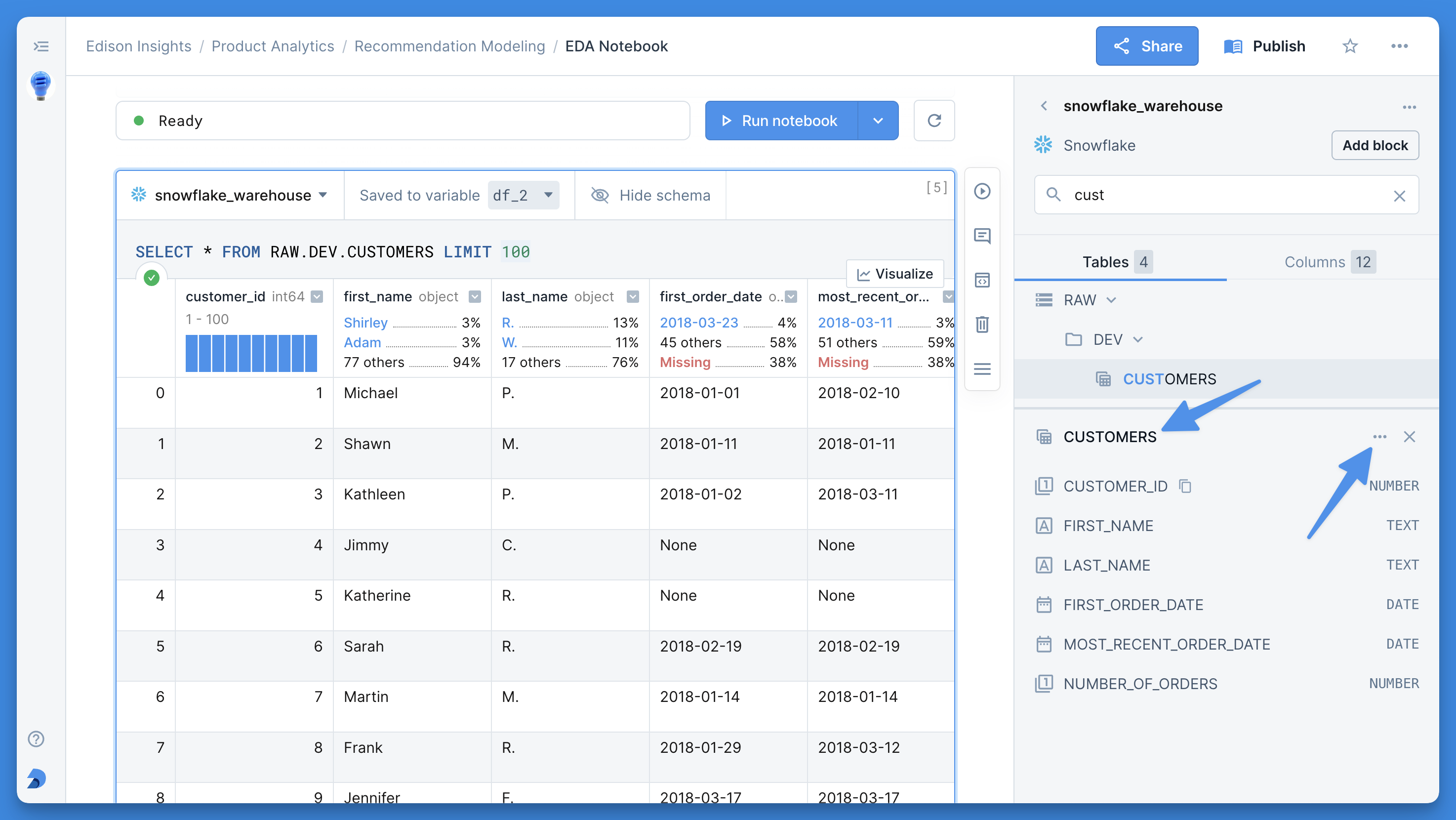
+
+### Refreshing the schema
+
+To provide a fast and seamless experience, the schema for a given integration is downloaded and stored by Deepnote after it is first opened. By default, this cached version will be served whenever a workspace member visits the schema browser.
+
+The cached version is retained for 7 days (or until the integration details are changed). After this expiration date, we automatically re-fetch the latest state of the schema when someone views the schema browser.
+
+If you need to access the freshest schema for your work, you can manually force an update. Click on the context menu displayed in the integration’s header and select **Refresh**.
diff --git a/docs/securing-connections.md b/docs/securing-connections.md
new file mode 100644
index 0000000000..d3e9f0a84e
--- /dev/null
+++ b/docs/securing-connections.md
@@ -0,0 +1,123 @@
+---
+title: Securing connections
+description: Data is the core of your work in Deepnote — that's why we prioritize keeping it safe. Here's how to secure connections to your data and ensure end-to-end privacy.
+noIndex: false
+noContent: false
+---
+
+## Connecting to databases on private networks
+
+You can choose one of two ways to authorize Deepnote to connect to your database. You can authorize the set of IP addresses that Deepnote uses to connect or you can connect using an SSH tunnel.
+
+### Authorizing Deepnote's IP addresses
+
+
+
+Authorizing Deepnote's IP addresses is only available on the [**Team plan**](https://deepnote.com/pricing) and the [**Enterprise plan**](https://deepnote.com/pricing), excluding Team Trial periods. Authorizing Deepnote's IP addresses is not available on the Education plan.
+
+
+
+Deepnote has fixed IP addresses you will need to authorize.
+
+```
+107.22.50.0
+18.214.47.38
+3.217.84.43
+3.229.1.246
+3.230.201.213
+44.216.70.44
+52.21.216.28
+52.55.205.54
+54.144.37.244
+54.165.20.26
+54.235.42.8
+54.242.142.100
+```
+
+Here are quick-start guides for changing the firewall/security settings:
+
+- [Deepnote's Google Cloud guide for GCP Cloud Postgres](https://deepnote.com/@deepnote/Static-IP-addresses-wsfusHNVQUWlAPHzuoDXFQ)
+- [AWS](https://docs.aws.amazon.com/vpc/latest/userguide/security.html)
+- [Google Cloud ](https://cloud.google.com/vpc/docs/firewalls)
+- [Snowflake](https://docs.snowflake.com/en/user-guide/network-policies.html)
+
+### Using SSH to connect to your data
+
+You can connect to selected data warehouses and database integrations via a secure SSH tunnel that is configurable in the **Integrations** menu. Deepnote automatically generates a public SSH key for your workspace that you can add it to the authorized keys file (`~/.ssh/authorized_keys`) on your SSH bastion.
+
+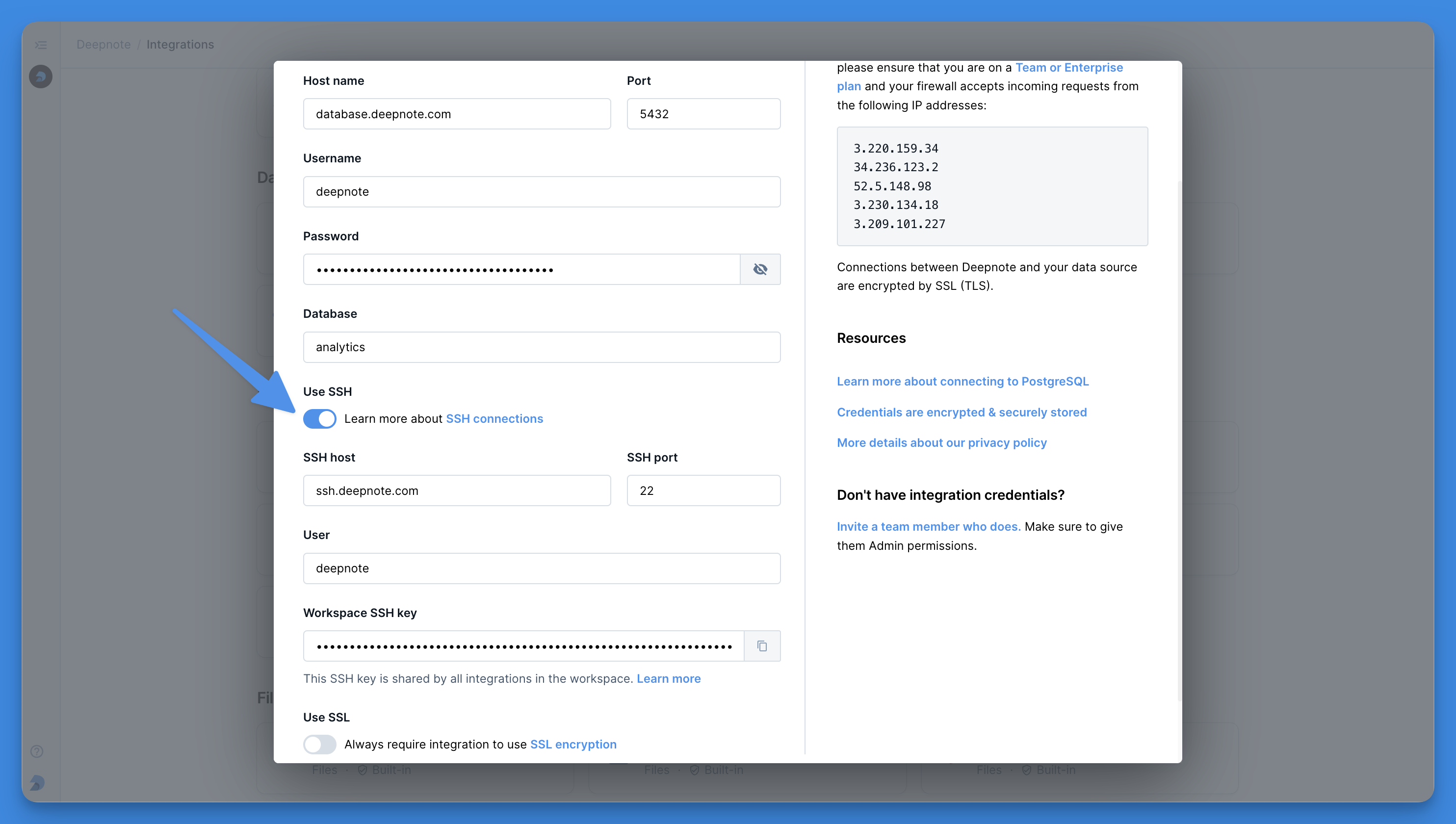
+
+If you query a database with SSH configured from an SQL block, Deepnote will automatically create an SSH tunnel.
+
+The following Integrations support SSH tunnels:
+
+- PostgreSQL
+- Microsoft SQL Server
+- Amazon Redshift
+- MongoDB
+- MySQL
+- ClickHouse
+- MindsDB
+- MariaDB
+- Dremio
+- Trino
+
+### SSH Tunnel integration
+
+
+The feature is available on the Enterprise plan.
+
+
+The SSH Tunnel integration allows you to securely connect to resources in your private network. For example, you may want to connect to an experiment tracking tool (such as MLflow), a database without native integration in Deepnote (such as Redis), or a feature store (such as Feast) hosted on your network.
+
+Deepnote automatically generates a public SSH key for your workspace. You can copy it from the SSH tunnel integration modal and add it to the authorized keys file (~/.ssh/authorized_keys) on your SSH bastion.
+
+When you connect the integration to the project, the SSH tunnel starts in the background and exposes the host and port that you can use to access your data. Here's an example, along with code that demonstrates how to use the SSH Tunnel integration to query a private API that provides daily candles for a given ticker.
+
+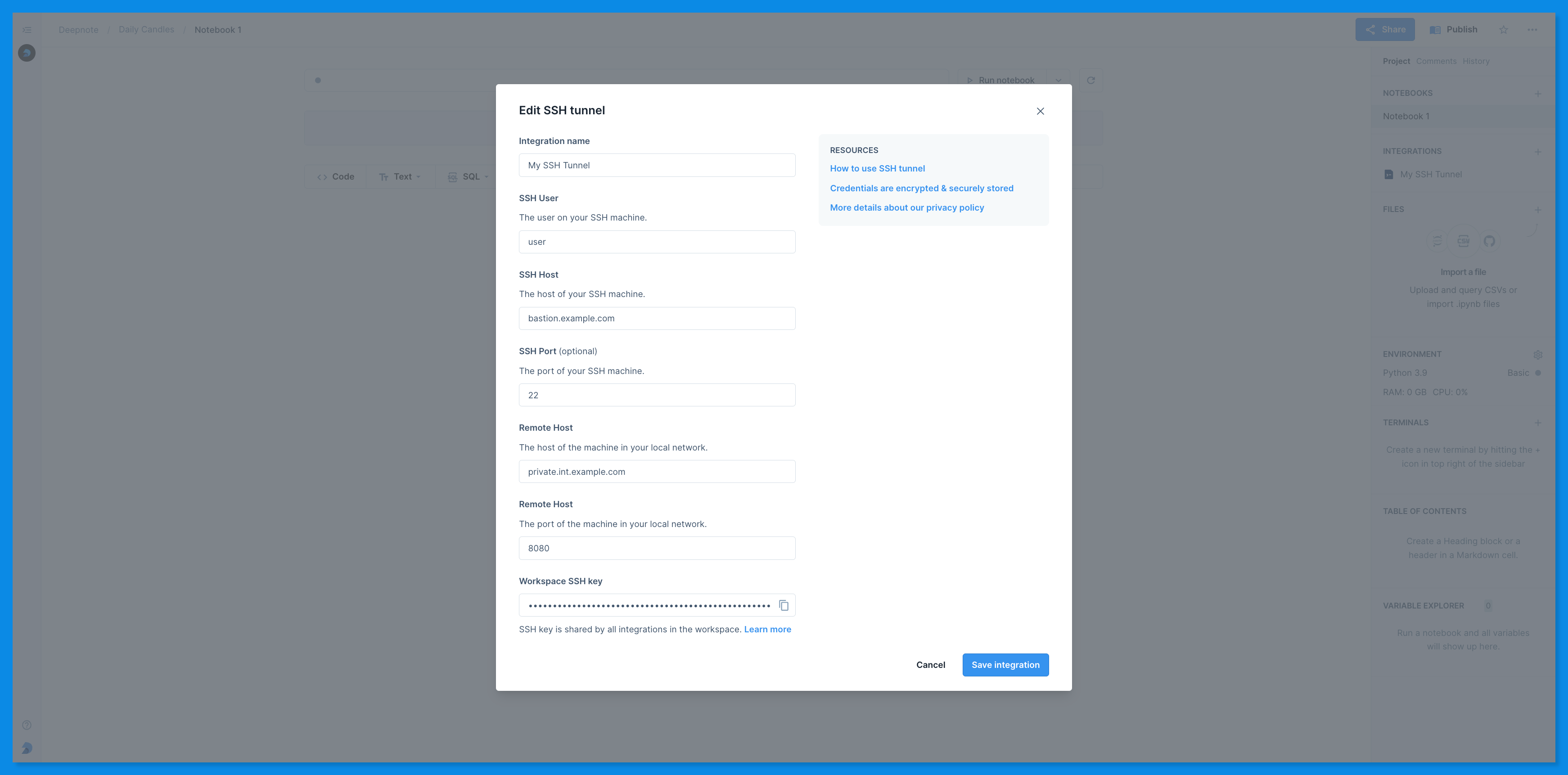
+
+```python
+
+import os
+import requests
+
+# Get the local host and port from environment variables
+# Note – you may need to change the variable names as they contain the integration name
+HOST = os.environ['MY_SSH_TUNNEL_LOCAL_HOST']
+PORT = os.environ['MY_SSH_TUNNEL_LOCAL_PORT']
+
+# Set up the URL for the API endpoint
+url = f'http://{HOST}:{PORT}/daily-candles/XYZ'
+
+# Make the API request
+response = requests.get(url)
+
+# Print the response content
+print(response.content)
+```
+
+To find the environment variable names for your integration, you can open the three-dot menu of the integration in the right sidebar and click "How to use".
+
+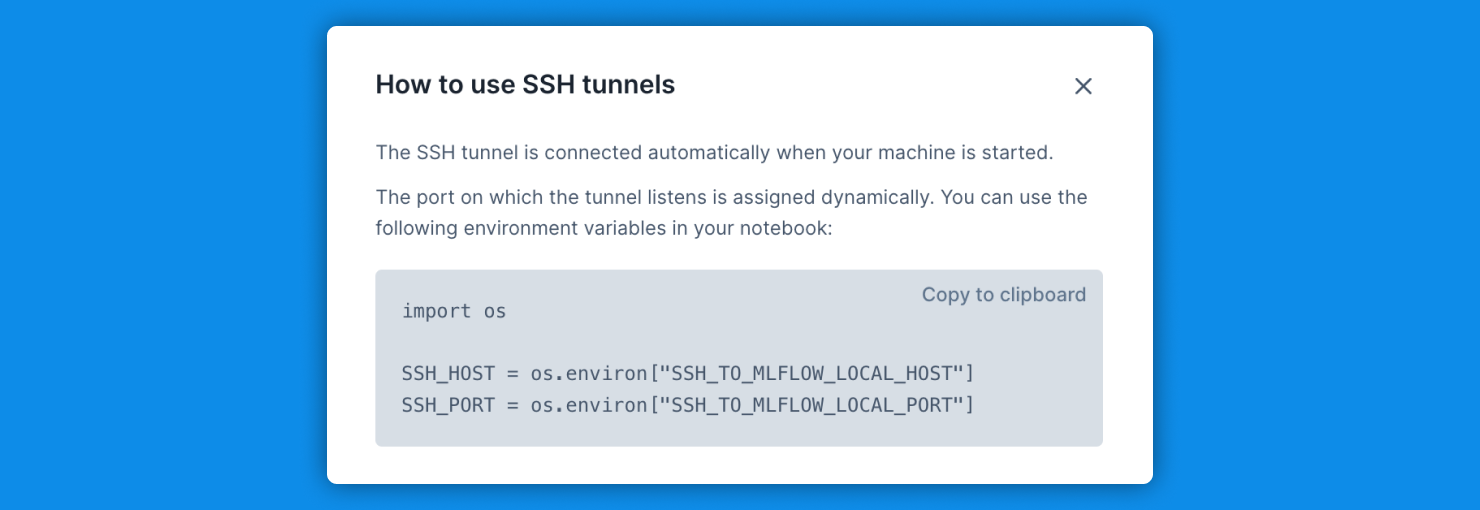
+
+In order to use SSH to connect to SQL databases with a native integration in Deepnote we recommend using the integration setting.
+
+### Workspace SSH key
+
+Deepnote automatically generates an SSH private/public key pair for your workspace. The private key is stored securely in Deepnote and used when authenticating an SSH connection from an [SQL block](/docs/sql-cells). The workspace SSH key is the same for all integrations within that workspace, simplifying deployment when multiple data sources are secured behind the same bastion.
+
+## Encrypting your connections with SSL
+
+All database and warehouse integrations support encrypted connections via SSL to make sure your data travels safely over the internet.
+
+Fully managed data warehouses such as Snowflake, Google BigQuery, and Amazon Redshift will have SSL enabled by default. Databases such as Postgres, MySQL, and Microsoft SQL Server may require additional configuration.
+
+By default, Deepnote will always connect using the `preferred` mode. It will try to use SSL if the database is configured to use it, but it will fall back to an unencrypted connection if not.
+
+To make sure SSL is used, enable the setting when creating a new integration or editing an existing one. This will put the connection in `required` mode. In this state, encryption is enforced but the certificate of the server is not validated. If the database is not configured to use SSL, the connection will fail.
+
+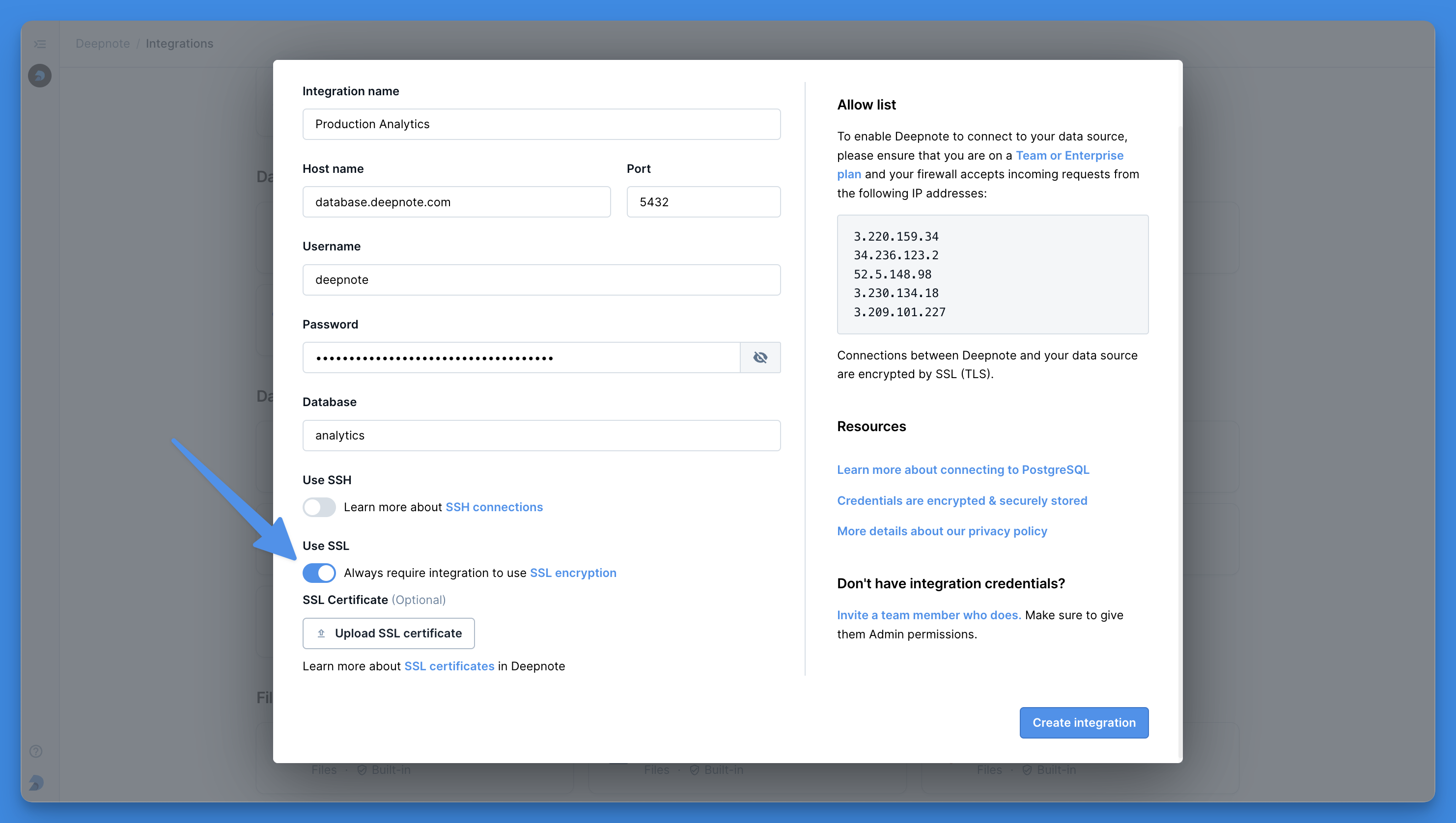
+
+To run in `strict` mode, you can upload a CA Certificate for your database or warehouse. We'll verify that the server's certificate is valid.
+
+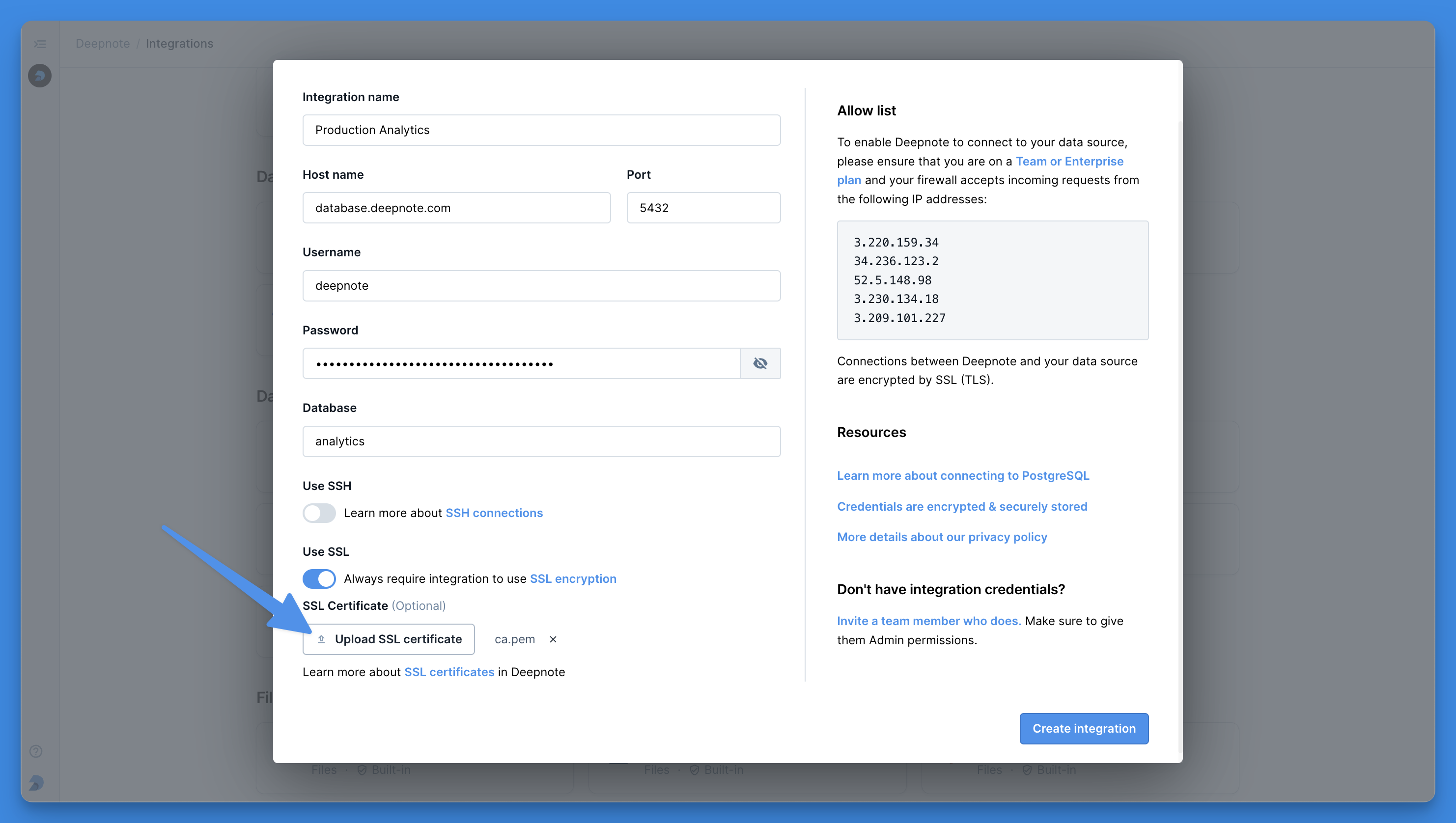
diff --git a/docs/security-overview.md b/docs/security-overview.md
new file mode 100644
index 0000000000..aead9b6d29
--- /dev/null
+++ b/docs/security-overview.md
@@ -0,0 +1,64 @@
+---
+title: Security overview
+description: Learn about Deepnote's security and privacy standards that protect your data.
+noIndex: false
+noContent: false
+---
+
+
+
+Deepnote is built on industry-leading security and privacy standards that keep our customer's data secure while connecting, querying, analyzing, and sharing. It offers a secure environment for teams to connect, analyze, and share data without compromising on data protection standards.
+
+As evidence of this, we've earned our SOC 2 Type II certification — a rigorous, third-party validation that our security practices and processes are built to meet the highest standards.
+
+Visit [https://deepnote.com/security](https://deepnote.com/security) for more detail on Deepnote's Security and Compliance posture.
+
+### Data security is core to how we work
+
+At Deepnote, security isn't just a feature — it's foundational to how we build and operate. From day one, every team member is trained on security best practices, with clear accountability for protecting customer data and privacy. We embed security deep into our workflows, aligning with the standards required for SOC 2 compliance.
+
+We invest heavily in proactive defenses, including regular third-party penetration testing and a [private bug bounty program](https://deepnote.com/.well-known/security.txt), to stay ahead of emerging threats. Security is everyone's job at Deepnote — and we take it seriously.
+
+### Analyze without extracting
+
+Deepnote powers your work through live queries directly against your data sources — no unnecessary extraction, duplication, or downloads to local machines. Forget about scattered .csv files, outdated Excel exports, or risky third-party storage. With Deepnote, data stays exactly where it belongs: securely in your warehouse, accessed only when needed.
+
+Inside projects, data is ephemeral by design — living just long enough in memory to power your analysis, then disappearing. [Our configurable caching](/docs/sql-query-caching) lets you fine-tune query costs without forcing long-term data storage or security trade-offs. Minimal movement, maximum control.
+
+### Architecture
+
+Deepnote's workspace is architected from day one with security at the core. Database credentials are encrypted at rest and stored securely in a vault, never exposed in plain text. When you run a query, Deepnote connects live to your data source, returns results into an isolated execution environment, and optionally caches results — always under your control.
+
+Workspace admins have full control over access policies — managing who can connect to databases, who can view or edit projects, and how data is shared across teams. Fine-grained permissions meet enterprise-grade security, without adding friction to your workflow.
+
+### Product access controls
+
+Deepnote supports secure authentication out of the box, with [full SSO integrations](/docs/sso) for Google Workspace, Okta, and any OIDC-compliant provider.
+
+Our access model is built to meet the needs of teams handling sensitive data — whether for GDPR compliance, sector-specific regulations, or internal security policies. Deepnote's flexible controls give you precision over who can see, query, and collaborate on your projects.
+
+Access management in Deepnote breaks down into three key layers:
+
+- **User Roles**: Define what actions users can take inside Deepnote — from editing notebooks to managing workspace settings — with smart defaults and customizable role assignment.
+- **Data Access**: Control who can connect to which databases. Limit users to pre-approved connections or credentials, minimizing risk and exposure.
+- **Project Access**: Fine-tune who can view, edit, or publish projects and apps, putting full control over logic, outputs, and shared insights into the right hands.
+
+Security isn't an afterthought at Deepnote — it's baked into every layer of the product.
+
+### Deployment options
+
+Deepnote offers flexible deployment models to meet your team's needs — from secure multi-tenant cloud hosting to dedicated single-tenant deployments for organizations with stricter compliance or privacy requirements. For specialized hosting (like region-specific data residency or private VPC deployment), reach out to us directly at [sales@deepnote.com](mailto:sales@deepnote.com) — we'll tailor the best setup for you.
+
+### What data does Deepnote store?
+
+Deepnote leverages AWS for processing and storage, with security baked in at every layer. Data at rest — including database credentials, file uploads, and cached query results — is encrypted using AES 256-bit encryption. Data in transit is protected with TLS 1.2 or higher, securing network traffic between Deepnote's servers and your browser. Your data stays safe, wherever it moves.
+
+### Does Deepnote use customer data to train, fine-tune, or otherwise improve any AI/ML models?
+
+No, Deepnote does not use customer data to train, fine-tune, or otherwise improve any AI or ML models. Deepnote integrates external AI services (such as OpenAI and Anthropic) via secured APIs under enterprise agreements that explicitly prohibit training on customer data. No personal, sensitive, or project data is sent to model providers by default, and zero-data retention agreements are in place for Anthropic (30-day retention for OpenAI under strict protections).
+
+Deepnote itself does not host or fine-tune any models internally, and all customer data remains encrypted (AES-256), stored within the customer's AWS environment, and protected under SOC 2 Type II-certified security practices with full user control. AI features are assistive only, optional, and fully transparent, ensuring that customer data privacy, GDPR compliance, and security standards are upheld at all times.
+
+### Support
+
+For all customers, Deepnote provides technical support via Intercom and email weekdays from 9 am to 5 pm Pacific Time as a minimum. Support via Slack channel may also be provided upon request.
diff --git a/docs/selecting-hardware.md b/docs/selecting-hardware.md
new file mode 100644
index 0000000000..3debe4e706
--- /dev/null
+++ b/docs/selecting-hardware.md
@@ -0,0 +1,28 @@
+---
+title: Selecting hardware
+noIndex: false
+noContent: false
+---
+
+### Hardware options
+
+Every project in Deepnote runs on a machine in the cloud. This means you don't need to worry about any kind of setup. Note that all hardware options have an enabled connection to the internet and therefore keep running even if you close your browser (also see [long-running jobs](/docs/long-running-jobs)).
+
+
+
+At this moment Deepnote does not support connecting to your own cloud-based resource (e.g. AWS, GCP), but this is coming soon.
+
+
+
+To choose a different machine for your project (and monitor you machine's performance), click the arrow next to "Environments" in the right sidebar. There you will see an option to change your machine if desired. More powerful machines are available on paid plans. See [Pricing](/docs/pricing) or contact us for details.
+
+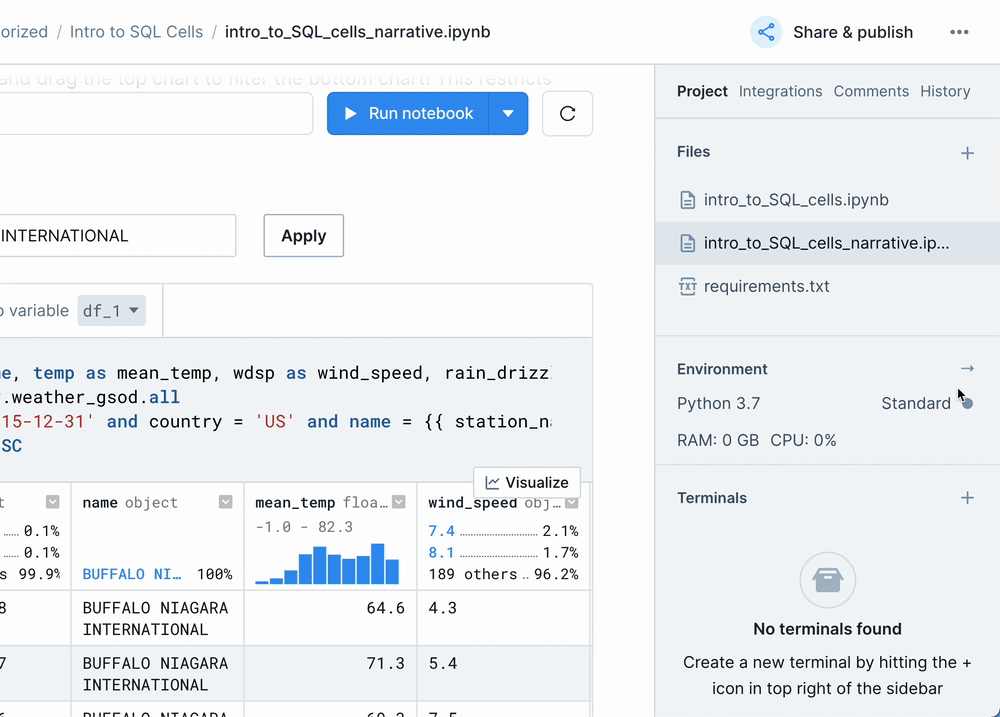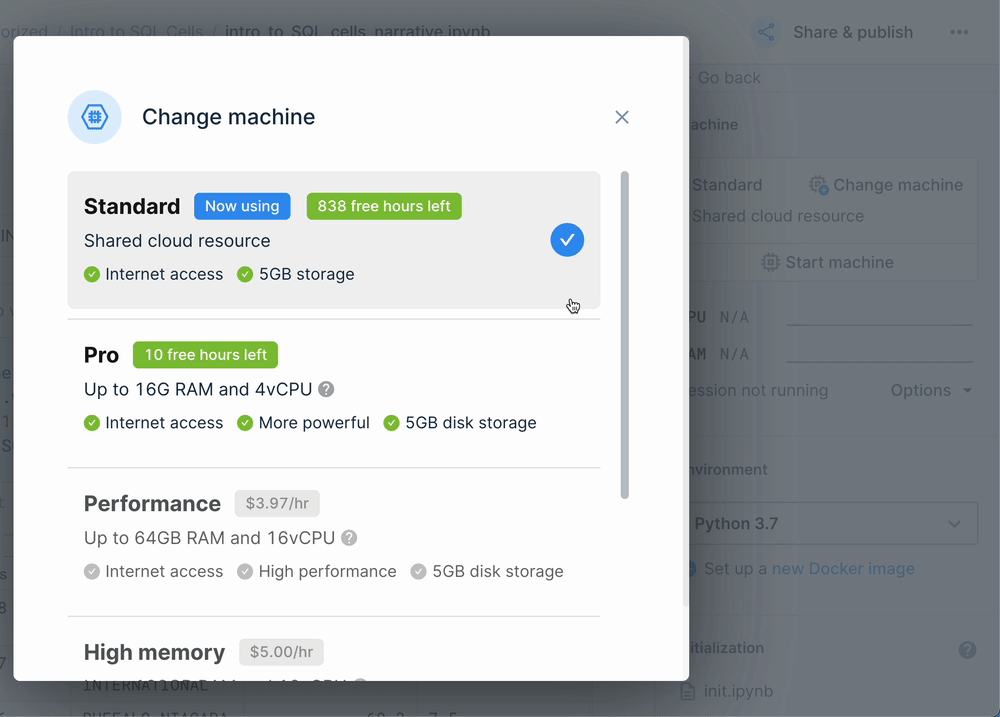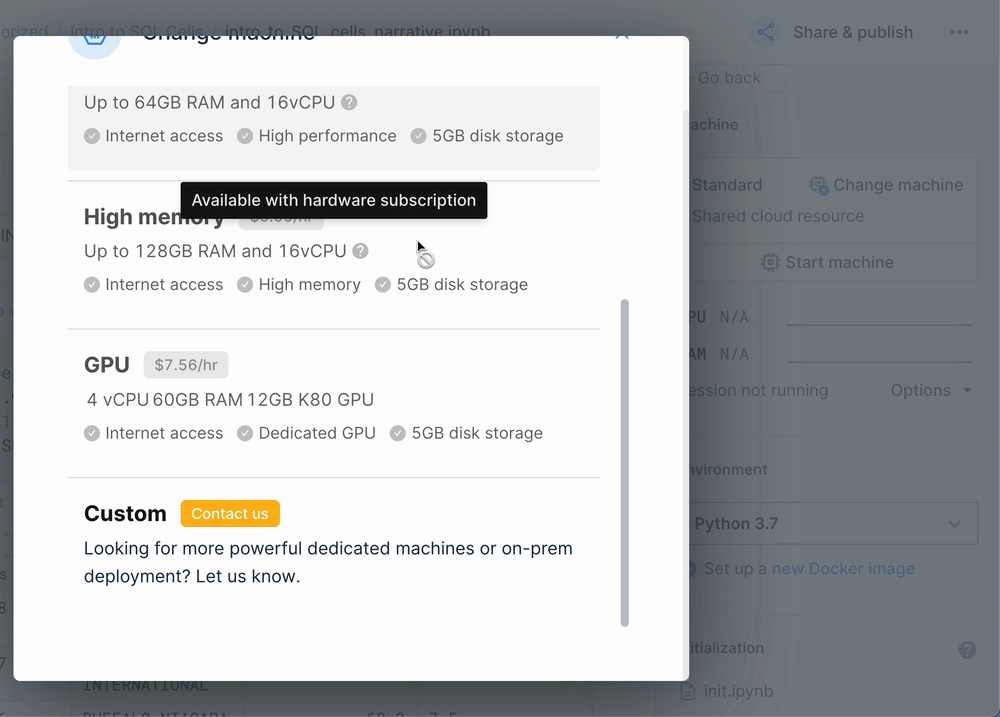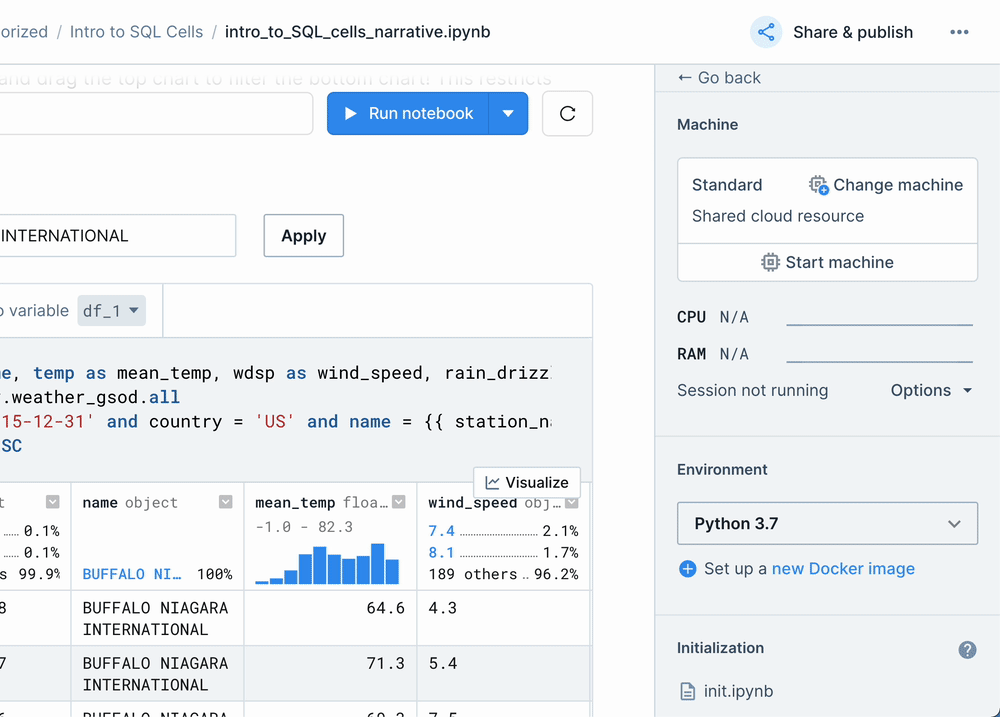
+
+# GPUs
+
+Deepnote's GPUs are engineered to meet the demanding requirements of machine learning workflows. We currently offer two choices on the team and enterprise plan. You may change the machine at the notebook level. Our current offerings are:
+
+- 4 vCPUs, 64 GB memory, K80 GPU
+- 8 vCPUs, 64 GB memory, 16 GB V100 GPU
+
+Please contact us if you require more powerful GPUs.
diff --git a/docs/semantic-layer.md b/docs/semantic-layer.md
new file mode 100644
index 0000000000..cc2c476155
--- /dev/null
+++ b/docs/semantic-layer.md
@@ -0,0 +1,34 @@
+---
+title: Semantic layer
+noIndex: false
+noContent: false
+---
+
+As your data team grows, a semantic layer becomes a useful abstraction to help you to create a consistent and unified view of your key metrics across the entire organization. It ensures that every analysis your do uses the same definitions when calculating complex metrics (e.g. _How many users do we have? What was our revenue in the last fiscal year?_).
+
+**Deepnote is compatible with all major approaches to building a semantic layer.** In this article, we will cover different approaches and how to integrate them with Deepnote.
+
+### Building a semantic layer in a notebook
+
+Deepnote is a great place to define your metrics, and with the new **modules** feature, creating a semantic layer has never been easier. This approach is recommended for teams of all sizes who want to ensure consistent metric definitions across their organization.
+
+We recommend creating a separate notebook for each metric definition. Use SQL or Python blocks to retrieve the data and text blocks to document each metric and its change history. Then publish these notebooks as modules that can be imported into any analysis.
+
+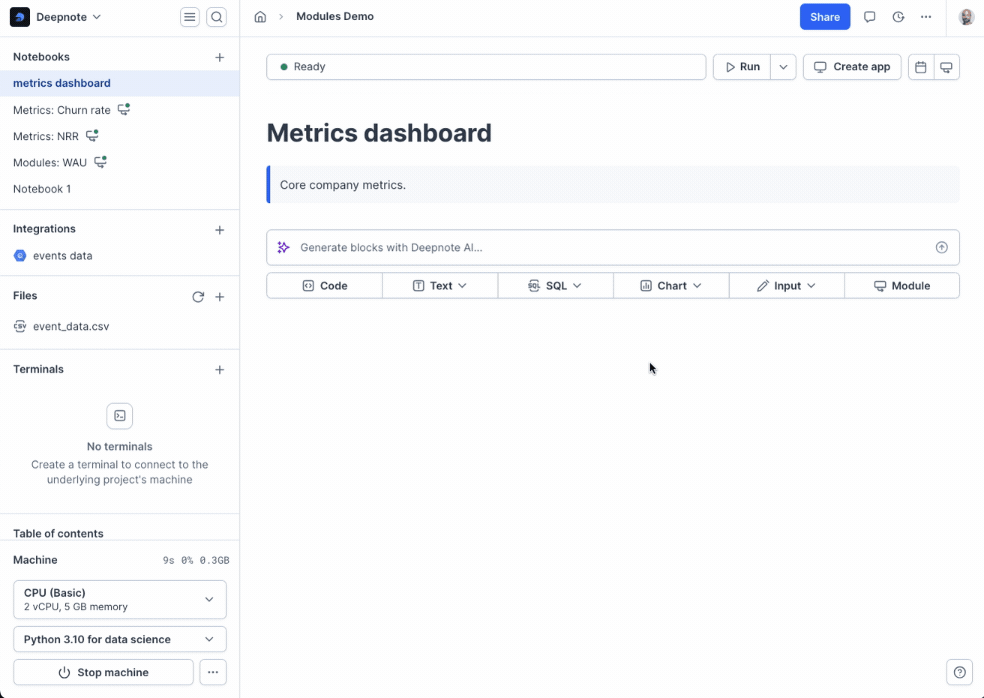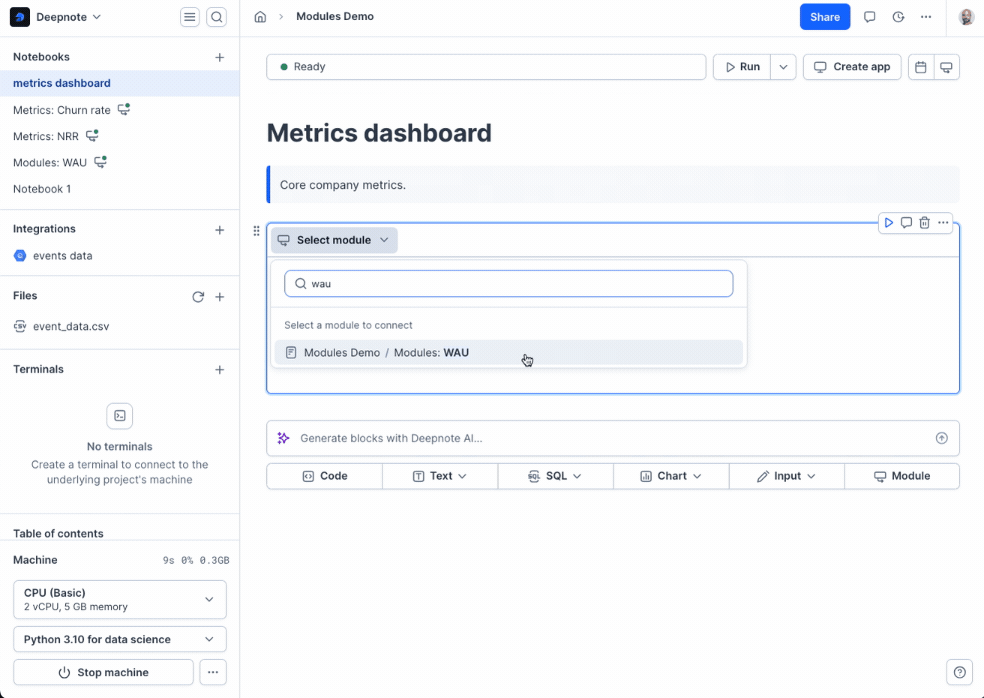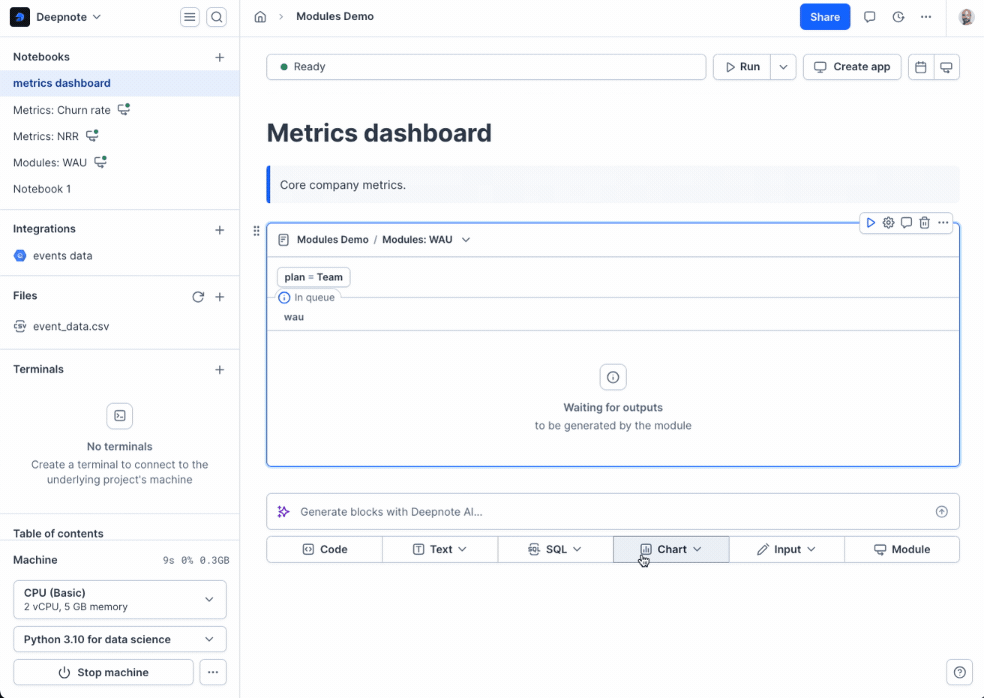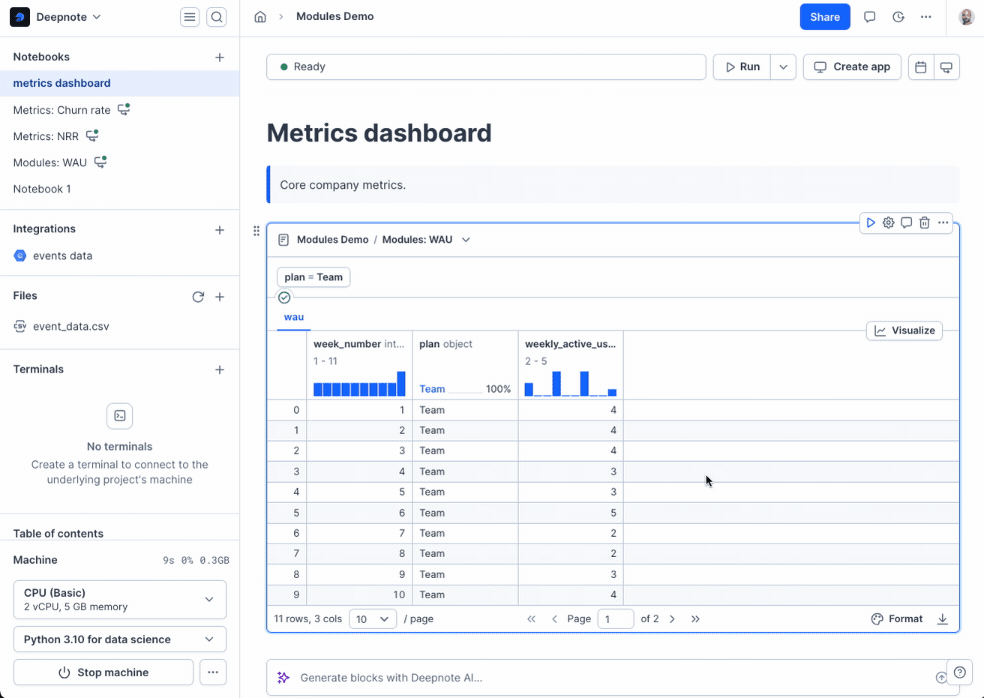
+
+Modules ensure that everyone on your team calculates metrics the same way, eliminating inconsistencies and building trust in your data. When a metric definition needs to be updated, you only need to change it in one place, and the update propagates automatically to all notebooks using that module.
+
+Learn more about [how to use modules](https://deepnote.com/docs/modules) and check out our [detailed example](https://deepnote.com/blog/modules) of building a semantic layer with modules.
+
+### dbt Semantic Layer
+
+You can use dbt or any other data warehouse-based semantic layers directly from Deepnote. dbt exposes a [JDBC interface](https://docs.getdbt.com/docs/dbt-cloud-apis/sl-jdbc), allowing you to query dbt models via SQL.
+
+Integration with the dbt Semantic Layer is on our roadmap. We're working on deeper native integration to make this experience even more seamless.
+If you'd like to influence the development of this feature, please vote and comment on this [portal card](https://portal.productboard.com/deepnote/1-deepnote-product-portal/c/159-dbt-semantic-layer-metricflow-integration).
+
+### Looker and LookML
+
+Looker also exposes a [JDBC interface](https://cloud.google.com/looker/docs/sql-interface), allowing you to query LookML models via SQL.Native integration with Looker and LookML is on our product roadmap. To help us prioritize this integration, you can vote and share your use case on this [portal card](https://portal.productboard.com/deepnote/1-deepnote-product-portal/c/162-lookml-integration).
+
+Get in touch with us at [sales@deepnote.com](mailto:sales@deepnote.com) to learn more about these integrations.
diff --git a/docs/share-projects.md b/docs/share-projects.md
new file mode 100644
index 0000000000..3a5a647aea
--- /dev/null
+++ b/docs/share-projects.md
@@ -0,0 +1,45 @@
+---
+title: Sharing a project
+noIndex: false
+noContent: false
+---
+
+Projects in a workspace are shared with all of its members by default, respecting their access levels. The primary way of collaborating with the rest of the team is to add them as workspace members. That way they can discover and contribute to any of the existing projects, or create new ones for others to see.
+
+In certain situations, you may prefer to change the sharing settings for a single project, for example:
+
+- You are working with an external contributor
+- You are working in a smaller group and the rest of the workspace shouldn't be able to see it
+- You want to make the project easy to access for anyone with a link
+
+## How to share a project
+
+You can change the sharing settings of the project by clicking the Share button in the top right-hand corner.
+
+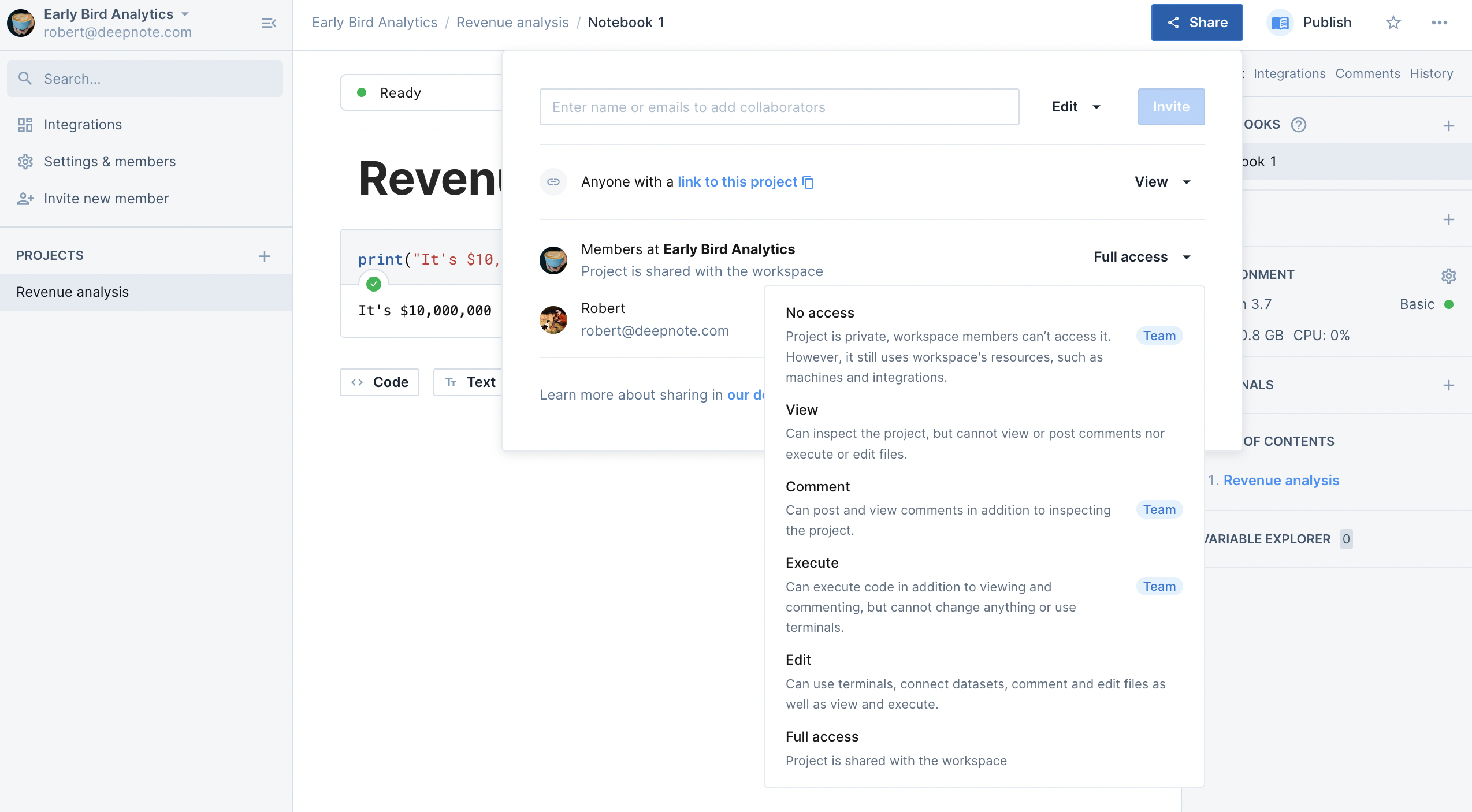
+
+- **Share with individual users.** You can share a project with existing workspace members using their name, or anybody else using their email. In both cases, they will receive an email invitation to the project. In case the person is not a Deepnote user yet, they will need to sign up using the same email to access the project.
+- **Share a link.** When you pick an access level for link sharing, anyone with that link will be able to access it. Your audience will be able to read the project without creating an account, but they will need to sign up to execute blocks.
+- **Private projects.** You can restrict access for other workspace members by changing the access level next to _Members at Your Workspace_. You can then increase it for specific users by adding them to the project individually.
+ - Setting this option to _No access_ will move the project to your Private projects, and vice versa – moving the project to Private will update this sharing option.
+
+## Project access levels
+
+
+
+Some of the fine-grained permissions are only available on Team and Enterprise plans.
+
+
+
+Grant fine-grained permissions to control how your invitees can use the project.
+
+- Those with **App user** access can use the published app, but cannot view the project source code.
+- Those with **View** access can inspect everything in the project, but cannot view or post comments, edit content, change datasets or terminals, execute cells or manage the sharing settings.
+- Those with **Comment** access can view and post comments in addition to viewing, but cannot edit content, change datasets or terminals, execute cells or manage the sharing settings.
+- Those with **Execute** access can execute code in addition to viewing and commenting. Execute access will not allow you to edit content, add connections, add terminals, change hardware or manage the sharing settings.
+- Those with **Edit** access can do anything except managing the sharing settings or deleting the project. This means that you will not be able to invite new members or turn on/off the link sharing.
+- Those with **Full access** access can do anything, including managing the sharing settings and deleting the project.
+
+## Projects shared with me
+
+You can navigate to a project that was shared with you by opening the workspace in which the project lives. The workspace will show up in the switcher in the top left corner.
diff --git a/docs/sharing-and-embedding-blocks.md b/docs/sharing-and-embedding-blocks.md
new file mode 100644
index 0000000000..2e460f6c29
--- /dev/null
+++ b/docs/sharing-and-embedding-blocks.md
@@ -0,0 +1,48 @@
+---
+title: Sharing and embedding blocks
+noIndex: false
+noContent: false
+---
+
+Deepnote supports sharing or embedding the code and output of individual blocks. **Once shared, the embed gets automatically refreshed based on the changes in your notebook!** To turn on sharing, select a block and click **`Share block`** on the right-hand side. The appearing pop-up window will allow you to select which part of the block you'd like to share: code only, output only, or both. _Keep in mind that the block won't be shared until you turn on the toggle switch up top._
+
+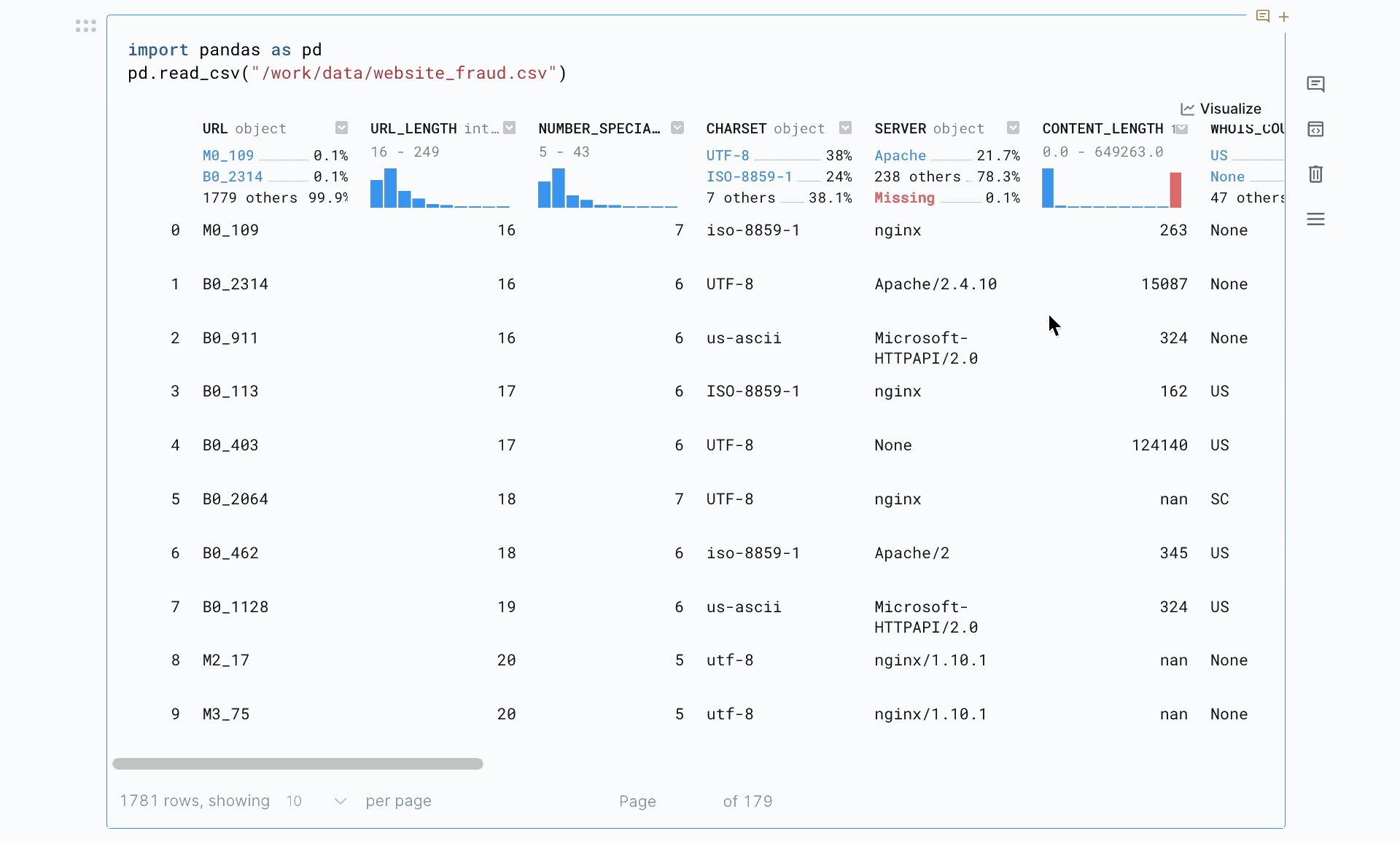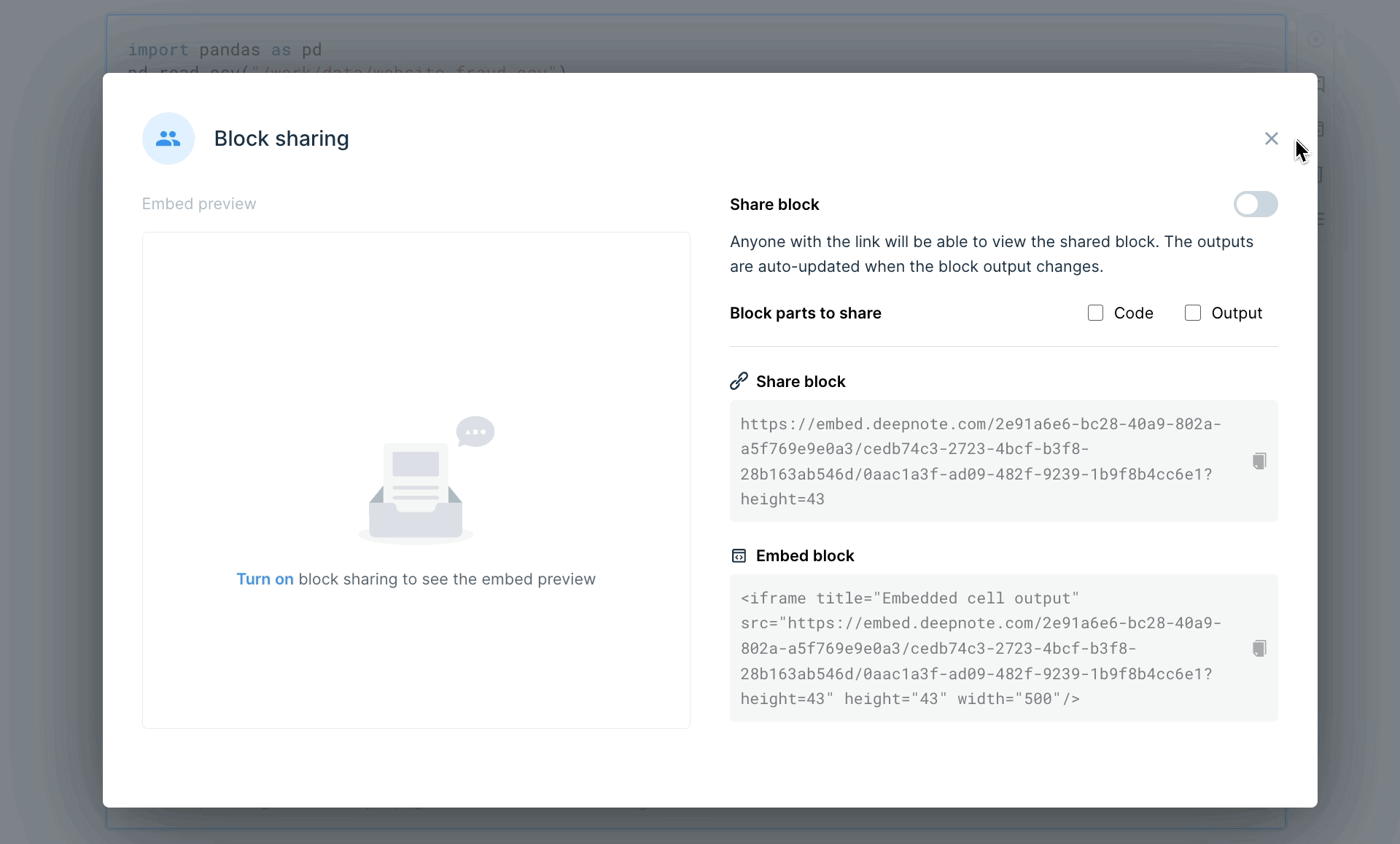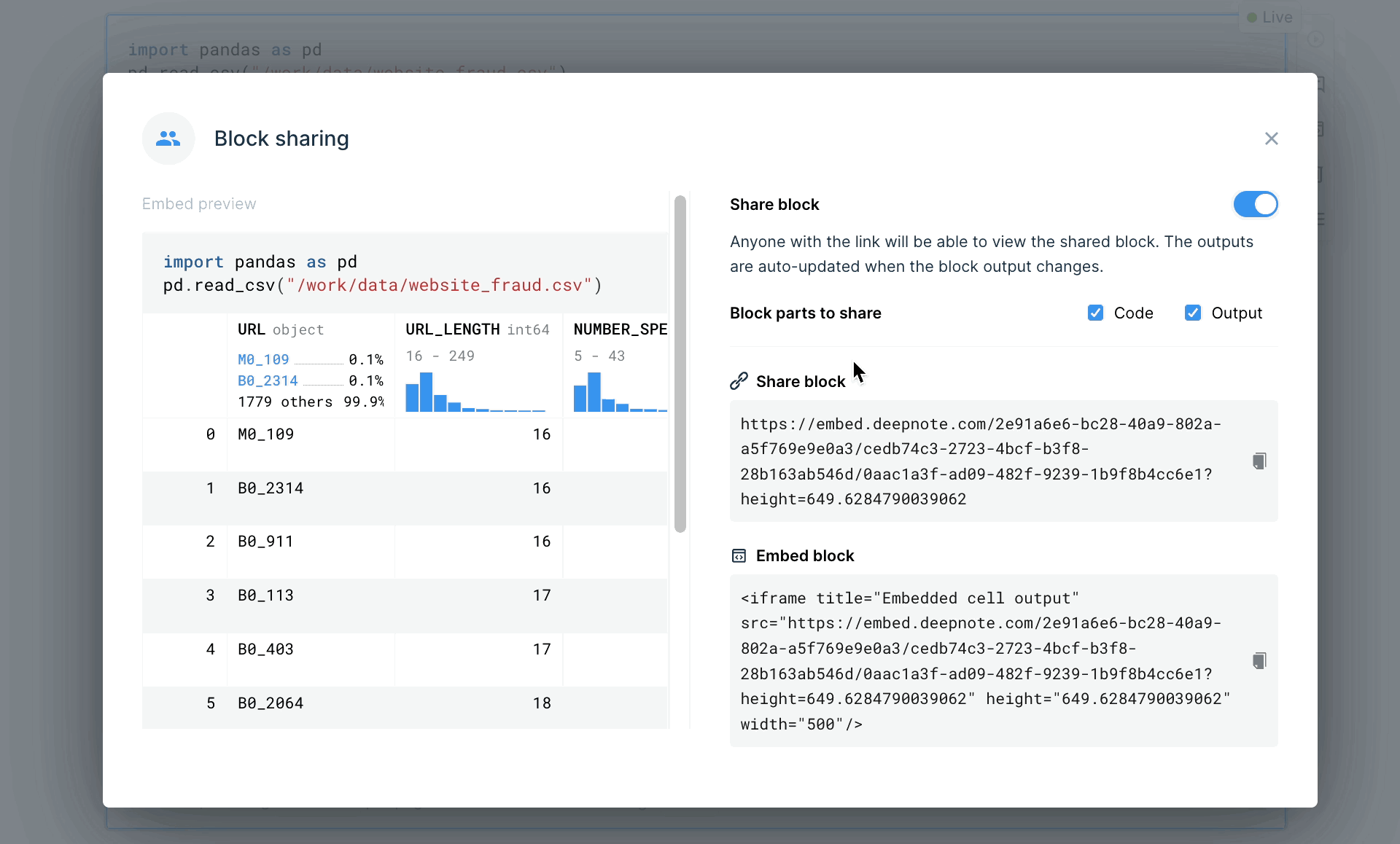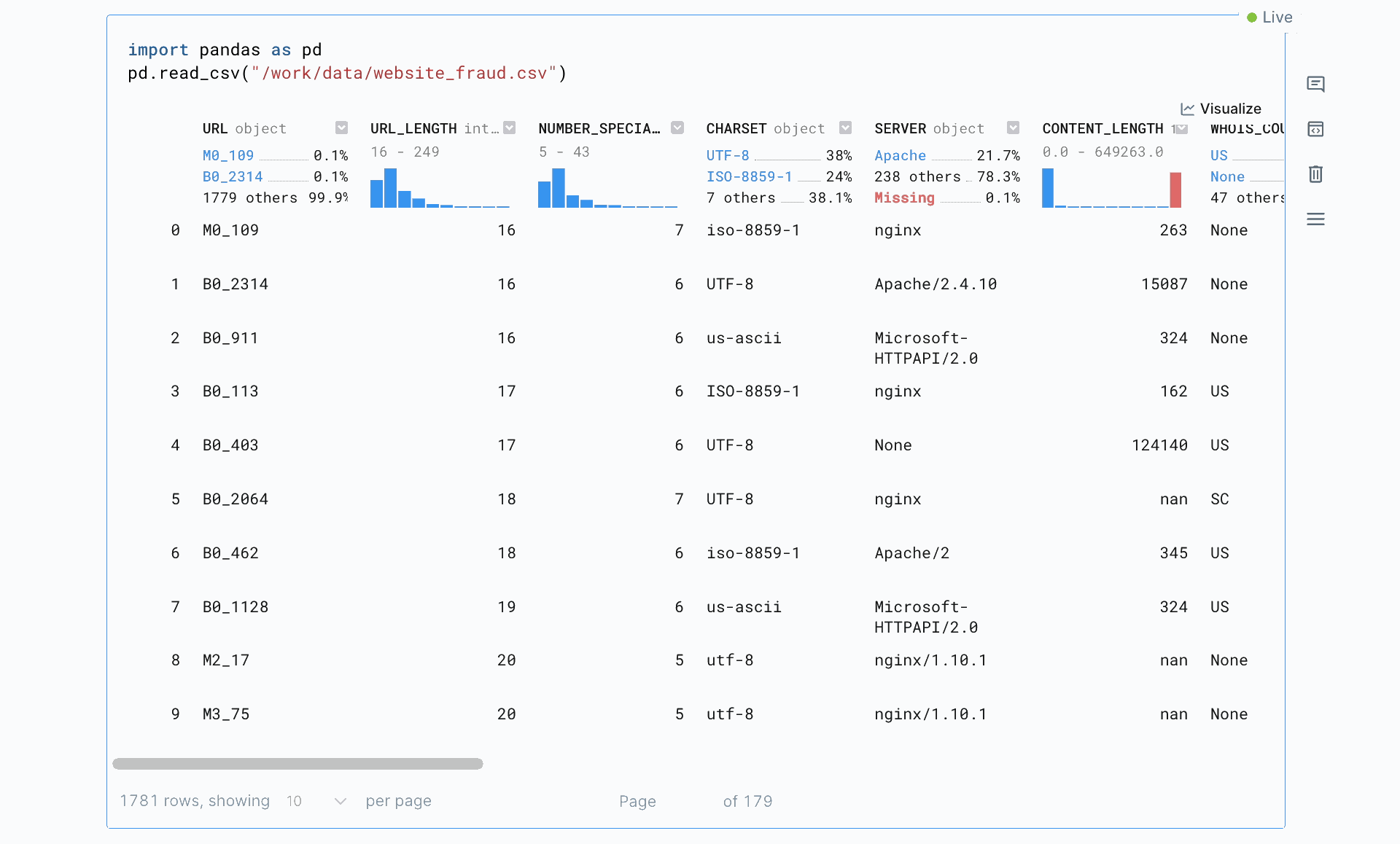
+
+
+You can quickly tell which blocks are being shared by the **Live** button in the top right corner of shared blocks.
+
+
+## Sharing blocks via URL
+
+If you'd like to quickly share an individual block's code and/or output via URL, all you need to do is copy the link in the **`Share block`** box. Then, to view the shared block, paste the link into the address bar in your browser of choice. _Note that anyone with the link can view the shared block content, not only collaborators on your Deepnote project!_
+
+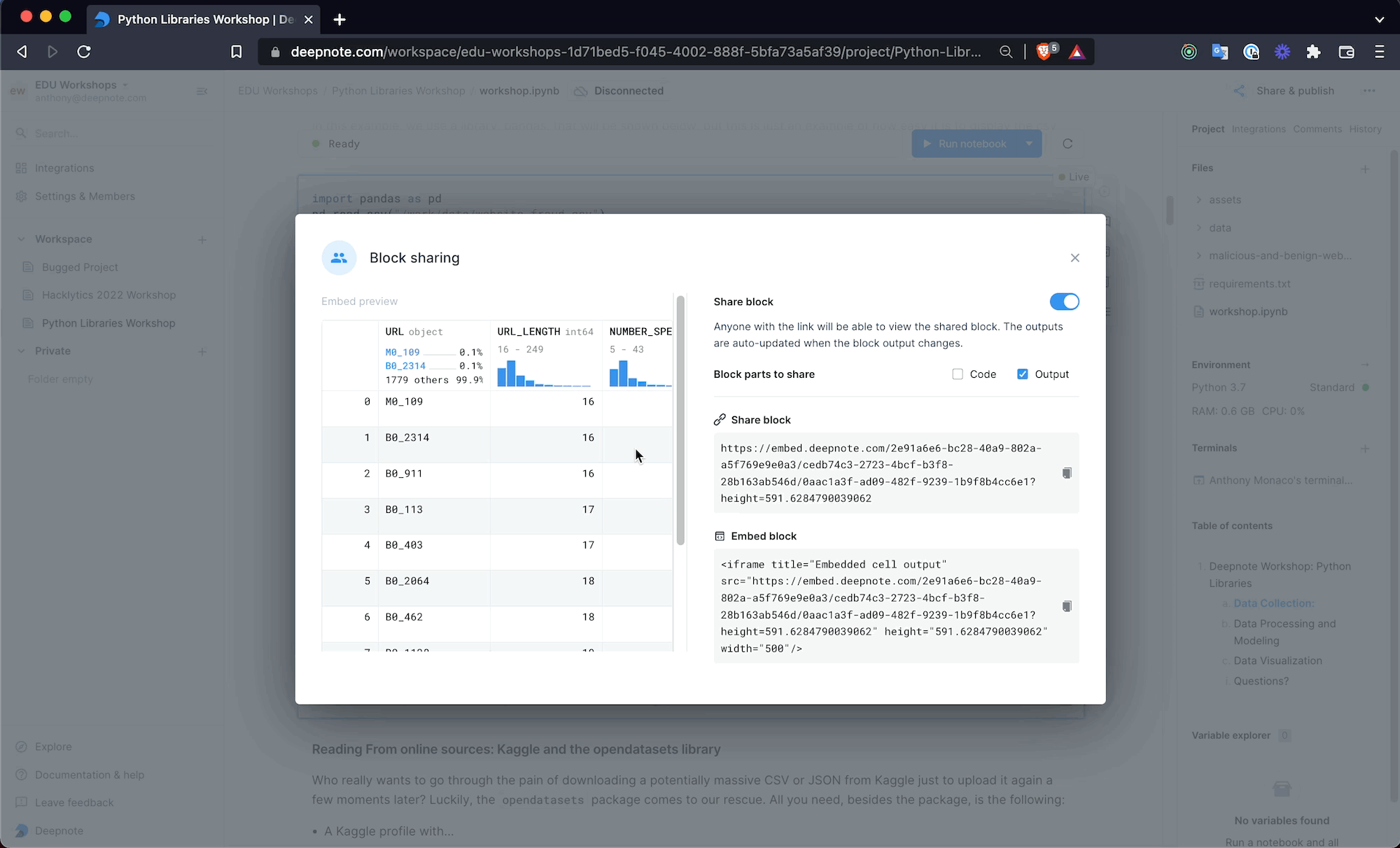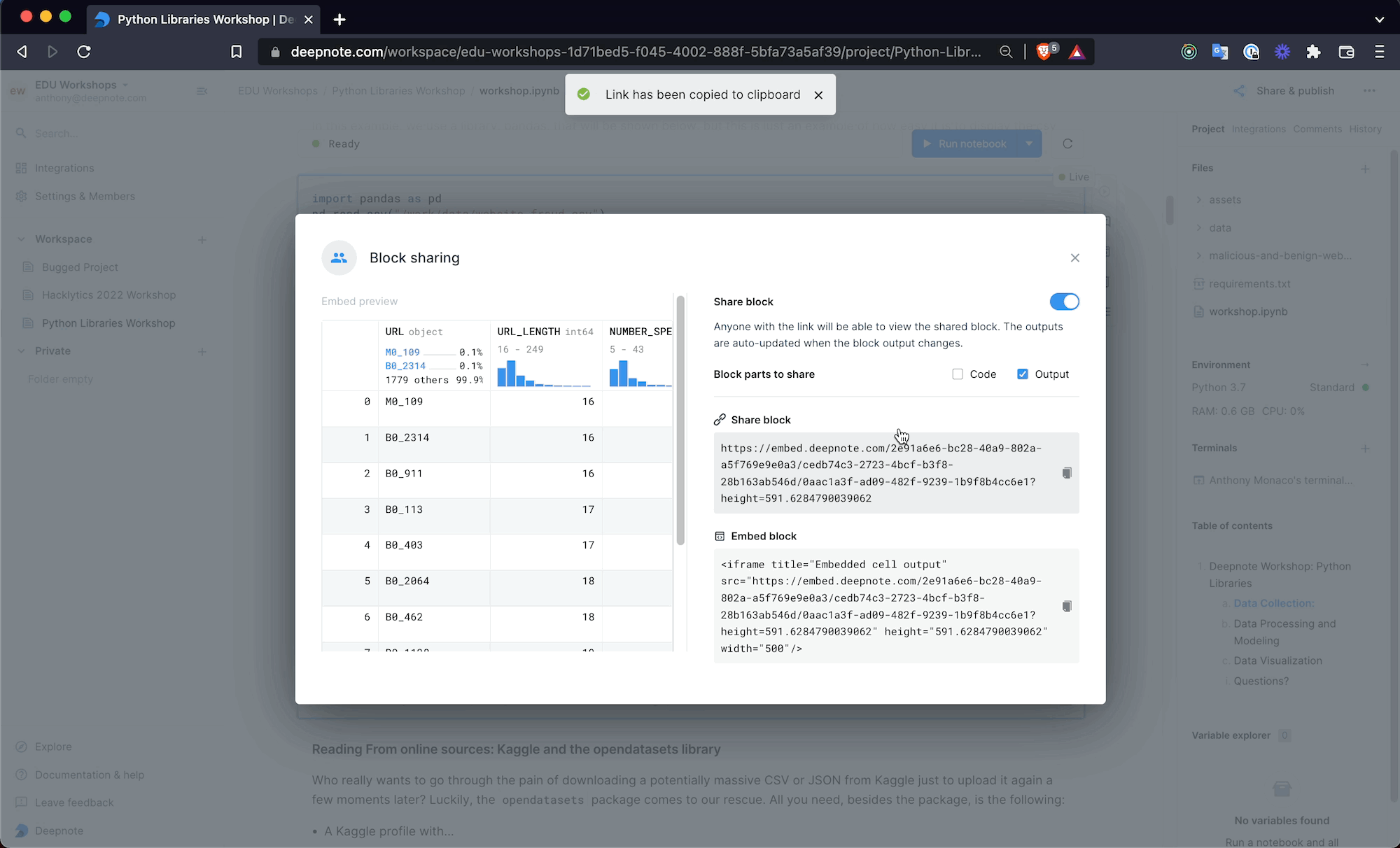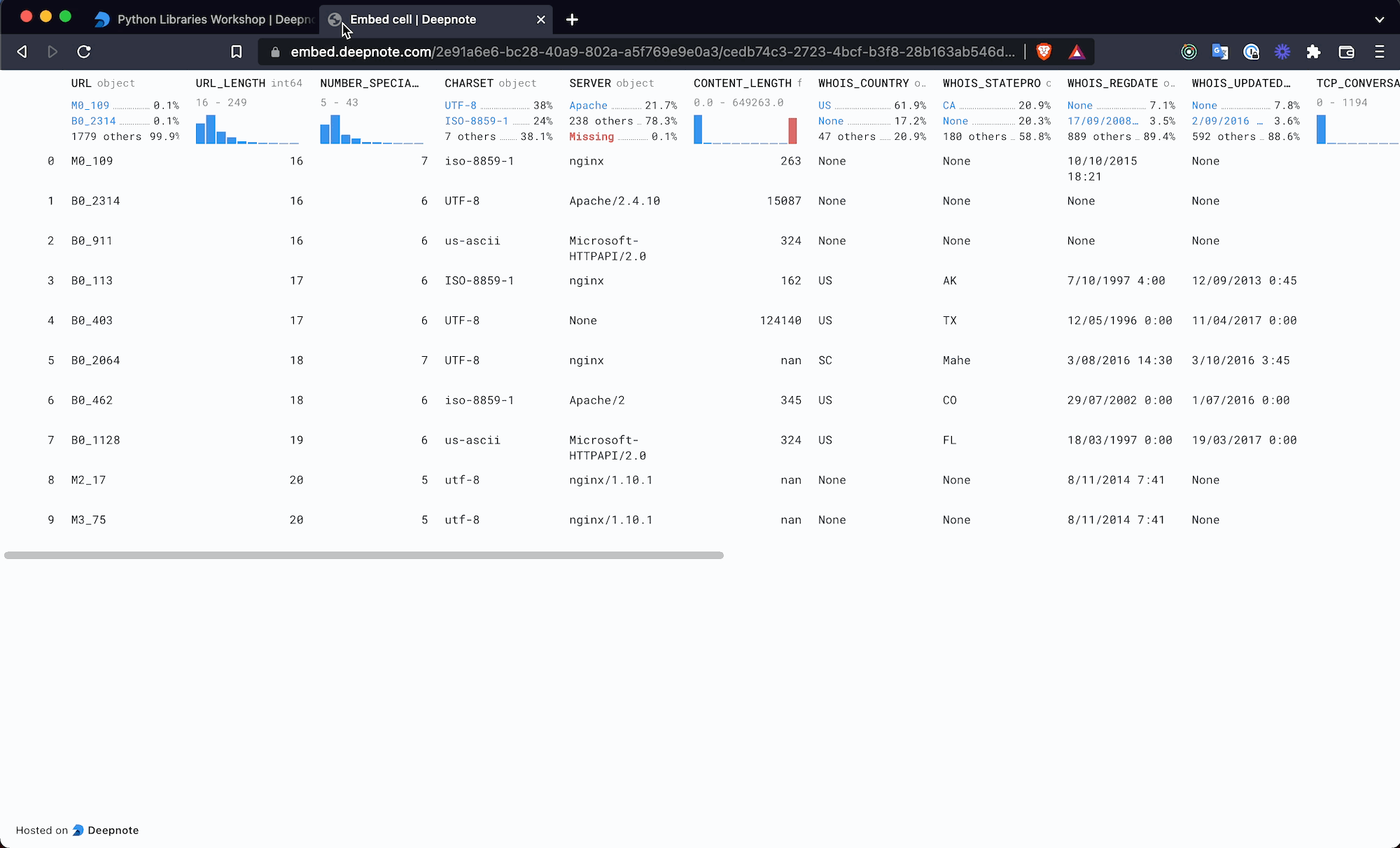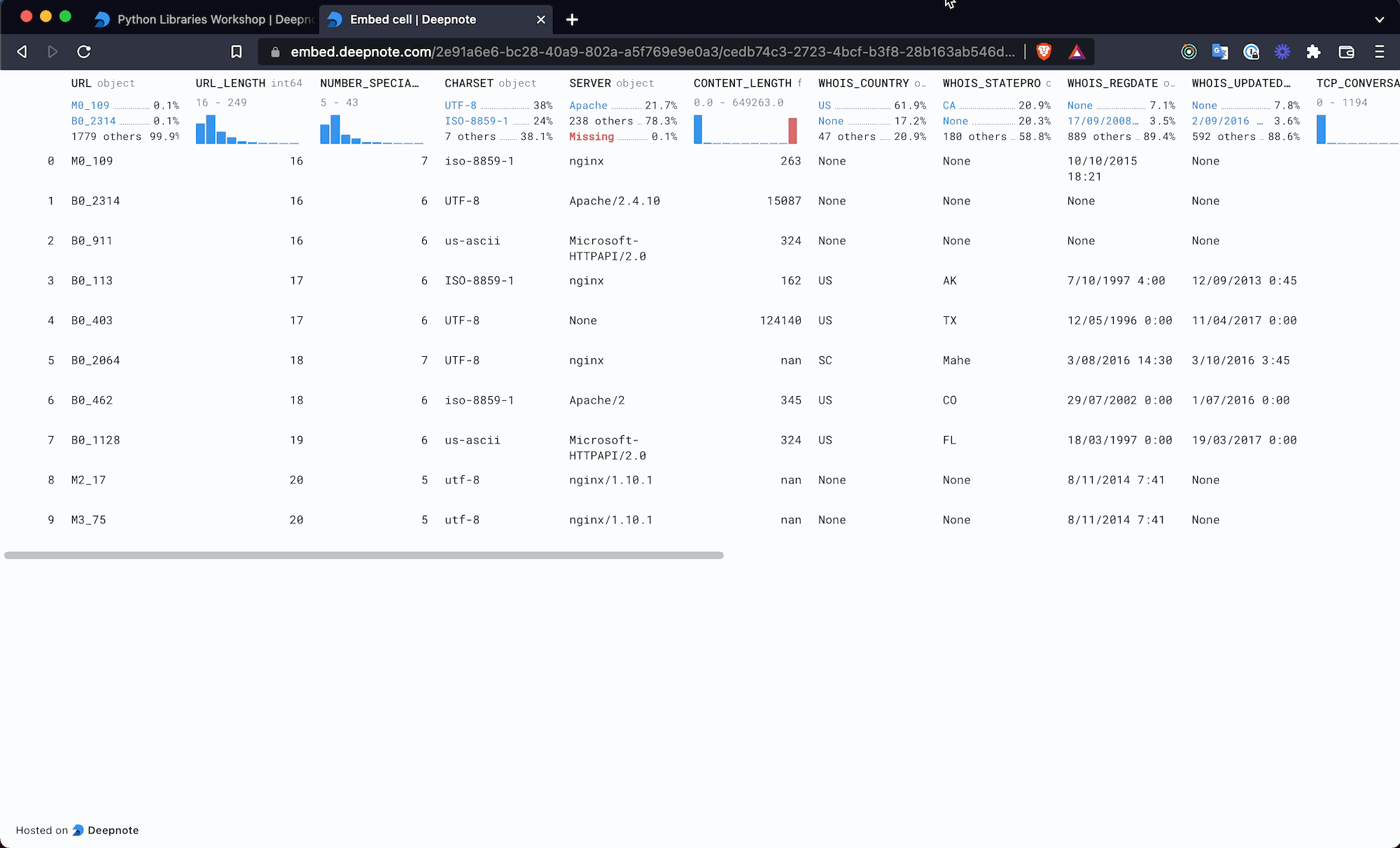
+
+## Embedding blocks on Medium / Notion
+
+Embedding Deepnote blocks into Notion pages is as easy as 1,2,3. All you need to do is copy the link in the **`Share block`** box, paste it into your Notion page, and hit **`Create embed`**... and ta-da! You can also resize the embedded block to make your Notion page look (even) better.
+
+
+
+
+If you love Notion as much as we do, check out [this page](https://medium.com/deepnote/bringing-analytics-to-notion-with-deepnote-b262a300c6de) describing even more cool ways to integrate Deepnote with Notion!
+
+
+Embedding Deepnote blocks into Medium articles is very straightforward. Simply copy the link in the **`Share block`** box, paste it into your Medium article, and you're set!
+
+
+Medium currently does not allow for custom image resizing, which might make your embedded blocks look a tad bit weird, but don't fret. To rectify this issue, edit the **`?height`** and **`?width`** parameters in the copied URL.
+
+
+
+
+## Embedding Deepnote blocks using `