diff --git a/.github/ISSUE_TEMPLATE/bug_report.md b/.github/ISSUE_TEMPLATE/bug_report.md
new file mode 100644
index 00000000..0f04a246
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/bug_report.md
@@ -0,0 +1,23 @@
+---
+name: Bug report
+about: Create a report to help us improve
+title: ''
+labels: ''
+assignees: ''
+
+---
+
+**需知**
+
+升级feapder,保证feapder是最新版,若BUG仍然存在,则详细描述问题
+> pip install --upgrade feapder
+
+**问题**
+
+**截图**
+
+**代码**
+
+```python
+
+```
diff --git a/.github/ISSUE_TEMPLATE/config.yml b/.github/ISSUE_TEMPLATE/config.yml
new file mode 100644
index 00000000..9ab3c9b8
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/config.yml
@@ -0,0 +1,6 @@
+# https://docs.github.com/en/github/building-a-strong-community/configuring-issue-templates-for-your-repository#configuring-the-template-chooser
+blank_issues_allowed: false # We have a blank template which assigns labels
+contact_links:
+ - name: Questions about using feapder?
+ url: "https://github.com/Boris-code/feapder/discussions"
+ about: Please see our guide on how to ask questions
\ No newline at end of file
diff --git a/.github/ISSUE_TEMPLATE/feature_request.md b/.github/ISSUE_TEMPLATE/feature_request.md
new file mode 100644
index 00000000..bbcbbe7d
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/feature_request.md
@@ -0,0 +1,20 @@
+---
+name: Feature request
+about: Suggest an idea for this project
+title: ''
+labels: ''
+assignees: ''
+
+---
+
+**Is your feature request related to a problem? Please describe.**
+A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
+
+**Describe the solution you'd like**
+A clear and concise description of what you want to happen.
+
+**Describe alternatives you've considered**
+A clear and concise description of any alternative solutions or features you've considered.
+
+**Additional context**
+Add any other context or screenshots about the feature request here.
diff --git a/.github/workflows/workflow.yml b/.github/workflows/workflow.yml
new file mode 100644
index 00000000..e69de29b
diff --git a/.gitignore b/.gitignore
index d6f90b5c..fedead23 100644
--- a/.gitignore
+++ b/.gitignore
@@ -14,4 +14,5 @@ dist/
.vscode/
media/
.MWebMetaData/
-push.sh
\ No newline at end of file
+push.sh
+assets/
\ No newline at end of file
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
new file mode 100644
index 00000000..63d42cb0
--- /dev/null
+++ b/CONTRIBUTING.md
@@ -0,0 +1,15 @@
+# 贡献指南
+感谢你的宝贵时间。你的贡献将使这个项目变得更好!在提交贡献之前,请务必花点时间阅读下面的入门指南。
+
+## 提交 Pull Request
+1. Fork [此仓库](https://github.com/Boris-code/feapder.git),
+2. clone到本地,从 `develop` 创建分支,对代码进行更改。
+3. 请确保进行了相应的测试。
+4. 推送代码到自己Fork的仓库中。
+5. 在Fork的仓库中点击 Pull request 链接
+6. 点击「New pull request」按钮。
+7. 填写提交说明后,「Create pull request」。提交到`develop`分支。
+
+## License
+
+[MIT](./LICENSE)
diff --git a/README.md b/README.md
index 80dffe49..7bde6250 100644
--- a/README.md
+++ b/README.md
@@ -8,48 +8,25 @@
[](https://pepy.tech/project/feapder)
[](https://pepy.tech/project/feapder)
-
- -
-
## 简介
-**feapder是一款上手简单,功能强大的Python爬虫框架**
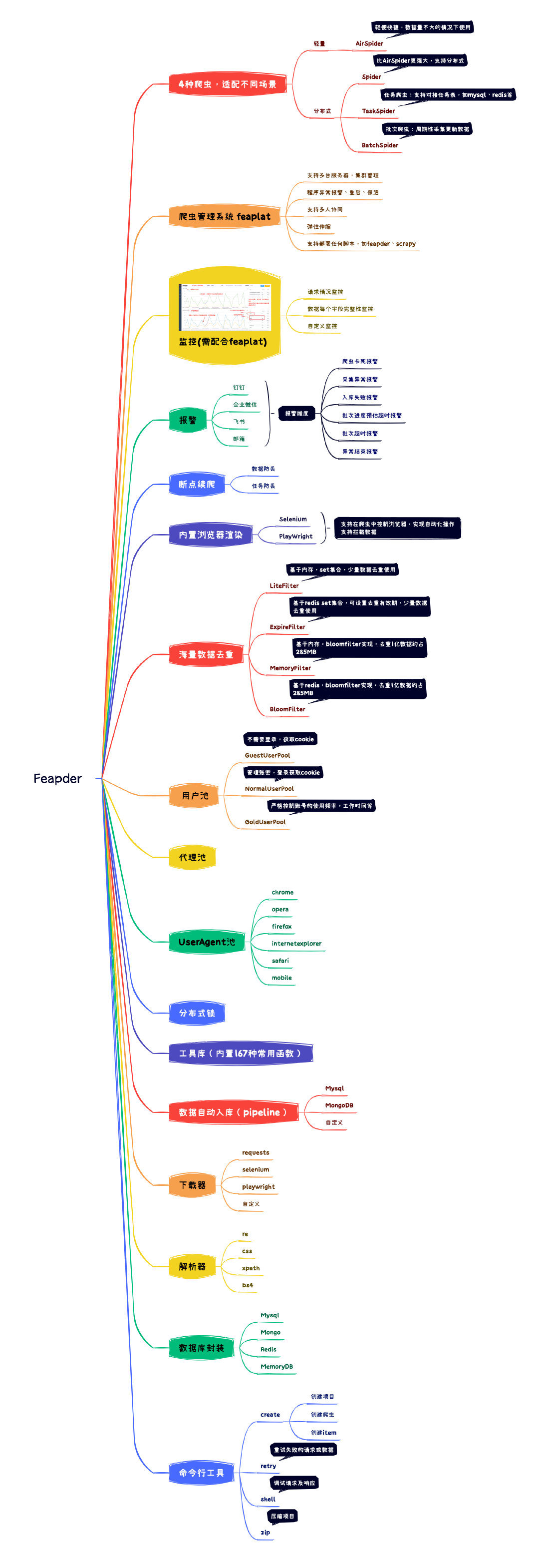
+1. feapder是一款上手简单,功能强大的Python爬虫框架,内置AirSpider、Spider、TaskSpider、BatchSpider四种爬虫解决不同场景的需求。
+2. 支持断点续爬、监控报警、浏览器渲染、海量数据去重等功能。
+3. 更有功能强大的爬虫管理系统feaplat为其提供方便的部署及调度
读音: `[ˈfiːpdə]`
-### 1.拥有强大的监控,保障数据质量
-
-
-
-监控面板:[点击查看详情](http://feapder.com/#/feapder_platform/feaplat)
-
-### 2. 内置多维度的报警(支持 钉钉、企业微信、邮箱)
-
-
-
-
+
-### 3. 简单易用,内置三种爬虫,可应对各种需求场景
-
-- `AirSpider` 轻量爬虫:学习成本低,可快速上手
-
-- `Spider` 分布式爬虫:支持断点续爬、爬虫报警、数据自动入库等功能
-
-- `BatchSpider` 批次爬虫:可周期性的采集数据,自动将数据按照指定的采集周期划分。(如每7天全量更新一次商品销量的需求)
-
-**feapder**对外暴露的接口类似scrapy,可由scrapy快速迁移过来。支持**断点续爬**、**数据防丢**、**监控报警**、**浏览器渲染下载**、**海量数据去重**等功能
-
## 文档地址
-- 官方文档:http://feapder.com
-- 国内文档:https://boris-code.gitee.io/feapder
-- 境外文档:https://boris.org.cn/feapder
+- 官方文档:https://feapder.com
- github:https://github.com/Boris-code/feapder
- 更新日志:https://github.com/Boris-code/feapder/releases
- 爬虫管理系统:http://feapder.com/#/feapder_platform/feaplat
+
## 环境要求:
- Python 3.6.0+
@@ -59,23 +36,30 @@
From PyPi:
-通用版
+精简版
```shell
-pip3 install feapder
-```
+pip install feapder
+```
+
+浏览器渲染版:
+```shell
+pip install "feapder[render]"
+```
完整版:
```shell
-pip3 install feapder[all]
-```
+pip install "feapder[all]"
+```
-通用版与完整版区别:
+三个版本区别:
-1. 完整版支持基于内存去重
+1. 精简版:不支持浏览器渲染、不支持基于内存去重、不支持入库mongo
+2. 浏览器渲染版:不支持基于内存去重、不支持入库mongo
+3. 完整版:支持所有功能
-完整版可能会安装出错,若安装出错,请参考[安装问题](https://boris.org.cn/feapder/#/question/%E5%AE%89%E8%A3%85%E9%97%AE%E9%A2%98)
+完整版可能会安装出错,若安装出错,请参考[安装问题](docs/question/安装问题.md)
## 小试一下
@@ -88,7 +72,6 @@ feapder create -s first_spider
创建后的爬虫代码如下:
```python
-
import feapder
@@ -124,10 +107,55 @@ FirstSpider|2021-02-09 14:55:14,620|air_spider.py|run|line:80|INFO| 无任务,
1. start_requests: 生产任务
2. parse: 解析数据
+
+## 感谢以下代理赞助商
+
+### Rapidproxy代理
+
+
+
+
+
+
-
-
## 简介
-**feapder是一款上手简单,功能强大的Python爬虫框架**
+1. feapder是一款上手简单,功能强大的Python爬虫框架,内置AirSpider、Spider、TaskSpider、BatchSpider四种爬虫解决不同场景的需求。
+2. 支持断点续爬、监控报警、浏览器渲染、海量数据去重等功能。
+3. 更有功能强大的爬虫管理系统feaplat为其提供方便的部署及调度
读音: `[ˈfiːpdə]`
-### 1.拥有强大的监控,保障数据质量
-
-
-
-监控面板:[点击查看详情](http://feapder.com/#/feapder_platform/feaplat)
-
-### 2. 内置多维度的报警(支持 钉钉、企业微信、邮箱)
-
-
-
-
+
-### 3. 简单易用,内置三种爬虫,可应对各种需求场景
-
-- `AirSpider` 轻量爬虫:学习成本低,可快速上手
-
-- `Spider` 分布式爬虫:支持断点续爬、爬虫报警、数据自动入库等功能
-
-- `BatchSpider` 批次爬虫:可周期性的采集数据,自动将数据按照指定的采集周期划分。(如每7天全量更新一次商品销量的需求)
-
-**feapder**对外暴露的接口类似scrapy,可由scrapy快速迁移过来。支持**断点续爬**、**数据防丢**、**监控报警**、**浏览器渲染下载**、**海量数据去重**等功能
-
## 文档地址
-- 官方文档:http://feapder.com
-- 国内文档:https://boris-code.gitee.io/feapder
-- 境外文档:https://boris.org.cn/feapder
+- 官方文档:https://feapder.com
- github:https://github.com/Boris-code/feapder
- 更新日志:https://github.com/Boris-code/feapder/releases
- 爬虫管理系统:http://feapder.com/#/feapder_platform/feaplat
+
## 环境要求:
- Python 3.6.0+
@@ -59,23 +36,30 @@
From PyPi:
-通用版
+精简版
```shell
-pip3 install feapder
-```
+pip install feapder
+```
+
+浏览器渲染版:
+```shell
+pip install "feapder[render]"
+```
完整版:
```shell
-pip3 install feapder[all]
-```
+pip install "feapder[all]"
+```
-通用版与完整版区别:
+三个版本区别:
-1. 完整版支持基于内存去重
+1. 精简版:不支持浏览器渲染、不支持基于内存去重、不支持入库mongo
+2. 浏览器渲染版:不支持基于内存去重、不支持入库mongo
+3. 完整版:支持所有功能
-完整版可能会安装出错,若安装出错,请参考[安装问题](https://boris.org.cn/feapder/#/question/%E5%AE%89%E8%A3%85%E9%97%AE%E9%A2%98)
+完整版可能会安装出错,若安装出错,请参考[安装问题](docs/question/安装问题.md)
## 小试一下
@@ -88,7 +72,6 @@ feapder create -s first_spider
创建后的爬虫代码如下:
```python
-
import feapder
@@ -124,10 +107,55 @@ FirstSpider|2021-02-09 14:55:14,620|air_spider.py|run|line:80|INFO| 无任务,
1. start_requests: 生产任务
2. parse: 解析数据
+
+## 感谢以下代理赞助商
+
+### Rapidproxy代理
+
+
+
+
+
+ +
+
+
+### SWIFTPROXY
+
+
+
+
+
+
+
+
+
+### SWIFTPROXY
+
+
+
+
+
+ +
+
+
+### NovProxy
+
+
+
+
+
+
+
+
+
+### NovProxy
+
+
+
+
+
+ +
+
+
+
+## 参与贡献
+
+贡献之前请先阅读 [贡献指南](./CONTRIBUTING.md)
+
+感谢所有做过贡献的人!
+
+
+
+
+
+
+
+## 参与贡献
+
+贡献之前请先阅读 [贡献指南](./CONTRIBUTING.md)
+
+感谢所有做过贡献的人!
+
+
+  +
+
## 爬虫工具推荐
1. 爬虫在线工具库:http://www.spidertools.cn
-2. 验证码识别库:https://github.com/sml2h3/ddddocr
+2. 爬虫管理系统:http://feapder.com/#/feapder_platform/feaplat
+3. 验证码识别库:https://github.com/sml2h3/ddddocr
## 微信赞赏
@@ -144,14 +172,16 @@ FirstSpider|2021-02-09 14:55:14,620|air_spider.py|run|line:80|INFO| 无任务,
+
+
## 爬虫工具推荐
1. 爬虫在线工具库:http://www.spidertools.cn
-2. 验证码识别库:https://github.com/sml2h3/ddddocr
+2. 爬虫管理系统:http://feapder.com/#/feapder_platform/feaplat
+3. 验证码识别库:https://github.com/sml2h3/ddddocr
## 微信赞赏
@@ -144,14 +172,16 @@ FirstSpider|2021-02-09 14:55:14,620|air_spider.py|run|line:80|INFO| 无任务,
| 知识星球:17321694 |
作者微信: boris_tm |
- QQ群号:750614606 |
+ QQ群号:521494615 |

|
 |
-  |
+  |
-
- 加好友备注:feapder
\ No newline at end of file
+
+
+
+ 加好友备注:feapder
diff --git a/docs/README.md b/docs/README.md
index 1e16f601..08ccb6aa 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -10,37 +10,17 @@
## 简介
-**feapder是一款上手简单,功能强大的Python爬虫框架**
+1. feapder是一款上手简单,功能强大的Python爬虫框架,内置AirSpider、Spider、TaskSpider、BatchSpider四种爬虫解决不同场景的需求。
+2. 支持断点续爬、监控报警、浏览器渲染、海量数据去重等功能。
+3. 更有功能强大的爬虫管理系统feaplat为其提供方便的部署及调度
读音: `[ˈfiːpdə]`
-### 1.拥有强大的监控,保障数据质量
-
-
-
-监控面板:[点击查看详情](http://feapder.com/#/feapder_platform/feaplat)
-
-### 2. 内置多维度的报警(支持 钉钉、企业微信、邮箱)
-
-
-
-
-
-### 3. 简单易用,内置三种爬虫,可应对各种需求场景
-
-- `AirSpider` 轻量爬虫:学习成本低,可快速上手
-
-- `Spider` 分布式爬虫:支持断点续爬、爬虫报警、数据自动入库等功能
-
-- `BatchSpider` 批次爬虫:可周期性的采集数据,自动将数据按照指定的采集周期划分。(如每7天全量更新一次商品销量的需求)
-
-**feapder**对外暴露的接口类似scrapy,可由scrapy快速迁移过来。支持**断点续爬**、**数据防丢**、**监控报警**、**浏览器渲染下载**、**海量数据去重**等功能
+
## 文档地址
-- 官方文档:http://feapder.com
-- 国内文档:https://boris-code.gitee.io/feapder
-- 境外文档:https://boris.org.cn/feapder
+- 官方文档:https://feapder.com
- github:https://github.com/Boris-code/feapder
- 更新日志:https://github.com/Boris-code/feapder/releases
- 爬虫管理系统:http://feapder.com/#/feapder_platform/feaplat
@@ -55,21 +35,29 @@
From PyPi:
-通用版
+精简版
```shell
-pip3 install feapder
-```
+pip install feapder
+```
+
+浏览器渲染版:
+```shell
+pip install "feapder[render]"
+```
完整版:
```shell
-pip3 install feapder[all]
-```
+pip install "feapder[all]"
+```
-通用版与完整版区别:
+三个版本区别:
+
+1. 精简版:不支持浏览器渲染、不支持基于内存去重、不支持入库mongo
+2. 浏览器渲染版:不支持基于内存去重、不支持入库mongo
+3. 完整版:支持所有功能
-1. 完整版支持基于内存去重
完整版可能会安装出错,若安装出错,请参考[安装问题](question/安装问题)
@@ -98,7 +86,7 @@ class FirstSpider(feapder.AirSpider):
if __name__ == "__main__":
FirstSpider().start()
-
+
```
直接运行,打印如下:
@@ -123,32 +111,34 @@ FirstSpider|2021-02-09 14:55:14,620|air_spider.py|run|line:80|INFO| 无任务,
## 爬虫工具推荐
1. 爬虫在线工具库:http://www.spidertools.cn
-2. 验证码识别库:https://github.com/sml2h3/ddddocr
+2. 爬虫管理系统:http://feapder.com/#/feapder_platform/feaplat
+3. 验证码识别库:https://github.com/sml2h3/ddddocr
-## 微信赞赏
+
## 学习交流
-
-
- | 知识星球:17321694 |
- 作者微信: boris_tm |
- QQ群号:750614606 |
-
-
+
+
+ | 知识星球:17321694 |
+ 作者微信: boris_tm |
+ QQ群号:521494615 |
+
+
|
- |
- |
- |
-
-
-
+
+ |
+ |
+
+
+
+
加好友备注:feapder
\ No newline at end of file
diff --git a/docs/_sidebar.md b/docs/_sidebar.md
index c8f98d37..bef51b37 100644
--- a/docs/_sidebar.md
+++ b/docs/_sidebar.md
@@ -11,6 +11,7 @@
* [使用前必读](usage/使用前必读.md)
* [轻量爬虫-AirSpider](usage/AirSpider.md)
* [分布式爬虫-Spider](usage/Spider.md)
+ * [任务爬虫-TaskSpider](usage/TaskSpider.md)
* [批次爬虫-BatchSpider](usage/BatchSpider.md)
* [爬虫集成](usage/爬虫集成.md)
@@ -19,7 +20,8 @@
* [响应-Response](source_code/Response.md)
* [代理使用说明](source_code/proxy.md)
* [用户池说明](source_code/UserPool.md)
- * [浏览器渲染](source_code/浏览器渲染.md)
+ * [浏览器渲染-Selenium](source_code/浏览器渲染-Selenium.md)
+ * [浏览器渲染-Playwright](source_code/浏览器渲染-Playwright)
* [解析器-BaseParser](source_code/BaseParser.md)
* [批次解析器-BatchParser](source_code/BatchParser.md)
* [Spider进阶](source_code/Spider进阶.md)
@@ -36,6 +38,7 @@
* [海量数据去重-dedup](source_code/dedup.md)
* [报警及监控](source_code/报警及监控.md)
* [监控打点](source_code/监控打点.md)
+ * [自定义下载器](source_code/custom_downloader.md)
* 爬虫管理系统
* [简介及部署](feapder_platform/feaplat.md)
@@ -45,4 +48,5 @@
* 常见问题
* [安装问题](question/安装问题.md)
* [运行问题](question/运行问题.md)
- * [请求问题](question/请求问题.md)
\ No newline at end of file
+ * [请求问题](question/请求问题.md)
+ * [setting不生效问题](question/setting不生效问题.md)
\ No newline at end of file
diff --git a/docs/command/cmdline.md b/docs/command/cmdline.md
index 91aadd81..74691832 100644
--- a/docs/command/cmdline.md
+++ b/docs/command/cmdline.md
@@ -24,43 +24,39 @@
Available commands:
create create project、feapder、item and so on
shell debug response
+ zip zip project
Use "feapder -h" to see more info about a command
-可见feapder支持`create`及`shell`两种命令
+可见feapder支持`create`、`shell`及`zip`三种命令
## 2. feapder create
使用feapder create 可快速创建项目、爬虫、item等,具体支持的命令可输入`feapder create -h` 查看使用帮助
> feapder create -h
- usage: feapder [-h] [-p] [-s [...]] [-i [...]] [-t] [-init] [-j] [-sj]
- [--host] [--port] [--username] [--password] [--db]
+ usage: cmdline.py [-h] [-p] [-s] [-i] [-t] [-init] [-j] [-sj] [-c] [--params] [--setting] [--host] [--port] [--username] [--password] [--db]
生成器
-
+
optional arguments:
- -h, --help show this help message and exit
- -p , --project 创建项目 如 feapder create -p
- -s [ ...], --spider [ ...]
- 创建爬虫 如 feapder create -s
- spider_type=1 AirSpider; spider_type=2 Spider;
- spider_type=3 BatchSpider;
- -i [ ...], --item [ ...]
- 创建item 如 feapder create -i test 则生成test表对应的item。
- 支持like语法模糊匹配所要生产的表。 若想生成支持字典方式赋值的item,则create -item
- test 1
- -t , --table 根据json创建表 如 feapder create -t
- -init 创建__init__.py 如 feapder create -init
- -j, --json 创建json
- -sj, --sort_json 创建有序json
- --setting 创建全局配置文件 feapder create -setting
- --host mysql 连接地址
- --port mysql 端口
- --username mysql 用户名
- --password mysql 密码
- --db mysql 数据库名
+ -h, --help show this help message and exit
+ -p , --project 创建项目 如 feapder create -p
+ -s , --spider 创建爬虫 如 feapder create -s
+ -i , --item 创建item 如 feapder create -i 支持模糊匹配 如 feapder create -i %table_name%
+ -t , --table 根据json创建表 如 feapder create -t
+ -init 创建__init__.py 如 feapder create -init
+ -j, --json 创建json
+ -sj, --sort_json 创建有序json
+ -c, --cookies 创建cookie
+ --params 解析地址中的参数
+ --setting 创建全局配置文件feapder create --setting
+ --host mysql 连接地址
+ --port mysql 端口
+ --username mysql 用户名
+ --password mysql 密码
+ --db mysql 数据库名
具体使用方法如下:
@@ -87,23 +83,23 @@
### 2. 创建爬虫
-爬虫分为3种,分别为 轻量级爬虫(AirSpider)、分布式爬虫(Spider)以及 批次爬虫(BatchSpider)
-
命令
- feapder create -s
-
-* AirSpider 对应的 spider_type 值为 1
-* Spider 对应的 spider_type 值为 2
-* BatchSpider 对应的 spider_type 值为 3
-* 默认 spider_type 值为 1
-
-AirSpider爬虫示例:
+ feapder create -s
+
+示例:创建名为first_spider的爬虫
- feapder create -s first_spider 1
+```shell
+feapder create -s first_spider
-
-生成first_spider.py, 内容如下:
+请选择爬虫模板
+> AirSpider
+ Spider
+ TaskSpider
+ BatchSpider
+```
+
+输入命令后,可以按上下键选择爬虫模板,如选择 AirSpider爬虫模板,生成first_spider.py, 内容如下:
import feapder
@@ -120,7 +116,7 @@ AirSpider爬虫示例:
FirstSpider().start()
-若为项目结构,建议先进入到spiders目录下,再创建爬虫
+若在项目下创建,建议先进入到spiders目录下,再创建爬虫
### 3. 创建 item
@@ -130,6 +126,16 @@ item为与数据库表的映射,与数据入库的逻辑相关。
命令
feapder create -i
+
+输出:
+
+```
+请选择Item类型
+> Item
+ Item 支持字典赋值
+ UpdateItem
+ UpdateItem 支持字典赋值
+```
示例
@@ -189,9 +195,9 @@ class SpiderDataItem(Item):
这样,以后所有的项目setting.py中均可不配置mysql连接信息
-**若item字段过多,不想逐一赋值,可通过如下方式创建**
+**若item字段过多,不想逐一赋值,可选择支持字典赋值的Item类型创建**
- feapder create -i spider_data 1
+
生成:
@@ -218,7 +224,7 @@ item = SpiderDataItem(**response_data)
```
-### 4. 创建json 或 有序json
+### 4. 创建json或有序json
此命令和快速将 `xxx:xxx` 这种字符串格式转为json格式,常用于将网页或者抓包工具抓取出来的header、cookie转为json
diff --git a/docs/feapder_platform/feaplat.md b/docs/feapder_platform/feaplat.md
index 83f028ca..405f3e0c 100644
--- a/docs/feapder_platform/feaplat.md
+++ b/docs/feapder_platform/feaplat.md
@@ -6,54 +6,61 @@
读音: `[ˈfiːplæt] `
-
+
+
## 特性
-1. 支持任何python脚本,包括不限于`feapder`、`scrapy`
-2. 支持浏览器渲染,支持有头模式。浏览器支持`playwright`、`selenium`
-3. 支持部署服务,可自动负载均衡
-4. 支持服务器集群管理
+1. 支持部署任何程序,包括不限于`feapder`、`scrapy`
+2. 支持集群管理,部署分布式爬虫可一键扩展进程数
+3. 支持部署服务,且可自动实现服务负载均衡
+4. 支持程序异常报警、重启、保活
5. 支持监控,监控内容可自定义
-6. 支持起多个实例,如分布式爬虫场景
-7. 支持弹性伸缩
-8. 支持4种定时启动方式
-9. 支持自定义worker镜像,如自定义java的运行环境、机器学习环境等,即根据自己的需求自定义(feaplat分为`master-调度端`和`worker-运行任务端`)
-10. docker一键部署,架设在docker swarm集群上
-
-
-## 为什么用feaplat爬虫管理系统
+6. 支持4种定时调度模式
+7. 自动从git仓库拉取最新的代码运行,支持指定分支
+8. 支持多人协同
+9. 支持浏览器渲染,支持有头模式。浏览器支持`playwright`、`selenium`
+10. 支持弹性伸缩
+12. 支持自定义worker镜像,如自定义java的运行环境、node运行环境等,即根据自己的需求自定义(feaplat分为`master-调度端`和`worker-运行任务端`)
+13. docker一键部署,架设在docker swarm集群上
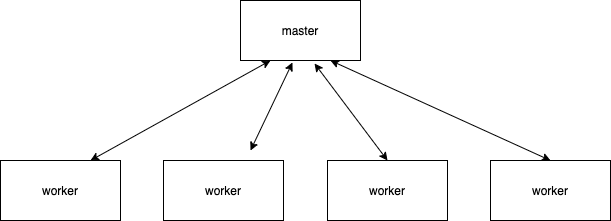
-**市面上的爬虫管理系统**
+## 功能概览
-
+暂时不支持 苹果电脑的Apple芯片
-worker节点常驻,且运行多个任务,不能弹性伸缩,任务之前会相互影响,稳定性得不到保障
-
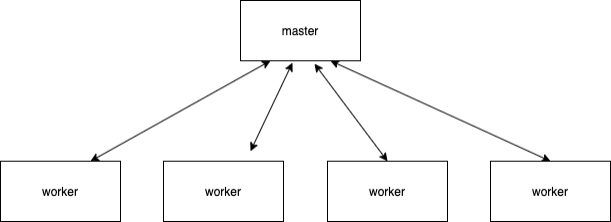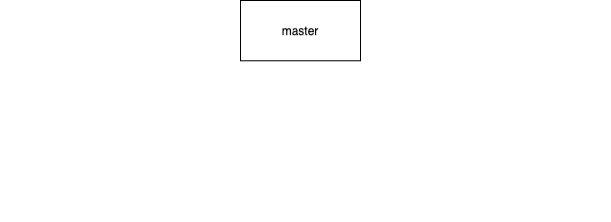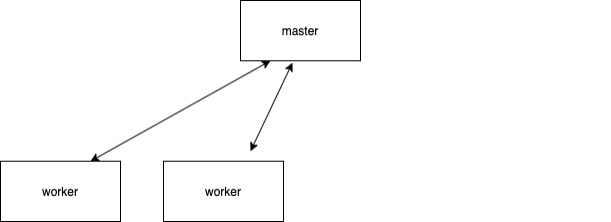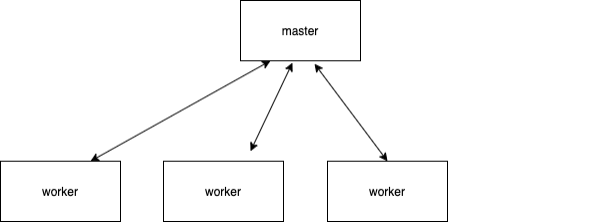
-**feaplat爬虫管理系统**
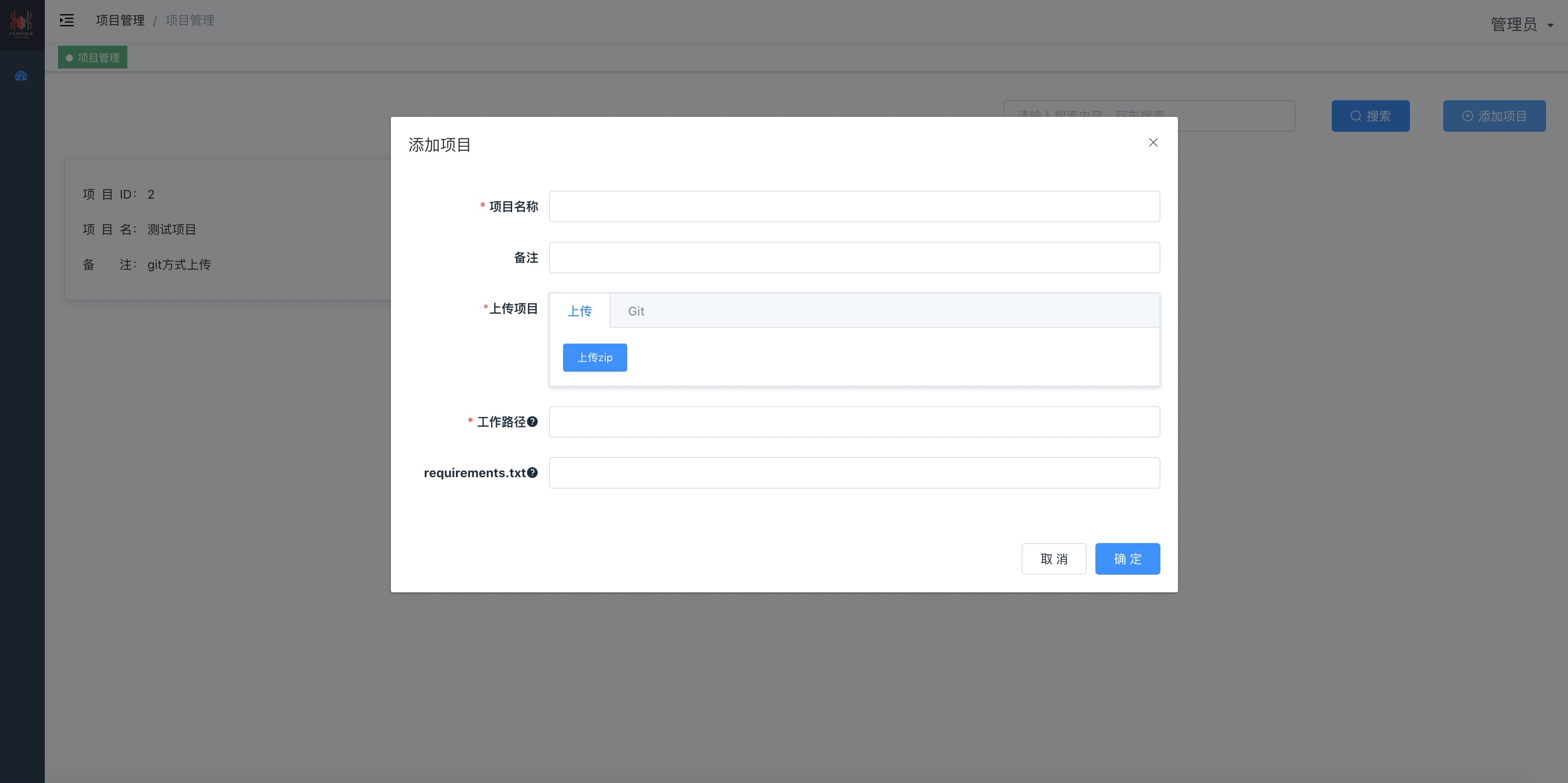
+### 1. 项目管理
-
+添加/编辑项目
-worker节点根据任务动态生成,一个worker只运行一个任务实例,任务做完worker销毁,稳定性高;多个服务器间自动均衡分配,弹性伸缩
+
+- 支持 git和zip两种方式上传项目
+- 根据requirements.txt自动安装依赖包
+- 可选择多个人参与项目
-## 功能概览
+### 2. 任务管理
-### 1. 项目管理
+
+
-添加/编辑项目
-
+- 支持一键启动多个任务实例(分布式爬虫场景或者需要启动多个进程的场景)
+- 支持4种调度模式
+- 标签:给任务分类使用
+- 强制运行:(上一次任务没结束,本次是否运行,是则会停止上一次任务,然后运行本次调度)
+- 异常重启:当部署的程序异常退出,是否自动重启,且会报警
+ 
+- 支持限制程序运行的CPU、内存等。
-### 2. 任务管理
-
+### 3. 任务实例
+一键部署了20份程序,每个程序独占一个进程,可从列表看每个进程部署到哪台服务器上了,运行状态是什么
-### 3. 任务实例
+
-日志
-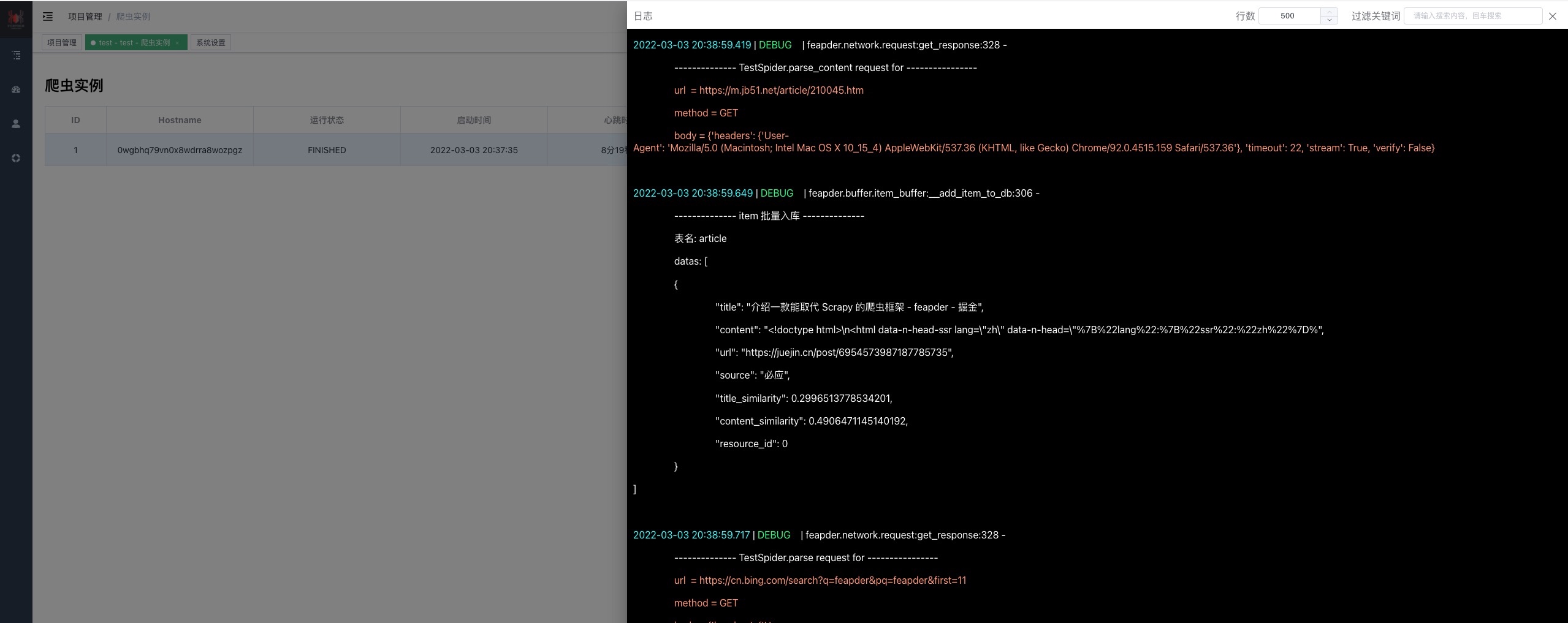
+实时查看日志
+
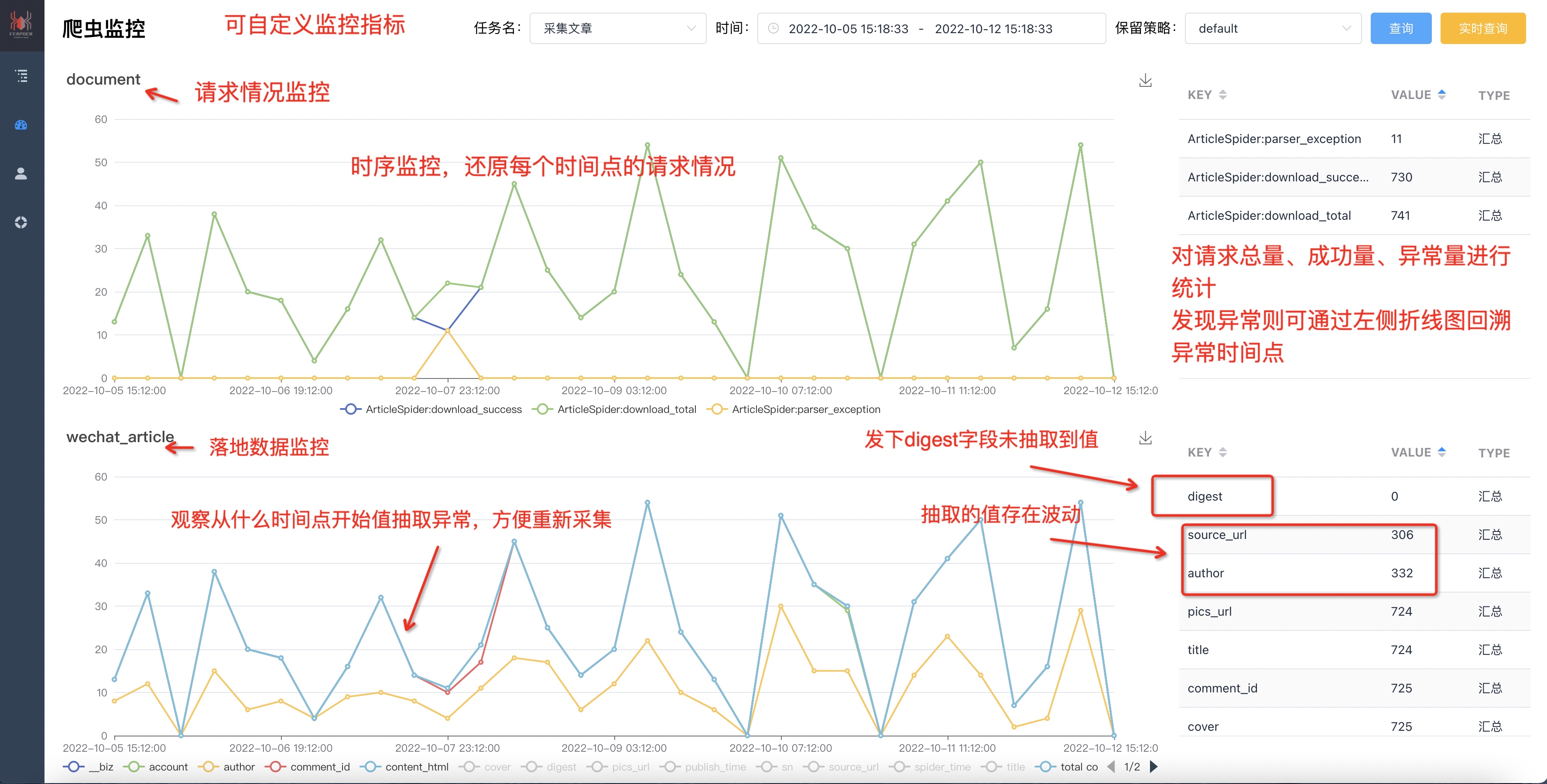
### 4. 爬虫监控
@@ -63,17 +70,43 @@ feaplat支持对feapder爬虫的运行情况进行监控,除了数据监控和
注:需 feapder>=1.6.6
-
+
+
+### 5. 报警
+调度异常、程序异常自动报警
+支持钉钉、企业微信、飞书、邮箱
+
+
+## 为什么用feaplat爬虫管理系统
+
+**稳!很稳!!相当稳!!!**
+
+### 市面上的爬虫管理系统
+
+
+
+worker节点常驻,且运行多个任务,不能弹性伸缩,任务之前会相互影响,稳定性得不到保障
+
+### feaplat爬虫管理系统
+
+
+
+worker节点根据任务动态生成,一个worker只运行一个任务实例,任务做完worker销毁,稳定性高;多个服务器间自动均衡分配,弹性伸缩
## 部署
-> 下面部署以centos为例, 其他平台docker安装方式可参考docker官方文档:https://docs.docker.com/compose/install/
+> 安装方式参考docker官方文档:https://docs.docker.com/compose/install/
### 1. 安装docker
-删除旧版本(可选,需要重装升级时执行)
+#### 1.1 centos系统
+
+> docker --version
+> 作者的docker版本为 20.10.12,低于此版本的可能会存在问题
+
+删除旧版本(可选,需要重装升级docker时执行)
```shell
yum remove docker docker-common docker-selinux docker-engine
@@ -87,12 +120,74 @@ yum install -y yum-utils device-mapper-persistent-data lvm2 && python2 /usr/bin/
```shell
yum install -y yum-utils device-mapper-persistent-data lvm2 && python2 /usr/bin/yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo && yum install docker-ce -y
```
-启动
+或者使用国内 daocloud 一键安装命令
+```
+curl -sSL https://get.daocloud.io/docker | sh
+```
+
+启动docker服务
+
```shell
systemctl enable docker
systemctl start docker
```
+验证: 打开终端,输入
+
+```shell
+docker ps
+```
+
+#### 1.2 ubuntu系统
+
+```
+sudo apt update
+sudo apt install docker.io docker-compose
+```
+
+启动docker服务
+
+```shell
+sudo systemctl enable docker
+sudo systemctl start docker
+```
+
+验证: 打开终端,输入
+
+```shell
+sudo docker ps
+```
+
+#### 1.3 window系统
+
+访问下面的链接,下载Docker Desktop, 然后安装即可
+
+https://docs.docker.com/desktop/setup/install/windows-install/
+
+
+运行安装好的Docker Desktop
+
+验证: 打开cmd终端,输入
+
+```shell
+docker ps
+```
+
+#### 1.4 mac系统
+
+访问下面的链接,下载Docker Desktop, 然后安装即可
+
+https://docs.docker.com/desktop/setup/install/mac-install/
+
+
+运行安装好的Docker Desktop
+
+验证: 打开终端,输入
+```shell
+docker ps
+```
+
+
### 2. 安装 docker swarm
docker swarm init
@@ -100,7 +195,12 @@ systemctl start docker
# 如果你的 Docker 主机有多个网卡,拥有多个 IP,必须使用 --advertise-addr 指定 IP
docker swarm init --advertise-addr 192.168.99.100
-### 3. 安装docker-compose
+### 3. 安装docker-compose(非必须)
+一般安装完docker后,会自带 docker compose。可先输入下面的命令验证是否有改环境,若有则不需要安装
+``` shell
+docker compose
+```
+若无`docker compose`命令,则按照下面的安装
```shell
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
@@ -111,6 +211,9 @@ sudo chmod +x /usr/local/bin/docker-compose
sudo curl -L "https://get.daocloud.io/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
```
+安装后输入`docker-compose`验证是否成功
+
+注:`docker-compose` 与 `docker compose` 两种命令用法一样,是一个东西,只不过不同版本的docker可能叫法不一
### 4. 部署feaplat爬虫管理系统
#### 预备项
@@ -120,13 +223,16 @@ yum -y install git
```
#### 1. 下载项目
+> 先按照下面命令拉取develop分支代码运行。
+> master分支不支持urllib3>=2.0版本,现在已经运行不起来了,但之前老用户不受影响。待后续测试好兼容性,不影响老用户后,会将develop分支合并到master
+
gitub
```shell
-git clone https://github.com/Boris-code/feaplat.git
+git clone -b develop https://github.com/Boris-code/feaplat.git
```
gitee
```shell
-git clone https://gitee.com/Boris-code/feaplat.git
+git clone -b develop https://gitee.com/Boris-code/feaplat.git
```
#### 2. 运行
@@ -135,6 +241,8 @@ git clone https://gitee.com/Boris-code/feaplat.git
```shell
cd feaplat
+docker compose up -d
+或者
docker-compose up -d
```
@@ -170,13 +278,26 @@ docker-compose stop
docker swarm join-token worker
```
+输出举例如下
+
+```shell
+docker swarm join --token SWMTKN-1-1mix1x7noormwig1pjqzmrvgnw2m8zxqdzctqa8t3o8s25fjgg-9ot0h1gatxfh0qrxiee38xxxx 172.17.5.110:2377
+```
+
**在需扩充的服务器上执行**
```shell
docker swarm join --token [token] [ip]
```
-这条命令用于将该台服务器加入集群节点
+若服务器彼此之间不是内网,为公网环境,则需要将ip改成公网,且开放端口2377
+
+开启并检查2377端口
+```shell
+firewall-cmd --zone=public --add-port=2377/tcp --permanent
+firewall-cmd --reload
+firewall-cmd --query-port=2377/tcp
+```
#### 3. 验证是否成功
@@ -196,55 +317,93 @@ docker node ls
docker swarm leave
```
-## 拉取私有项目
+## 使用
-拉取私有项目需在git仓库里添加如下公钥
-
-```
-ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCd/k/tjbcMislEunjtYQNXxz5tgEDc/fSvuLHBNUX4PtfmMQ07TuUX2XJIIzLRPaqv3nsMn3+QZrV0xQd545FG1Cq83JJB98ATTW7k5Q0eaWXkvThdFeG5+n85KeVV2W4BpdHHNZ5h9RxBUmVZPpAZacdC6OUSBYTyCblPfX9DvjOk+KfwAZVwpJSkv4YduwoR3DNfXrmK5P+wrYW9z/VHUf0hcfWEnsrrHktCKgohZn9Fe8uS3B5wTNd9GgVrLGRk85ag+CChoqg80DjgFt/IhzMCArqwLyMn7rGG4Iu2Ie0TcdMc0TlRxoBhqrfKkN83cfQ3gDf41tZwp67uM9ZN feapder@qq.com
-```
-
-或在系统设置页面配置您的SSH私钥,然后在git仓库里添加您的公钥,例如:
-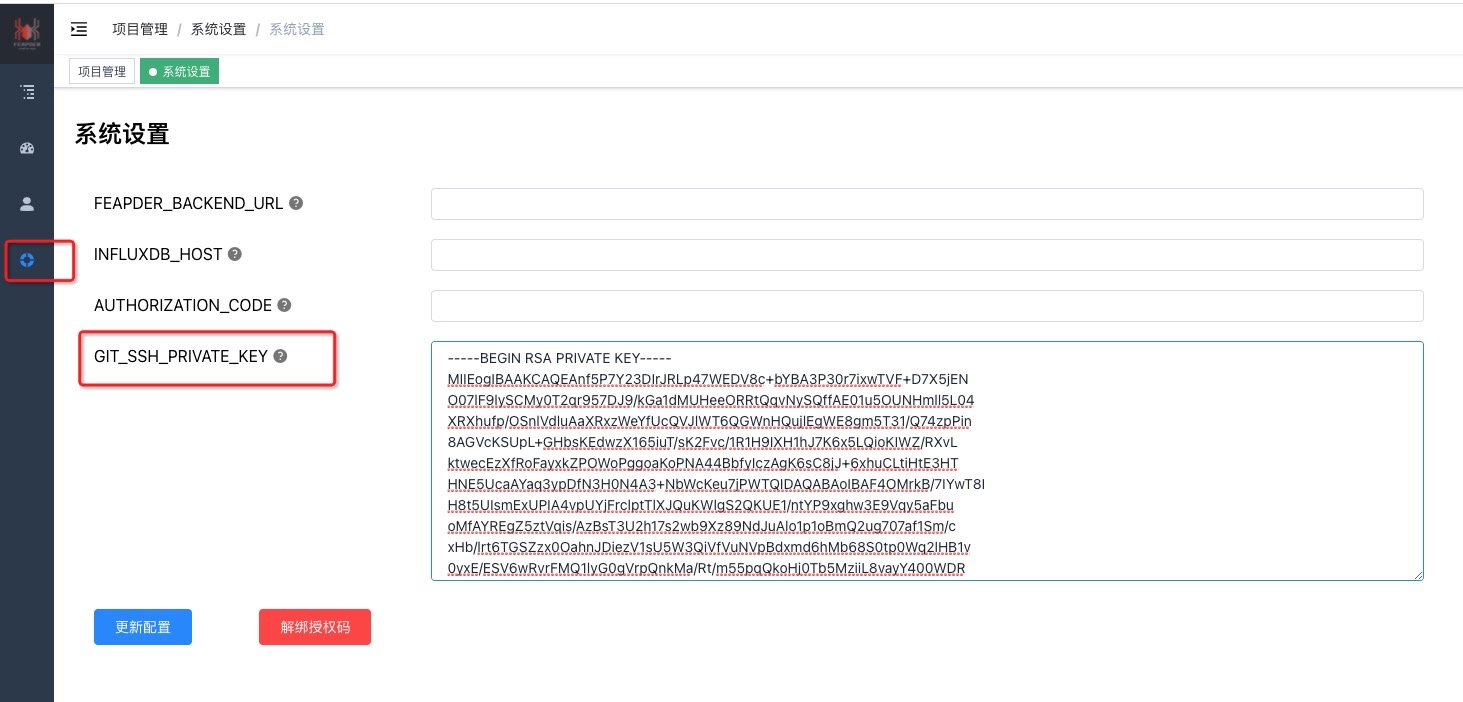
-
-注意,公私钥加密方式为RSA,其他的可能会有问题
-
-生成RSA公私钥方式如下:
-```shell
-ssh-keygen -t rsa -C "备注" -f 生成路径/文件名
-```
-如:
-`ssh-keygen -t rsa -C "feaplat" -f id_rsa`
-然后一路回车,不要输密码
-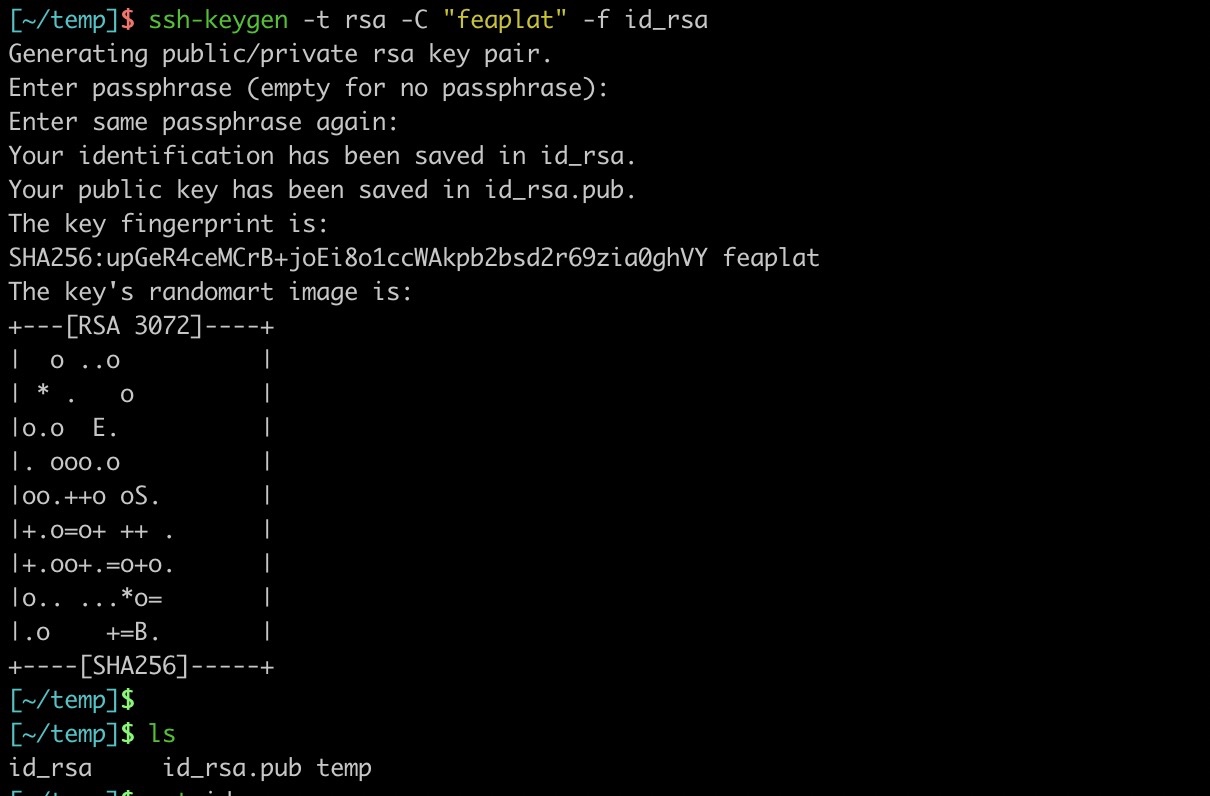
-最终生成 `id_rsa`、`id_rsa.pub` 文件,复制`id_rsa.pub`文件内容到git仓库,复制`id_rsa`文件内容到feaplat爬虫管理系统
+见 [FEAPLAT使用说明](feapder_platform/usage)
## 自定义爬虫镜像
默认的爬虫镜像只打包了`feapder`、`scrapy`框架,若需要其它环境,可基于`.env`文件里的`SPIDER_IMAGE`镜像自行构建
-如将常用的python库打包到镜像
+如自定义python版本,安装常用的库等,需修改feaplat下的`feapder_dockerfile`
+
```
-FROM registry.cn-hangzhou.aliyuncs.com/feapderd/feapder:[最新版本号]
+# 基于最新的版本,若需要自定义python版本,则要求feapder版本号>=2.4
+FROM registry.cn-hangzhou.aliyuncs.com/feapderd/feapder:2.4
+
+# 安装自定义的python版本,3.10.8
+RUN set -ex \
+ && wget https://www.python.org/ftp/python/3.10.8/Python-3.10.8.tgz \
+ && tar -zxvf Python-3.10.8.tgz \
+ && cd Python-3.10.8 \
+ && ./configure prefix=/usr/local/python-3.10.8 \
+ && make \
+ && make install \
+ && make clean \
+ && rm -rf /Python-3.10.8* \
+ # 配置软链接
+ && ln -s /usr/local/python-3.10.8/bin/python3 /usr/bin/python3.10.8 \
+ && ln -s /usr/local/python-3.10.8/bin/pip3 /usr/bin/pip3.10.8
+
+# 删除之前的默认python版本
+RUN set -ex \
+ && rm -rf /usr/bin/python3 \
+ && rm -rf /usr/bin/pip3 \
+ && rm -rf /usr/bin/python \
+ && rm -rf /usr/bin/pip
+
+# 设置默认为python3.10.8
+RUN set -ex \
+ && ln -s /usr/local/python-3.10.8/bin/python3 /usr/bin/python \
+ && ln -s /usr/local/python-3.10.8/bin/python3 /usr/bin/python3 \
+ && ln -s /usr/local/python-3.10.8/bin/pip3 /usr/bin/pip \
+ && ln -s /usr/local/python-3.10.8/bin/pip3 /usr/bin/pip3
+
+# 将python3.10.8加入到环境变量
+ENV PATH=$PATH:/usr/local/python-3.10.8/bin/
# 安装依赖
RUN pip3 install feapder \
&& pip3 install scrapy
+
+# 安装node依赖包,内置的node为v10.15.3版本
+# RUN npm install packageName -g
```
-自己随便搞事情,搞完修改下 `.env`文件里的 SPIDER_IMAGE 的值即可
+改好后要打包镜像,打包命令:
+```
+docker build -f feapder_dockerfile -t 镜像名:版本号 .
+```
+如
+```
+docker build -f feapder_dockerfile -t my_feapder:1.0 .
+```
+
+打包好后修改下 `.env`文件里的 SPIDER_IMAGE 的值即可如:
+```
+SPIDER_IMAGE=my_feapder:1.0
+```
+注:
+1. 若有多个worker服务器,且没将镜像传到镜像服务,则需要手动将镜像推到其他服务器上,否则无法拉取此镜像运行
+2. 若自定义了python版本,则需要添加挂载,否则feaplat上自动安装的依赖库不会保留。挂载方式:修改`docker-compose.yaml`的 SPIDER_RUN_ARGS参数。如
+ ```
+ SPIDER_RUN_ARGS=["--mount type=volume,source=feapder_python3.10,destination=/usr/local/python-3.10.8"]
+ ```
## 价格
-| 类型 | 价格 | 说明 |
-|------|-----|-------------------------------|
-| 免费版 | 0元 | 可部署2个任务 |
-| 绑定版 | 188元 | 同一公网IP或机器码下永久使用 |
-| 非绑定版 | 288元 | 永久使用 |
+可免费部署20个任务,超出额度时,需购买授权码,在授权有效期内不限额度,可换绑服务器
+
+| 授权时长 | 价格 | 说明 |
+|------|------|---------------------|
+| 1个月 | 168元 | 无折扣|
+| 6个月| 666元 | 原价1008元,减免342元|
+| 1年 | 888元 | 原价2016元,减免1128元|
+| 2年 | 1500元 | 原价4032元,减免2532元|
-**所有版本功能一致,均可免费更新,永久使用**
+**删除任务不可恢复额度**
购买方式:添加微信 `boris_tm`
@@ -252,18 +411,18 @@ RUN pip3 install feapder \
## 学习交流
-
-
- | 知识星球:17321694 |
- 作者微信: boris_tm |
- QQ群号:750614606 |
-
-
+
+
+ | 知识星球:17321694 |
+ 作者微信: boris_tm |
+ QQ群号:521494615 |
+
+
|
- |
-  |
- |
-
-
-
- 加好友备注:feaplat
+
+ |
+ |
+
+
+
+ 加好友备注:feapder
diff --git a/docs/feapder_platform/feaplat_bak.md b/docs/feapder_platform/feaplat_bak.md
new file mode 100644
index 00000000..87333075
--- /dev/null
+++ b/docs/feapder_platform/feaplat_bak.md
@@ -0,0 +1,288 @@
+# 爬虫管理系统 - FEAPLAT
+
+> 生而为虫,不止于虫
+
+**feaplat**命名源于 feapder 与 platform 的缩写
+
+读音: `[ˈfiːplæt] `
+
+
+
+## 特性
+
+1. 支持任何python脚本,包括不限于`feapder`、`scrapy`
+2. 支持浏览器渲染,支持有头模式。浏览器支持`playwright`、`selenium`
+3. 支持部署服务,可自动负载均衡
+4. 支持服务器集群管理
+5. 支持监控,监控内容可自定义
+6. 支持起多个实例,如分布式爬虫场景
+7. 支持弹性伸缩
+8. 支持4种定时启动方式
+9. 支持自定义worker镜像,如自定义java的运行环境、机器学习环境等,即根据自己的需求自定义(feaplat分为`master-调度端`和`worker-运行任务端`)
+10. docker一键部署,架设在docker swarm集群上
+
+
+## 为什么用feaplat爬虫管理系统
+
+**市面上的爬虫管理系统**
+
+
+
+worker节点常驻,且运行多个任务,不能弹性伸缩,任务之前会相互影响,稳定性得不到保障
+
+**feaplat爬虫管理系统**
+
+
+
+worker节点根据任务动态生成,一个worker只运行一个任务实例,任务做完worker销毁,稳定性高;多个服务器间自动均衡分配,弹性伸缩
+
+
+## 功能概览
+
+### 1. 项目管理
+
+添加/编辑项目
+
+
+### 2. 任务管理
+
+
+
+
+### 3. 任务实例
+
+日志
+
+
+
+### 4. 爬虫监控
+
+feaplat支持对feapder爬虫的运行情况进行监控,除了数据监控和请求监控外,用户还可自定义监控内容,详情参考[自定义监控](source_code/监控打点?id=自定义监控)
+
+若scrapy爬虫或其他python脚本使用监控功能,也可通过自定义监控的功能来支持,详情参考[自定义监控](source_code/监控打点?id=自定义监控)
+
+注:需 feapder>=1.6.6
+
+
+
+
+
+## 部署
+
+> 下面部署以centos为例, 其他平台docker安装方式可参考docker官方文档:https://docs.docker.com/compose/install/
+
+### 1. 安装docker
+
+删除旧版本(可选,需要重装升级时执行)
+
+```shell
+yum remove docker docker-common docker-selinux docker-engine
+```
+
+安装:
+```shell
+yum install -y yum-utils device-mapper-persistent-data lvm2 && python2 /usr/bin/yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo && yum install docker-ce -y
+```
+国内用户推荐使用
+```shell
+yum install -y yum-utils device-mapper-persistent-data lvm2 && python2 /usr/bin/yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo && yum install docker-ce -y
+```
+或者使用国内 daocloud 一键安装命令
+```
+curl -sSL https://get.daocloud.io/docker | sh
+```
+
+
+
+启动
+```shell
+systemctl enable docker
+systemctl start docker
+```
+
+### 2. 安装 docker swarm
+
+ docker swarm init
+
+ # 如果你的 Docker 主机有多个网卡,拥有多个 IP,必须使用 --advertise-addr 指定 IP
+ docker swarm init --advertise-addr 192.168.99.100
+
+### 3. 安装docker-compose
+
+```shell
+sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
+sudo chmod +x /usr/local/bin/docker-compose
+```
+国内用户推荐使用
+```shell
+sudo curl -L "https://get.daocloud.io/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
+sudo chmod +x /usr/local/bin/docker-compose
+```
+
+### 4. 部署feaplat爬虫管理系统
+#### 预备项
+安装git(1.8.3的版本已够用)
+```shell
+yum -y install git
+```
+#### 1. 下载项目
+
+gitub
+```shell
+git clone https://github.com/Boris-code/feaplat.git
+```
+gitee
+```shell
+git clone https://gitee.com/Boris-code/feaplat.git
+```
+
+#### 2. 运行
+
+首次运行需拉取镜像,时间比较久,且运行可能会报错,再次运行下就好了
+
+```shell
+cd feaplat
+docker-compose up -d
+```
+
+- 若端口冲突,可修改.env文件,参考[常见问题](feapder_platform/question?id=修改端口)
+
+#### 3. 访问爬虫管理系统
+
+默认地址:`http://localhost`
+默认账密:admin / admin
+
+- 若未成功,参考[常见问题](feapder_platform/question)
+- 使用说明,参考[使用说明](feapder_platform/usage)
+
+#### 4. 停止(可选)
+
+```shell
+docker-compose stop
+```
+
+### 5. 添加服务器(可选)
+
+> 用于搭建集群,扩展爬虫(worker)节点服务器
+
+#### 1. 安装docker
+
+参考部署步骤1
+
+#### 2. 部署
+
+在master服务器(feaplat爬虫管理系统所在服务器)执行下面命令,查看token
+
+```shell
+docker swarm join-token worker
+```
+
+输出举例如下
+
+```shell
+docker swarm join --token SWMTKN-1-1mix1x7noormwig1pjqzmrvgnw2m8zxqdzctqa8t3o8s25fjgg-9ot0h1gatxfh0qrxiee38xxxx 172.17.5.110:2377
+```
+
+**在需扩充的服务器上执行**
+
+```shell
+docker swarm join --token [token] [ip]
+```
+
+若服务器彼此之间不是内网,为公网环境,则需要将ip改成公网,且开放端口2377
+
+开启并检查2377端口
+```shell
+firewall-cmd --zone=public --add-port=2377/tcp --permanent
+firewall-cmd --reload
+firewall-cmd --query-port=2377/tcp
+```
+
+#### 3. 验证是否成功
+
+在master服务器(feaplat爬虫管理系统所在服务器)执行下面命令
+
+```shell
+docker node ls
+```
+
+若打印结果包含刚加入的服务器,则添加服务器成功
+
+#### 4. 下线服务器(可选)
+
+在需要下线的服务器上执行
+
+```shell
+docker swarm leave
+```
+
+## 拉取私有项目
+
+拉取私有项目需在git仓库里添加如下公钥
+
+```
+ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCd/k/tjbcMislEunjtYQNXxz5tgEDc/fSvuLHBNUX4PtfmMQ07TuUX2XJIIzLRPaqv3nsMn3+QZrV0xQd545FG1Cq83JJB98ATTW7k5Q0eaWXkvThdFeG5+n85KeVV2W4BpdHHNZ5h9RxBUmVZPpAZacdC6OUSBYTyCblPfX9DvjOk+KfwAZVwpJSkv4YduwoR3DNfXrmK5P+wrYW9z/VHUf0hcfWEnsrrHktCKgohZn9Fe8uS3B5wTNd9GgVrLGRk85ag+CChoqg80DjgFt/IhzMCArqwLyMn7rGG4Iu2Ie0TcdMc0TlRxoBhqrfKkN83cfQ3gDf41tZwp67uM9ZN feapder@qq.com
+```
+
+或在系统设置页面配置您的SSH私钥,然后在git仓库里添加您的公钥,例如:
+
+
+注意,公私钥加密方式为RSA,其他的可能会有问题
+
+生成RSA公私钥方式如下:
+```shell
+ssh-keygen -t rsa -C "备注" -f 生成路径/文件名
+```
+如:
+`ssh-keygen -t rsa -C "feaplat" -f id_rsa`
+然后一路回车,不要输密码
+
+最终生成 `id_rsa`、`id_rsa.pub` 文件,复制`id_rsa.pub`文件内容到git仓库,复制`id_rsa`文件内容到feaplat爬虫管理系统
+
+## 自定义爬虫镜像
+
+默认的爬虫镜像只打包了`feapder`、`scrapy`框架,若需要其它环境,可基于`.env`文件里的`SPIDER_IMAGE`镜像自行构建
+
+如将常用的python库打包到镜像
+```
+FROM registry.cn-hangzhou.aliyuncs.com/feapderd/feapder:[最新版本号]
+
+# 安装依赖
+RUN pip3 install feapder \
+ && pip3 install scrapy
+
+```
+
+自己随便搞事情,搞完修改下 `.env`文件里的 SPIDER_IMAGE 的值即可
+
+
+## 价格
+
+| 类型 | 价格 | 说明 |
+|------|------|---------------------|
+| 试用版 | 0元 | 可部署20个任务,删除任务不可恢复额度 |
+| 正式版 | 888元 | 有效期一年,可换绑服务器 |
+
+**部署后默认为试用版,购买授权码后配置到系统里即为正式版**
+
+购买方式:添加微信 `boris_tm`
+
+随着功能的完善,价格会逐步调整
+
+## 学习交流
+
+
+
+ | 知识星球:17321694 |
+ 作者微信: boris_tm |
+ QQ群号:750614606 |
+
+
+ |
+ |
+ |
+ |
+
+
+
+ 加好友备注:feaplat
diff --git a/docs/feapder_platform/question.md b/docs/feapder_platform/question.md
index 9b59ee6c..78de0f2f 100644
--- a/docs/feapder_platform/question.md
+++ b/docs/feapder_platform/question.md
@@ -52,8 +52,14 @@ INFLUXDB_PORT_UDP=8089
1. 查看后端日志,观察报错
1. 若是docker版本问题,参考部署一节安装最新版本,
2. 若是报 `This node is not a swarm manager`,则是部署环境没准备好,执行`docker swarm init`,可参考参考部署一节
-2. 查看镜像`docker images`,若不存在爬虫镜像`registry.cn-hangzhou.aliyuncs.com/feapderd/feapder`,可能自动拉取失败了,可手动拉取,拉取命令:`docker pull registry.cn-hangzhou.aliyuncs.com/feapderd/feapder:版本号`,版本号在`.env`里查看
-3. 重启docker服务,Centos对应的命令为:`service docker restart`,其他自行查资料
+2. 查看worker状态:
+ ```
+ docker service ps task_任务id --no-trunc
+ ```
+ 看看error信息
+
+4. 查看镜像`docker images`,若不存在爬虫镜像`registry.cn-hangzhou.aliyuncs.com/feapderd/feapder`,可能自动拉取失败了,可手动拉取,拉取命令:`docker pull registry.cn-hangzhou.aliyuncs.com/feapderd/feapder:版本号`,版本号在`.env`里查看
+5. 重启docker服务,Centos对应的命令为:`service docker restart`,其他自行查资料
## 依赖包安装失败,可手动安装包
@@ -88,7 +94,62 @@ INFLUXDB_PORT_UDP=8089
rm -f /etc/localtime
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
-# 校对时间
+# 校对时间 方式1
clock --hctosys
+# 校对时间 方式2
+ntpdate 0.asia.pool.ntp.org
```
-
\ No newline at end of file
+
+## 我搭建了个集群,如何让主节点不跑任务
+
+在主节点上执行下面命令,将其设置成drain状态即可
+
+ docker node update --availability drain 节点id
+
+ ## Network 问题
+
+attaching to network failed, make sure your network options are correct and check manager logs: context deadline exceeded
+ 
+
+1. 确定当前节点是不是Drain节点:docker node ls
+
+ 
+
+ 是则继续往下看,不是则在评论区留言
+
+1. 修复
+
+ ```
+ docker node update --availability active 节点id
+ docker node update --availability drain 节点id
+ ```
+
+原因是Drain节点,不能为其分配网络资源,需要先改成active,然后启动,之后在改回drain
+
+**若不是以上情况,可能是network内的可分配的ip满了(老版本feaplat会有这个问题),那么可继续往下看**
+
+1. 先检查feaplat目录下的docker-compost.yaml,翻到最后,看network相关配置是否为如下。若不是,则改成下面这样的。若下面指定的11 ip段和主机有冲突,可以写12、13等
+
+ ```
+ networks:
+ default:
+ name: feaplat
+ driver: overlay
+ attachable: true
+ ipam:
+ config:
+ - subnet: 11.0.0.0/8
+ gateway: 11.0.0.1
+ ```
+
+ 完整配置见:https://github.com/Boris-code/feaplat/blob/develop/docker-compose.yaml
+
+
+2. 改完后,需要删除之前的network,使其重新创建,命令如下:
+
+ ```
+ docker service ls -q | xargs docker service rm # 注意 这个会停止掉所有任务。
+ docker network rm feaplat # 删除网络
+ docker compose rm # 删除之前feaplat运行环境
+ docker compose up -d # 启动
+ ```
\ No newline at end of file
diff --git a/docs/feapder_platform/usage.md b/docs/feapder_platform/usage.md
index 100cd423..20e7bb12 100644
--- a/docs/feapder_platform/usage.md
+++ b/docs/feapder_platform/usage.md
@@ -31,7 +31,7 @@
1. 准备项目,项目结构如下:

-2. 压缩后上传:
+2. 压缩后上传:(推荐使用 `feapder zip` 命令压缩)

- 工作路径:上传的项目会被放到docker里的根目录下(跟你本机项目路径没关系),然后解压运行。因`feapder_demo.zip`解压后为`feapder_demo`,所以工作路径配置`/feapder_demo`
- 本项目没依赖,可以不配置`requirements.txt`
@@ -44,6 +44,30 @@

可以看到已经运行完毕
+
+## git方式拉取私有项目
+
+拉取私有项目需在git仓库里添加如下公钥
+
+```
+ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCd/k/tjbcMislEunjtYQNXxz5tgEDc/fSvuLHBNUX4PtfmMQ07TuUX2XJIIzLRPaqv3nsMn3+QZrV0xQd545FG1Cq83JJB98ATTW7k5Q0eaWXkvThdFeG5+n85KeVV2W4BpdHHNZ5h9RxBUmVZPpAZacdC6OUSBYTyCblPfX9DvjOk+KfwAZVwpJSkv4YduwoR3DNfXrmK5P+wrYW9z/VHUf0hcfWEnsrrHktCKgohZn9Fe8uS3B5wTNd9GgVrLGRk85ag+CChoqg80DjgFt/IhzMCArqwLyMn7rGG4Iu2Ie0TcdMc0TlRxoBhqrfKkN83cfQ3gDf41tZwp67uM9ZN feapder@qq.com
+```
+
+或在系统设置页面配置您的SSH私钥,然后在git仓库里添加您的公钥,例如:
+
+
+注意,公私钥加密方式为RSA,其他的可能会有问题
+
+生成RSA公私钥方式如下:
+```shell
+ssh-keygen -t rsa -C "备注" -f 生成路径/文件名
+```
+如:
+`ssh-keygen -t rsa -C "feaplat" -f id_rsa`
+然后一路回车,不要输密码
+
+最终生成 `id_rsa`、`id_rsa.pub` 文件,复制`id_rsa.pub`文件内容到git仓库,复制`id_rsa`文件内容到feaplat爬虫管理系统
+
## 爬虫监控
diff --git a/docs/images/aliyun_sale.jpg b/docs/images/aliyun_sale.jpg
deleted file mode 100644
index f7b42b1a..00000000
Binary files a/docs/images/aliyun_sale.jpg and /dev/null differ
diff --git a/docs/images/qingguo.jpg b/docs/images/qingguo.jpg
new file mode 100644
index 00000000..24331df2
Binary files /dev/null and b/docs/images/qingguo.jpg differ
diff --git a/docs/index.html b/docs/index.html
index 75f1c322..d1112896 100644
--- a/docs/index.html
+++ b/docs/index.html
@@ -2,160 +2,171 @@
-
- feapder-document
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
+
+ feapder官方文档|feapder-document
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
+
+
+
+
+
+
+
+
+
-
-
-
-
-
-
-
-
-
-
-
-
+ -->
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/lib/docsify-copy-code/docsify-copy-code.min.js b/docs/lib/docsify-copy-code/docsify-copy-code.min.js
new file mode 100644
index 00000000..dee84c79
--- /dev/null
+++ b/docs/lib/docsify-copy-code/docsify-copy-code.min.js
@@ -0,0 +1,9 @@
+/*!
+ * docsify-copy-code
+ * v2.1.0
+ * https://github.com/jperasmus/docsify-copy-code
+ * (c) 2017-2019 JP Erasmus
+ * MIT license
+ */
+!function(){"use strict";function r(o){return(r="function"==typeof Symbol&&"symbol"==typeof Symbol.iterator?function(o){return typeof o}:function(o){return o&&"function"==typeof Symbol&&o.constructor===Symbol&&o!==Symbol.prototype?"symbol":typeof o})(o)}!function(o,e){void 0===e&&(e={});var t=e.insertAt;if(o&&"undefined"!=typeof document){var n=document.head||document.getElementsByTagName("head")[0],c=document.createElement("style");c.type="text/css","top"===t&&n.firstChild?n.insertBefore(c,n.firstChild):n.appendChild(c),c.styleSheet?c.styleSheet.cssText=o:c.appendChild(document.createTextNode(o))}}(".docsify-copy-code-button,.docsify-copy-code-button span{cursor:pointer;transition:all .25s ease}.docsify-copy-code-button{position:absolute;z-index:1;top:0;right:0;overflow:visible;padding:.65em .8em;border:0;border-radius:0;outline:0;font-size:1em;background:grey;background:var(--theme-color,grey);color:#fff;opacity:0}.docsify-copy-code-button span{border-radius:3px;background:inherit;pointer-events:none}.docsify-copy-code-button .error,.docsify-copy-code-button .success{position:absolute;z-index:-100;top:50%;left:0;padding:.5em .65em;font-size:.825em;opacity:0;-webkit-transform:translateY(-50%);transform:translateY(-50%)}.docsify-copy-code-button.error .error,.docsify-copy-code-button.success .success{opacity:1;-webkit-transform:translate(-115%,-50%);transform:translate(-115%,-50%)}.docsify-copy-code-button:focus,pre:hover .docsify-copy-code-button{opacity:1}"),document.querySelector('link[href*="docsify-copy-code"]')&&console.warn("[Deprecation] Link to external docsify-copy-code stylesheet is no longer necessary."),window.DocsifyCopyCodePlugin={init:function(){return function(o,e){o.ready(function(){console.warn("[Deprecation] Manually initializing docsify-copy-code using window.DocsifyCopyCodePlugin.init() is no longer necessary.")})}}},window.$docsify=window.$docsify||{},window.$docsify.plugins=[function(o,s){o.doneEach(function(){var o=Array.apply(null,document.querySelectorAll("pre[data-lang]")),c={buttonText:"Copy to clipboard",errorText:"Error",successText:"Copied"};s.config.copyCode&&Object.keys(c).forEach(function(t){var n=s.config.copyCode[t];"string"==typeof n?c[t]=n:"object"===r(n)&&Object.keys(n).some(function(o){var e=-1',''.concat(c.buttonText,""),''.concat(c.errorText,""),''.concat(c.successText,""),""].join("");o.forEach(function(o){o.insertAdjacentHTML("beforeend",e)})}),o.mounted(function(){document.querySelector(".content").addEventListener("click",function(o){if(o.target.classList.contains("docsify-copy-code-button")){var e="BUTTON"===o.target.tagName?o.target:o.target.parentNode,t=document.createRange(),n=e.parentNode.querySelector("code"),c=window.getSelection();t.selectNode(n),c.removeAllRanges(),c.addRange(t);try{document.execCommand("copy")&&(e.classList.add("success"),setTimeout(function(){e.classList.remove("success")},1e3))}catch(o){console.error("docsify-copy-code: ".concat(o)),e.classList.add("error"),setTimeout(function(){e.classList.remove("error")},1e3)}"function"==typeof(c=window.getSelection()).removeRange?c.removeRange(t):"function"==typeof c.removeAllRanges&&c.removeAllRanges()}})})}].concat(window.$docsify.plugins||[])}();
+//# sourceMappingURL=docsify-copy-code.min.js.map
diff --git "a/docs/question/setting\344\270\215\347\224\237\346\225\210\351\227\256\351\242\230.md" "b/docs/question/setting\344\270\215\347\224\237\346\225\210\351\227\256\351\242\230.md"
new file mode 100644
index 00000000..0a443c97
--- /dev/null
+++ "b/docs/question/setting\344\270\215\347\224\237\346\225\210\351\227\256\351\242\230.md"
@@ -0,0 +1,38 @@
+# setting不生效问题
+
+## 问题
+
+以下面这个项目结构为例,在`spiders`目录下运行`spider_test.py`读取不到`setting.py`,所以`setting`的配置不生效。
+
+
+
+读取不到是因为python的环境变量问题,在spiders目录下运行,只会找spides目录下的文件
+
+## 解决方式
+
+### 方法1:在setting同级目录下运行
+
+在main.py中导入spider_test, 然后运行main.py
+
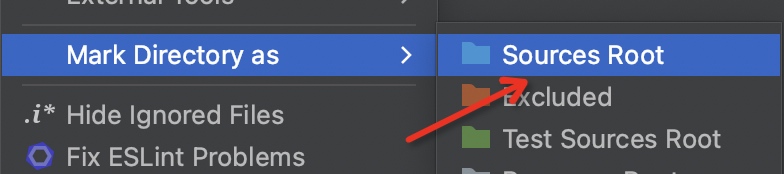
+### 方法2:设置工作区间
+
+设置工作区间方式(以pycharm为例):项目->右键->Mark Directory as -> Sources Root
+
+
+
+### 方法3:设置PYTHONPATH
+
+以mac或linux举例,执行如下命令
+
+```shell
+export PYTHONPATH=$PYTHONPATH:/绝对路径/spider-project
+```
+注:这个命令设置的环境变量只在当前终端有效
+
+然后即可在spiders目录下运行
+
+```shell
+python spider_test.py
+```
+
+window如何添加环境变量大家自行探索,搞定了可在评论区留言
\ No newline at end of file
diff --git "a/docs/question/\350\277\220\350\241\214\351\227\256\351\242\230.md" "b/docs/question/\350\277\220\350\241\214\351\227\256\351\242\230.md"
index cbc84e3b..ade03f4d 100644
--- "a/docs/question/\350\277\220\350\241\214\351\227\256\351\242\230.md"
+++ "b/docs/question/\350\277\220\350\241\214\351\227\256\351\242\230.md"
@@ -21,7 +21,7 @@
delete_keys为需要删除的key,类型: 元组/bool/string,支持正则; 常用于清空任务队列,否则重启时会断点续爬,如写成`delete_keys=True`也是可以的
-1. 手动修改任务分数为小于当前时间搓的分数
+1. 手动修改任务分数为小于当前时间戳的分数

diff --git a/docs/source_code/Item.md b/docs/source_code/Item.md
index 3aafe547..e48218b9 100644
--- a/docs/source_code/Item.md
+++ b/docs/source_code/Item.md
@@ -102,6 +102,26 @@ class SpiderDataItem(Item):
self.title = self.title.strip()
```
+## 指定入库使用的pipelines
+
+```python
+
+from feapder import Item
+from feapder.pipelines.csv_pipeline import CsvPipeline
+
+
+class SpiderDataItem(Item):
+
+ __pipelines__ = [CsvPipeline()]
+
+ def __init__(self, *args, **kwargs):
+ # self.id = None
+ self.title = None
+```
+
+使用__pipelines__指定后,该item只会流经指定的pipelines处理
+
+
## 更新数据
采集过程中,往往会有些数据漏采或解析出错,如果我们想更新已入库的数据,可将Item转为UpdateItem
diff --git a/docs/source_code/Response.md b/docs/source_code/Response.md
index d769a484..0fa80e60 100644
--- a/docs/source_code/Response.md
+++ b/docs/source_code/Response.md
@@ -145,13 +145,39 @@ response.open()
这个函数会打开浏览器,渲染下载内容,方便查看下载内容是否与数据源一致
-### 11. 将普通response转为feapder.Response
+### 11. 更新response.text的值
+
+```
+response.text = ""
+```
+常用于浏览器渲染模式,如页面有变化,可以取最新的页面内容更新到response.text里,然后使用response的选择器提取内容
+
+### 12. 将普通response转为feapder.Response
```
response = feapder.Response(response)
```
-### 12. 序列化与反序列化
+### 13. 将源码转为feapder.Response
+
+```
+response = feapder.Response.from_text(text=html, url="", cookies={}, headers={})
+```
+
+url是网页的地址,用来将html里的链接转为绝对链接,若不提供,则无法转换
+
+示例:
+```
+import feapder
+
+html = "hello word"
+response = feapder.Response.from_text(text=html, url="https://www.feapder.com", cookies={}, headers={})
+print(response.xpath("//a/@href").extract_first())
+
+输出:https://www.feapder.com/666
+```
+
+### 14. 序列化与反序列化
序列化
@@ -160,6 +186,7 @@ response = feapder.Response(response)
反序列化
feapder.Response.from_dict(response_dict)
+
### 其他
diff --git "a/docs/source_code/Spider\350\277\233\351\230\266.md" "b/docs/source_code/Spider\350\277\233\351\230\266.md"
index c99608b3..215898a8 100644
--- "a/docs/source_code/Spider\350\277\233\351\230\266.md"
+++ "b/docs/source_code/Spider\350\277\233\351\230\266.md"
@@ -46,9 +46,9 @@ redis_key为redis中存储任务等信息的key前缀,如redis_key="feapder:sp
key的命名方式为[配置文件](source_code/配置文件.md)中定义的
# 任务表模版
- TAB_REQUSETS = "{redis_key}:z_requsets"
+ TAB_REQUESTS = "{redis_key}:z_requsets"
# 任务失败模板
- TAB_FAILED_REQUSETS = "{redis_key}:z_failed_requsets"
+ TAB_FAILED_REQUESTS = "{redis_key}:z_failed_requsets"
# 爬虫状态表模版
TAB_SPIDER_STATUS = "{redis_key}:z_spider_status"
# item 表模版
diff --git a/docs/source_code/UpdateItem.md b/docs/source_code/UpdateItem.md
index a461fad4..3036628a 100644
--- a/docs/source_code/UpdateItem.md
+++ b/docs/source_code/UpdateItem.md
@@ -1,6 +1,6 @@
# UpdateItem
-UpdateItem用于更新数据,继承至Item,所以使用方式基本与Item一致,下载只说不同之处
+UpdateItem用于更新数据,继承至Item,所以使用方式基本与Item一致,下面只说不同之处
## 更新逻辑
@@ -70,4 +70,4 @@ item = item.to_UpdateItem()
item.update_key = "title"
```
-**推荐方式1,直接改Item类,不用修改爬虫代码**
\ No newline at end of file
+**推荐方式1,直接改Item类,不用修改爬虫代码**
diff --git a/docs/source_code/custom_downloader.md b/docs/source_code/custom_downloader.md
new file mode 100644
index 00000000..eb7c8c05
--- /dev/null
+++ b/docs/source_code/custom_downloader.md
@@ -0,0 +1,300 @@
+# 自定义下载器
+
+下载器一共分为三种:**普通下载器**、**支持保持session的下载器**以及**浏览器渲染下载器**。默认已经在框架中内置,setting中的配置如下
+
+```
+DOWNLOADER = "feapder.network.downloader.RequestsDownloader" # 请求下载器
+SESSION_DOWNLOADER = "feapder.network.downloader.RequestsSessionDownloader"
+RENDER_DOWNLOADER = "feapder.network.downloader.SeleniumDownloader" # 渲染下载器
+```
+
+- session下载器当配置中`USE_SESSION = True`时会启用
+- 渲染下载器当使用浏览器下载功能时会启用
+
+这些下载器均为插件的形式,我们可以自定义
+
+## 自定义普通下载器
+
+1. 编写下载器。如在 `xxx-spider/downloader/my_downloader.py `下自定义了如下下载器
+
+ ```
+ import requests
+
+ from feapder.network.downloader.base import Downloader
+ from feapder.network.response import Response
+
+ class RequestsDownloader(Downloader):
+ def download(self, request) -> Response:
+ response = requests.request(
+ request.method, request.url, **request.requests_kwargs
+ )
+ # 将requests的response转化为feapder的Response 对象,方便后续解析时使用xpath、re等方法
+ response = Response(response)
+ return response
+ ```
+
+ 注:这里返回的response对象不强制要求为是feapder的Response。返回值会传到解析函数的response参数里,若返回的是文本,则接收到的也是文本。
+
+ 但为了代码可读性,建议将返回值转为feapder的Response后再返回。
+
+ 转feapder的Response的方式有如下几种
+
+ ```
+ # 方式1
+ # response参数为reqeusts的response
+ Response(response)
+
+ # 方式2
+ Response.from_text(text="html内容")
+ ```
+
+2. 在settings中指定下载器
+
+ ```
+ DOWNLOADER = "downloader.my_downloader.RequestsDownloader"
+ ```
+
+## 自定义session下载器
+
+1. 和普通下载器一样,都是继承`Downloader`,如何保持session,可自定义。代码示例 `xxx-spider/downloader/my_downloader.py `
+
+ ```
+ class RequestsSessionDownloader(Downloader):
+ session = None
+
+ @property
+ def _session(self):
+ if not self.__class__.session:
+ self.__class__.session = requests.Session()
+ # pool_connections – 缓存的 urllib3 连接池个数 pool_maxsize – 连接池中保存的最大连接数
+ http_adapter = HTTPAdapter(pool_connections=1000, pool_maxsize=1000)
+ # 任何使用该session会话的 HTTP 请求,只要其 URL 是以给定的前缀开头,该传输适配器就会被使用到。
+ self.__class__.session.mount("http", http_adapter)
+
+ return self.__class__.session
+
+ def download(self, request) -> Response:
+ response = self._session.request(
+ request.method, request.url, **request.requests_kwargs
+ )
+ response = Response(response)
+ return response
+ ```
+
+2. 在settings中指定下载器
+
+ ```
+ SESSION_DOWNLOADER = "downloader.my_downloader.RequestsSessionDownloader"
+ ```
+
+注意,这里要配置 `SESSION_DOWNLOADER`
+
+## 自定义浏览器渲染下载器
+
+1. 编写下载器 `xxx-spider/downloader/my_downloader.py `
+
+**若浏览器框架本身不支持多线程,但想在多线程中使用,如playwright使用,参考如下:**
+
+```
+import feapder.setting as setting
+import feapder.utils.tools as tools
+from feapder.network.downloader.base import RenderDownloader
+from feapder.network.response import Response
+from feapder.utils.webdriver import WebDriverPool, PlaywrightDriver
+
+
+class MyDownloader(RenderDownloader):
+ webdriver_pool: WebDriverPool = None
+
+ @property
+ def _webdriver_pool(self):
+ if not self.__class__.webdriver_pool:
+ self.__class__.webdriver_pool = WebDriverPool(
+ **setting.PLAYWRIGHT, driver_cls=PlaywrightDriver, thread_safe=True
+ )
+
+ return self.__class__.webdriver_pool
+
+ def download(self, request) -> Response:
+ # 代理优先级 自定义 > 配置文件 > 随机
+ if request.custom_proxies:
+ proxy = request.get_proxy()
+ elif setting.PLAYWRIGHT.get("proxy"):
+ proxy = setting.PLAYWRIGHT.get("proxy")
+ else:
+ proxy = request.get_proxy()
+
+ # user_agent优先级 自定义 > 配置文件 > 随机
+ if request.custom_ua:
+ user_agent = request.get_user_agent()
+ elif setting.PLAYWRIGHT.get("user_agent"):
+ user_agent = setting.PLAYWRIGHT.get("user_agent")
+ else:
+ user_agent = request.get_user_agent()
+
+ cookies = request.get_cookies()
+ url = request.url
+ render_time = request.render_time or setting.PLAYWRIGHT.get("render_time")
+ wait_until = setting.PLAYWRIGHT.get("wait_until") or "domcontentloaded"
+ if request.get_params():
+ url = tools.joint_url(url, request.get_params())
+
+ driver: PlaywrightDriver = self._webdriver_pool.get(
+ user_agent=user_agent, proxy=proxy
+ )
+ try:
+ if cookies:
+ driver.url = url
+ driver.cookies = cookies
+ driver.page.goto(url, wait_until=wait_until)
+
+ if render_time:
+ tools.delay_time(render_time)
+
+ html = driver.page.content()
+ response = Response.from_dict(
+ {
+ "url": driver.page.url,
+ "cookies": driver.cookies,
+ "_content": html.encode(),
+ "status_code": 200,
+ "elapsed": 666,
+ "headers": {
+ "User-Agent": driver.user_agent,
+ "Cookie": tools.cookies2str(driver.cookies),
+ },
+ }
+ )
+
+ response.driver = driver
+ response.browser = driver
+ return response
+ except Exception as e:
+ self._webdriver_pool.remove(driver)
+ raise e
+
+ def close(self, driver):
+ if driver:
+ self._webdriver_pool.remove(driver)
+
+ def put_back(self, driver):
+ """
+ 释放浏览器对象
+ """
+ self._webdriver_pool.put(driver)
+
+ def close_all(self):
+ """
+ 关闭所有浏览器
+ """
+ # 不支持
+ # self._webdriver_pool.close()
+ pass
+```
+
+这里使用了WebDriverPool,参数`thread_safe=True`,即要保证使用时的线程安全,确保同个浏览器对象只能被同一个线程调用
+
+**若浏览器框架本身支持多线程,如selenium,则参考如下**
+
+```
+import feapder.setting as setting
+import feapder.utils.tools as tools
+from feapder.network.downloader.base import RenderDownloader
+from feapder.network.response import Response
+from feapder.utils.webdriver import WebDriverPool, SeleniumDriver
+
+
+class MyDownloader(RenderDownloader):
+ webdriver_pool: WebDriverPool = None
+
+ @property
+ def _webdriver_pool(self):
+ if not self.__class__.webdriver_pool:
+ self.__class__.webdriver_pool = WebDriverPool(
+ **setting.WEBDRIVER, driver=SeleniumDriver
+ )
+
+ return self.__class__.webdriver_pool
+
+ def download(self, request) -> Response:
+ # 代理优先级 自定义 > 配置文件 > 随机
+ if request.custom_proxies:
+ proxy = request.get_proxy()
+ elif setting.WEBDRIVER.get("proxy"):
+ proxy = setting.WEBDRIVER.get("proxy")
+ else:
+ proxy = request.get_proxy()
+
+ # user_agent优先级 自定义 > 配置文件 > 随机
+ if request.custom_ua:
+ user_agent = request.get_user_agent()
+ elif setting.WEBDRIVER.get("user_agent"):
+ user_agent = setting.WEBDRIVER.get("user_agent")
+ else:
+ user_agent = request.get_user_agent()
+
+ cookies = request.get_cookies()
+ url = request.url
+ render_time = request.render_time or setting.WEBDRIVER.get("render_time")
+ if request.get_params():
+ url = tools.joint_url(url, request.get_params())
+
+ browser: SeleniumDriver = self._webdriver_pool.get(
+ user_agent=user_agent, proxy=proxy
+ )
+ try:
+ browser.get(url)
+ if cookies:
+ browser.cookies = cookies
+ # 刷新使cookie生效
+ browser.get(url)
+
+ if render_time:
+ tools.delay_time(render_time)
+
+ html = browser.page_source
+ response = Response.from_dict(
+ {
+ "url": browser.current_url,
+ "cookies": browser.cookies,
+ "_content": html.encode(),
+ "status_code": 200,
+ "elapsed": 666,
+ "headers": {
+ "User-Agent": browser.user_agent,
+ "Cookie": tools.cookies2str(browser.cookies),
+ },
+ }
+ )
+
+ response.driver = browser
+ response.browser = browser
+ return response
+ except Exception as e:
+ self._webdriver_pool.remove(browser)
+ raise e
+
+ def close(self, driver):
+ if driver:
+ self._webdriver_pool.remove(driver)
+
+ def put_back(self, driver):
+ """
+ 释放浏览器对象
+ """
+ self._webdriver_pool.put(driver)
+
+ def close_all(self):
+ """
+ 关闭所有浏览器
+ """
+ self._webdriver_pool.close()
+```
+
+2. 在settings中指定下载器
+
+```
+RENDER_DOWNLOADER = "downloader.my_downloader.MyDownloader"
+```
+
+注,这里要写`RENDER_DOWNLOADER`
\ No newline at end of file
diff --git a/docs/source_code/pipeline.md b/docs/source_code/pipeline.md
index 14dd7455..6a04dbf1 100644
--- a/docs/source_code/pipeline.md
+++ b/docs/source_code/pipeline.md
@@ -2,11 +2,26 @@
Pipeline是数据入库时流经的管道,用户可自定义,以便对接其他数据库。
-框架已内置mysql及mongo管道,其他管道作为扩展方式提供,可从[feapder_pipelines](https://github.com/Boris-code/feapder_pipelines)项目中按需安装
+框架已内置mysql、mongo、csv管道,其他管道作为扩展方式提供,可从[feapder_pipelines](https://github.com/Boris-code/feapder_pipelines)项目中按需安装
项目地址:https://github.com/Boris-code/feapder_pipelines
-## 使用方式
+## 选择内置的pipeline
+
+在配置文件 `setting.py` 中的 `ITEM_PIPELINES` 中启用:
+
+```python
+ITEM_PIPELINES = [
+ "feapder.pipelines.mysql_pipeline.MysqlPipeline",
+ # "feapder.pipelines.mongo_pipeline.MongoPipeline",
+ # "feapder.pipelines.csv_pipeline.CsvPipeline",
+ # "feapder.pipelines.console_pipeline.ConsolePipeline",
+]
+```
+
+然后 爬虫中`yield`的`item`会流经选择的pipeline自动存储
+
+## 自定义pipeline
注:item会被聚合成多条一起流经pipeline,方便批量入库
diff --git a/docs/source_code/proxy.md b/docs/source_code/proxy.md
index b961ecf0..de87845a 100644
--- a/docs/source_code/proxy.md
+++ b/docs/source_code/proxy.md
@@ -1,12 +1,13 @@
# 代理使用说明
-代理使用有两种方式
-1. 用框架内置的代理池
-2. 自己写
+代理使用有三种方式
+1. 使用框架内置代理池
+2. 自定义代理池
+3. 请求中直接指定
-## 1. 框架内置的代理池
+## 方式1. 使用框架内置代理池
-### 基本使用
+### 配置代理
在配置文件中配置代理提取接口
@@ -14,9 +15,10 @@
# 设置代理
PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n
PROXY_ENABLE = True
+PROXY_MAX_FAILED_TIMES = 5 # 代理最大失败次数,超过则不使用,自动删除
```
-要求API返回的代理格式为:
+要求API返回的代理格式为使用 /r/n 分隔:
```
ip:port
@@ -26,13 +28,11 @@ ip:port
这样feapder在请求时会自动随机使用上面的代理请求了
-### 高阶
+## 管理代理
-> 注意:高阶用法现在不太友好,后期会调整使用方式
+1. 删除代理(默认是请求异常连续5次,再删除代理)
-1. 标记代理失效或延时使用
-
- 例如在发生异常时处理代理
+ 例如在发生异常时删除代理
```python
import feapder
@@ -44,49 +44,48 @@ ip:port
print(response)
def exception_request(self, request, response):
-
- # request.proxies_pool.tag_proxy(request.requests_kwargs.get("proxies"), -1) # 废弃本次代理
- request.proxies_pool.tag_proxy(request.requests_kwargs.get("proxies"), 1, 30) # 延迟本次代理30秒后再使用
- ```
-
-1. 指定代理拉取时间间隔等
-
- 在代码头部给feapder.Request.proxies_pool重新赋值
-
- ```python
- import feapder
- from feapder.network.proxy_pool import ProxyPool
-
- proxy_pool= ProxyPool(reset_interval_max=180, reset_interval=5)
- feapder.Request.proxies_pool = proxy_pool
+ request.del_proxy()
+
```
- 相当于修改了代理池的默认参数值,更多参数看源码
+## 方式2. 自定义代理池
-1. 从redis里提取代理
+1. 编写代理池:例如在你的项目下创建个my_proxypool.py,实现下面的函数
```python
- import feapder
- from feapder.network.proxy_pool import ProxyPool
-
- proxy_pool = ProxyPool(
- proxy_source_url="redis://:passwd@host:ip/db", redis_proxies_key="proxies"
- )
- feapder.Request.proxies_pool = proxy_pool
+ from feapder.network.proxy_pool import BaseProxyPool
+
+ class MyProxyPool(BaseProxyPool):
+ def get_proxy(self):
+ """
+ 获取代理
+ Returns:
+ {"http": "xxx", "https": "xxx"}
+ """
+ pass
+
+ def del_proxy(self, proxy):
+ """
+ @summary: 删除代理
+ ---------
+ @param proxy: xxx
+ """
+ pass
```
-
- 要求redis使用zset集合存储代理,存储内容示例如下:
+
+3. 修改setting的代理配置
+
```
- ip:port
- ip:port
- ip:port
+ PROXY_POOL = "my_proxypool.MyProxyPool" # 代理池
```
- redis_proxies_key及为存储代理的key,每次拉取时会拉取全量
+ 将编写好的代理池配置进来,值为类的模块路径,需要指定到具体的类名
+
+
-## 2. 自己写
+## 方式3. 不使用代理池,直接给请求指定代理
-自己写就比较灵活,自己随机取个代理,然后给request赋值即可,例如在下载中间件里使用
+直接给request.proxies赋值即可,例如在下载中间件里使用
```python
import feapder
@@ -96,7 +95,7 @@ class TestProxy(feapder.AirSpider):
yield feapder.Request("https://www.baidu.com")
def download_midware(self, request):
- # 这里随机取个代理使用即可
+ # 这里使用代理使用即可
request.proxies = {"https": "https://ip:port", "http": "http://ip:port"}
return request
diff --git "a/docs/source_code/\346\212\245\350\255\246\345\217\212\347\233\221\346\216\247.md" "b/docs/source_code/\346\212\245\350\255\246\345\217\212\347\233\221\346\216\247.md"
index 023bd06f..87dbc695 100644
--- "a/docs/source_code/\346\212\245\350\255\246\345\217\212\347\233\221\346\216\247.md"
+++ "b/docs/source_code/\346\212\245\350\255\246\345\217\212\347\233\221\346\216\247.md"
@@ -1,5 +1,7 @@
# 报警及监控
+支持钉钉、飞书、企业微信、邮件报警
+
## 钉钉报警
条件:需要有钉钉群,需要获取钉钉机器人的Webhook地址
@@ -10,15 +12,19 @@
+或使用加签方式,然后在setting中设置密钥
+
相关配置:
```python
# 钉钉报警
DINGDING_WARNING_URL = "" # 钉钉机器人api
DINGDING_WARNING_PHONE = "" # 报警人 支持列表,可指定多个
+DINGDING_WARNING_ALL = False # 是否提示所有人, 默认为False
+DINGDING_WARNING_SECRET = None # 加签密钥
```
-## 微信报警
+## 企业微信报警
条件:需要企业微信群,并获取企业微信机器人的Webhook地址
@@ -39,6 +45,17 @@ WECHAT_WARNING_PHONE = "" # 报警人 将会在群内@此人, 支持列表,
WECHAT_WARNING_ALL = False # 是否提示所有人, 默认为False
```
+## 飞书报警
+
+可参考文档设置机器人:https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN#e1cdee9f
+
+然后在feapder的setting文件中修改如下配置
+
+```
+FEISHU_WARNING_URL = "" # 飞书机器人api
+FEISHU_WARNING_USER = None # 报警人 {"open_id":"ou_xxxxx", "name":"xxxx"} 或 [{"open_id":"ou_xxxxx", "name":"xxxx"}]
+FEISHU_WARNING_ALL = False # 是否提示所有人, 默认为False
+```
## 邮件报警
@@ -69,6 +86,20 @@ EMAIL_RECEIVER = "" # 收件人 支持列表,可指定多个
4. 将本邮箱账号添加到白名单中
+## Qmsg酱报警
+
+Qmsg酱是一个QQ消息推送机器人,用来通知自己消息的免费服务。
+
+可以参考文档:https://qmsg.zendee.cn/docs/api/
+
+```python
+# QMSG报警
+QMSG_WARNING_URL = "" # qmsg机器人api
+QMSG_WARNING_QQ = "" # 指定要接收消息的QQ号或者QQ群。多个以英文逗号分割,例如:12345,12346,支持列表,可指定多人
+QMSG_WARNING_BOT = "" # 机器人的QQ号
+```
+
+
## 报警间隔及报警级别
框架会对相同的报警进行过滤,防止刷屏,默认的报警时间间隔为1小时,可通过以下配置修改:
diff --git "a/docs/source_code/\346\265\217\350\247\210\345\231\250\346\270\262\346\237\223-Playwright.md" "b/docs/source_code/\346\265\217\350\247\210\345\231\250\346\270\262\346\237\223-Playwright.md"
new file mode 100644
index 00000000..8483b126
--- /dev/null
+++ "b/docs/source_code/\346\265\217\350\247\210\345\231\250\346\270\262\346\237\223-Playwright.md"
@@ -0,0 +1,258 @@
+# 浏览器渲染-Playwright
+
+采集动态页面时(Ajax渲染的页面),常用的有两种方案。一种是找接口拼参数,这种方式比较复杂但效率高,需要一定的爬虫功底;另外一种是采用浏览器渲染的方式,直接获取源码,简单方便
+
+框架支持playwright渲染下载,每个线程持有一个playwright实例
+
+
+## 使用方式:
+
+1. 修改配置文件的渲染下载器:
+
+ ```
+ RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader"
+ ```
+2. 使用
+
+ ```python
+ def start_requests(self):
+ yield feapder.Request("https://news.qq.com/", render=True)
+ ```
+
+在返回的Request中传递`render=True`即可
+
+框架支持`chromium`、`firefox`、`webkit` 三种浏览器渲染,可通过[配置文件](source_code/配置文件)进行配置。相关配置如下:
+
+```python
+PLAYWRIGHT = dict(
+ user_agent=None, # 字符串 或 无参函数,返回值为user_agent
+ proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+ headless=False, # 是否为无头浏览器
+ driver_type="chromium", # chromium、firefox、webkit
+ timeout=30, # 请求超时时间
+ window_size=(1024, 800), # 窗口大小
+ executable_path=None, # 浏览器路径,默认为默认路径
+ download_path=None, # 下载文件的路径
+ render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
+ wait_until="networkidle", # 等待页面加载完成的事件,可选值:"commit", "domcontentloaded", "load", "networkidle"
+ use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+ page_on_event_callback=None, # page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()}
+ storage_state_path=None, # 保存浏览器状态的路径
+ url_regexes=None, # 拦截接口,支持正则,数组类型
+ save_all=False, # 是否保存所有拦截的接口, 配合url_regexes使用,为False时只保存最后一次拦截的接口
+)
+```
+
+ - `feapder.Request` 也支持`render_time`参数, 优先级大于配置文件中的`render_time`
+
+ - 代理使用优先级:`feapder.Request`指定的代理 > 配置文件中的`PROXY_EXTRACT_API` > webdriver配置文件中的`proxy`
+
+ - user_agent使用优先级:`feapder.Request`指定的header里的`User-Agent` > 框架随机的`User-Agent` > webdriver配置文件中的`user_agent`
+
+## 设置User-Agent
+
+> 每次生成一个新的浏览器实例时生效
+
+### 方式1:
+
+通过配置文件的 `user_agent` 参数设置
+
+### 方式2:
+
+通过 `feapder.Request`携带,优先级大于配置文件, 如:
+
+```python
+def download_midware(self, request):
+ request.headers = {
+ "User-Agent": "xxxxxxxx"
+ }
+ return request
+```
+
+## 设置代理
+
+> 每次生成一个新的浏览器实例时生效
+
+### 方式1:
+
+通过配置文件的 `proxy` 参数设置
+
+### 方式2:
+
+通过 `feapder.Request`携带,优先级大于配置文件, 如:
+
+```python
+def download_midware(self, request):
+ request.proxies = {
+ "https": "https://xxx.xxx.xxx.xxx:xxxx"
+ }
+ return request
+```
+
+## 设置Cookie
+
+通过 `feapder.Request`携带,如:
+
+```python
+def download_midware(self, request):
+ request.headers = {
+ "Cookie": "key=value; key2=value2"
+ }
+ return request
+```
+
+或者
+
+```python
+def download_midware(self, request):
+ request.cookies = {
+ "key": "value",
+ "key2": "value2",
+ }
+ return request
+```
+
+或者
+
+```python
+def download_midware(self, request):
+ request.cookies = [
+ {
+ "domain": "xxx",
+ "name": "xxx",
+ "value": "xxx",
+ "expirationDate": "xxx"
+ },
+ ]
+ return request
+```
+
+## 拦截数据示例
+
+> 注意:主函数使用run方法运行,不能使用start
+
+```python
+from playwright.sync_api import Response
+from feapder.utils.webdriver import (
+ PlaywrightDriver,
+ InterceptResponse,
+ InterceptRequest,
+)
+
+import feapder
+
+
+def on_response(response: Response):
+ print(response.url)
+
+
+class TestPlaywright(feapder.AirSpider):
+ __custom_setting__ = dict(
+ RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader",
+ PLAYWRIGHT=dict(
+ user_agent=None, # 字符串 或 无参函数,返回值为user_agent
+ proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+ headless=False, # 是否为无头浏览器
+ driver_type="chromium", # chromium、firefox、webkit
+ timeout=30, # 请求超时时间
+ window_size=(1024, 800), # 窗口大小
+ executable_path=None, # 浏览器路径,默认为默认路径
+ download_path=None, # 下载文件的路径
+ render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
+ wait_until="networkidle", # 等待页面加载完成的事件,可选值:"commit", "domcontentloaded", "load", "networkidle"
+ use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+ # page_on_event_callback=dict(response=on_response), # 监听response事件
+ # page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()}
+ storage_state_path=None, # 保存浏览器状态的路径
+ url_regexes=["wallpaper/list"], # 拦截接口,支持正则,数组类型
+ save_all=True, # 是否保存所有拦截的接口
+ ),
+ )
+
+ def start_requests(self):
+ yield feapder.Request(
+ "http://www.soutushenqi.com/image/search/?searchWord=%E6%A0%91%E5%8F%B6",
+ render=True,
+ )
+
+ def parse(self, reqeust, response):
+ driver: PlaywrightDriver = response.driver
+
+ intercept_response: InterceptResponse = driver.get_response("wallpaper/list")
+ intercept_request: InterceptRequest = intercept_response.request
+
+ req_url = intercept_request.url
+ req_header = intercept_request.headers
+ req_data = intercept_request.data
+ print("请求url", req_url)
+ print("请求header", req_header)
+ print("请求data", req_data)
+
+ data = driver.get_json("wallpaper/list")
+ print("接口返回的数据", data)
+
+ print("------ 测试save_all=True ------- ")
+
+ # 测试save_all=True
+ all_intercept_response: list = driver.get_all_response("wallpaper/list")
+ for intercept_response in all_intercept_response:
+ intercept_request: InterceptRequest = intercept_response.request
+ req_url = intercept_request.url
+ req_header = intercept_request.headers
+ req_data = intercept_request.data
+ print("请求url", req_url)
+ print("请求header", req_header)
+ print("请求data", req_data)
+
+ all_intercept_json = driver.get_all_json("wallpaper/list")
+ for intercept_json in all_intercept_json:
+ print("接口返回的数据", intercept_json)
+
+ # 千万别忘了
+ driver.clear_cache()
+
+
+if __name__ == "__main__":
+ TestPlaywright(thread_count=1).run()
+```
+可通过配置的`page_on_event_callback`参数自定义事件的回调,如设置`on_response`的事件回调,亦可直接使用`url_regexes`设置拦截的接口
+
+## 操作浏览器对象示例
+
+> 注意:主函数使用run方法运行,不能使用start
+
+```python
+import time
+
+from playwright.sync_api import Page
+
+import feapder
+from feapder.utils.webdriver import PlaywrightDriver
+
+
+class TestPlaywright(feapder.AirSpider):
+ __custom_setting__ = dict(
+ RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader",
+ )
+
+ def start_requests(self):
+ yield feapder.Request("https://www.baidu.com", render=True)
+
+ def parse(self, reqeust, response):
+ driver: PlaywrightDriver = response.driver
+ page: Page = driver.page
+
+ page.type("#kw", "feapder")
+ page.click("#su")
+ page.wait_for_load_state("networkidle")
+ time.sleep(1)
+
+ html = page.content()
+ response.text = html # 使response加载最新的页面
+ for data_container in response.xpath("//div[@class='c-container']"):
+ print(data_container.xpath("string(.//h3)").extract_first())
+
+
+if __name__ == "__main__":
+ TestPlaywright(thread_count=1).run()
+```
\ No newline at end of file
diff --git "a/docs/source_code/\346\265\217\350\247\210\345\231\250\346\270\262\346\237\223.md" "b/docs/source_code/\346\265\217\350\247\210\345\231\250\346\270\262\346\237\223-Selenium.md"
similarity index 92%
rename from "docs/source_code/\346\265\217\350\247\210\345\231\250\346\270\262\346\237\223.md"
rename to "docs/source_code/\346\265\217\350\247\210\345\231\250\346\270\262\346\237\223-Selenium.md"
index ac728047..089f9537 100644
--- "a/docs/source_code/\346\265\217\350\247\210\345\231\250\346\270\262\346\237\223.md"
+++ "b/docs/source_code/\346\265\217\350\247\210\345\231\250\346\270\262\346\237\223-Selenium.md"
@@ -1,10 +1,10 @@
-# 浏览器渲染
+# 浏览器渲染-Selenium
采集动态页面时(Ajax渲染的页面),常用的有两种方案。一种是找接口拼参数,这种方式比较复杂但效率高,需要一定的爬虫功底;另外一种是采用浏览器渲染的方式,直接获取源码,简单方便
框架内置一个浏览器渲染池,默认的池子大小为1,请求时重复利用浏览器实例,只有当代理失效请求异常时,才会销毁、创建一个新的浏览器实例
-内置浏览器渲染支持 **CHROME** 、**PHANTOMJS**、**FIREFOX**
+内置浏览器渲染支持 **CHROME**、**EDGE**、**PHANTOMJS**、**FIREFOX**
## 使用方式:
@@ -14,7 +14,7 @@ def start_requests(self):
```
在返回的Request中传递`render=True`即可
-框架支持`CHROME`、`PHANTOMJS`、`FIREFOX` 三种浏览器渲染,可通过[配置文件](source_code/配置文件)进行配置。相关配置如下:
+框架支持`CHROME`、`EDGE`、`PHANTOMJS`、`FIREFOX` 三种浏览器渲染,可通过[配置文件](source_code/配置文件)进行配置。相关配置如下:
```python
# 浏览器渲染
@@ -24,7 +24,7 @@ WEBDRIVER = dict(
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
- driver_type="CHROME", # CHROME 、PHANTOMJS、FIREFOX
+ driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
@@ -73,16 +73,6 @@ def download_midware(self, request):
通过 `feapder.Request`携带,优先级大于配置文件, 如:
-```python
-def download_midware(self, request):
- request.proxies = {
- "http": "http://xxx.xxx.xxx.xxx:xxxx"
- }
- return request
-```
-
-或者
-
```python
def download_midware(self, request):
request.proxies = {
@@ -90,7 +80,7 @@ def download_midware(self, request):
}
return request
```
-
+
## 设置Cookie
通过 `feapder.Request`携带,如:
@@ -114,6 +104,21 @@ def download_midware(self, request):
return request
```
+或者
+
+```python
+def download_midware(self, request):
+ request.cookies = [
+ {
+ "domain": "xxx",
+ "name": "xxx",
+ "value": "xxx",
+ "expirationDate": "xxx"
+ },
+ ]
+ return request
+```
+
## 操作浏览器对象
通过 `response.browser` 获取浏览器对象
@@ -137,10 +142,10 @@ class TestRender(feapder.AirSpider):
browser.find_element_by_id("su").click()
time.sleep(5)
print(browser.page_source)
-
+
# response也是可以正常使用的
# response.xpath("//title")
-
+
# 若有滚动,可通过如下方式更新response,使其加载滚动后的内容
# response.text = browser.page_source
@@ -198,6 +203,7 @@ print("返回内容", xhr_response.content)

代码:
+
```python
import time
@@ -213,7 +219,7 @@ class TestRender(feapder.AirSpider):
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
- driver_type="CHROME", # CHROME、PHANTOMJS、FIREFOX
+ driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
@@ -251,7 +257,7 @@ class TestRender(feapder.AirSpider):
if __name__ == "__main__":
TestRender().start()
-
+
```
## 驱动版本自动适配
diff --git "a/docs/source_code/\351\205\215\347\275\256\346\226\207\344\273\266.md" "b/docs/source_code/\351\205\215\347\275\256\346\226\207\344\273\266.md"
index 6ca1d936..e22be333 100644
--- "a/docs/source_code/\351\205\215\347\275\256\346\226\207\344\273\266.md"
+++ "b/docs/source_code/\351\205\215\347\275\256\346\226\207\344\273\266.md"
@@ -8,103 +8,188 @@

```python
-import os
+# -*- coding: utf-8 -*-
+"""爬虫配置文件"""
+# import os
+# import sys
+#
+# # MYSQL
+# MYSQL_IP = "localhost"
+# MYSQL_PORT = 3306
+# MYSQL_DB = ""
+# MYSQL_USER_NAME = ""
+# MYSQL_USER_PASS = ""
+#
+# # MONGODB
+# MONGO_IP = "localhost"
+# MONGO_PORT = 27017
+# MONGO_DB = ""
+# MONGO_USER_NAME = ""
+# MONGO_USER_PASS = ""
+#
+# # REDIS
+# # ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"]
+# REDISDB_IP_PORTS = "localhost:6379"
+# REDISDB_USER_PASS = ""
+# REDISDB_DB = 0
+# # 适用于redis哨兵模式
+# REDISDB_SERVICE_NAME = ""
+#
+# # 数据入库的pipeline,可自定义,默认MysqlPipeline
+# ITEM_PIPELINES = [
+# "feapder.pipelines.mysql_pipeline.MysqlPipeline",
+# # "feapder.pipelines.mongo_pipeline.MongoPipeline",
+# # "feapder.pipelines.console_pipeline.ConsolePipeline",
+# ]
+# EXPORT_DATA_MAX_FAILED_TIMES = 10 # 导出数据时最大的失败次数,包括保存和更新,超过这个次数报警
+# EXPORT_DATA_MAX_RETRY_TIMES = 10 # 导出数据时最大的重试次数,包括保存和更新,超过这个次数则放弃重试
+#
+# # 爬虫相关
+# # COLLECTOR
+# COLLECTOR_TASK_COUNT = 32 # 每次获取任务数量,追求速度推荐32
+#
+# # SPIDER
+# SPIDER_THREAD_COUNT = 1 # 爬虫并发数,追求速度推荐32
+# # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
+# SPIDER_SLEEP_TIME = 0
+# SPIDER_MAX_RETRY_TIMES = 10 # 每个请求最大重试次数
+# KEEP_ALIVE = False # 爬虫是否常驻
+
+# 下载
+# DOWNLOADER = "feapder.network.downloader.RequestsDownloader"
+# SESSION_DOWNLOADER = "feapder.network.downloader.RequestsSessionDownloader"
+# RENDER_DOWNLOADER = "feapder.network.downloader.SeleniumDownloader"
+# # RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader",
+# MAKE_ABSOLUTE_LINKS = True # 自动转成绝对连接
+
+# # 浏览器渲染
+# WEBDRIVER = dict(
+# pool_size=1, # 浏览器的数量
+# load_images=True, # 是否加载图片
+# user_agent=None, # 字符串 或 无参函数,返回值为user_agent
+# proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+# headless=False, # 是否为无头浏览器
+# driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
+# timeout=30, # 请求超时时间
+# window_size=(1024, 800), # 窗口大小
+# executable_path=None, # 浏览器路径,默认为默认路径
+# render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
+# custom_argument=[
+# "--ignore-certificate-errors",
+# "--disable-blink-features=AutomationControlled",
+# ], # 自定义浏览器渲染参数
+# xhr_url_regexes=None, # 拦截xhr接口,支持正则,数组类型
+# auto_install_driver=True, # 自动下载浏览器驱动 支持chrome 和 firefox
+# download_path=None, # 下载文件的路径
+# use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+# )
+#
+# PLAYWRIGHT = dict(
+# user_agent=None, # 字符串 或 无参函数,返回值为user_agent
+# proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+# headless=False, # 是否为无头浏览器
+# driver_type="chromium", # chromium、firefox、webkit
+# timeout=30, # 请求超时时间
+# window_size=(1024, 800), # 窗口大小
+# executable_path=None, # 浏览器路径,默认为默认路径
+# download_path=None, # 下载文件的路径
+# render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
+# wait_until="networkidle", # 等待页面加载完成的事件,可选值:"commit", "domcontentloaded", "load", "networkidle"
+# use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+# page_on_event_callback=None, # page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()}
+# storage_state_path=None, # 保存浏览器状态的路径
+# url_regexes=None, # 拦截接口,支持正则,数组类型
+# save_all=False, # 是否保存所有拦截的接口, 配合url_regexes使用,为False时只保存最后一次拦截的接口
+# )
+#
+# # 爬虫启动时,重新抓取失败的requests
+# RETRY_FAILED_REQUESTS = False
+# # 保存失败的request
+# SAVE_FAILED_REQUEST = True
+# # request防丢机制。(指定的REQUEST_LOST_TIMEOUT时间内request还没做完,会重新下发 重做)
+# REQUEST_LOST_TIMEOUT = 600 # 10分钟
+# # request网络请求超时时间
+# REQUEST_TIMEOUT = 22 # 等待服务器响应的超时时间,浮点数,或(connect timeout, read timeout)元组
+# # item在内存队列中最大缓存数量
+# ITEM_MAX_CACHED_COUNT = 5000
+# # item每批入库的最大数量
+# ITEM_UPLOAD_BATCH_MAX_SIZE = 1000
+# # item入库时间间隔
+# ITEM_UPLOAD_INTERVAL = 1
+# # 内存任务队列最大缓存的任务数,默认不限制;仅对AirSpider有效。
+# TASK_MAX_CACHED_SIZE = 0
+#
+# # 下载缓存 利用redis缓存,但由于内存大小限制,所以建议仅供开发调试代码时使用,防止每次debug都需要网络请求
+# RESPONSE_CACHED_ENABLE = False # 是否启用下载缓存 成本高的数据或容易变需求的数据,建议设置为True
+# RESPONSE_CACHED_EXPIRE_TIME = 3600 # 缓存时间 秒
+# RESPONSE_CACHED_USED = False # 是否使用缓存 补采数据时可设置为True
+#
+# # 设置代理
+# PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n
+# PROXY_ENABLE = True
+#
+# # 随机headers
+# RANDOM_HEADERS = True
+# # UserAgent类型 支持 'chrome', 'opera', 'firefox', 'internetexplorer', 'safari','mobile' 若不指定则随机类型
+# USER_AGENT_TYPE = "chrome"
+# # 默认使用的浏览器头
+# DEFAULT_USERAGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
+# # requests 使用session
+# USE_SESSION = False
+#
+# # 去重
+# ITEM_FILTER_ENABLE = False # item 去重
+# REQUEST_FILTER_ENABLE = False # request 去重
+# ITEM_FILTER_SETTING = dict(
+# filter_type=1 # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4
+# )
+# REQUEST_FILTER_SETTING = dict(
+# filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4
+# expire_time=2592000, # 过期时间1个月
+# )
+#
+# # 报警 支持钉钉、飞书、企业微信、邮件
+# # 钉钉报警
+# DINGDING_WARNING_URL = "" # 钉钉机器人api
+# DINGDING_WARNING_PHONE = "" # 报警人 支持列表,可指定多个
+# DINGDING_WARNING_ALL = False # 是否提示所有人, 默认为False
+# # 飞书报警
+# # https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN#e1cdee9f
+# FEISHU_WARNING_URL = "" # 飞书机器人api
+# FEISHU_WARNING_USER = None # 报警人 {"open_id":"ou_xxxxx", "name":"xxxx"} 或 [{"open_id":"ou_xxxxx", "name":"xxxx"}]
+# FEISHU_WARNING_ALL = False # 是否提示所有人, 默认为False
+# # 邮件报警
+# EMAIL_SENDER = "" # 发件人
+# EMAIL_PASSWORD = "" # 授权码
+# EMAIL_RECEIVER = "" # 收件人 支持列表,可指定多个
+# EMAIL_SMTPSERVER = "smtp.163.com" # 邮件服务器 默认为163邮箱
+# # 企业微信报警
+# WECHAT_WARNING_URL = "" # 企业微信机器人api
+# WECHAT_WARNING_PHONE = "" # 报警人 将会在群内@此人, 支持列表,可指定多人
+# WECHAT_WARNING_ALL = False # 是否提示所有人, 默认为False
+# # 时间间隔
+# WARNING_INTERVAL = 3600 # 相同报警的报警时间间隔,防止刷屏; 0表示不去重
+# WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / INFO / ERROR
+# WARNING_FAILED_COUNT = 1000 # 任务失败数 超过WARNING_FAILED_COUNT则报警
+#
+# LOG_NAME = os.path.basename(os.getcwd())
+# LOG_PATH = "log/%s.log" % LOG_NAME # log存储路径
+# LOG_LEVEL = "DEBUG"
+# LOG_COLOR = True # 是否带有颜色
+# LOG_IS_WRITE_TO_CONSOLE = True # 是否打印到控制台
+# LOG_IS_WRITE_TO_FILE = False # 是否写文件
+# LOG_MODE = "w" # 写文件的模式
+# LOG_MAX_BYTES = 10 * 1024 * 1024 # 每个日志文件的最大字节数
+# LOG_BACKUP_COUNT = 20 # 日志文件保留数量
+# LOG_ENCODING = "utf8" # 日志文件编码
+# OTHERS_LOG_LEVAL = "ERROR" # 第三方库的log等级
+#
+# # 切换工作路径为当前项目路径
+# project_path = os.path.abspath(os.path.dirname(__file__))
+# os.chdir(project_path) # 切换工作路经
+# sys.path.insert(0, project_path)
+# print("当前工作路径为 " + os.getcwd())
-
-# MYSQL
-MYSQL_IP = ""
-MYSQL_PORT = 3306
-MYSQL_DB = ""
-MYSQL_USER_NAME = ""
-MYSQL_USER_PASS = ""
-
-# REDIS
-# IP:PORT
-REDISDB_IP_PORTS = "xxx:6379"
-REDISDB_USER_PASS = ""
-# 默认 0 到 15 共16个数据库
-REDISDB_DB = 0
-
-# 数据入库的pipeline,可自定义,默认MysqlPipeline
-ITEM_PIPELINES = ["feapder.pipelines.mysql_pipeline.MysqlPipeline"]
-
-# 爬虫相关
-# COLLECTOR
-COLLECTOR_SLEEP_TIME = 1 # 从任务队列中获取任务到内存队列的间隔
-COLLECTOR_TASK_COUNT = 100 # 每次获取任务数量
-
-# SPIDER
-SPIDER_THREAD_COUNT = 10 # 爬虫并发数
-SPIDER_SLEEP_TIME = 0 # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
-SPIDER_MAX_RETRY_TIMES = 100 # 每个请求最大重试次数
-
-# 浏览器渲染下载
-WEBDRIVER = dict(
- pool_size=2, # 浏览器的数量
- load_images=False, # 是否加载图片
- user_agent=None, # 字符串 或 无参函数,返回值为user_agent
- proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
- headless=False, # 是否为无头浏览器
- driver_type="CHROME", # CHROME 或 PHANTOMJS,
- timeout=30, # 请求超时时间
- window_size=(1024, 800), # 窗口大小
- executable_path=None, # 浏览器路径,默认为默认路径
- render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
-)
-
-# 重新尝试失败的requests 当requests重试次数超过允许的最大重试次数算失败
-RETRY_FAILED_REQUESTS = False
-# request 超时时间,超过这个时间重新做(不是网络请求的超时时间)单位秒
-REQUEST_LOST_TIMEOUT = 600 # 10分钟
-# 保存失败的request
-SAVE_FAILED_REQUEST = True
-
-# 下载缓存 利用redis缓存,由于内存小,所以仅供测试时使用
-RESPONSE_CACHED_ENABLE = False # 是否启用下载缓存 成本高的数据或容易变需求的数据,建议设置为True
-RESPONSE_CACHED_EXPIRE_TIME = 3600 # 缓存时间 秒
-RESPONSE_CACHED_USED = False # 是否使用缓存 补采数据时可设置为True
-
-WARNING_FAILED_COUNT = 1000 # 任务失败数 超过WARNING_FAILED_COUNT则报警
-
-# 爬虫是否常驻
-KEEP_ALIVE = False
-
-# 设置代理
-PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n
-PROXY_ENABLE = True
-
-# 随机headers
-RANDOM_HEADERS = True
-# requests 使用session
-USE_SESSION = False
-
-# 去重
-ITEM_FILTER_ENABLE = False # item 去重
-REQUEST_FILTER_ENABLE = False # request 去重
-
-# 报警 支持钉钉及邮件,二选一即可
-# 钉钉报警
-DINGDING_WARNING_URL = "" # 钉钉机器人api
-DINGDING_WARNING_PHONE = "" # 报警人 支持列表,可指定多个
-# 邮件报警
-EMAIL_SENDER = "" # 发件人
-EMAIL_PASSWORD = "" # 授权码
-EMAIL_RECEIVER = "" # 收件人 支持列表,可指定多个
-# 时间间隔
-WARNING_INTERVAL = 3600 # 相同报警的报警时间间隔,防止刷屏; 0表示不去重
-WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / ERROR
-
-LOG_NAME = os.path.basename(os.getcwd())
-LOG_PATH = "log/%s.log" % LOG_NAME # log存储路径
-LOG_LEVEL = "DEBUG"
-LOG_COLOR = True # 是否带有颜色
-LOG_IS_WRITE_TO_CONSOLE = True # 是否打印到控制台
-LOG_IS_WRITE_TO_FILE = False # 是否写文件
-LOG_MODE = "w" # 写文件的模式
-LOG_MAX_BYTES = 10 * 1024 * 1024 # 每个日志文件的最大字节数
-LOG_BACKUP_COUNT = 20 # 日志文件保留数量
-LOG_ENCODING = "utf8" # 日志文件编码
-OTHERS_LOG_LEVAL = "ERROR" # 第三方库的log等级
```
- 数据库连接信息默认读取的环境变量,因此若不想将自己的账号暴露给其他同事,建议写在环境变量里,环境变量的`key`与配置文件的`key`相同
@@ -117,10 +202,10 @@ OTHERS_LOG_LEVAL = "ERROR" # 第三方库的log等级
```python
import feapder
-
-
+
+
class SpiderTest(feapder.AirSpider):
__custom_setting__ = dict(
SPIDER_MAX_RETRY_TIMES=20,
)
-```
\ No newline at end of file
+```
diff --git a/docs/usage/AirSpider.md b/docs/usage/AirSpider.md
index f645fe67..71ac053c 100644
--- a/docs/usage/AirSpider.md
+++ b/docs/usage/AirSpider.md
@@ -8,7 +8,15 @@ AirSpider是一款轻量爬虫,学习成本低。面对一些数据量较少
示例
- feapder create -s air_spider_test
+```python
+feapder create -s air_spider_test
+
+请选择爬虫模板
+> AirSpider
+ Spider
+ TaskSpider
+ BatchSpider
+```
生成如下
@@ -235,7 +243,7 @@ def start_requests(self):
```
在返回的Request中传递`render=True`即可
-框架支持`CHROME`和`PHANTOMJS`两种浏览器渲染,可通过[配置文件](source_code/配置文件)进行配置。相关配置如下:
+框架支持`CHROME`、`EDGE`和`PHANTOMJS`浏览器渲染,可通过[配置文件](source_code/配置文件)进行配置。相关配置如下:
```python
# 浏览器渲染
@@ -245,7 +253,7 @@ WEBDRIVER = dict(
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
- driver_type="CHROME", # CHROME 或 PHANTOMJS,
+ driver_type="CHROME", # CHROME、EDGE或PHANTOMJS,
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
@@ -274,7 +282,7 @@ class AirSpeedTest(feapder.AirSpider):
return request, response
def parse(self, request, response):
- print(response)
+ print(response)
if __name__ == "__main__":
@@ -306,7 +314,25 @@ class AirSpeedTest(feapder.AirSpider):
print(title)
```
-## 15. 完整的代码示例
+## 15. 主动停止爬虫
+
+```
+import feapder
+
+
+class AirTest(feapder.AirSpider):
+ def start_requests(self):
+ yield feapder.Request("http://www.baidu.com")
+
+ def parse(self, request, response):
+ self.stop_spider() # 停止爬虫,可以在任意地方调用该方法
+
+
+if __name__ == "__main__":
+ AirTest().start()
+```
+
+## 16. 完整的代码示例
AirSpider:https://github.com/Boris-code/feapder/blob/master/tests/air-spider/test_air_spider.py
diff --git a/docs/usage/BatchSpider.md b/docs/usage/BatchSpider.md
index dcf34d0b..d85bbce9 100644
--- a/docs/usage/BatchSpider.md
+++ b/docs/usage/BatchSpider.md
@@ -12,7 +12,15 @@ BatchSpider是一款分布式批次爬虫,对于需要周期性采集的数据
示例:
- feapder create -s batch_spider_test 3
+```python
+feapder create -s batch_spider_test
+
+请选择爬虫模板
+ AirSpider
+ Spider
+ TaskSpider
+> BatchSpider
+```
生成如下
@@ -42,7 +50,7 @@ class BatchSpiderTest(feapder.BatchSpider):
if __name__ == "__main__":
spider = BatchSpiderTest(
- redis_key="xxx:xxxx", # redis中存放任务等信息的根key
+ redis_key="xxx:xxxx", # 分布式爬虫调度信息存储位置
task_table="", # mysql中的任务表
task_keys=["id", "xxx"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
@@ -137,7 +145,7 @@ def start_requests(self, task):
```
def crawl_test(args):
spider = test_spider.TestSpider(
- redis_key="feapder:test_batch_spider", # redis中存放任务等信息的根key
+ redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置
task_table="batch_spider_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
@@ -251,7 +259,7 @@ def failed_request(self, request, response):
def test_debug():
spider = test_spider.TestSpider.to_DebugBatchSpider(
task_id=1,
- redis_key="feapder:test_batch_spider", # redis中存放任务等信息的根key
+ redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置
task_table="batch_spider_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
@@ -282,7 +290,7 @@ from feapder import ArgumentParser
def crawl_test(args):
spider = test_spider.TestSpider(
- redis_key="feapder:test_batch_spider", # redis中存放任务等信息的根key
+ redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置
task_table="batch_spider_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
diff --git a/docs/usage/Spider.md b/docs/usage/Spider.md
index 6a53b571..47736c21 100644
--- a/docs/usage/Spider.md
+++ b/docs/usage/Spider.md
@@ -25,7 +25,15 @@ Spider是一款基于redis的分布式爬虫,适用于海量数据采集,支
示例:
- feapder create -s spider_test 2
+```python
+feapder create -s spider_test
+
+请选择爬虫模板
+ AirSpider
+> Spider
+ TaskSpider
+ BatchSpider
+```
生成如下
@@ -125,7 +133,7 @@ Item详细介绍参考[Item](source_code/Item.md)
可以看到,代码中 `to_DebugSpider`方法可以将原爬虫直接转为debug爬虫,然后通过传递request参数抓取指定的任务。
-通常结合断点来进行调试,bebug模式下,运行产生的数据默认不入库
+通常结合断点来进行调试,debug模式下,运行产生的数据默认不入库
除了指定request参数外,还可以指定`request_dict`参数,request_dict接收字典类型,如`request_dict={"url":"http://www.baidu.com"}`, 其作用于传递request一致。request 与 request_dict 二者选一传递即可
@@ -192,4 +200,4 @@ if __name__ == "__main__":
## 9. 完整的代码示例
-[https://github.com/Boris-code/feapder/tree/master/tests/spider](https://github.com/Boris-code/feapder/tree/master/tests/spider)
\ No newline at end of file
+[https://github.com/Boris-code/feapder/tree/master/tests/spider](https://github.com/Boris-code/feapder/tree/master/tests/spider)
diff --git a/docs/usage/TaskSpider.md b/docs/usage/TaskSpider.md
new file mode 100644
index 00000000..5978dff9
--- /dev/null
+++ b/docs/usage/TaskSpider.md
@@ -0,0 +1,133 @@
+# TaskSpider
+
+TaskSpider是一款分布式爬虫,内部封装了取种子任务的逻辑,内置支持从redis或者mysql获取任务,也可通过自定义实现从其他来源获取任务
+
+## 1. 创建项目
+
+参考 [Spider](usage/Spider?id=_1-创建项目)
+
+## 2. 创建爬虫
+
+命令参考:[命令行工具](command/cmdline.md?id=_2-创建爬虫)
+
+示例:
+
+```python
+feapder create -s task_spider_test
+
+请选择爬虫模板
+ AirSpider
+ Spider
+> TaskSpider
+ BatchSpider
+```
+
+示例代码:
+
+```python
+import feapder
+from feapder import ArgumentParser
+
+
+class TaskSpiderTest(feapder.TaskSpider):
+ # 自定义数据库,若项目中有setting.py文件,此自定义可删除
+ # redis 必须,mysql可选
+ __custom_setting__ = dict(
+ REDISDB_IP_PORTS="localhost:6379",
+ REDISDB_USER_PASS="",
+ REDISDB_DB=0,
+ MYSQL_IP="localhost",
+ MYSQL_PORT=3306,
+ MYSQL_DB="feapder",
+ MYSQL_USER_NAME="feapder",
+ MYSQL_USER_PASS="feapder123",
+ )
+
+ def add_task(self):
+ # 加种子任务 框架会调用这个函数,方便往redis里塞任务,但不能写成死循环。实际业务中可以自己写个脚本往redis里塞任务
+ self._redisdb.zadd(self._task_table, {"id": 1, "url": "https://www.baidu.com"})
+
+ def start_requests(self, task):
+ task_id, url = task
+ yield feapder.Request(url, task_id=task_id)
+
+ def parse(self, request, response):
+ # 提取网站title
+ print(response.xpath("//title/text()").extract_first())
+ # 提取网站描述
+ print(response.xpath("//meta[@name='description']/@content").extract_first())
+ print("网站地址: ", response.url)
+
+ # mysql 需要更新任务状态为做完 即 state=1
+ # yield self.update_task_batch(request.task_id)
+
+def start(args):
+ """
+ 用mysql做种子表
+ """
+ spider = TaskSpiderTest(
+ task_table="spider_task", # 任务表名
+ task_keys=["id", "url"], # 表里查询的字段
+ redis_key="test:task_spider", # redis里做任务队列的key
+ keep_alive=True, # 是否常驻
+ )
+ if args == 1:
+ spider.start_monitor_task()
+ else:
+ spider.start()
+
+
+def start2(args):
+ """
+ 用redis做种子表
+ """
+ spider = TaskSpiderTest(
+ task_table="spider_task2", # 任务表名
+ task_table_type="redis", # 任务表类型为redis
+ redis_key="test:task_spider", # redis里做任务队列的key
+ keep_alive=True, # 是否常驻
+ use_mysql=False, # 若用不到mysql,可以不使用
+ )
+ if args == 1:
+ spider.start_monitor_task()
+ else:
+ spider.start()
+
+
+if __name__ == "__main__":
+ parser = ArgumentParser(description="测试TaskSpider")
+
+ parser.add_argument("--start", type=int, nargs=1, help="用mysql做种子表 (1|2)", function=start)
+ parser.add_argument("--start2", type=int, nargs=1, help="用redis做种子表 (1|2)", function=start2)
+
+ parser.start()
+
+ # 下发任务 python3 task_spider_test.py --start 1
+ # 采集 python3 task_spider_test.py --start 2
+```
+
+## 3. 代码讲解
+
+#### 3.1 main
+
+main函数为命令行参数解析,分别定义了两种获取任务的方式。start函数为从mysql里获取任务,前提是需要有任务表。start2函数为从redis里获取任务,指定了根任务的key为`spider_task2`,key的类型为zset
+
+启动:TaskSpider分为master及work两种程序
+
+1. master负责下发任务,监控批次进度,创建批次等功能,启动方式:
+
+ spider.start_monitor_task()
+
+2. worker负责消费任务,抓取数据,启动方式:
+
+ spider.start()
+
+#### 3.1 add_task:
+
+框架内置的函数,在调用start_monitor_task时会自动调度此函数,用于初始化任务种子,若不需要,可直接删除此函数
+
+本代码示例为向redis的`spider_task2`的key加了个值为`{"id": 1, "url": "https://www.baidu.com"}`的种子
+
+
+
+
diff --git a/feapder/VERSION b/feapder/VERSION
index 089f78d3..7b0231f5 100644
--- a/feapder/VERSION
+++ b/feapder/VERSION
@@ -1 +1 @@
-1.7.5-beta3
\ No newline at end of file
+1.9.3
\ No newline at end of file
diff --git a/feapder/__init__.py b/feapder/__init__.py
index 0183833f..565be4b9 100644
--- a/feapder/__init__.py
+++ b/feapder/__init__.py
@@ -7,16 +7,19 @@
@author: Boris
@email: boris_liu@foxmail.com
"""
-import os, sys
+import os
import re
+import sys
sys.path.insert(0, re.sub(r"([\\/]items$)|([\\/]spiders$)", "", os.getcwd()))
__all__ = [
"AirSpider",
"Spider",
+ "TaskSpider",
"BatchSpider",
"BaseParser",
+ "TaskParser",
"BatchParser",
"Request",
"Response",
@@ -25,8 +28,8 @@
"ArgumentParser",
]
-from feapder.core.spiders import Spider, BatchSpider, AirSpider
-from feapder.core.base_parser import BaseParser, BatchParser
+from feapder.core.spiders import AirSpider, Spider, TaskSpider, BatchSpider
+from feapder.core.base_parser import BaseParser, TaskParser, BatchParser
from feapder.network.request import Request
from feapder.network.response import Response
from feapder.network.item import Item, UpdateItem
diff --git a/feapder/buffer/item_buffer.py b/feapder/buffer/item_buffer.py
index 6a5eddaf..35f9bb01 100644
--- a/feapder/buffer/item_buffer.py
+++ b/feapder/buffer/item_buffer.py
@@ -8,12 +8,11 @@
@email: boris_liu@foxmail.com
"""
-import importlib
import threading
from queue import Queue
-import feapder.setting as setting
import feapder.utils.tools as tools
+from feapder import setting
from feapder.db.redisdb import RedisDB
from feapder.dedup import Dedup
from feapder.network.item import Item, UpdateItem
@@ -22,9 +21,6 @@
from feapder.utils import metrics
from feapder.utils.log import log
-MAX_ITEM_COUNT = 5000 # 缓存中最大item数
-UPLOAD_BATCH_MAX_SIZE = 1000
-
MYSQL_PIPELINE_PATH = "feapder.pipelines.mysql_pipeline.MysqlPipeline"
@@ -41,9 +37,9 @@ def __init__(self, redis_key, task_table=None):
self._redis_key = redis_key
self._task_table = task_table
- self._items_queue = Queue(maxsize=MAX_ITEM_COUNT)
+ self._items_queue = Queue(maxsize=setting.ITEM_MAX_CACHED_COUNT)
- self._table_request = setting.TAB_REQUSETS.format(redis_key=redis_key)
+ self._table_request = setting.TAB_REQUESTS.format(redis_key=redis_key)
self._table_failed_items = setting.TAB_FAILED_ITEMS.format(
redis_key=redis_key
)
@@ -56,15 +52,28 @@ def __init__(self, redis_key, task_table=None):
# 'table_name': ['id', 'name'...] # 缓存table_name与__update_key__的关系
}
+ self._item_pipelines = {
+ # 'table_name': ['pipeline1', 'pipeline2'] # 缓存table_name与pipelines的关系
+ }
+
self._pipelines = self.load_pipelines()
self._have_mysql_pipeline = MYSQL_PIPELINE_PATH in setting.ITEM_PIPELINES
self._mysql_pipeline = None
if setting.ITEM_FILTER_ENABLE and not self.__class__.dedup:
- self.__class__.dedup = Dedup(
- to_md5=False, **setting.ITEM_FILTER_SETTING
- )
+ if setting.ITEM_FILTER_SETTING.get(
+ "filter_type"
+ ) == Dedup.BloomFilter or setting.ITEM_FILTER_SETTING.get("name"):
+ self.__class__.dedup = Dedup(
+ to_md5=False, **setting.ITEM_FILTER_SETTING
+ )
+ else:
+ self.__class__.dedup = Dedup(
+ to_md5=False,
+ name=self._redis_key,
+ **setting.ITEM_FILTER_SETTING,
+ )
# 导出重试的次数
self.export_retry_times = 0
@@ -81,9 +90,7 @@ def redis_db(self):
def load_pipelines(self):
pipelines = []
for pipeline_path in setting.ITEM_PIPELINES:
- module, class_name = pipeline_path.rsplit(".", 1)
- pipeline_cls = importlib.import_module(module).__getattribute__(class_name)
- pipeline = pipeline_cls()
+ pipeline = tools.import_cls(pipeline_path)()
if not isinstance(pipeline, BasePipeline):
raise ValueError(f"{pipeline_path} 需继承 feapder.pipelines.BasePipeline")
pipelines.append(pipeline)
@@ -93,9 +100,7 @@ def load_pipelines(self):
@property
def mysql_pipeline(self):
if not self._mysql_pipeline:
- module, class_name = MYSQL_PIPELINE_PATH.rsplit(".", 1)
- pipeline_cls = importlib.import_module(module).__getattribute__(class_name)
- self._mysql_pipeline = pipeline_cls()
+ self._mysql_pipeline = tools.import_cls(MYSQL_PIPELINE_PATH)()
return self._mysql_pipeline
@@ -103,7 +108,7 @@ def run(self):
self._thread_stop = False
while not self._thread_stop:
self.flush()
- tools.delay_time(1)
+ tools.delay_time(setting.ITEM_UPLOAD_INTERVAL)
self.close()
@@ -146,7 +151,7 @@ def flush(self):
else: # request-redis
requests.append(data)
- if data_count >= UPLOAD_BATCH_MAX_SIZE:
+ if data_count >= setting.ITEM_UPLOAD_BATCH_MAX_SIZE:
self.__add_item_to_db(
items, update_items, requests, callbacks, items_fingerprints
)
@@ -216,7 +221,7 @@ def __pick_items(self, items, is_update_item=False):
将每个表之间的数据分开 拆分后 原items为空
@param items:
@param is_update_item:
- @return:
+ @return: 表名与数据的字典
"""
datas_dict = {
# 'table_name': [{}, {}]
@@ -231,25 +236,24 @@ def __pick_items(self, items, is_update_item=False):
if not table_name:
table_name = item.table_name
self._item_tables[item_name] = table_name
+ self._item_pipelines[table_name] = item.pipelines
+
+ if is_update_item and table_name not in self._item_update_keys:
+ self._item_update_keys[table_name] = item.update_key
if table_name not in datas_dict:
datas_dict[table_name] = []
datas_dict[table_name].append(item.to_dict)
- if is_update_item and table_name not in self._item_update_keys:
- self._item_update_keys[table_name] = item.update_key
-
return datas_dict
- def __export_to_db(self, table, datas, is_update=False, update_keys=()):
- # 打点 校验
- self.check_datas(table=table, datas=datas)
-
- for pipeline in self._pipelines:
+ def __export_to_db(self, table, datas, is_update=False, update_keys=(), used_pipelines=None):
+ pipelines = used_pipelines or self._pipelines # 优先采用指定的pipelines
+ for pipeline in pipelines:
if is_update:
if table == self._task_table and not isinstance(
- pipeline, MysqlPipeline
+ pipeline, MysqlPipeline
):
continue
@@ -269,17 +273,18 @@ def __export_to_db(self, table, datas, is_update=False, update_keys=()):
# 若是任务表, 且上面的pipeline里没mysql,则需调用mysql更新任务
if not self._have_mysql_pipeline and is_update and table == self._task_table:
if not self.mysql_pipeline.update_items(
- table, datas, update_keys=update_keys
+ table, datas, update_keys=update_keys
):
log.error(
f"{self.mysql_pipeline.__class__.__name__} 更新数据失败. table: {table} items: {datas}"
)
return False
+ self.metric_datas(table=table, datas=datas)
return True
def __add_item_to_db(
- self, items, update_items, requests, callbacks, items_fingerprints
+ self, items, update_items, requests, callbacks, items_fingerprints
):
export_success = True
self._is_adding_to_db = True
@@ -288,7 +293,7 @@ def __add_item_to_db(
if setting.ITEM_FILTER_ENABLE:
items, items_fingerprints = self.__dedup_items(items, items_fingerprints)
- # 分捡
+ # 分捡(返回值包含 pipelines_dict)
items_dict = self.__pick_items(items)
update_items_dict = self.__pick_items(update_items, is_update_item=True)
@@ -296,6 +301,7 @@ def __add_item_to_db(
failed_items = {"add": [], "update": [], "requests": []}
while items_dict:
table, datas = items_dict.popitem()
+ used_pipelines = self._item_pipelines.get(table)
log.debug(
"""
@@ -306,13 +312,14 @@ def __add_item_to_db(
% (table, tools.dumps_json(datas, indent=16))
)
- if not self.__export_to_db(table, datas):
+ if not self.__export_to_db(table, datas, used_pipelines=used_pipelines):
export_success = False
failed_items["add"].append({"table": table, "datas": datas})
# 执行批量update
while update_items_dict:
table, datas = update_items_dict.popitem()
+ used_pipelines = self._item_pipelines.get(table)
log.debug(
"""
@@ -325,10 +332,12 @@ def __add_item_to_db(
update_keys = self._item_update_keys.get(table)
if not self.__export_to_db(
- table, datas, is_update=True, update_keys=update_keys
+ table, datas, is_update=True, update_keys=update_keys, used_pipelines=used_pipelines
):
export_success = False
- failed_items["update"].append({"table": table, "datas": datas})
+ failed_items["update"].append(
+ {"table": table, "datas": datas, "update_keys": update_keys}
+ )
if export_success:
# 执行回调
@@ -405,17 +414,19 @@ def __add_item_to_db(
self._is_adding_to_db = False
- def check_datas(self, table, datas):
+ def metric_datas(self, table, datas):
"""
打点 记录总条数及每个key情况
@param table: 表名
@param datas: 数据 列表
@return:
"""
- metrics.emit_counter("total count", len(datas), classify=table)
+ total_count = 0
for data in datas:
+ total_count += 1
for k, v in data.items():
metrics.emit_counter(k, int(bool(v)), classify=table)
+ metrics.emit_counter("total count", total_count, classify=table)
def close(self):
# 调用pipeline的close方法
diff --git a/feapder/buffer/request_buffer.py b/feapder/buffer/request_buffer.py
index c3a29542..70677a94 100644
--- a/feapder/buffer/request_buffer.py
+++ b/feapder/buffer/request_buffer.py
@@ -13,6 +13,7 @@
import feapder.setting as setting
import feapder.utils.tools as tools
+from feapder.db.memorydb import MemoryDB
from feapder.db.redisdb import RedisDB
from feapder.dedup import Dedup
from feapder.utils.log import log
@@ -20,29 +21,56 @@
MAX_URL_COUNT = 1000 # 缓存中最大request数
-class RequestBuffer(threading.Thread):
+class AirSpiderRequestBuffer:
dedup = None
- def __init__(self, redis_key):
- if not hasattr(self, "_requests_deque"):
- super(RequestBuffer, self).__init__()
+ def __init__(self, db=None, dedup_name: str = None):
+ self._db = db or MemoryDB()
- self._thread_stop = False
- self._is_adding_to_db = False
+ if not self.__class__.dedup and setting.REQUEST_FILTER_ENABLE:
+ if setting.REQUEST_FILTER_SETTING.get(
+ "filter_type"
+ ) == Dedup.BloomFilter or setting.REQUEST_FILTER_SETTING.get("name"):
+ self.__class__.dedup = Dedup(
+ to_md5=False, **setting.REQUEST_FILTER_SETTING
+ )
+ else:
+ self.__class__.dedup = Dedup(
+ to_md5=False, name=dedup_name, **setting.REQUEST_FILTER_SETTING
+ )
+
+ def is_exist_request(self, request):
+ if (
+ request.filter_repeat
+ and setting.REQUEST_FILTER_ENABLE
+ and not self.__class__.dedup.add(request.fingerprint)
+ ):
+ log.debug("request已存在 url = %s" % request.url)
+ return True
+ return False
+
+ def put_request(self, request, ignore_max_size=True):
+ if self.is_exist_request(request):
+ return
+ else:
+ self._db.add(request, ignore_max_size=ignore_max_size)
+
+
+class RequestBuffer(AirSpiderRequestBuffer, threading.Thread):
+ def __init__(self, redis_key):
+ AirSpiderRequestBuffer.__init__(self, db=RedisDB(), dedup_name=redis_key)
+ threading.Thread.__init__(self)
- self._requests_deque = collections.deque()
- self._del_requests_deque = collections.deque()
- self._db = RedisDB()
+ self._thread_stop = False
+ self._is_adding_to_db = False
- self._table_request = setting.TAB_REQUSETS.format(redis_key=redis_key)
- self._table_failed_request = setting.TAB_FAILED_REQUSETS.format(
- redis_key=redis_key
- )
+ self._requests_deque = collections.deque()
+ self._del_requests_deque = collections.deque()
- if not self.__class__.dedup and setting.REQUEST_FILTER_ENABLE:
- self.__class__.dedup = Dedup(
- name=redis_key, to_md5=False, **setting.REQUEST_FILTER_SETTING
- ) # 默认过期时间为一个月
+ self._table_request = setting.TAB_REQUESTS.format(redis_key=redis_key)
+ self._table_failed_request = setting.TAB_FAILED_REQUESTS.format(
+ redis_key=redis_key
+ )
def run(self):
self._thread_stop = False
@@ -109,12 +137,7 @@ def __add_request_to_db(self):
priority = request.priority
# 如果需要去重并且库中已重复 则continue
- if (
- request.filter_repeat
- and setting.REQUEST_FILTER_ENABLE
- and not self.__class__.dedup.add(request.fingerprint)
- ):
- log.debug("request已存在 url = %s" % request.url)
+ if self.is_exist_request(request):
continue
else:
request_list.append(str(request.to_dict))
diff --git a/feapder/commands/cmdline.py b/feapder/commands/cmdline.py
index 39afb164..91d0531e 100644
--- a/feapder/commands/cmdline.py
+++ b/feapder/commands/cmdline.py
@@ -8,26 +8,52 @@
@email: boris_liu@foxmail.com
"""
+import re
import sys
from os.path import dirname, join
+import os
+
+import requests
from feapder.commands import create_builder
+from feapder.commands import retry
from feapder.commands import shell
from feapder.commands import zip
+HELP = """
+███████╗███████╗ █████╗ ██████╗ ██████╗ ███████╗██████╗
+██╔════╝██╔════╝██╔══██╗██╔══██╗██╔══██╗██╔════╝██╔══██╗
+█████╗ █████╗ ███████║██████╔╝██║ ██║█████╗ ██████╔╝
+██╔══╝ ██╔══╝ ██╔══██║██╔═══╝ ██║ ██║██╔══╝ ██╔══██╗
+██║ ███████╗██║ ██║██║ ██████╔╝███████╗██║ ██║
+╚═╝ ╚══════╝╚═╝ ╚═╝╚═╝ ╚═════╝ ╚══════╝╚═╝ ╚═╝
+
+Version: {version}
+Document: https://feapder.com
+
+Usage:
+ feapder [options] [args]
+
+Available commands:
+"""
+
+NEW_VERSION_TIP = """
+──────────────────────────────────────────────────────
+New version available \033[31m{version}\033[0m → \033[32m{new_version}\033[0m
+Run \033[33mpip install --upgrade feapder\033[0m to update!
+"""
+
+with open(join(dirname(dirname(__file__)), "VERSION"), "rb") as f:
+ VERSION = f.read().decode("ascii").strip()
-def _print_commands():
- with open(join(dirname(dirname(__file__)), "VERSION"), "rb") as f:
- version = f.read().decode("ascii").strip()
- print("feapder {}".format(version))
- print("\nUsage:")
- print(" feapder [options] [args]\n")
- print("Available commands:")
+def _print_commands():
+ print(HELP.rstrip().format(version=VERSION))
cmds = {
"create": "create project、spider、item and so on",
"shell": "debug response",
"zip": "zip project",
+ "retry": "retry failed request or item",
}
for cmdname, cmdclass in sorted(cmds.items()):
print(" %-13s %s" % (cmdname, cmdclass))
@@ -35,21 +61,54 @@ def _print_commands():
print('\nUse "feapder -h" to see more info about a command')
+def check_new_version():
+ try:
+ url = "https://pypi.org/simple/feapder/"
+ resp = requests.get(url, timeout=3, verify=False)
+ html = resp.text
+
+ last_stable_version = re.findall(r"feapder-([\d.]*?).tar.gz", html)[-1]
+ now_version = VERSION
+ now_stable_version = re.sub("-beta.*", "", VERSION)
+
+ if now_stable_version < last_stable_version or (
+ now_stable_version == last_stable_version and "beta" in now_version
+ ):
+ new_version = f"feapder=={last_stable_version}"
+ if new_version:
+ version = f"feapder=={VERSION.replace('-beta', 'b')}"
+ tip = NEW_VERSION_TIP.format(version=version, new_version=new_version)
+ # 修复window下print不能带颜色输出的问题
+ if os.name == "nt":
+ os.system("")
+ print(tip)
+ except Exception as e:
+ pass
+
+
def execute():
- args = sys.argv
- if len(args) < 2:
- _print_commands()
- return
-
- command = args.pop(1)
- if command == "create":
- create_builder.main()
- elif command == "shell":
- shell.main()
- elif command == "zip":
- zip.main()
- else:
- _print_commands()
+ try:
+ args = sys.argv
+ if len(args) < 2:
+ _print_commands()
+ check_new_version()
+ return
+
+ command = args.pop(1)
+ if command == "create":
+ create_builder.main()
+ elif command == "shell":
+ shell.main()
+ elif command == "zip":
+ zip.main()
+ elif command == "retry":
+ retry.main()
+ else:
+ _print_commands()
+ except KeyboardInterrupt:
+ pass
+
+ check_new_version()
if __name__ == "__main__":
diff --git a/feapder/commands/create/create_item.py b/feapder/commands/create/create_item.py
index 8c71dba2..d8726381 100644
--- a/feapder/commands/create/create_item.py
+++ b/feapder/commands/create/create_item.py
@@ -19,7 +19,7 @@
def deal_file_info(file):
file = file.replace("{DATE}", tools.get_current_date())
- file = file.replace("{USER}", getpass.getuser())
+ file = file.replace("{USER}", os.getenv("FEAPDER_USER") or getpass.getuser())
return file
@@ -65,10 +65,15 @@ def convert_table_name_to_hump(self, table_name):
return table_hump_format
- def get_item_template(self):
- template_path = os.path.abspath(
- os.path.join(__file__, "../../../templates/item_template.tmpl")
- )
+ def get_item_template(self, item_type):
+ if item_type == "Item":
+ template_path = os.path.abspath(
+ os.path.join(__file__, "../../../templates/item_template.tmpl")
+ )
+ else:
+ template_path = os.path.abspath(
+ os.path.join(__file__, "../../../templates/update_item_template.tmpl")
+ )
with open(template_path, "r", encoding="utf-8") as file:
item_template = file.read()
@@ -148,7 +153,7 @@ def save_template_to_file(self, item_template, table_name):
if os.path.basename(os.path.dirname(os.path.abspath(item_file))) == "items":
self._create_init.create()
- def create(self, tables_name, support_dict):
+ def create(self, tables_name, item_type, support_dict):
input_tables_name = tables_name
tables_name = self.select_tables_name(tables_name)
@@ -161,7 +166,7 @@ def create(self, tables_name, support_dict):
table_name = table_name[0]
columns = self.select_columns(table_name)
- item_template = self.get_item_template()
+ item_template = self.get_item_template(item_type)
item_template = self.create_item(
item_template, columns, table_name, support_dict
)
diff --git a/feapder/commands/create/create_project.py b/feapder/commands/create/create_project.py
index 83d9576a..c500f6af 100644
--- a/feapder/commands/create/create_project.py
+++ b/feapder/commands/create/create_project.py
@@ -17,7 +17,7 @@
def deal_file_info(file):
file = file.replace("{DATE}", tools.get_current_date())
- file = file.replace("{USER}", getpass.getuser())
+ file = file.replace("{USER}", os.getenv("FEAPDER_USER") or getpass.getuser())
return file
diff --git a/feapder/commands/create/create_spider.py b/feapder/commands/create/create_spider.py
index 1cbaff7c..f464e059 100644
--- a/feapder/commands/create/create_spider.py
+++ b/feapder/commands/create/create_spider.py
@@ -18,7 +18,7 @@
def deal_file_info(file):
file = file.replace("{DATE}", tools.get_current_date())
- file = file.replace("{USER}", getpass.getuser())
+ file = file.replace("{USER}", os.getenv("FEAPDER_USER") or getpass.getuser())
return file
@@ -49,14 +49,16 @@ def cover_to_underline(self, key):
return key
def get_spider_template(self, spider_type):
- if spider_type == 1:
+ if spider_type == "AirSpider":
template_path = "air_spider_template.tmpl"
- elif spider_type == 2:
+ elif spider_type == "Spider":
template_path = "spider_template.tmpl"
- elif spider_type == 3:
+ elif spider_type == "TaskSpider":
+ template_path = "task_spider_template.tmpl"
+ elif spider_type == "BatchSpider":
template_path = "batch_spider_template.tmpl"
else:
- raise ValueError("spider type error, support 1 2 3")
+ raise ValueError("spider type error, only support AirSpider、 Spider、TaskSpider、BatchSpider")
template_path = os.path.abspath(
os.path.join(__file__, "../../../templates", template_path)
@@ -66,26 +68,24 @@ def get_spider_template(self, spider_type):
return spider_template
- def create_spider(self, spider_template, spider_name):
+ def create_spider(self, spider_template, spider_name, file_name):
spider_template = spider_template.replace("${spider_name}", spider_name)
+ spider_template = spider_template.replace("${file_name}", file_name)
spider_template = deal_file_info(spider_template)
return spider_template
- def save_spider_to_file(self, spider, spider_name):
- spider_underline = self.cover_to_underline(spider_name)
- spider_file = spider_underline + ".py"
-
- if os.path.exists(spider_file):
- confirm = input("%s 文件已存在 是否覆盖 (y/n). " % spider_file)
+ def save_spider_to_file(self, spider, spider_name, file_name):
+ if os.path.exists(file_name):
+ confirm = input("%s 文件已存在 是否覆盖 (y/n). " % file_name)
if confirm != "y":
print("取消覆盖 退出")
return
- with open(spider_file, "w", encoding="utf-8") as file:
+ with open(file_name, "w", encoding="utf-8") as file:
file.write(spider)
print("\n%s 生成成功" % spider_name)
- if os.path.basename(os.path.dirname(os.path.abspath(spider_file))) == "spiders":
+ if os.path.basename(os.path.dirname(os.path.abspath(file_name))) == "spiders":
self._create_init.create()
def create(self, spider_name, spider_type):
@@ -94,8 +94,12 @@ def create(self, spider_name, spider_type):
print("爬虫命名不符合规范,请用蛇形或驼峰命名方式")
return
- if spider_name.islower():
- spider_name = tools.key2hump(spider_name)
+ underline_format = self.cover_to_underline(spider_name)
+ spider_name = tools.key2hump(underline_format)
+ file_name = underline_format + ".py"
+
+ print(spider_name, file_name)
+
spider_template = self.get_spider_template(spider_type)
- spider = self.create_spider(spider_template, spider_name)
- self.save_spider_to_file(spider, spider_name)
+ spider = self.create_spider(spider_template, spider_name, file_name)
+ self.save_spider_to_file(spider, spider_name, file_name)
diff --git a/feapder/commands/create/create_table.py b/feapder/commands/create/create_table.py
index 4ce404f3..15162782 100644
--- a/feapder/commands/create/create_table.py
+++ b/feapder/commands/create/create_table.py
@@ -33,12 +33,6 @@ def is_valid_date(self, date):
return False
def get_key_type(self, value):
- try:
- value = eval(value)
- except:
- value = value
-
- key_type = "varchar(255)"
if isinstance(value, int):
key_type = "int"
elif isinstance(value, float):
@@ -55,6 +49,8 @@ def get_key_type(self, value):
key_type = "varchar(255)"
elif isinstance(value, (dict, list)):
key_type = "longtext"
+ else:
+ key_type = "varchar(255)"
return key_type
@@ -145,8 +141,9 @@ def create(self, table_name):
unique=unique,
)
print(sql)
-
- if self._db.execute(sql):
+ result=self._db.execute(sql)
+ # 建立表成功。受影响的行数为 0,因此返回0
+ if result==0:
print("\n%s 创建成功" % table_name)
print("注意手动检查下字段类型,确保无误!!!")
else:
diff --git a/feapder/commands/create_builder.py b/feapder/commands/create_builder.py
index f00bea0e..dec0ba05 100644
--- a/feapder/commands/create_builder.py
+++ b/feapder/commands/create_builder.py
@@ -9,6 +9,9 @@
"""
import argparse
+from terminal_layout import Fore
+from terminal_layout.extensions.choice import Choice, StringStyle
+
import feapder.setting as setting
from feapder.commands.create import *
@@ -22,21 +25,13 @@ def main():
spider.add_argument(
"-s",
"--spider",
- nargs="+",
- help="创建爬虫\n"
- "如 feapder create -s "
- "spider_type=1 AirSpider; "
- "spider_type=2 Spider; "
- "spider_type=3 BatchSpider;",
+ help="创建爬虫 如 feapder create -s ",
metavar="",
)
spider.add_argument(
"-i",
"--item",
- nargs="+",
- help="创建item 如 feapder create -i test 则生成test表对应的item。 "
- "支持like语法模糊匹配所要生产的表。 "
- "若想生成支持字典方式赋值的item,则create -item test 1",
+ help="创建item 如 feapder create -i 支持模糊匹配 如 feapder create -i %%table_name%%",
metavar="",
)
spider.add_argument(
@@ -73,21 +68,35 @@ def main():
setting.MYSQL_DB = args.db
if args.item:
- item_name, *support_dict = args.item
- support_dict = bool(support_dict)
- CreateItem().create(item_name, support_dict)
+ c = Choice(
+ "请选择Item类型",
+ ["Item", "Item 支持字典赋值", "UpdateItem", "UpdateItem 支持字典赋值"],
+ icon_style=StringStyle(fore=Fore.green),
+ selected_style=StringStyle(fore=Fore.green),
+ )
+
+ choice = c.get_choice()
+ if choice:
+ index, value = choice
+ item_name = args.item
+ item_type = "Item" if index <= 1 else "UpdateItem"
+ support_dict = index in (1, 3)
+
+ CreateItem().create(item_name, item_type, support_dict)
elif args.spider:
- spider_name, *spider_type = args.spider
- if not spider_type:
- spider_type = 1
- else:
- spider_type = spider_type[0]
- try:
- spider_type = int(spider_type)
- except:
- raise ValueError("spider_type error, support 1, 2, 3")
- CreateSpider().create(spider_name, spider_type)
+ c = Choice(
+ "请选择爬虫模板",
+ ["AirSpider", "Spider", "TaskSpider", "BatchSpider"],
+ icon_style=StringStyle(fore=Fore.green),
+ selected_style=StringStyle(fore=Fore.green),
+ )
+
+ choice = c.get_choice()
+ if choice:
+ index, spider_type = choice
+ spider_name = args.spider
+ CreateSpider().create(spider_name, spider_type)
elif args.project:
CreateProject().create(args.project)
@@ -113,6 +122,9 @@ def main():
elif args.params:
CreateParams().create()
+ else:
+ spider.print_help()
+
if __name__ == "__main__":
main()
diff --git a/feapder/commands/retry.py b/feapder/commands/retry.py
new file mode 100644
index 00000000..19a86f32
--- /dev/null
+++ b/feapder/commands/retry.py
@@ -0,0 +1,54 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/11/18 12:33 PM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+import argparse
+
+from feapder.core.handle_failed_items import HandleFailedItems
+from feapder.core.handle_failed_requests import HandleFailedRequests
+
+
+def retry_failed_requests(redis_key):
+ handle_failed_requests = HandleFailedRequests(redis_key)
+ handle_failed_requests.reput_failed_requests_to_requests()
+
+
+def retry_failed_items(redis_key):
+ handle_failed_items = HandleFailedItems(redis_key)
+ handle_failed_items.reput_failed_items_to_db()
+ handle_failed_items.close()
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description="重试失败的请求或入库失败的item",
+ usage="usage: feapder retry [options] [args]",
+ )
+ parser.add_argument(
+ "-r",
+ "--request",
+ help="重试失败的request 如 feapder retry --request ",
+ metavar="",
+ )
+ parser.add_argument(
+ "-i", "--item", help="重试失败的item 如 feapder retry --item ", metavar=""
+ )
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ if args.request:
+ retry_failed_requests(args.request)
+ if args.item:
+ retry_failed_items(args.item)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/feapder/commands/shell.py b/feapder/commands/shell.py
index a5b816aa..37483799 100644
--- a/feapder/commands/shell.py
+++ b/feapder/commands/shell.py
@@ -8,13 +8,142 @@
@email: boris_liu@foxmail.com
"""
-import json
+import argparse
import re
+import shlex
import sys
import IPython
+import pyperclip
from feapder import Request
+from feapder.utils import tools
+
+
+def parse_curl(curl_str):
+ parser = argparse.ArgumentParser(description="")
+ parser.add_argument("target_url", type=str, nargs="?")
+ parser.add_argument("-X", "--request", type=str, nargs=1, default="")
+ parser.add_argument("-H", "--header", nargs=1, action="append", default=[])
+ parser.add_argument("-d", "--data", nargs=1, action="append", default=[])
+ parser.add_argument("--data-ascii", nargs=1, action="append", default=[])
+ parser.add_argument("--data-binary", nargs=1, action="append", default=[])
+ parser.add_argument("--data-urlencode", nargs=1, action="append", default=[])
+ parser.add_argument("--data-raw", nargs=1, action="append", default=[])
+ parser.add_argument("-F", "--form", nargs=1, action="append", default=[])
+ parser.add_argument("--digest", action="store_true")
+ parser.add_argument("--ntlm", action="store_true")
+ parser.add_argument("--anyauth", action="store_true")
+ parser.add_argument("-e", "--referer", type=str)
+ parser.add_argument("-G", "--get", action="store_true", default=False)
+ parser.add_argument("-I", "--head", action="store_true")
+ parser.add_argument("-k", "--insecure", action="store_true")
+ parser.add_argument("-o", "--output", type=str)
+ parser.add_argument("-O", "--remote_name", action="store_true")
+ parser.add_argument("-r", "--range", type=str)
+ parser.add_argument("-u", "--user", type=str)
+ parser.add_argument("--url", type=str)
+ parser.add_argument("-A", "--user-agent", type=str)
+ parser.add_argument("--compressed", action="store_true", default=False)
+
+ curl_split = shlex.split(curl_str)
+ try:
+ args = parser.parse_known_args(curl_split[1:])[0]
+ except:
+ raise ValueError("Could not parse arguments.")
+
+ # 请求地址
+ url = args.target_url
+
+ # # 请求方法
+ # try:
+ # method = args.request.lower()
+ # except AttributeError:
+ # method = args.request[0].lower()
+
+ # 请求头
+ headers = {
+ h[0].split(":", 1)[0]: ("".join(h[0].split(":", 1)[1]).strip())
+ for h in args.header
+ }
+ if args.user_agent:
+ headers["User-Agent"] = args.user_agent
+ if args.referer:
+ headers["Referer"] = args.referer
+ if args.range:
+ headers["Range"] = args.range
+
+ # Cookie
+ cookie_str = headers.pop("Cookie", "") or headers.pop("cookie", "")
+ cookies = tools.get_cookies_from_str(cookie_str) if cookie_str else {}
+
+ # params
+ url, params = tools.parse_url_params(url)
+
+ # data
+ data = "".join(
+ [
+ "".join(d)
+ for d in args.data
+ + args.data_ascii
+ + args.data_binary
+ + args.data_raw
+ + args.form
+ ]
+ )
+ if data:
+ data = re.sub(r"^\$", "", data)
+
+ # method
+ if args.head:
+ method = "head"
+ elif args.get:
+ method = "get"
+ params.update(data)
+ elif args.request:
+ method = (
+ args.request[0].lower()
+ if isinstance(args.request, list)
+ else args.request.lower()
+ )
+ elif data:
+ method = "post"
+ else:
+ method = "get"
+ params.update(data)
+
+ username = None
+ password = None
+ if args.user:
+ u = args.user
+ if ":" in u:
+ username, password = u.split(":")
+ else:
+ username = u
+ password = input(f"请输入用户{username}的密码")
+
+ auth = None
+ if args.digest:
+ auth = "digest"
+ elif args.ntlm:
+ auth = "ntlm"
+ elif username:
+ auth = "basic"
+
+ insecure = args.insecure
+
+ return dict(
+ url=url,
+ method=method,
+ cookies=cookies,
+ headers=headers,
+ params=params,
+ data=data,
+ insecure=insecure,
+ username=username,
+ password=password,
+ auth=auth,
+ )
def request(**kwargs):
@@ -29,64 +158,54 @@ def fetch_url(url):
request(url=url)
-def fetch_curl(curl_args):
- """
- 解析及抓取curl请求
- :param curl_args:
- [url, '-H', 'xxx', '-H', 'xxx', '--data-binary', '{"xxx":"xxx"}', '--compressed']
- :return:
- """
- url = curl_args[0]
- curl_args.pop(0)
-
- headers = {}
- data = {}
- for i in range(0, len(curl_args), 2):
- if curl_args[i] == "-H":
- regex = "([^:\s]*)[:|\s]*(.*)"
- result = re.search(regex, curl_args[i + 1], re.S).groups()
- if result[0] in headers:
- headers[result[0]] = headers[result[0]] + "&" + result[1]
- else:
- headers[result[0]] = result[1].strip()
-
- elif curl_args[i] == "--data-binary":
- data = json.loads(curl_args[i + 1])
-
- request(url=url, data=data, headers=headers)
+def fetch_curl():
+ input("请复制请求为cURL (bash),复制后按任意键读取剪切板内容\n")
+ curl = pyperclip.paste()
+ if curl:
+ kwargs = parse_curl(curl)
+ request(**kwargs)
def usage():
"""
-下载调试器
+ 下载调试器
-usage: feapder shell [options] [args]
+ usage: feapder shell [options] [args]
-optional arguments:
- -u, --url 抓取指定url
- -c, --curl 抓取curl格式的请求
+ optional arguments:
+ -u, --url 抓取指定url
+ -c, --curl 抓取curl格式的请求
"""
print(usage.__doc__)
sys.exit()
-def main():
- args = sys.argv
- if len(args) < 3:
- usage()
-
- elif args[1] in ("-h", "--help"):
- usage()
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description="测试请求",
+ usage="usage: feapder shell [options] [args]",
+ )
+ parser.add_argument(
+ "-u",
+ "--url",
+ help="请求指定地址, 如 feapder shell --url http://www.spidertools.cn/",
+ metavar="",
+ )
+ parser.add_argument("-c", "--curl", help="执行curl,调试响应", action="store_true")
- elif args[1] in ("-u", "--url"):
- fetch_url(args[2])
+ args = parser.parse_args()
+ return parser, args
- elif args[1] in ("-c", "--curl"):
- fetch_curl(args[2:])
+def main():
+ parser, args = parse_args()
+ if args.url:
+ fetch_url(args.url)
+ elif args.curl:
+ fetch_curl()
else:
- usage()
+ parser.print_help()
if __name__ == "__main__":
diff --git a/feapder/commands/zip.py b/feapder/commands/zip.py
index c8900a51..bb604f2e 100644
--- a/feapder/commands/zip.py
+++ b/feapder/commands/zip.py
@@ -51,16 +51,16 @@ def parse_args():
)
parser.add_argument("dir_path", type=str, help="文件夹路径")
parser.add_argument("zip_name", type=str, nargs="?", help="压缩后的文件名,默认为文件夹名.zip")
- parser.add_argument("-i", type=str, nargs="?", help="忽略文件,支持正则;逗号分隔")
- parser.add_argument("-I", type=str, nargs="?", help="忽略文件夹,支持正则;逗号分隔")
- parser.add_argument("-d", type=str, nargs="?", help="输出路径 默认为当前目录")
+ parser.add_argument("-i", help="忽略文件,逗号分隔,支持正则", metavar="")
+ parser.add_argument("-I", help="忽略文件夹,逗号分隔,支持正则 ", metavar="")
+ parser.add_argument("-o", help="输出路径,默认为当前目录", metavar="")
args = parser.parse_args()
return args
def main():
- ignore_dirs = [".git", "__pycache__", ".idea", "venv"]
+ ignore_dirs = [".git", "__pycache__", ".idea", "venv", "env"]
ignore_files = [".DS_Store"]
args = parse_args()
if args.i:
@@ -69,7 +69,7 @@ def main():
ignore_dirs.extend(args.I.split(","))
dir_path = args.dir_path
zip_name = args.zip_name or os.path.basename(dir_path) + ".zip"
- if args.d:
- zip_name = os.path.join(args.d, os.path.basename(zip_name))
+ if args.o:
+ zip_name = os.path.join(args.o, os.path.basename(zip_name))
zip(dir_path, zip_name, ignore_dirs=ignore_dirs, ignore_files=ignore_files)
diff --git a/feapder/core/base_parser.py b/feapder/core/base_parser.py
index bdc6383e..a06f9c44 100644
--- a/feapder/core/base_parser.py
+++ b/feapder/core/base_parser.py
@@ -13,6 +13,9 @@
from feapder.db.mysqldb import MysqlDB
from feapder.network.item import UpdateItem
from feapder.utils.log import log
+from feapder.network.request import Request
+from feapder.network.response import Response
+from feapder.utils.perfect_dict import PerfectDict
class BaseParser(object):
@@ -26,7 +29,7 @@ def start_requests(self):
pass
- def download_midware(self, request):
+ def download_midware(self, request: Request):
"""
@summary: 下载中间件 可修改请求的一些参数, 或可自定义下载,然后返回 request, response
---------
@@ -37,7 +40,7 @@ def download_midware(self, request):
pass
- def validate(self, request, response):
+ def validate(self, request: Request, response: Response):
"""
@summary: 校验函数, 可用于校验response是否正确
若函数内抛出异常,则重试请求
@@ -53,7 +56,7 @@ def validate(self, request, response):
pass
- def parse(self, request, response):
+ def parse(self, request: Request, response: Response):
"""
@summary: 默认的解析函数
---------
@@ -65,24 +68,27 @@ def parse(self, request, response):
pass
- def exception_request(self, request, response):
+ def exception_request(self, request: Request, response: Response, e: Exception):
"""
@summary: 请求或者parser里解析出异常的request
---------
@param request:
@param response:
+ @param e: 异常
---------
@result: request / callback / None (返回值必须可迭代)
"""
pass
- def failed_request(self, request, response):
+ def failed_request(self, request: Request, response: Response, e: Exception):
"""
@summary: 超过最大重试次数的request
可返回修改后的request 若不返回request,则将传进来的request直接人redis的failed表。否则将修改后的request入failed表
---------
@param request:
+ @param response:
+ @param e: 异常
---------
@result: request / item / callback / None (返回值必须可迭代)
"""
@@ -117,21 +123,12 @@ def close(self):
pass
-class BatchParser(BaseParser):
- """
- @summary: 批次爬虫模版
- ---------
- """
-
- def __init__(
- self, task_table, batch_record_table, task_state, date_format, mysqldb=None
- ):
+class TaskParser(BaseParser):
+ def __init__(self, task_table, task_state, mysqldb=None):
self._mysqldb = mysqldb or MysqlDB() # mysqldb
- self._task_table = task_table # mysql中的任务表
- self._batch_record_table = batch_record_table # mysql 中的批次记录表
self._task_state = task_state # mysql中任务表的state字段名
- self._date_format = date_format # 批次日期格式
+ self._task_table = task_table # mysql中的任务表
def add_task(self):
"""
@@ -141,7 +138,7 @@ def add_task(self):
@result:
"""
- def start_requests(self, task):
+ def start_requests(self, task: PerfectDict):
"""
@summary:
---------
@@ -173,6 +170,8 @@ def update_task_state(self, task_id, state=1, **kwargs):
else:
log.error("置任务%s状态失败 sql=%s" % (task_id, sql))
+ update_task = update_task_state
+
def update_task_batch(self, task_id, state=1, **kwargs):
"""
批量更新任务 多处调用,更新的字段必须一致
@@ -191,6 +190,22 @@ def update_task_batch(self, task_id, state=1, **kwargs):
return update_item
+
+class BatchParser(TaskParser):
+ """
+ @summary: 批次爬虫模版
+ ---------
+ """
+
+ def __init__(
+ self, task_table, batch_record_table, task_state, date_format, mysqldb=None
+ ):
+ super(BatchParser, self).__init__(
+ task_table=task_table, task_state=task_state, mysqldb=mysqldb
+ )
+ self._batch_record_table = batch_record_table # mysql 中的批次记录表
+ self._date_format = date_format # 批次日期格式
+
@property
def batch_date(self):
"""
diff --git a/feapder/core/collector.py b/feapder/core/collector.py
index 9eab61be..5b8ff652 100644
--- a/feapder/core/collector.py
+++ b/feapder/core/collector.py
@@ -8,9 +8,9 @@
@email: boris_liu@foxmail.com
"""
-import collections
import threading
import time
+from queue import Queue, Empty
import feapder.setting as setting
import feapder.utils.tools as tools
@@ -34,110 +34,50 @@ def __init__(self, redis_key):
self._thread_stop = False
- self._todo_requests = collections.deque()
-
- self._tab_requests = setting.TAB_REQUSETS.format(redis_key=redis_key)
- self._tab_spider_status = setting.TAB_SPIDER_STATUS.format(redis_key=redis_key)
-
- self._spider_mark = tools.get_localhost_ip() + f"-{time.time()}"
-
- self._interval = setting.COLLECTOR_SLEEP_TIME
- self._request_count = setting.COLLECTOR_TASK_COUNT
+ self._todo_requests = Queue(maxsize=setting.COLLECTOR_TASK_COUNT)
+ self._tab_requests = setting.TAB_REQUESTS.format(redis_key=redis_key)
self._is_collector_task = False
- self._first_get_task = True
-
- self.__delete_dead_node()
def run(self):
self._thread_stop = False
while not self._thread_stop:
try:
- self.__report_node_heartbeat()
self.__input_data()
except Exception as e:
log.exception(e)
+ time.sleep(0.1)
self._is_collector_task = False
- time.sleep(self._interval)
-
def stop(self):
self._thread_stop = True
self._started.clear()
def __input_data(self):
- current_timestamp = tools.get_current_timestamp()
- if len(self._todo_requests) >= self._request_count:
+ if setting.COLLECTOR_TASK_COUNT / setting.SPIDER_THREAD_COUNT > 1 and (
+ self._todo_requests.qsize() > setting.SPIDER_THREAD_COUNT
+ or self._todo_requests.qsize() >= self._todo_requests.maxsize
+ ):
+ time.sleep(0.1)
return
- request_count = self._request_count # 先赋值
- # 查询最近有心跳的节点数量
- spider_count = self._db.zget_count(
- self._tab_spider_status,
- priority_min=current_timestamp - (self._interval + 10),
- priority_max=current_timestamp,
- )
- # 根据等待节点数量,动态分配request
- if spider_count:
- # 任务数量
- task_count = self._db.zget_count(self._tab_requests)
- # 动态分配的数量 = 任务数量 / 休息的节点数量 + 1
- request_count = task_count // spider_count + 1
-
- request_count = (
- request_count
- if request_count <= self._request_count
- else self._request_count
- )
-
- if not request_count:
- return
+ current_timestamp = tools.get_current_timestamp()
- # 当前无其他节点,并且是首次取任务,则重置丢失的任务
- if self._first_get_task and spider_count <= 1:
- datas = self._db.zrangebyscore_set_score(
- self._tab_requests,
- priority_min=current_timestamp,
- priority_max=current_timestamp + setting.REQUEST_LOST_TIMEOUT,
- score=300,
- count=None,
- )
- self._first_get_task = False
- lose_count = len(datas)
- if lose_count:
- log.info("重置丢失任务完毕,共{}条".format(len(datas)))
-
- # 取任务,只取当前时间搓以内的任务,同时将任务分数修改为 current_timestamp + setting.REQUEST_LOST_TIMEOUT
+ # 取任务,只取当前时间戳以内的任务,同时将任务分数修改为 current_timestamp + setting.REQUEST_LOST_TIMEOUT
requests_list = self._db.zrangebyscore_set_score(
self._tab_requests,
priority_min="-inf",
priority_max=current_timestamp,
score=current_timestamp + setting.REQUEST_LOST_TIMEOUT,
- count=request_count,
+ count=setting.COLLECTOR_TASK_COUNT,
)
if requests_list:
self._is_collector_task = True
# 存request
self.__put_requests(requests_list)
-
- def __report_node_heartbeat(self):
- """
- 汇报节点心跳,以便任务平均分配
- """
- self._db.zadd(
- self._tab_spider_status, self._spider_mark, tools.get_current_timestamp()
- )
-
- def __delete_dead_node(self):
- """
- 删除没有心跳的节点信息
- """
- self._db.zremrangebyscore(
- self._tab_spider_status,
- "-inf",
- tools.get_current_timestamp() - (self._interval + 10),
- )
+ else:
+ time.sleep(0.1)
def __put_requests(self, requests_list):
for request in requests_list:
@@ -158,19 +98,19 @@ def __put_requests(self, requests_list):
request_dict = None
if request_dict:
- self._todo_requests.append(request_dict)
+ self._todo_requests.put(request_dict)
- def get_requests(self, count):
- requests = []
- count = count if count <= len(self._todo_requests) else len(self._todo_requests)
- while count:
- requests.append(self._todo_requests.popleft())
- count -= 1
-
- return requests
+ def get_request(self):
+ try:
+ request = self._todo_requests.get(timeout=1)
+ return request
+ except Empty as e:
+ return None
def get_requests_count(self):
- return len(self._todo_requests) or self._db.zget_count(self._tab_requests) or 0
+ return (
+ self._todo_requests.qsize() or self._db.zget_count(self._tab_requests) or 0
+ )
def is_collector_task(self):
return self._is_collector_task
diff --git a/feapder/core/handle_failed_items.py b/feapder/core/handle_failed_items.py
new file mode 100644
index 00000000..655330f5
--- /dev/null
+++ b/feapder/core/handle_failed_items.py
@@ -0,0 +1,81 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/11/18 11:33 AM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+import feapder.setting as setting
+from feapder.buffer.item_buffer import ItemBuffer
+from feapder.db.redisdb import RedisDB
+from feapder.network.item import Item, UpdateItem
+from feapder.utils.log import log
+
+
+class HandleFailedItems:
+ def __init__(self, redis_key, task_table=None, item_buffer=None):
+ if redis_key.endswith(":s_failed_items"):
+ redis_key = redis_key.replace(":s_failed_items", "")
+
+ self._redisdb = RedisDB()
+ self._item_buffer = item_buffer or ItemBuffer(redis_key, task_table=task_table)
+
+ self._table_failed_items = setting.TAB_FAILED_ITEMS.format(redis_key=redis_key)
+
+ def get_failed_items(self, count=1):
+ failed_items = self._redisdb.sget(
+ self._table_failed_items, count=count, is_pop=False
+ )
+ return failed_items
+
+ def reput_failed_items_to_db(self):
+ log.debug("正在重新写入失败的items...")
+ total_count = 0
+ while True:
+ try:
+ failed_items = self.get_failed_items()
+ if not failed_items:
+ break
+
+ for data_str in failed_items:
+ data = eval(data_str)
+
+ for add in data.get("add"):
+ table = add.get("table")
+ datas = add.get("datas")
+ for _data in datas:
+ item = Item(**_data)
+ item.table_name = table
+ self._item_buffer.put_item(item)
+ total_count += 1
+
+ for update in data.get("update"):
+ table = update.get("table")
+ datas = update.get("datas")
+ update_keys = update.get("update_keys")
+ for _data in datas:
+ item = UpdateItem(**_data)
+ item.table_name = table
+ item.update_key = update_keys
+ self._item_buffer.put_item(item)
+ total_count += 1
+
+ # 入库成功后删除
+ def delete_item():
+ self._redisdb.srem(self._table_failed_items, data_str)
+
+ self._item_buffer.put_item(delete_item)
+ self._item_buffer.flush()
+
+ except Exception as e:
+ log.exception(e)
+
+ if total_count:
+ log.debug("导入%s条失败item到数库" % total_count)
+ else:
+ log.debug("没有失败的item")
+
+ def close(self):
+ self._item_buffer.close()
diff --git a/feapder/core/handle_failed_requests.py b/feapder/core/handle_failed_requests.py
index 0e3498a4..3c1cc880 100644
--- a/feapder/core/handle_failed_requests.py
+++ b/feapder/core/handle_failed_requests.py
@@ -14,17 +14,15 @@
from feapder.utils.log import log
-class HandleFailedRequests(object):
- """docstring for HandleFailedRequests"""
-
+class HandleFailedRequests:
def __init__(self, redis_key):
- super(HandleFailedRequests, self).__init__()
- self._redis_key = redis_key
+ if redis_key.endswith(":z_failed_requests"):
+ redis_key = redis_key.replace(":z_failed_requests", "")
self._redisdb = RedisDB()
- self._request_buffer = RequestBuffer(self._redis_key)
+ self._request_buffer = RequestBuffer(redis_key)
- self._table_failed_request = setting.TAB_FAILED_REQUSETS.format(
+ self._table_failed_request = setting.TAB_FAILED_REQUESTS.format(
redis_key=redis_key
)
diff --git a/feapder/core/parser_control.py b/feapder/core/parser_control.py
index 1f9959a2..021d2956 100644
--- a/feapder/core/parser_control.py
+++ b/feapder/core/parser_control.py
@@ -7,6 +7,7 @@
@author: Boris
@email: boris_liu@foxmail.com
"""
+import inspect
import random
import threading
import time
@@ -15,14 +16,16 @@
import feapder.setting as setting
import feapder.utils.tools as tools
from feapder.buffer.item_buffer import ItemBuffer
-from feapder.db.memory_db import MemoryDB
+from feapder.buffer.request_buffer import AirSpiderRequestBuffer
+from feapder.core.base_parser import BaseParser
+from feapder.db.memorydb import MemoryDB
from feapder.network.item import Item
from feapder.network.request import Request
from feapder.utils import metrics
from feapder.utils.log import log
-class PaserControl(threading.Thread):
+class ParserControl(threading.Thread):
DOWNLOAD_EXCEPTION = "download_exception"
DOWNLOAD_SUCCESS = "download_success"
DOWNLOAD_TOTAL = "download_total"
@@ -33,9 +36,12 @@ class PaserControl(threading.Thread):
# 实时统计已做任务数及失败任务数,若失败任务数/已做任务数>0.5 则报警
_success_task_count = 0
_failed_task_count = 0
+ _total_task_count = 0
+
+ _hook_parsers = set()
def __init__(self, collector, redis_key, request_buffer, item_buffer):
- super(PaserControl, self).__init__()
+ super(ParserControl, self).__init__()
self._parsers = []
self._collector = collector
self._redis_key = redis_key
@@ -44,228 +50,172 @@ def __init__(self, collector, redis_key, request_buffer, item_buffer):
self._thread_stop = False
- self._wait_task_time = 0
-
def run(self):
self._thread_stop = False
while not self._thread_stop:
try:
- requests = self._collector.get_requests(setting.SPIDER_TASK_COUNT)
- if not requests:
+ request = self._collector.get_request()
+ if not request:
if not self.is_show_tip:
- log.debug("parser 等待任务...")
+ log.debug("等待任务...")
self.is_show_tip = True
-
- # log.debug('parser 等待任务{}...'.format(tools.format_seconds(self._wait_task_time)))
-
- time.sleep(1)
- self._wait_task_time += 1
continue
self.is_show_tip = False
- self.deal_requests(requests)
+ self.deal_request(request)
except Exception as e:
log.exception(e)
- time.sleep(3)
def is_not_task(self):
return self.is_show_tip
@classmethod
def get_task_status_count(cls):
- return cls._failed_task_count, cls._success_task_count
-
- def deal_requests(self, requests):
- for request in requests:
-
- response = None
- request_redis = request["request_redis"]
- request = request["request_obj"]
-
- del_request_redis_after_item_to_db = False
- del_request_redis_after_request_to_db = False
-
- for parser in self._parsers:
- if parser.name == request.parser_name:
- used_download_midware_enable = False
- try:
- # 记录需下载的文档
- self.record_download_status(
- PaserControl.DOWNLOAD_TOTAL, parser.name
- )
-
- # 解析request
- if request.auto_request:
- request_temp = None
- response = None
-
- # 下载中间件
- if request.download_midware:
- if isinstance(request.download_midware, (list, tuple)):
- request_temp = request
- for download_midware in request.download_midware:
- download_midware = (
- download_midware
- if callable(download_midware)
- else tools.get_method(
- parser, download_midware
- )
- )
- request_temp = download_midware(request_temp)
- else:
+ return cls._failed_task_count, cls._success_task_count, cls._total_task_count
+
+ def deal_request(self, request):
+ response = None
+ request_redis = request["request_redis"]
+ request = request["request_obj"]
+
+ del_request_redis_after_item_to_db = False
+ del_request_redis_after_request_to_db = False
+
+ for parser in self._parsers:
+ if parser.name == request.parser_name:
+ used_download_midware_enable = False
+ try:
+ self.__class__._total_task_count += 1
+ # 记录需下载的文档
+ self.record_download_status(
+ ParserControl.DOWNLOAD_TOTAL, parser.name
+ )
+
+ # 解析request
+ if request.auto_request:
+ request_temp = None
+ response = None
+
+ # 下载中间件
+ if request.download_midware:
+ if isinstance(request.download_midware, (list, tuple)):
+ request_temp = request
+ for download_midware in request.download_midware:
download_midware = (
- request.download_midware
- if callable(request.download_midware)
- else tools.get_method(
- parser, request.download_midware
- )
+ download_midware
+ if callable(download_midware)
+ else tools.get_method(parser, download_midware)
)
- request_temp = download_midware(request)
- elif request.download_midware != False:
- request_temp = parser.download_midware(request)
-
- # 请求
- if request_temp:
- if (
- isinstance(request_temp, (tuple, list))
- and len(request_temp) == 2
- ):
- request_temp, response = request_temp
-
- if not isinstance(request_temp, Request):
- raise Exception(
- "download_midware need return a request, but received type: {}".format(
- type(request_temp)
- )
+ request_temp = download_midware(request_temp)
+ else:
+ download_midware = (
+ request.download_midware
+ if callable(request.download_midware)
+ else tools.get_method(
+ parser, request.download_midware
)
- used_download_midware_enable = True
- if not response:
- response = (
- request_temp.get_response()
- if not setting.RESPONSE_CACHED_USED
- else request_temp.get_response_from_cached(
- save_cached=False
- )
+ )
+ request_temp = download_midware(request)
+ elif request.download_midware != False:
+ request_temp = parser.download_midware(request)
+
+ # 请求
+ if request_temp:
+ if (
+ isinstance(request_temp, (tuple, list))
+ and len(request_temp) == 2
+ ):
+ request_temp, response = request_temp
+
+ if not isinstance(request_temp, Request):
+ raise Exception(
+ "download_midware need return a request, but received type: {}".format(
+ type(request_temp)
)
- else:
+ )
+ used_download_midware_enable = True
+ if response is None:
response = (
- request.get_response()
+ request_temp.get_response()
if not setting.RESPONSE_CACHED_USED
- else request.get_response_from_cached(
+ else request_temp.get_response_from_cached(
save_cached=False
)
)
-
- if response == None:
- raise Exception(
- "连接超时 url: %s" % (request.url or request_temp.url)
- )
-
else:
- response = None
-
- # 校验
- if parser.validate(request, response) == False:
- continue
-
- if request.callback: # 如果有parser的回调函数,则用回调处理
- callback_parser = (
- request.callback
- if callable(request.callback)
- else tools.get_method(parser, request.callback)
+ response = (
+ request.get_response()
+ if not setting.RESPONSE_CACHED_USED
+ else request.get_response_from_cached(save_cached=False)
)
- results = callback_parser(request, response)
- else: # 否则默认用parser处理
- results = parser.parse(request, response)
- if results and not isinstance(results, Iterable):
+ if response == None:
raise Exception(
- "%s.%s返回值必须可迭代"
- % (parser.name, request.callback or "parse")
+ "连接超时 url: %s" % (request.url or request_temp.url)
)
- # 标识上一个result是什么
- result_type = 0 # 0\1\2 (初始值\request\item)
- # 此处判断是request 还是 item
- for result in results or []:
- if isinstance(result, Request):
- result_type = 1
- # 给request的 parser_name 赋值
- result.parser_name = result.parser_name or parser.name
-
- # 判断是同步的callback还是异步的
- if result.request_sync: # 同步
- request_dict = {
- "request_obj": result,
- "request_redis": None,
- }
- requests.append(request_dict)
- else: # 异步
- # 将next_request 入库
- self._request_buffer.put_request(result)
- del_request_redis_after_request_to_db = True
-
- elif isinstance(result, Item):
- result_type = 2
- # 将item入库
- self._item_buffer.put_item(result)
- # 需删除正在做的request
- del_request_redis_after_item_to_db = True
+ # 校验
+ if parser.validate(request, response) == False:
+ break
- elif callable(result): # result为可执行的无参函数
- if (
- result_type == 2
- ): # item 的 callback,buffer里的item均入库后再执行
- self._item_buffer.put_item(result)
- del_request_redis_after_item_to_db = True
+ else:
+ response = None
- else: # result_type == 1: # request 的 callback,buffer里的request均入库后再执行。可能有的parser直接返回callback
- self._request_buffer.put_request(result)
- del_request_redis_after_request_to_db = True
-
- elif result is not None:
- function_name = "{}.{}".format(
- parser.name,
- (
- request.callback
- and callable(request.callback)
- and getattr(request.callback, "__name__")
- or request.callback
- )
- or "parse",
- )
- raise TypeError(
- f"{function_name} result expect Request、Item or callback, bug get type: {type(result)}"
- )
+ if request.callback: # 如果有parser的回调函数,则用回调处理
+ callback_parser = (
+ request.callback
+ if callable(request.callback)
+ else tools.get_method(parser, request.callback)
+ )
+ results = callback_parser(request, response)
+ else: # 否则默认用parser处理
+ results = parser.parse(request, response)
- except Exception as e:
- exception_type = (
- str(type(e)).replace("", "")
+ if results and not isinstance(results, Iterable):
+ raise Exception(
+ "%s.%s返回值必须可迭代" % (parser.name, request.callback or "parse")
)
- if exception_type.startswith("requests"):
- # 记录下载失败的文档
- self.record_download_status(
- PaserControl.DOWNLOAD_EXCEPTION, parser.name
- )
- else:
- # 记录解析程序异常
- self.record_download_status(
- PaserControl.PAESERS_EXCEPTION, parser.name
- )
+ # 标识上一个result是什么
+ result_type = 0 # 0\1\2 (初始值\request\item)
+ # 此处判断是request 还是 item
+ for result in results or []:
+ if isinstance(result, Request):
+ result_type = 1
+ # 给request的 parser_name 赋值
+ result.parser_name = result.parser_name or parser.name
+
+ # 判断是同步的callback还是异步的
+ if result.request_sync: # 同步
+ request_dict = {
+ "request_obj": result,
+ "request_redis": None,
+ }
+ self.deal_request(request_dict)
+ else: # 异步
+ # 将next_request 入库
+ self._request_buffer.put_request(result)
+ del_request_redis_after_request_to_db = True
- if setting.LOG_LEVEL == "DEBUG": # 只有debug模式下打印, 超时的异常篇幅太多
- log.exception(e)
+ elif isinstance(result, Item):
+ result_type = 2
+ # 将item入库
+ self._item_buffer.put_item(result)
+ # 需删除正在做的request
+ del_request_redis_after_item_to_db = True
- log.error(
- """
- -------------- %s.%s error -------------
- error %s
- response %s
- deal request %s
- """
- % (
+ elif callable(result): # result为可执行的无参函数
+ if result_type == 2: # item 的 callback,buffer里的item均入库后再执行
+ self._item_buffer.put_item(result)
+ del_request_redis_after_item_to_db = True
+
+ else: # result_type == 1: # request 的 callback,buffer里的request均入库后再执行。可能有的parser直接返回callback
+ self._request_buffer.put_request(result)
+ del_request_redis_after_request_to_db = True
+
+ elif result is not None:
+ function_name = "{}.{}".format(
parser.name,
(
request.callback
@@ -274,155 +224,190 @@ def deal_requests(self, requests):
or request.callback
)
or "parse",
- str(e),
- response,
- tools.dumps_json(request.to_dict, indent=28)
- if setting.LOG_LEVEL == "DEBUG"
- else request,
)
- )
+ raise TypeError(
+ f"{function_name} result expect Request、Item or callback, bug get type: {type(result)}"
+ )
- request.error_msg = "%s: %s" % (exception_type, e)
- request.response = str(response)
+ except Exception as e:
+ exception_type = (
+ str(type(e)).replace("", "")
+ )
+ if exception_type.startswith("requests"):
+ # 记录下载失败的文档
+ self.record_download_status(
+ ParserControl.DOWNLOAD_EXCEPTION, parser.name
+ )
+ if request.retry_times % setting.PROXY_MAX_FAILED_TIMES == 0:
+ request.del_proxy()
- if "Invalid URL" in str(e):
- request.is_abandoned = True
+ else:
+ # 记录解析程序异常
+ self.record_download_status(
+ ParserControl.PAESERS_EXCEPTION, parser.name
+ )
- requests = parser.exception_request(request, response) or [
- request
- ]
- if not isinstance(requests, Iterable):
- raise Exception(
- "%s.%s返回值必须可迭代" % (parser.name, "exception_request")
+ if setting.LOG_LEVEL == "DEBUG": # 只有debug模式下打印, 超时的异常篇幅太多
+ log.exception(e)
+
+ log.error(
+ """
+ -------------- %s.%s error -------------
+ error %s
+ response %s
+ deal request %s
+ """
+ % (
+ parser.name,
+ (
+ request.callback
+ and callable(request.callback)
+ and getattr(request.callback, "__name__")
+ or request.callback
)
- for request in requests:
- if callable(request):
- self._request_buffer.put_request(request)
- continue
+ or "parse",
+ str(e),
+ response,
+ tools.dumps_json(request.to_dict, indent=28)
+ if setting.LOG_LEVEL == "DEBUG"
+ else request,
+ )
+ )
- if not isinstance(request, Request):
- raise Exception("exception_request 需 yield request")
+ request.error_msg = "%s: %s" % (exception_type, e)
+ request.response = str(response)
- if (
- request.retry_times + 1 > setting.SPIDER_MAX_RETRY_TIMES
- or request.is_abandoned
- ):
- self.__class__._failed_task_count += 1 # 记录失败任务数
-
- # 处理failed_request的返回值 request 或 func
- results = parser.failed_request(request, response) or [
- request
- ]
- if not isinstance(results, Iterable):
- raise Exception(
- "%s.%s返回值必须可迭代"
- % (parser.name, "failed_request")
- )
+ if "Invalid URL" in str(e):
+ request.is_abandoned = True
- for result in results:
- if isinstance(result, Request):
- if setting.SAVE_FAILED_REQUEST:
- if used_download_midware_enable:
- # 去掉download_midware 添加的属性
- original_request = (
- Request.from_dict(
- eval(request_redis)
- )
- if request_redis
- else result
- )
- original_request.error_msg = (
- request.error_msg
- )
- original_request.response = (
- request.response
- )
-
- self._request_buffer.put_failed_request(
- original_request
- )
- else:
- self._request_buffer.put_failed_request(
- result
- )
-
- elif callable(result):
- self._request_buffer.put_request(result)
-
- elif isinstance(result, Item):
- self._item_buffer.put_item(result)
+ requests = parser.exception_request(request, response, e) or [
+ request
+ ]
+ if not isinstance(requests, Iterable):
+ raise Exception(
+ "%s.%s返回值必须可迭代" % (parser.name, "exception_request")
+ )
+ for request in requests:
+ if callable(request):
+ self._request_buffer.put_request(request)
+ continue
- del_request_redis_after_request_to_db = True
+ if not isinstance(request, Request):
+ raise Exception("exception_request 需 yield request")
- else:
- # 将 requests 重新入库 爬取
- request.retry_times += 1
- request.filter_repeat = False
- log.info(
- """
- 入库 等待重试
- url %s
- 重试次数 %s
- 最大允许重试次数 %s"""
- % (
- request.url,
- request.retry_times,
- setting.SPIDER_MAX_RETRY_TIMES,
- )
+ if (
+ request.retry_times + 1 > setting.SPIDER_MAX_RETRY_TIMES
+ or request.is_abandoned
+ ):
+ self.__class__._failed_task_count += 1 # 记录失败任务数
+
+ # 处理failed_request的返回值 request 或 func
+ results = parser.failed_request(request, response, e) or [
+ request
+ ]
+ if not isinstance(results, Iterable):
+ raise Exception(
+ "%s.%s返回值必须可迭代" % (parser.name, "failed_request")
)
- if used_download_midware_enable:
- # 去掉download_midware 添加的属性 使用原来的requests
- original_request = (
- Request.from_dict(eval(request_redis))
- if request_redis
- else request
- )
- if hasattr(request, "error_msg"):
- original_request.error_msg = request.error_msg
- if hasattr(request, "response"):
- original_request.response = request.response
- original_request.retry_times = request.retry_times
- original_request.filter_repeat = (
- request.filter_repeat
- )
- self._request_buffer.put_request(original_request)
- else:
- self._request_buffer.put_request(request)
- del_request_redis_after_request_to_db = True
+ for result in results:
+ if isinstance(result, Request):
+ if setting.SAVE_FAILED_REQUEST:
+ if used_download_midware_enable:
+ # 去掉download_midware 添加的属性
+ original_request = (
+ Request.from_dict(eval(request_redis))
+ if request_redis
+ else result
+ )
+ original_request.error_msg = (
+ request.error_msg
+ )
+ original_request.response = request.response
- else:
- # 记录下载成功的文档
- self.record_download_status(
- PaserControl.DOWNLOAD_SUCCESS, parser.name
- )
- # 记录成功任务数
- self.__class__._success_task_count += 1
-
- # 缓存下载成功的文档
- if setting.RESPONSE_CACHED_ENABLE:
- request.save_cached(
- response=response,
- expire_time=setting.RESPONSE_CACHED_EXPIRE_TIME,
- )
+ self._request_buffer.put_failed_request(
+ original_request
+ )
+ else:
+ self._request_buffer.put_failed_request(
+ result
+ )
- finally:
- # 释放浏览器
- if response and hasattr(response, "browser"):
- request._webdriver_pool.put(response.browser)
+ elif callable(result):
+ self._request_buffer.put_request(result)
- break
+ elif isinstance(result, Item):
+ self._item_buffer.put_item(result)
- # 删除正在做的request 跟随item优先
- if request_redis:
- if del_request_redis_after_item_to_db:
- self._item_buffer.put_item(request_redis)
+ del_request_redis_after_request_to_db = True
- elif del_request_redis_after_request_to_db:
- self._request_buffer.put_del_request(request_redis)
+ else:
+ # 将 requests 重新入库 爬取
+ request.retry_times += 1
+ request.filter_repeat = False
+ log.info(
+ """
+ 入库 等待重试
+ url %s
+ 重试次数 %s
+ 最大允许重试次数 %s"""
+ % (
+ request.url,
+ request.retry_times,
+ setting.SPIDER_MAX_RETRY_TIMES,
+ )
+ )
+ if used_download_midware_enable:
+ # 去掉download_midware 添加的属性 使用原来的requests
+ original_request = (
+ Request.from_dict(eval(request_redis))
+ if request_redis
+ else request
+ )
+ if hasattr(request, "error_msg"):
+ original_request.error_msg = request.error_msg
+ if hasattr(request, "response"):
+ original_request.response = request.response
+ original_request.retry_times = request.retry_times
+ original_request.filter_repeat = request.filter_repeat
+
+ self._request_buffer.put_request(original_request)
+ else:
+ self._request_buffer.put_request(request)
+ del_request_redis_after_request_to_db = True
else:
- self._request_buffer.put_del_request(request_redis)
+ # 记录下载成功的文档
+ self.record_download_status(
+ ParserControl.DOWNLOAD_SUCCESS, parser.name
+ )
+ # 记录成功任务数
+ self.__class__._success_task_count += 1
+
+ # 缓存下载成功的文档
+ if setting.RESPONSE_CACHED_ENABLE:
+ request.save_cached(
+ response=response,
+ expire_time=setting.RESPONSE_CACHED_EXPIRE_TIME,
+ )
+
+ finally:
+ # 释放浏览器
+ if response and getattr(response, "browser", None):
+ request.render_downloader.put_back(response.browser)
+
+ break
+
+ # 删除正在做的request 跟随item优先
+ if request_redis:
+ if del_request_redis_after_item_to_db:
+ self._item_buffer.put_item(request_redis)
+
+ elif del_request_redis_after_request_to_db:
+ self._request_buffer.put_del_request(request_redis)
+
+ else:
+ self._request_buffer.put_del_request(request_redis)
if setting.SPIDER_SLEEP_TIME:
if (
@@ -448,193 +433,164 @@ def stop(self):
self._thread_stop = True
self._started.clear()
- def add_parser(self, parser):
+ def add_parser(self, parser: BaseParser):
+ # 动态增加parser.exception_request和parser.failed_request的参数, 兼容旧版本
+ if parser not in self.__class__._hook_parsers:
+ self.__class__._hook_parsers.add(parser)
+ if len(inspect.getfullargspec(parser.exception_request).args) == 3:
+ _exception_request = parser.exception_request
+ parser.exception_request = (
+ lambda request, response, e: _exception_request(request, response)
+ )
+
+ if len(inspect.getfullargspec(parser.failed_request).args) == 3:
+ _failed_request = parser.failed_request
+ parser.failed_request = lambda request, response, e: _failed_request(
+ request, response
+ )
+
self._parsers.append(parser)
-class AirSpiderParserControl(PaserControl):
+class AirSpiderParserControl(ParserControl):
is_show_tip = False
# 实时统计已做任务数及失败任务数,若失败任务数/已做任务数>0.5 则报警
_success_task_count = 0
_failed_task_count = 0
- def __init__(self, memory_db: MemoryDB, item_buffer: ItemBuffer):
- super(PaserControl, self).__init__()
+ def __init__(
+ self,
+ *,
+ memory_db: MemoryDB,
+ request_buffer: AirSpiderRequestBuffer,
+ item_buffer: ItemBuffer,
+ ):
+ super(ParserControl, self).__init__()
self._parsers = []
self._memory_db = memory_db
self._thread_stop = False
- self._wait_task_time = 0
+ self._request_buffer = request_buffer
self._item_buffer = item_buffer
def run(self):
while not self._thread_stop:
try:
- requests = self._memory_db.get()
- if not requests:
+ request = self._memory_db.get()
+ if not request:
if not self.is_show_tip:
- log.debug("parser 等待任务...")
+ log.debug("等待任务...")
self.is_show_tip = True
-
- time.sleep(1)
- self._wait_task_time += 1
continue
self.is_show_tip = False
- self.deal_requests([requests])
+ self.deal_request(request)
except Exception as e:
log.exception(e)
- time.sleep(3)
-
- def deal_requests(self, requests):
- for request in requests:
-
- response = None
-
- for parser in self._parsers:
- if parser.name == request.parser_name:
- try:
- # 记录需下载的文档
- self.record_download_status(
- PaserControl.DOWNLOAD_TOTAL, parser.name
- )
- # 解析request
- if request.auto_request:
- request_temp = None
- response = None
-
- # 下载中间件
- if request.download_midware:
- if isinstance(request.download_midware, (list, tuple)):
- request_temp = request
- for download_midware in request.download_midware:
- download_midware = (
- download_midware
- if callable(download_midware)
- else tools.get_method(
- parser, download_midware
- )
- )
- request_temp = download_midware(request_temp)
- else:
+ def deal_request(self, request):
+ response = None
+
+ for parser in self._parsers:
+ if parser.name == request.parser_name:
+ try:
+ self.__class__._total_task_count += 1
+ # 记录需下载的文档
+ self.record_download_status(
+ ParserControl.DOWNLOAD_TOTAL, parser.name
+ )
+
+ # 解析request
+ if request.auto_request:
+ request_temp = None
+ response = None
+
+ # 下载中间件
+ if request.download_midware:
+ if isinstance(request.download_midware, (list, tuple)):
+ request_temp = request
+ for download_midware in request.download_midware:
download_midware = (
- request.download_midware
- if callable(request.download_midware)
- else tools.get_method(
- parser, request.download_midware
- )
+ download_midware
+ if callable(download_midware)
+ else tools.get_method(parser, download_midware)
)
- request_temp = download_midware(request)
- elif request.download_midware != False:
- request_temp = parser.download_midware(request)
-
- # 请求
- if request_temp:
- if (
- isinstance(request_temp, (tuple, list))
- and len(request_temp) == 2
- ):
- request_temp, response = request_temp
-
- if not isinstance(request_temp, Request):
- raise Exception(
- "download_midware need return a request, but received type: {}".format(
- type(request_temp)
- )
+ request_temp = download_midware(request_temp)
+ else:
+ download_midware = (
+ request.download_midware
+ if callable(request.download_midware)
+ else tools.get_method(
+ parser, request.download_midware
)
- request = request_temp
+ )
+ request_temp = download_midware(request)
+ elif request.download_midware != False:
+ request_temp = parser.download_midware(request)
- if not response:
- response = (
- request.get_response()
- if not setting.RESPONSE_CACHED_USED
- else request.get_response_from_cached(
- save_cached=False
+ # 请求
+ if request_temp:
+ if (
+ isinstance(request_temp, (tuple, list))
+ and len(request_temp) == 2
+ ):
+ request_temp, response = request_temp
+
+ if not isinstance(request_temp, Request):
+ raise Exception(
+ "download_midware need return a request, but received type: {}".format(
+ type(request_temp)
)
)
+ request = request_temp
- else:
- response = None
+ if response is None:
+ response = (
+ request.get_response()
+ if not setting.RESPONSE_CACHED_USED
+ else request.get_response_from_cached(save_cached=False)
+ )
# 校验
if parser.validate(request, response) == False:
- continue
-
- if request.callback: # 如果有parser的回调函数,则用回调处理
- callback_parser = (
- request.callback
- if callable(request.callback)
- else tools.get_method(parser, request.callback)
- )
- results = callback_parser(request, response)
- else: # 否则默认用parser处理
- results = parser.parse(request, response)
-
- if results and not isinstance(results, Iterable):
- raise Exception(
- "%s.%s返回值必须可迭代"
- % (parser.name, request.callback or "parse")
- )
-
- # 此处判断是request 还是 item
- for result in results or []:
- if isinstance(result, Request):
- # 给request的 parser_name 赋值
- result.parser_name = result.parser_name or parser.name
-
- # 判断是同步的callback还是异步的
- if result.request_sync: # 同步
- requests.append(result)
- else: # 异步
- # 将next_request 入库
- self._memory_db.add(result)
+ break
- elif isinstance(result, Item):
- self._item_buffer.put_item(result)
- elif result is not None:
- function_name = "{}.{}".format(
- parser.name,
- (
- request.callback
- and callable(request.callback)
- and getattr(request.callback, "__name__")
- or request.callback
- )
- or "parse",
- )
- raise TypeError(
- f"{function_name} result expect Request or Item, bug get type: {type(result)}"
- )
+ else:
+ response = None
- except Exception as e:
- exception_type = (
- str(type(e)).replace("", "")
+ if request.callback: # 如果有parser的回调函数,则用回调处理
+ callback_parser = (
+ request.callback
+ if callable(request.callback)
+ else tools.get_method(parser, request.callback)
)
- if exception_type.startswith("requests"):
- # 记录下载失败的文档
- self.record_download_status(
- PaserControl.DOWNLOAD_EXCEPTION, parser.name
- )
-
- else:
- # 记录解析程序异常
- self.record_download_status(
- PaserControl.PAESERS_EXCEPTION, parser.name
- )
+ results = callback_parser(request, response)
+ else: # 否则默认用parser处理
+ results = parser.parse(request, response)
- if setting.LOG_LEVEL == "DEBUG": # 只有debug模式下打印, 超时的异常篇幅太多
- log.exception(e)
+ if results and not isinstance(results, Iterable):
+ raise Exception(
+ "%s.%s返回值必须可迭代" % (parser.name, request.callback or "parse")
+ )
- log.error(
- """
- -------------- %s.%s error -------------
- error %s
- response %s
- deal request %s
- """
- % (
+ # 此处判断是request 还是 item
+ for result in results or []:
+ if isinstance(result, Request):
+ # 给request的 parser_name 赋值
+ result.parser_name = result.parser_name or parser.name
+
+ # 判断是同步的callback还是异步的
+ if result.request_sync: # 同步
+ self.deal_request(result)
+ else: # 异步
+ # 将next_request 入库
+ self._request_buffer.put_request(result)
+
+ elif isinstance(result, Item):
+ self._item_buffer.put_item(result)
+ elif result is not None:
+ function_name = "{}.{}".format(
parser.name,
(
request.callback
@@ -643,99 +599,140 @@ def deal_requests(self, requests):
or request.callback
)
or "parse",
- str(e),
- response,
- tools.dumps_json(request.to_dict, indent=28)
- if setting.LOG_LEVEL == "DEBUG"
- else request,
)
+ raise TypeError(
+ f"{function_name} result expect Request or Item, bug get type: {type(result)}"
+ )
+
+ except Exception as e:
+ exception_type = (
+ str(type(e)).replace("", "")
+ )
+ if exception_type.startswith("requests"):
+ # 记录下载失败的文档
+ self.record_download_status(
+ ParserControl.DOWNLOAD_EXCEPTION, parser.name
)
+ if request.retry_times % setting.PROXY_MAX_FAILED_TIMES == 0:
+ request.del_proxy()
- request.error_msg = "%s: %s" % (exception_type, e)
- request.response = str(response)
+ else:
+ # 记录解析程序异常
+ self.record_download_status(
+ ParserControl.PAESERS_EXCEPTION, parser.name
+ )
- if "Invalid URL" in str(e):
- request.is_abandoned = True
+ if setting.LOG_LEVEL == "DEBUG": # 只有debug模式下打印, 超时的异常篇幅太多
+ log.exception(e)
- requests = parser.exception_request(request, response) or [
- request
- ]
- if not isinstance(requests, Iterable):
- raise Exception(
- "%s.%s返回值必须可迭代" % (parser.name, "exception_request")
+ log.error(
+ """
+ -------------- %s.%s error -------------
+ error %s
+ response %s
+ deal request %s
+ """
+ % (
+ parser.name,
+ (
+ request.callback
+ and callable(request.callback)
+ and getattr(request.callback, "__name__")
+ or request.callback
)
- for request in requests:
- if not isinstance(request, Request):
- raise Exception("exception_request 需 yield request")
+ or "parse",
+ str(e),
+ response,
+ tools.dumps_json(request.to_dict, indent=28)
+ if setting.LOG_LEVEL == "DEBUG"
+ else request,
+ )
+ )
- if (
- request.retry_times + 1 > setting.SPIDER_MAX_RETRY_TIMES
- or request.is_abandoned
- ):
- self.__class__._failed_task_count += 1 # 记录失败任务数
-
- # 处理failed_request的返回值 request 或 func
- results = parser.failed_request(request, response) or [
- request
- ]
- if not isinstance(results, Iterable):
- raise Exception(
- "%s.%s返回值必须可迭代"
- % (parser.name, "failed_request")
- )
+ request.error_msg = "%s: %s" % (exception_type, e)
+ request.response = str(response)
+
+ if "Invalid URL" in str(e):
+ request.is_abandoned = True
+
+ requests = parser.exception_request(request, response, e) or [
+ request
+ ]
+ if not isinstance(requests, Iterable):
+ raise Exception(
+ "%s.%s返回值必须可迭代" % (parser.name, "exception_request")
+ )
+ for request in requests:
+ if not isinstance(request, Request):
+ raise Exception("exception_request 需 yield request")
+
+ if (
+ request.retry_times + 1 > setting.SPIDER_MAX_RETRY_TIMES
+ or request.is_abandoned
+ ):
+ self.__class__._failed_task_count += 1 # 记录失败任务数
+
+ # 处理failed_request的返回值 request 或 func
+ results = parser.failed_request(request, response, e) or [
+ request
+ ]
+ if not isinstance(results, Iterable):
+ raise Exception(
+ "%s.%s返回值必须可迭代" % (parser.name, "failed_request")
+ )
+
+ log.info(
+ """
+ 任务超过最大重试次数,丢弃
+ url %s
+ 重试次数 %s
+ 最大允许重试次数 %s"""
+ % (
+ request.url,
+ request.retry_times,
+ setting.SPIDER_MAX_RETRY_TIMES,
+ )
+ )
- log.info(
- """
- 任务超过最大重试次数,丢弃
+ else:
+ # 将 requests 重新入库 爬取
+ request.retry_times += 1
+ request.filter_repeat = False
+ log.info(
+ """
+ 入库 等待重试
url %s
重试次数 %s
最大允许重试次数 %s"""
- % (
- request.url,
- request.retry_times,
- setting.SPIDER_MAX_RETRY_TIMES,
- )
- )
-
- else:
- # 将 requests 重新入库 爬取
- request.retry_times += 1
- request.filter_repeat = False
- log.info(
- """
- 入库 等待重试
- url %s
- 重试次数 %s
- 最大允许重试次数 %s"""
- % (
- request.url,
- request.retry_times,
- setting.SPIDER_MAX_RETRY_TIMES,
- )
+ % (
+ request.url,
+ request.retry_times,
+ setting.SPIDER_MAX_RETRY_TIMES,
)
- self._memory_db.add(request)
+ )
+ self._request_buffer.put_request(request)
- else:
- # 记录下载成功的文档
- self.record_download_status(
- PaserControl.DOWNLOAD_SUCCESS, parser.name
+ else:
+ # 记录下载成功的文档
+ self.record_download_status(
+ ParserControl.DOWNLOAD_SUCCESS, parser.name
+ )
+ # 记录成功任务数
+ self.__class__._success_task_count += 1
+
+ # 缓存下载成功的文档
+ if setting.RESPONSE_CACHED_ENABLE:
+ request.save_cached(
+ response=response,
+ expire_time=setting.RESPONSE_CACHED_EXPIRE_TIME,
)
- # 记录成功任务数
- self.__class__._success_task_count += 1
-
- # 缓存下载成功的文档
- if setting.RESPONSE_CACHED_ENABLE:
- request.save_cached(
- response=response,
- expire_time=setting.RESPONSE_CACHED_EXPIRE_TIME,
- )
- finally:
- # 释放浏览器
- if response and hasattr(response, "browser"):
- request._webdriver_pool.put(response.browser)
+ finally:
+ # 释放浏览器
+ if response and getattr(response, "browser", None):
+ request.render_downloader.put_back(response.browser)
- break
+ break
if setting.SPIDER_SLEEP_TIME:
if (
diff --git a/feapder/core/scheduler.py b/feapder/core/scheduler.py
index 4963fab7..0177d185 100644
--- a/feapder/core/scheduler.py
+++ b/feapder/core/scheduler.py
@@ -17,21 +17,24 @@
from feapder.buffer.request_buffer import RequestBuffer
from feapder.core.base_parser import BaseParser
from feapder.core.collector import Collector
+from feapder.core.handle_failed_items import HandleFailedItems
from feapder.core.handle_failed_requests import HandleFailedRequests
-from feapder.core.parser_control import PaserControl
+from feapder.core.parser_control import ParserControl
from feapder.db.redisdb import RedisDB
from feapder.network.item import Item
from feapder.network.request import Request
+from feapder.utils import metrics
from feapder.utils.log import log
from feapder.utils.redis_lock import RedisLock
-from feapder.utils import metrics
+from feapder.utils.tail_thread import TailThread
SPIDER_START_TIME_KEY = "spider_start_time"
SPIDER_END_TIME_KEY = "spider_end_time"
SPIDER_LAST_TASK_COUNT_RECORD_TIME_KEY = "last_task_count_record_time"
+HEARTBEAT_TIME_KEY = "heartbeat_time"
-class Scheduler(threading.Thread):
+class Scheduler(TailThread):
__custom_setting__ = {}
def __init__(
@@ -46,7 +49,7 @@ def __init__(
batch_interval=0,
wait_lock=True,
task_table=None,
- **kwargs
+ **kwargs,
):
"""
@summary: 调度器
@@ -89,7 +92,7 @@ def __init__(
self._collector = Collector(redis_key)
self._parsers = []
self._parser_controls = []
- self._parser_control_obj = PaserControl
+ self._parser_control_obj = ParserControl
# 兼容老版本的参数
if "auto_stop_when_spider_done" in kwargs:
@@ -116,27 +119,24 @@ def __init__(
else lambda: log.info("\n********** feapder end **********")
)
- self._thread_count = (
- setting.SPIDER_THREAD_COUNT if not thread_count else thread_count
- )
+ if thread_count:
+ setattr(setting, "SPIDER_THREAD_COUNT", thread_count)
+ self._thread_count = setting.SPIDER_THREAD_COUNT
- self._spider_name = redis_key
- self._project_name = redis_key.split(":")[0]
+ self._spider_name = self.name
+ self._task_table = task_table
- self._tab_spider_time = setting.TAB_SPIDER_TIME.format(redis_key=redis_key)
self._tab_spider_status = setting.TAB_SPIDER_STATUS.format(redis_key=redis_key)
- self._tab_requests = setting.TAB_REQUSETS.format(redis_key=redis_key)
- self._tab_failed_requests = setting.TAB_FAILED_REQUSETS.format(
+ self._tab_requests = setting.TAB_REQUESTS.format(redis_key=redis_key)
+ self._tab_failed_requests = setting.TAB_FAILED_REQUESTS.format(
redis_key=redis_key
)
-
self._is_notify_end = False # 是否已经通知结束
self._last_task_count = 0 # 最近一次任务数量
+ self._last_check_task_count_time = 0
+ self._stop_heartbeat = False # 是否停止心跳
self._redisdb = RedisDB()
- self._project_total_state_table = "{}_total_state".format(self._project_name)
- self._is_exist_project_total_state_table = False
-
# Request 缓存设置
Request.cached_redis_key = redis_key
Request.cached_expire_time = setting.RESPONSE_CACHED_EXPIRE_TIME
@@ -149,6 +149,10 @@ def __init__(
self.wait_lock = wait_lock
self.init_metrics()
+ # 重置丢失的任务
+ self.reset_task()
+
+ self._stop_spider = False
def init_metrics(self):
"""
@@ -171,16 +175,9 @@ def run(self):
while True:
try:
- if self.all_thread_is_done():
+ if self._stop_spider or self.all_thread_is_done():
if not self._is_notify_end:
self.spider_end() # 跑完一轮
- self.record_spider_state(
- spider_type=1,
- state=1,
- spider_end_time=tools.get_current_date(),
- batch_interval=self._batch_interval,
- )
-
self._is_notify_end = True
if not self._keep_alive:
@@ -198,22 +195,13 @@ def run(self):
tools.delay_time(1) # 1秒钟检查一次爬虫状态
def __add_task(self):
- # 启动parser 的 start_requests
- self.spider_begin() # 不自动结束的爬虫此处只能执行一遍
- self.record_spider_state(
- spider_type=1,
- state=0,
- batch_date=tools.get_current_date(),
- spider_start_time=tools.get_current_date(),
- batch_interval=self._batch_interval,
- )
-
# 判断任务池中属否还有任务,若有接着抓取
todo_task_count = self._collector.get_requests_count()
if todo_task_count:
log.info("检查到有待做任务 %s 条,不重下发新任务,将接着上回异常终止处继续抓取" % todo_task_count)
else:
for parser in self._parsers:
+ # 启动parser 的 start_requests
results = parser.start_requests()
# 添加request到请求队列,由请求队列统一入库
if results and not isinstance(results, Iterable):
@@ -246,6 +234,19 @@ def __add_task(self):
self._item_buffer.flush()
def _start(self):
+ self.spider_begin()
+
+ # 将失败的item入库
+ if setting.RETRY_FAILED_ITEMS:
+ handle_failed_items = HandleFailedItems(
+ redis_key=self._redis_key,
+ task_table=self._task_table,
+ item_buffer=self._item_buffer,
+ )
+ handle_failed_items.reput_failed_items_to_db()
+
+ # 心跳开始
+ self.heartbeat_start()
# 启动request_buffer
self._request_buffer.start()
# 启动item_buffer
@@ -329,62 +330,6 @@ def check_task_status(self):
else:
return
- # 检查redis中任务状态,若连续20分钟内任务数量未发生变化(parser可能卡死),则发出报警信息
- task_count = self._redisdb.zget_count(self._tab_requests)
-
- if task_count:
- if task_count != self._last_task_count:
- self._last_task_count = task_count
- self._redisdb.hset(
- self._tab_spider_time,
- SPIDER_LAST_TASK_COUNT_RECORD_TIME_KEY,
- tools.get_current_timestamp(),
- ) # 多进程会重复发消息, 使用reids记录上次统计时间
- else:
- # 判断时间间隔是否超过20分钟
- lua = """
- -- local key = KEYS[1]
- local field = ARGV[1]
- local current_timestamp = ARGV[2]
-
- -- 取值
- local last_timestamp = redis.call('hget', KEYS[1], field)
- if last_timestamp and current_timestamp - last_timestamp >= 1200 then
- return current_timestamp - last_timestamp -- 返回任务停滞时间 秒
- end
-
- if not last_timestamp then
- redis.call('hset', KEYS[1], field, current_timestamp)
- end
-
- return 0
-
- """
- redis_obj = self._redisdb.get_redis_obj()
- cmd = redis_obj.register_script(lua)
- overtime = cmd(
- keys=[self._tab_spider_time],
- args=[
- SPIDER_LAST_TASK_COUNT_RECORD_TIME_KEY,
- tools.get_current_timestamp(),
- ],
- )
-
- if overtime:
- # 发送报警
- msg = "《{}》爬虫任务停滞 {},请检查爬虫是否正常".format(
- self._spider_name, tools.format_seconds(overtime)
- )
- log.error(msg)
- self.send_msg(
- msg,
- level="error",
- message_prefix="《{}》爬虫任务停滞".format(self._spider_name),
- )
-
- else:
- self._last_task_count = 0
-
# 检查失败任务数量 超过1000 报警,
failed_count = self._redisdb.zget_count(self._tab_failed_requests)
if failed_count > setting.WARNING_FAILED_COUNT:
@@ -398,7 +343,11 @@ def check_task_status(self):
)
# parser_control实时统计已做任务数及失败任务数,若成功率<0.5 则报警
- failed_task_count, success_task_count = PaserControl.get_task_status_count()
+ (
+ failed_task_count,
+ success_task_count,
+ total_task_count,
+ ) = ParserControl.get_task_status_count()
total_count = success_task_count + failed_task_count
if total_count > 0:
task_success_rate = success_task_count / total_count
@@ -417,6 +366,34 @@ def check_task_status(self):
message_prefix="《%s》爬虫当前任务成功率报警" % (self._spider_name),
)
+ # 判断任务数是否变化
+ current_time = tools.get_current_timestamp()
+ if (
+ current_time - self._last_check_task_count_time
+ > setting.WARNING_CHECK_TASK_COUNT_INTERVAL
+ ):
+ if (
+ self._last_task_count
+ and self._last_task_count == total_task_count
+ and self._redisdb.zget_count(self._tab_requests) > 0
+ ):
+ # 发送报警
+ msg = "《{}》爬虫停滞 {},请检查爬虫是否正常".format(
+ self._spider_name,
+ tools.format_seconds(
+ current_time - self._last_check_task_count_time
+ ),
+ )
+ log.error(msg)
+ self.send_msg(
+ msg,
+ level="error",
+ message_prefix="《{}》爬虫停滞".format(self._spider_name),
+ )
+ else:
+ self._last_task_count = total_task_count
+ self._last_check_task_count_time = current_time
+
# 检查入库失败次数
if self._item_buffer.export_falied_times > setting.EXPORT_DATA_MAX_FAILED_TIMES:
msg = "《{}》爬虫导出数据失败,失败次数:{}, 请检查爬虫是否正常".format(
@@ -427,21 +404,19 @@ def check_task_status(self):
msg, level="error", message_prefix="《%s》爬虫导出数据失败" % (self._spider_name)
)
- def delete_tables(self, delete_tables_list):
- if isinstance(delete_tables_list, bool):
- delete_tables_list = [self._redis_key + "*"]
- elif not isinstance(delete_tables_list, (list, tuple)):
- delete_tables_list = [delete_tables_list]
-
- redis = RedisDB()
- for delete_tab in delete_tables_list:
- if not delete_tab.startswith(self._redis_key):
- delete_tab = self._redis_key + delete_tab
- tables = redis.getkeys(delete_tab)
- for table in tables:
- if table != self._tab_spider_time:
- log.info("正在删除key %s" % table)
- redis.clear(table)
+ def delete_tables(self, delete_keys):
+ if delete_keys == True:
+ delete_keys = [self._redis_key + "*"]
+ elif not isinstance(delete_keys, (list, tuple)):
+ delete_keys = [delete_keys]
+
+ for delete_key in delete_keys:
+ if not delete_key.startswith(self._redis_key):
+ delete_key = self._redis_key + delete_key
+ keys = self._redisdb.getkeys(delete_key)
+ for key in keys:
+ log.debug("正在删除key %s" % key)
+ self._redisdb.clear(key)
def _stop_all_thread(self):
self._request_buffer.stop()
@@ -451,7 +426,7 @@ def _stop_all_thread(self):
# 停止 parser_controls
for parser_control in self._parser_controls:
parser_control.stop()
-
+ self.heartbeat_stop()
self._started.clear()
def send_msg(self, msg, level="debug", message_prefix=""):
@@ -473,10 +448,10 @@ def spider_begin(self):
parser.start_callback()
# 记录开始时间
- if not self._redisdb.hexists(self._tab_spider_time, SPIDER_START_TIME_KEY):
+ if not self._redisdb.hexists(self._tab_spider_status, SPIDER_START_TIME_KEY):
current_timestamp = tools.get_current_timestamp()
self._redisdb.hset(
- self._tab_spider_time, SPIDER_START_TIME_KEY, current_timestamp
+ self._tab_spider_status, SPIDER_START_TIME_KEY, current_timestamp
)
# 发送消息
@@ -495,8 +470,7 @@ def spider_end(self):
if not self._keep_alive:
# 关闭webdirver
- if Request.webdriver_pool:
- Request.webdriver_pool.close()
+ Request.render_downloader and Request.render_downloader.close_all()
# 关闭打点
metrics.close()
@@ -505,15 +479,16 @@ def spider_end(self):
# 计算抓取时长
data = self._redisdb.hget(
- self._tab_spider_time, SPIDER_START_TIME_KEY, is_pop=True
+ self._tab_spider_status, SPIDER_START_TIME_KEY, is_pop=True
)
if data:
begin_timestamp = int(data)
spand_time = tools.get_current_timestamp() - begin_timestamp
- msg = "《%s》爬虫结束,耗时 %s" % (
+ msg = "《%s》爬虫%s,采集耗时 %s" % (
self._spider_name,
+ "被终止" if self._stop_spider else "结束",
tools.format_seconds(spand_time),
)
log.info(msg)
@@ -530,7 +505,7 @@ def record_end_time(self):
if self._batch_interval:
current_timestamp = tools.get_current_timestamp()
self._redisdb.hset(
- self._tab_spider_time, SPIDER_END_TIME_KEY, current_timestamp
+ self._tab_spider_status, SPIDER_END_TIME_KEY, current_timestamp
)
def is_reach_next_spider_time(self):
@@ -538,7 +513,7 @@ def is_reach_next_spider_time(self):
return True
last_spider_end_time = self._redisdb.hget(
- self._tab_spider_time, SPIDER_END_TIME_KEY
+ self._tab_spider_status, SPIDER_END_TIME_KEY
)
if last_spider_end_time:
last_spider_end_time = int(last_spider_end_time)
@@ -557,17 +532,6 @@ def is_reach_next_spider_time(self):
return True
- def record_spider_state(
- self,
- spider_type,
- state,
- batch_date=None,
- spider_start_time=None,
- spider_end_time=None,
- batch_interval=None,
- ):
- pass
-
def join(self, timeout=None):
"""
重写线程的join
@@ -576,3 +540,52 @@ def join(self, timeout=None):
return
super().join()
+
+ def heartbeat(self):
+ while not self._stop_heartbeat:
+ try:
+ self._redisdb.hset(
+ self._tab_spider_status,
+ HEARTBEAT_TIME_KEY,
+ tools.get_current_timestamp(),
+ )
+ except Exception as e:
+ log.error("心跳异常: {}".format(e))
+ time.sleep(5)
+
+ def heartbeat_start(self):
+ threading.Thread(target=self.heartbeat).start()
+
+ def heartbeat_stop(self):
+ self._stop_heartbeat = True
+
+ def have_alive_spider(self, heartbeat_interval=10):
+ heartbeat_time = self._redisdb.hget(self._tab_spider_status, HEARTBEAT_TIME_KEY)
+ if heartbeat_time:
+ heartbeat_time = int(heartbeat_time)
+ current_timestamp = tools.get_current_timestamp()
+ if current_timestamp - heartbeat_time < heartbeat_interval:
+ return True
+ return False
+
+ def reset_task(self, heartbeat_interval=10):
+ """
+ 重置丢失的任务
+ Returns:
+
+ """
+ if self.have_alive_spider(heartbeat_interval=heartbeat_interval):
+ current_timestamp = tools.get_current_timestamp()
+ datas = self._redisdb.zrangebyscore_set_score(
+ self._tab_requests,
+ priority_min=current_timestamp,
+ priority_max=current_timestamp + setting.REQUEST_LOST_TIMEOUT,
+ score=300,
+ count=None,
+ )
+ lose_count = len(datas)
+ if lose_count:
+ log.info("重置丢失任务完毕,共{}条".format(len(datas)))
+
+ def stop_spider(self):
+ self._stop_spider = True
diff --git a/feapder/core/spiders/__init__.py b/feapder/core/spiders/__init__.py
index 70b7c226..a32ba668 100644
--- a/feapder/core/spiders/__init__.py
+++ b/feapder/core/spiders/__init__.py
@@ -8,8 +8,9 @@
@email: boris_liu@foxmail.com
"""
-__all__ = ["AirSpider", "Spider", "BatchSpider"]
+__all__ = ["AirSpider", "TaskSpider", "Spider", "BatchSpider"]
from feapder.core.spiders.air_spider import AirSpider
from feapder.core.spiders.spider import Spider
+from feapder.core.spiders.task_spider import TaskSpider
from feapder.core.spiders.batch_spider import BatchSpider
diff --git a/feapder/core/spiders/air_spider.py b/feapder/core/spiders/air_spider.py
index d7f1c7ff..70c30112 100644
--- a/feapder/core/spiders/air_spider.py
+++ b/feapder/core/spiders/air_spider.py
@@ -8,20 +8,20 @@
@email: boris_liu@foxmail.com
"""
-from threading import Thread
-
import feapder.setting as setting
import feapder.utils.tools as tools
from feapder.buffer.item_buffer import ItemBuffer
+from feapder.buffer.request_buffer import AirSpiderRequestBuffer
from feapder.core.base_parser import BaseParser
from feapder.core.parser_control import AirSpiderParserControl
-from feapder.db.memory_db import MemoryDB
+from feapder.db.memorydb import MemoryDB
from feapder.network.request import Request
-from feapder.utils.log import log
from feapder.utils import metrics
+from feapder.utils.log import log
+from feapder.utils.tail_thread import TailThread
-class AirSpider(BaseParser, Thread):
+class AirSpider(BaseParser, TailThread):
__custom_setting__ = {}
def __init__(self, thread_count=None):
@@ -34,14 +34,18 @@ def __init__(self, thread_count=None):
for key, value in self.__class__.__custom_setting__.items():
setattr(setting, key, value)
- self._thread_count = (
- setting.SPIDER_THREAD_COUNT if not thread_count else thread_count
- )
+ if thread_count:
+ setattr(setting, "SPIDER_THREAD_COUNT", thread_count)
+ self._thread_count = setting.SPIDER_THREAD_COUNT
self._memory_db = MemoryDB()
self._parser_controls = []
- self._item_buffer = ItemBuffer(redis_key="air_spider")
+ self._item_buffer = ItemBuffer(redis_key=self.name)
+ self._request_buffer = AirSpiderRequestBuffer(
+ db=self._memory_db, dedup_name=self.name
+ )
+ self._stop_spider = False
metrics.init(**setting.METRICS_OTHER_ARGS)
def distribute_task(self):
@@ -50,7 +54,7 @@ def distribute_task(self):
raise ValueError("仅支持 yield Request")
request.parser_name = request.parser_name or self.name
- self._memory_db.add(request)
+ self._request_buffer.put_request(request, ignore_max_size=False)
def all_thread_is_done(self):
for i in range(3): # 降低偶然性, 因为各个环节不是并发的,很有可能当时状态为假,但检测下一条时该状态为真。一次检测很有可能遇到这种偶然性
@@ -78,7 +82,11 @@ def run(self):
self.start_callback()
for i in range(self._thread_count):
- parser_control = AirSpiderParserControl(self._memory_db, self._item_buffer)
+ parser_control = AirSpiderParserControl(
+ memory_db=self._memory_db,
+ request_buffer=self._request_buffer,
+ item_buffer=self._item_buffer,
+ )
parser_control.add_parser(self)
parser_control.start()
self._parser_controls.append(parser_control)
@@ -89,7 +97,7 @@ def run(self):
while True:
try:
- if self.all_thread_is_done():
+ if self._stop_spider or self.all_thread_is_done():
# 停止 parser_controls
for parser_control in self._parser_controls:
parser_control.stop()
@@ -98,10 +106,12 @@ def run(self):
self._item_buffer.stop()
# 关闭webdirver
- if Request.webdriver_pool:
- Request.webdriver_pool.close()
+ Request.render_downloader and Request.render_downloader.close_all()
- log.info("无任务,爬虫结束")
+ if self._stop_spider:
+ log.info("爬虫被终止")
+ else:
+ log.info("无任务,爬虫结束")
break
except Exception as e:
@@ -123,3 +133,6 @@ def join(self, timeout=None):
return
super().join()
+
+ def stop_spider(self):
+ self._stop_spider = True
diff --git a/feapder/core/spiders/batch_spider.py b/feapder/core/spiders/batch_spider.py
index e5c7ff06..6b2ae092 100644
--- a/feapder/core/spiders/batch_spider.py
+++ b/feapder/core/spiders/batch_spider.py
@@ -16,7 +16,6 @@
import feapder.setting as setting
import feapder.utils.tools as tools
-from feapder.buffer.item_buffer import MAX_ITEM_COUNT
from feapder.core.base_parser import BatchParser
from feapder.core.scheduler import Scheduler
from feapder.db.mysqldb import MysqlDB
@@ -29,7 +28,6 @@
from feapder.utils.redis_lock import RedisLock
CONSOLE_PIPELINE_PATH = "feapder.pipelines.console_pipeline.ConsolePipeline"
-MYSQL_PIPELINE_PATH = "feapder.pipelines.mysql_pipeline.MysqlPipeline"
class BatchSpider(BatchParser, Scheduler):
@@ -54,6 +52,7 @@ def __init__(
end_callback=None,
delete_keys=(),
keep_alive=None,
+ auto_start_next_batch=True,
**kwargs,
):
"""
@@ -89,6 +88,7 @@ def __init__(
@param end_callback: 爬虫结束回调函数
@param delete_keys: 爬虫启动时删除的key,类型: 元组/bool/string。 支持正则; 常用于清空任务队列,否则重启时会断点续爬
@param keep_alive: 爬虫是否常驻,默认否
+ @param auto_start_next_batch: 本批次结束后,且下一批次时间已到达时,是否自动启动下一批次,默认是
@param related_redis_key: 有关联的其他爬虫任务表(redis)注意:要避免环路 如 A -> B & B -> A 。
@param related_batch_record: 有关联的其他爬虫批次表(mysql)注意:要避免环路 如 A -> B & B -> A 。
related_redis_key 与 related_batch_record 选其一配置即可;用于相关联的爬虫没结束时,本爬虫也不结束
@@ -126,11 +126,11 @@ def __init__(
self._check_task_interval = check_task_interval
self._task_limit = task_limit # mysql中一次取的任务数量
self._related_task_tables = [
- setting.TAB_REQUSETS.format(redis_key=redis_key)
+ setting.TAB_REQUESTS.format(redis_key=redis_key)
] # 自己的task表也需要检查是否有任务
if related_redis_key:
self._related_task_tables.append(
- setting.TAB_REQUSETS.format(redis_key=related_redis_key)
+ setting.TAB_REQUESTS.format(redis_key=related_redis_key)
)
self._related_batch_record = related_batch_record
@@ -142,6 +142,7 @@ def __init__(
task_condition
)
self._task_order_by = task_order_by and " order by {}".format(task_order_by)
+ self._auto_start_next_batch = auto_start_next_batch
self._batch_date_cache = None
if self._batch_interval >= 1:
@@ -151,25 +152,26 @@ def __init__(
else:
self._date_format = "%Y-%m-%d %H:%M"
- # 报警相关
- self._send_msg_interval = datetime.timedelta(hours=1) # 每隔1小时发送一次报警
- self._last_send_msg_time = None
+ self._is_more_parsers = True # 多模版类爬虫
+ # 初始化每个配置的属性
self._spider_last_done_time = None # 爬虫最近已做任务数量时间
- self._spider_last_done_count = 0 # 爬虫最近已做任务数量
+ self._spider_last_done_count = None # 爬虫最近已做任务数量
self._spider_deal_speed_cached = None
+ self._batch_timeout = False # 批次是否超时或将要超时
- self._is_more_parsers = True # 多模版类爬虫
+ # 重置任务
+ self.reset_task()
- def init_property(self):
+ def init_batch_property(self):
"""
每个批次开始时需要重置的属性
@return:
"""
- self._last_send_msg_time = None
-
+ self._spider_deal_speed_cached = None
self._spider_last_done_time = None
- self._spider_last_done_count = 0 # 爬虫刚开始启动时已做任务数量
+ self._spider_last_done_count = None # 爬虫刚开始启动时已做任务数量
+ self._batch_timeout = False
def add_parser(self, parser, **kwargs):
parser = parser(
@@ -217,7 +219,7 @@ def start_monitor_task(self):
is_first_check = False
# 检查redis中是否有任务 任务小于_min_task_count 则从mysql中取
- tab_requests = setting.TAB_REQUSETS.format(redis_key=self._redis_key)
+ tab_requests = setting.TAB_REQUESTS.format(redis_key=self._redis_key)
todo_task_count = self._redisdb.zget_count(tab_requests)
tasks = []
@@ -306,7 +308,7 @@ def create_batch_record_table(self):
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
""".format(
table_name=self._batch_record_table,
- batch_date="date" if self._date_format == "%Y-%m-%d" else "datetime",
+ batch_date="datetime",
)
self._mysqldb.execute(sql)
@@ -345,7 +347,7 @@ def distribute_task(self, tasks):
if (
self._item_buffer.get_items_count()
- >= MAX_ITEM_COUNT
+ >= setting.ITEM_MAX_CACHED_COUNT
):
self._item_buffer.flush()
@@ -357,7 +359,7 @@ def distribute_task(self, tasks):
if (
self._item_buffer.get_items_count()
- >= MAX_ITEM_COUNT
+ >= setting.ITEM_MAX_CACHED_COUNT
):
self._item_buffer.flush()
@@ -393,7 +395,10 @@ def distribute_task(self, tasks):
self._item_buffer.put_item(request)
result_type = 2
- if self._item_buffer.get_items_count() >= MAX_ITEM_COUNT:
+ if (
+ self._item_buffer.get_items_count()
+ >= setting.ITEM_MAX_CACHED_COUNT
+ ):
self._item_buffer.flush()
elif callable(request): # callbale的request可能是更新数据库操作的函数
@@ -404,7 +409,7 @@ def distribute_task(self, tasks):
if (
self._item_buffer.get_items_count()
- >= MAX_ITEM_COUNT
+ >= setting.ITEM_MAX_CACHED_COUNT
):
self._item_buffer.flush()
@@ -554,14 +559,12 @@ def get_deal_speed(self, total_count, done_count, last_batch_date):
或
None
"""
- if not self._spider_last_done_count:
- now_date = datetime.datetime.now()
+ now_date = datetime.datetime.now()
+ if self._spider_last_done_count is None:
self._spider_last_done_count = done_count
self._spider_last_done_time = now_date
- if done_count > self._spider_last_done_count:
- now_date = datetime.datetime.now()
-
+ elif done_count > self._spider_last_done_count:
time_interval = (now_date - self._spider_last_done_time).total_seconds()
deal_speed = (
done_count - self._spider_last_done_count
@@ -613,14 +616,14 @@ def check_batch(self, is_first_check=False):
@result: 完成返回True 否则False
"""
- sql = 'select date_format(batch_date, "{date_format}"), total_count, done_count from {batch_record_table} order by id desc limit 1'.format(
+ sql = 'select date_format(batch_date, "{date_format}"), total_count, done_count, is_done from {batch_record_table} order by id desc limit 1'.format(
date_format=self._date_format.replace(":%M", ":%i"),
batch_record_table=self._batch_record_table,
)
- batch_info = self._mysqldb.find(sql) # (('2018-08-19', 49686, 0),)
+ batch_info = self._mysqldb.find(sql) # (('批次时间', 总量, 完成量, 批次是否完成),)
if batch_info:
- batch_date, total_count, done_count = batch_info[0]
+ batch_date, total_count, done_count, is_done = batch_info[0]
now_date = datetime.datetime.now()
last_batch_date = datetime.datetime.strptime(batch_date, self._date_format)
@@ -636,27 +639,22 @@ def check_batch(self, is_first_check=False):
done_count = task_count.get("done_count")
if total_count == done_count:
- # 检查相关联的爬虫是否完成
- releated_spider_is_done = self.related_spider_is_done()
- if releated_spider_is_done == False:
- msg = "《{}》本批次未完成, 正在等待依赖爬虫 {} 结束. 批次时间 {} 批次进度 {}/{}".format(
- self._batch_name,
- self._related_batch_record or self._related_task_tables,
- batch_date,
- done_count,
- total_count,
- )
- log.info(msg)
- # 检查是否超时 超时发出报警
- if time_difference >= datetime.timedelta(
- days=self._batch_interval
- ): # 已经超时
- if (
- not self._last_send_msg_time
- or now_date - self._last_send_msg_time
- >= self._send_msg_interval
- ):
- self._last_send_msg_time = now_date
+ if not is_done:
+ # 检查相关联的爬虫是否完成
+ related_spider_is_done = self.related_spider_is_done()
+ if related_spider_is_done is False:
+ msg = "《{}》本批次未完成, 正在等待依赖爬虫 {} 结束. 批次时间 {} 批次进度 {}/{}".format(
+ self._batch_name,
+ self._related_batch_record or self._related_task_tables,
+ batch_date,
+ done_count,
+ total_count,
+ )
+ log.info(msg)
+ # 检查是否超时 超时发出报警
+ if time_difference >= datetime.timedelta(
+ days=self._batch_interval
+ ): # 已经超时
self.send_msg(
msg,
level="error",
@@ -666,25 +664,29 @@ def check_batch(self, is_first_check=False):
or self._related_task_tables,
),
)
+ self._batch_timeout = True
- return False
-
- elif releated_spider_is_done == True:
- # 更新is_done 状态
- self.update_is_done()
+ return False
- else:
- self.update_is_done()
+ else:
+ self.update_is_done()
msg = "《{}》本批次完成 批次时间 {} 共处理 {} 条任务".format(
self._batch_name, batch_date, done_count
)
log.info(msg)
if not is_first_check:
- self.send_msg(msg)
+ if self._batch_timeout: # 之前报警过已超时,现在已完成,发出恢复消息
+ self._batch_timeout = False
+ self.send_msg(msg, level="error")
+ else:
+ self.send_msg(msg)
# 判断下一批次是否到
if time_difference >= datetime.timedelta(days=self._batch_interval):
+ if not is_first_check and not self._auto_start_next_batch:
+ return True # 下一批次不开始。因为设置了不自动开始下一批次
+
msg = "《{}》下一批次开始".format(self._batch_name)
log.info(msg)
self.send_msg(msg)
@@ -692,23 +694,16 @@ def check_batch(self, is_first_check=False):
# 初始化任务表状态
if self.init_task() != False: # 更新失败返回False 其他返回True/None
# 初始化属性
- self.init_property()
+ self.init_batch_property()
is_success = (
self.record_batch()
) # 有可能插入不成功,但是任务表已经重置了,不过由于当前时间为下一批次的时间,检查批次是否结束时不会检查任务表,所以下次执行时仍然会重置
if is_success:
# 看是否有等待任务的worker,若有则需要等会再下发任务,防止work批次时间没来得及更新
- current_timestamp = tools.get_current_timestamp()
- spider_count = self._redisdb.zget_count(
- self._tab_spider_status,
- priority_min=current_timestamp
- - (setting.COLLECTOR_SLEEP_TIME + 10),
- priority_max=current_timestamp,
- )
- if spider_count:
+ if self.have_alive_spider():
log.info(
- f"插入新批次记录成功,检测到有{spider_count}个爬虫进程在等待任务,本批任务1分钟后开始下发, 防止爬虫端缓存的批次时间没来得及更新"
+ f"插入新批次记录成功,检测到有爬虫进程在等待任务,本批任务1分钟后开始下发, 防止爬虫端缓存的批次时间没来得及更新"
)
tools.delay_time(60)
else:
@@ -770,18 +765,12 @@ def check_batch(self, is_first_check=False):
)
log.info(msg)
-
- if (
- not self._last_send_msg_time
- or now_date - self._last_send_msg_time
- >= self._send_msg_interval
- ):
- self._last_send_msg_time = now_date
- self.send_msg(
- msg,
- level="error",
- message_prefix="《{}》批次超时".format(self._batch_name),
- )
+ self.send_msg(
+ msg,
+ level="error",
+ message_prefix="《{}》批次超时".format(self._batch_name),
+ )
+ self._batch_timeout = True
else: # 未超时
remaining_time = (
@@ -833,19 +822,12 @@ def check_batch(self, is_first_check=False):
tools.format_seconds(overflow_time)
)
# 发送警报
- if (
- not self._last_send_msg_time
- or now_date - self._last_send_msg_time
- >= self._send_msg_interval
- ):
- self._last_send_msg_time = now_date
- self.send_msg(
- msg,
- level="error",
- message_prefix="《{}》批次可能超时".format(
- self._batch_name
- ),
- )
+ self.send_msg(
+ msg,
+ level="error",
+ message_prefix="《{}》批次可能超时".format(self._batch_name),
+ )
+ self._batch_timeout = True
elif overflow_time < 0:
msg += ", 该批次预计提前 {} 完成".format(
@@ -882,7 +864,7 @@ def related_spider_is_done(self):
if is_done is None:
log.warning("相关联的批次表不存在或无批次信息")
- return None
+ return True
if not is_done:
return False
@@ -926,13 +908,6 @@ def record_batch(self):
# 爬虫开始
self.spider_begin()
- self.record_spider_state(
- spider_type=2,
- state=0,
- batch_date=batch_date,
- spider_start_time=tools.get_current_date(),
- batch_interval=self._batch_interval,
- )
else:
log.error("插入新批次失败")
@@ -1027,19 +1002,11 @@ def run(self):
while True:
try:
- if (
+ if self._stop_spider or (
self.task_is_done() and self.all_thread_is_done()
): # redis全部的任务已经做完 并且mysql中的任务已经做完(检查各个线程all_thread_is_done,防止任务没做完,就更新任务状态,导致程序结束的情况)
if not self._is_notify_end:
self.spider_end()
- self.record_spider_state(
- spider_type=2,
- state=1,
- batch_date=self._batch_date_cache,
- spider_end_time=tools.get_current_date(),
- batch_interval=self._batch_interval,
- )
-
self._is_notify_end = True
if not self._keep_alive:
@@ -1078,12 +1045,10 @@ class DebugBatchSpider(BatchSpider):
"""
__debug_custom_setting__ = dict(
- COLLECTOR_SLEEP_TIME=1,
COLLECTOR_TASK_COUNT=1,
# SPIDER
SPIDER_THREAD_COUNT=1,
SPIDER_SLEEP_TIME=0,
- SPIDER_TASK_COUNT=1,
SPIDER_MAX_RETRY_TIMES=10,
REQUEST_LOST_TIMEOUT=600, # 10分钟
PROXY_ENABLE=False,
@@ -1095,7 +1060,6 @@ class DebugBatchSpider(BatchSpider):
REQUEST_FILTER_ENABLE=False,
OSS_UPLOAD_TABLES=(),
DELETE_KEYS=True,
- ITEM_PIPELINES=[CONSOLE_PIPELINE_PATH],
)
def __init__(
@@ -1103,7 +1067,7 @@ def __init__(
task_id=None,
task=None,
save_to_db=False,
- update_stask=False,
+ update_task=False,
*args,
**kwargs,
):
@@ -1111,7 +1075,7 @@ def __init__(
@param task_id: 任务id
@param task: 任务 task 与 task_id 二者选一即可
@param save_to_db: 数据是否入库 默认否
- @param update_stask: 是否更新任务 默认否
+ @param update_task: 是否更新任务 默认否
@param args:
@param kwargs:
"""
@@ -1123,10 +1087,11 @@ def __init__(
raise Exception("task_id 与 task 不能同时为null")
kwargs["redis_key"] = kwargs["redis_key"] + "_debug"
- if save_to_db and not self.__class__.__custom_setting__.get("ITEM_PIPELINES"):
- self.__class__.__debug_custom_setting__.update(
- ITEM_PIPELINES=[MYSQL_PIPELINE_PATH]
- )
+ if not save_to_db:
+ self.__class__.__debug_custom_setting__["ITEM_PIPELINES"] = [
+ CONSOLE_PIPELINE_PATH
+ ]
+
self.__class__.__custom_setting__.update(
self.__class__.__debug_custom_setting__
)
@@ -1135,7 +1100,7 @@ def __init__(
self._task_id = task_id
self._task = task
- self._update_task = update_stask
+ self._update_task = update_task
def start_monitor_task(self):
"""
@@ -1228,22 +1193,6 @@ def update_task_batch(self, task_id, state=1, *args, **kwargs):
return update_item
- def delete_tables(self, delete_tables_list):
- if isinstance(delete_tables_list, bool):
- delete_tables_list = [self._redis_key + "*"]
- elif not isinstance(delete_tables_list, (list, tuple)):
- delete_tables_list = [delete_tables_list]
-
- redis = RedisDB()
- for delete_tab in delete_tables_list:
- if delete_tab == "*":
- delete_tab = self._redis_key + "*"
-
- tables = redis.getkeys(delete_tab)
- for table in tables:
- log.debug("正在清理表 %s" % table)
- redis.clear(table)
-
def run(self):
self.start_monitor_task()
@@ -1264,14 +1213,3 @@ def run(self):
tools.delay_time(1) # 1秒钟检查一次爬虫状态
self.delete_tables([self._redis_key + "*"])
-
- def record_spider_state(
- self,
- spider_type,
- state,
- batch_date=None,
- spider_start_time=None,
- spider_end_time=None,
- batch_interval=None,
- ):
- pass
diff --git a/feapder/core/spiders/spider.py b/feapder/core/spiders/spider.py
index d42ec209..a1097559 100644
--- a/feapder/core/spiders/spider.py
+++ b/feapder/core/spiders/spider.py
@@ -96,7 +96,7 @@ def start_monitor_task(self, *args, **kws):
while True:
try:
# 检查redis中是否有任务
- tab_requests = setting.TAB_REQUSETS.format(redis_key=self._redis_key)
+ tab_requests = setting.TAB_REQUESTS.format(redis_key=self._redis_key)
todo_task_count = redisdb.zget_count(tab_requests)
if todo_task_count < self._min_task_count: # 添加任务
@@ -160,13 +160,6 @@ def distribute_task(self, *args, **kws):
if self._is_distributed_task: # 有任务时才提示启动爬虫
# begin
self.spider_begin()
- self.record_spider_state(
- spider_type=1,
- state=0,
- batch_date=tools.get_current_date(),
- spider_start_time=tools.get_current_date(),
- batch_interval=self._batch_interval,
- )
# 重置已经提示无任务状态为False
self._is_show_not_task = False
@@ -191,16 +184,9 @@ def run(self):
while True:
try:
- if self.all_thread_is_done():
+ if self._stop_spider or self.all_thread_is_done():
if not self._is_notify_end:
self.spider_end() # 跑完一轮
- self.record_spider_state(
- spider_type=1,
- state=1,
- spider_end_time=tools.get_current_date(),
- batch_interval=self._batch_interval,
- )
-
self._is_notify_end = True
if not self._keep_alive:
@@ -230,12 +216,10 @@ class DebugSpider(Spider):
"""
__debug_custom_setting__ = dict(
- COLLECTOR_SLEEP_TIME=1,
COLLECTOR_TASK_COUNT=1,
# SPIDER
SPIDER_THREAD_COUNT=1,
SPIDER_SLEEP_TIME=0,
- SPIDER_TASK_COUNT=1,
SPIDER_MAX_RETRY_TIMES=10,
REQUEST_LOST_TIMEOUT=600, # 10分钟
PROXY_ENABLE=False,
@@ -247,13 +231,15 @@ class DebugSpider(Spider):
REQUEST_FILTER_ENABLE=False,
OSS_UPLOAD_TABLES=(),
DELETE_KEYS=True,
- ITEM_PIPELINES=[CONSOLE_PIPELINE_PATH],
)
- def __init__(self, request=None, request_dict=None, *args, **kwargs):
+ def __init__(
+ self, request=None, request_dict=None, save_to_db=False, *args, **kwargs
+ ):
"""
@param request: request 类对象
@param request_dict: request 字典。 request 与 request_dict 二者选一即可
+ @param save_to_db: 数据是否入库 默认否
@param kwargs:
"""
warnings.warn(
@@ -264,6 +250,10 @@ def __init__(self, request=None, request_dict=None, *args, **kwargs):
raise Exception("request 与 request_dict 不能同时为null")
kwargs["redis_key"] = kwargs["redis_key"] + "_debug"
+ if not save_to_db:
+ self.__class__.__debug_custom_setting__["ITEM_PIPELINES"] = [
+ CONSOLE_PIPELINE_PATH
+ ]
self.__class__.__custom_setting__.update(
self.__class__.__debug_custom_setting__
)
@@ -275,22 +265,6 @@ def __init__(self, request=None, request_dict=None, *args, **kwargs):
def save_cached(self, request, response, table):
pass
- def delete_tables(self, delete_tables_list):
- if isinstance(delete_tables_list, bool):
- delete_tables_list = [self._redis_key + "*"]
- elif not isinstance(delete_tables_list, (list, tuple)):
- delete_tables_list = [delete_tables_list]
-
- redis = RedisDB()
- for delete_tab in delete_tables_list:
- if delete_tab == "*":
- delete_tab = self._redis_key + "*"
-
- tables = redis.getkeys(delete_tab)
- for table in tables:
- log.debug("正在清理表 %s" % table)
- redis.clear(table)
-
def __start_requests(self):
yield self._request
@@ -333,13 +307,6 @@ def distribute_task(self):
if self._is_distributed_task: # 有任务时才提示启动爬虫
# begin
self.spider_begin()
- self.record_spider_state(
- spider_type=1,
- state=0,
- batch_date=tools.get_current_date(),
- spider_start_time=tools.get_current_date(),
- batch_interval=self._batch_interval,
- )
# 重置已经提示无任务状态为False
self._is_show_not_task = False
@@ -353,17 +320,6 @@ def distribute_task(self):
self._is_show_not_task = True
- def record_spider_state(
- self,
- spider_type,
- state,
- batch_date=None,
- spider_start_time=None,
- spider_end_time=None,
- batch_interval=None,
- ):
- pass
-
def _start(self):
# 启动parser 的 start_requests
self.spider_begin() # 不自动结束的爬虫此处只能执行一遍
diff --git a/feapder/core/spiders/task_spider.py b/feapder/core/spiders/task_spider.py
new file mode 100644
index 00000000..41cb3596
--- /dev/null
+++ b/feapder/core/spiders/task_spider.py
@@ -0,0 +1,733 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2020/4/22 12:06 AM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import os
+import time
+import warnings
+from collections.abc import Iterable
+from typing import List, Tuple, Dict, Union
+
+import feapder.setting as setting
+import feapder.utils.tools as tools
+from feapder.core.base_parser import TaskParser
+from feapder.core.scheduler import Scheduler
+from feapder.db.mysqldb import MysqlDB
+from feapder.db.redisdb import RedisDB
+from feapder.network.item import Item
+from feapder.network.item import UpdateItem
+from feapder.network.request import Request
+from feapder.utils.log import log
+from feapder.utils.perfect_dict import PerfectDict
+
+CONSOLE_PIPELINE_PATH = "feapder.pipelines.console_pipeline.ConsolePipeline"
+
+
+class TaskSpider(TaskParser, Scheduler):
+ def __init__(
+ self,
+ redis_key,
+ task_table,
+ task_table_type="mysql",
+ task_keys=None,
+ task_state="state",
+ min_task_count=10000,
+ check_task_interval=5,
+ task_limit=10000,
+ related_redis_key=None,
+ related_batch_record=None,
+ task_condition="",
+ task_order_by="",
+ thread_count=None,
+ begin_callback=None,
+ end_callback=None,
+ delete_keys=(),
+ keep_alive=None,
+ batch_interval=0,
+ use_mysql=True,
+ **kwargs,
+ ):
+ """
+ @summary: 任务爬虫
+ 必要条件 需要指定任务表,可以是redis表或者mysql表作为任务种子
+ redis任务种子表:zset类型。值为 {"xxx":xxx, "xxx2":"xxx2"};若为集成模式,需指定parser_name字段,如{"xxx":xxx, "xxx2":"xxx2", "parser_name":"TestTaskSpider"}
+ mysql任务表:
+ 任务表中必须有id及任务状态字段 如 state, 其他字段可根据爬虫需要的参数自行扩充。若为集成模式,需指定parser_name字段。
+
+ 参考建表语句如下:
+ CREATE TABLE `table_name` (
+ `id` int(11) NOT NULL AUTO_INCREMENT,
+ `param` varchar(1000) DEFAULT NULL COMMENT '爬虫需要的抓取数据需要的参数',
+ `state` int(11) DEFAULT NULL COMMENT '任务状态',
+ `parser_name` varchar(255) DEFAULT NULL COMMENT '任务解析器的脚本类名',
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `nui` (`param`) USING BTREE
+ ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
+
+ ---------
+ @param task_table: mysql中的任务表 或 redis中存放任务种子的key,zset类型
+ @param task_table_type: 任务表类型 支持 redis 、mysql
+ @param task_keys: 需要获取的任务字段 列表 [] 如需指定解析的parser,则需将parser_name字段取出来。
+ @param task_state: mysql中任务表的任务状态字段
+ @param min_task_count: redis 中最少任务数, 少于这个数量会从种子表中取任务
+ @param check_task_interval: 检查是否还有任务的时间间隔;
+ @param task_limit: 每次从数据库中取任务的数量
+ @param redis_key: 任务等数据存放在redis中的key前缀
+ @param thread_count: 线程数,默认为配置文件中的线程数
+ @param begin_callback: 爬虫开始回调函数
+ @param end_callback: 爬虫结束回调函数
+ @param delete_keys: 爬虫启动时删除的key,类型: 元组/bool/string。 支持正则; 常用于清空任务队列,否则重启时会断点续爬
+ @param keep_alive: 爬虫是否常驻,默认否
+ @param related_redis_key: 有关联的其他爬虫任务表(redis)注意:要避免环路 如 A -> B & B -> A 。
+ @param related_batch_record: 有关联的其他爬虫批次表(mysql)注意:要避免环路 如 A -> B & B -> A 。
+ related_redis_key 与 related_batch_record 选其一配置即可;用于相关联的爬虫没结束时,本爬虫也不结束
+ 若相关连的爬虫为批次爬虫,推荐以related_batch_record配置,
+ 若相关连的爬虫为普通爬虫,无批次表,可以以related_redis_key配置
+ @param task_condition: 任务条件 用于从一个大任务表中挑选出数据自己爬虫的任务,即where后的条件语句
+ @param task_order_by: 取任务时的排序条件 如 id desc
+ @param batch_interval: 抓取时间间隔 默认为0 天为单位 多次启动时,只有当前时间与第一次抓取结束的时间间隔大于指定的时间间隔时,爬虫才启动
+ @param use_mysql: 是否使用mysql数据库
+ ---------
+ @result:
+ """
+ Scheduler.__init__(
+ self,
+ redis_key=redis_key,
+ thread_count=thread_count,
+ begin_callback=begin_callback,
+ end_callback=end_callback,
+ delete_keys=delete_keys,
+ keep_alive=keep_alive,
+ auto_start_requests=False,
+ batch_interval=batch_interval,
+ task_table=task_table,
+ **kwargs,
+ )
+
+ self._redisdb = RedisDB()
+ self._mysqldb = MysqlDB() if use_mysql else None
+
+ self._task_table = task_table # mysql中的任务表
+ self._task_keys = task_keys # 需要获取的任务字段
+ self._task_table_type = task_table_type
+
+ if self._task_table_type == "mysql" and not self._task_keys:
+ raise Exception("需指定任务字段 使用task_keys")
+
+ self._task_state = task_state # mysql中任务表的state字段名
+ self._min_task_count = min_task_count # redis 中最少任务数
+ self._check_task_interval = check_task_interval
+ self._task_limit = task_limit # mysql中一次取的任务数量
+ self._related_task_tables = [
+ setting.TAB_REQUESTS.format(redis_key=redis_key)
+ ] # 自己的task表也需要检查是否有任务
+ if related_redis_key:
+ self._related_task_tables.append(
+ setting.TAB_REQUESTS.format(redis_key=related_redis_key)
+ )
+
+ self._related_batch_record = related_batch_record
+ self._task_condition = task_condition
+ self._task_condition_prefix_and = task_condition and " and {}".format(
+ task_condition
+ )
+ self._task_condition_prefix_where = task_condition and " where {}".format(
+ task_condition
+ )
+ self._task_order_by = task_order_by and " order by {}".format(task_order_by)
+
+ self._is_more_parsers = True # 多模版类爬虫
+ self.reset_task()
+
+ def add_parser(self, parser, **kwargs):
+ parser = parser(
+ self._task_table,
+ self._task_state,
+ self._mysqldb,
+ **kwargs,
+ ) # parser 实例化
+ self._parsers.append(parser)
+
+ def start_monitor_task(self):
+ """
+ @summary: 监控任务状态
+ ---------
+ ---------
+ @result:
+ """
+ if not self._parsers: # 不是多模版模式, 将自己注入到parsers,自己为模版
+ self._is_more_parsers = False
+ self._parsers.append(self)
+
+ elif len(self._parsers) <= 1:
+ self._is_more_parsers = False
+
+ # 添加任务
+ for parser in self._parsers:
+ parser.add_task()
+
+ while True:
+ try:
+ # 检查redis中是否有任务 任务小于_min_task_count 则从mysql中取
+ tab_requests = setting.TAB_REQUESTS.format(redis_key=self._redis_key)
+ todo_task_count = self._redisdb.zget_count(tab_requests)
+
+ tasks = []
+ if todo_task_count < self._min_task_count:
+ tasks = self.get_task(todo_task_count)
+ if not tasks:
+ if not todo_task_count:
+ if self._keep_alive:
+ log.info("任务均已做完,爬虫常驻, 等待新任务")
+ time.sleep(self._check_task_interval)
+ continue
+ elif self.have_alive_spider():
+ log.info("任务均已做完,但还有爬虫在运行,等待爬虫结束")
+ time.sleep(self._check_task_interval)
+ continue
+ elif not self.related_spider_is_done():
+ continue
+ else:
+ log.info("任务均已做完,爬虫结束")
+ break
+
+ else:
+ log.info("redis 中尚有%s条积压任务,暂时不派发新任务" % todo_task_count)
+
+ if not tasks:
+ if todo_task_count >= self._min_task_count:
+ # log.info('任务正在进行 redis中剩余任务 %s' % todo_task_count)
+ pass
+ else:
+ log.info("无待做种子 redis中剩余任务 %s" % todo_task_count)
+ else:
+ # make start requests
+ self.distribute_task(tasks)
+ log.info(f"添加任务到redis成功 共{len(tasks)}条")
+
+ except Exception as e:
+ log.exception(e)
+
+ time.sleep(self._check_task_interval)
+
+ def get_task(self, todo_task_count) -> List[Union[Tuple, Dict]]:
+ """
+ 获取任务
+ Args:
+ todo_task_count: redis里剩余的任务数
+
+ Returns:
+
+ """
+ tasks = []
+ if self._task_table_type == "mysql":
+ # 从mysql中取任务
+ log.info("redis 中剩余任务%s 数量过小 从mysql中取任务追加" % todo_task_count)
+ tasks = self.get_todo_task_from_mysql()
+ if not tasks: # 状态为0的任务已经做完,需要检查状态为2的任务是否丢失
+ # redis 中无待做任务,此时mysql中状态为2的任务为丢失任务。需重新做
+ if todo_task_count == 0:
+ log.info("无待做任务,尝试取丢失的任务")
+ tasks = self.get_doing_task_from_mysql()
+ elif self._task_table_type == "redis":
+ log.info("redis 中剩余任务%s 数量过小 从redis种子任务表中取任务追加" % todo_task_count)
+ tasks = self.get_task_from_redis()
+ else:
+ raise Exception(
+ f"task_table_type expect mysql or redis,bug got {self._task_table_type}"
+ )
+
+ return tasks
+
+ def distribute_task(self, tasks):
+ """
+ @summary: 分发任务
+ ---------
+ @param tasks:
+ ---------
+ @result:
+ """
+ if self._is_more_parsers: # 为多模版类爬虫,需要下发指定的parser
+ for task in tasks:
+ for parser in self._parsers: # 寻找task对应的parser
+ if parser.name in task:
+ if isinstance(task, dict):
+ task = PerfectDict(_dict=task)
+ else:
+ task = PerfectDict(
+ _dict=dict(zip(self._task_keys, task)),
+ _values=list(task),
+ )
+ requests = parser.start_requests(task)
+ if requests and not isinstance(requests, Iterable):
+ raise Exception(
+ "%s.%s返回值必须可迭代" % (parser.name, "start_requests")
+ )
+
+ result_type = 1
+ for request in requests or []:
+ if isinstance(request, Request):
+ request.parser_name = request.parser_name or parser.name
+ self._request_buffer.put_request(request)
+ result_type = 1
+
+ elif isinstance(request, Item):
+ self._item_buffer.put_item(request)
+ result_type = 2
+
+ if (
+ self._item_buffer.get_items_count()
+ >= setting.ITEM_MAX_CACHED_COUNT
+ ):
+ self._item_buffer.flush()
+
+ elif callable(request): # callbale的request可能是更新数据库操作的函数
+ if result_type == 1:
+ self._request_buffer.put_request(request)
+ else:
+ self._item_buffer.put_item(request)
+
+ if (
+ self._item_buffer.get_items_count()
+ >= setting.ITEM_MAX_CACHED_COUNT
+ ):
+ self._item_buffer.flush()
+
+ else:
+ raise TypeError(
+ "start_requests yield result type error, expect Request、Item、callback func, bug get type: {}".format(
+ type(requests)
+ )
+ )
+
+ break
+
+ else: # task没对应的parser 则将task下发到所有的parser
+ for task in tasks:
+ for parser in self._parsers:
+ if isinstance(task, dict):
+ task = PerfectDict(_dict=task)
+ else:
+ task = PerfectDict(
+ _dict=dict(zip(self._task_keys, task)), _values=list(task)
+ )
+ requests = parser.start_requests(task)
+ if requests and not isinstance(requests, Iterable):
+ raise Exception(
+ "%s.%s返回值必须可迭代" % (parser.name, "start_requests")
+ )
+
+ result_type = 1
+ for request in requests or []:
+ if isinstance(request, Request):
+ request.parser_name = request.parser_name or parser.name
+ self._request_buffer.put_request(request)
+ result_type = 1
+
+ elif isinstance(request, Item):
+ self._item_buffer.put_item(request)
+ result_type = 2
+
+ if (
+ self._item_buffer.get_items_count()
+ >= setting.ITEM_MAX_CACHED_COUNT
+ ):
+ self._item_buffer.flush()
+
+ elif callable(request): # callbale的request可能是更新数据库操作的函数
+ if result_type == 1:
+ self._request_buffer.put_request(request)
+ else:
+ self._item_buffer.put_item(request)
+
+ if (
+ self._item_buffer.get_items_count()
+ >= setting.ITEM_MAX_CACHED_COUNT
+ ):
+ self._item_buffer.flush()
+
+ self._request_buffer.flush()
+ self._item_buffer.flush()
+
+ def get_task_from_redis(self):
+ tasks = self._redisdb.zget(self._task_table, count=self._task_limit)
+ tasks = [eval(task) for task in tasks]
+ return tasks
+
+ def get_todo_task_from_mysql(self):
+ """
+ @summary: 取待做的任务
+ ---------
+ ---------
+ @result:
+ """
+ # TODO 分批取数据 每批最大取 1000000个,防止内存占用过大
+ # 查询任务
+ task_keys = ", ".join([f"`{key}`" for key in self._task_keys])
+ sql = "select %s from %s where %s = 0%s%s limit %s" % (
+ task_keys,
+ self._task_table,
+ self._task_state,
+ self._task_condition_prefix_and,
+ self._task_order_by,
+ self._task_limit,
+ )
+ tasks = self._mysqldb.find(sql)
+
+ if tasks:
+ # 更新任务状态
+ for i in range(0, len(tasks), 10000): # 10000 一批量更新
+ task_ids = str(
+ tuple([task[0] for task in tasks[i : i + 10000]])
+ ).replace(",)", ")")
+ sql = "update %s set %s = 2 where id in %s" % (
+ self._task_table,
+ self._task_state,
+ task_ids,
+ )
+ self._mysqldb.update(sql)
+
+ return tasks
+
+ def get_doing_task_from_mysql(self):
+ """
+ @summary: 取正在做的任务
+ ---------
+ ---------
+ @result:
+ """
+
+ # 查询任务
+ task_keys = ", ".join([f"`{key}`" for key in self._task_keys])
+ sql = "select %s from %s where %s = 2%s%s limit %s" % (
+ task_keys,
+ self._task_table,
+ self._task_state,
+ self._task_condition_prefix_and,
+ self._task_order_by,
+ self._task_limit,
+ )
+ tasks = self._mysqldb.find(sql)
+
+ return tasks
+
+ def get_lose_task_count(self):
+ sql = "select count(1) from %s where %s = 2%s" % (
+ self._task_table,
+ self._task_state,
+ self._task_condition_prefix_and,
+ )
+ doing_count = self._mysqldb.find(sql)[0][0]
+ return doing_count
+
+ def reset_lose_task_from_mysql(self):
+ """
+ @summary: 重置丢失任务为待做
+ ---------
+ ---------
+ @result:
+ """
+
+ sql = "update {table} set {state} = 0 where {state} = 2{task_condition}".format(
+ table=self._task_table,
+ state=self._task_state,
+ task_condition=self._task_condition_prefix_and,
+ )
+ return self._mysqldb.update(sql)
+
+ def related_spider_is_done(self):
+ """
+ 相关连的爬虫是否跑完
+ @return: True / False / None 表示无相关的爬虫 可由自身的total_count 和 done_count 来判断
+ """
+
+ for related_redis_task_table in self._related_task_tables:
+ if self._redisdb.exists_key(related_redis_task_table):
+ log.info(f"依赖的爬虫还未结束,任务表为:{related_redis_task_table}")
+ return False
+
+ if self._related_batch_record:
+ sql = "select is_done from {} order by id desc limit 1".format(
+ self._related_batch_record
+ )
+ is_done = self._mysqldb.find(sql)
+ is_done = is_done[0][0] if is_done else None
+
+ if is_done is None:
+ log.warning("相关联的批次表不存在或无批次信息")
+ return True
+
+ if not is_done:
+ log.info(f"依赖的爬虫还未结束,批次表为:{self._related_batch_record}")
+ return False
+
+ return True
+
+ # -------- 批次结束逻辑 ------------
+
+ def task_is_done(self):
+ """
+ @summary: 检查种子表是否做完
+ ---------
+ ---------
+ @result: True / False (做完 / 未做完)
+ """
+ is_done = False
+ if self._task_table_type == "mysql":
+ sql = "select 1 from %s where (%s = 0 or %s=2)%s limit 1" % (
+ self._task_table,
+ self._task_state,
+ self._task_state,
+ self._task_condition_prefix_and,
+ )
+ count = self._mysqldb.find(sql) # [(1,)] / []
+ elif self._task_table_type == "redis":
+ count = self._redisdb.zget_count(self._task_table)
+ else:
+ raise Exception(
+ f"task_table_type expect mysql or redis,bug got {self._task_table_type}"
+ )
+
+ if not count:
+ log.info("种子表中任务均已完成")
+ is_done = True
+
+ return is_done
+
+ def run(self):
+ """
+ @summary: 重写run方法 检查mysql中的任务是否做完, 做完停止
+ ---------
+ ---------
+ @result:
+ """
+ try:
+ if not self.is_reach_next_spider_time():
+ return
+
+ if not self._parsers: # 不是add_parser 模式
+ self._parsers.append(self)
+
+ self._start()
+
+ while True:
+ try:
+ if self._stop_spider or (
+ self.all_thread_is_done()
+ and self.task_is_done()
+ and self.related_spider_is_done()
+ ): # redis全部的任务已经做完 并且mysql中的任务已经做完(检查各个线程all_thread_is_done,防止任务没做完,就更新任务状态,导致程序结束的情况)
+ if not self._is_notify_end:
+ self.spider_end()
+ self._is_notify_end = True
+
+ if not self._keep_alive:
+ self._stop_all_thread()
+ break
+ else:
+ log.info("常驻爬虫,等待新任务")
+ else:
+ self._is_notify_end = False
+
+ self.check_task_status()
+
+ except Exception as e:
+ log.exception(e)
+
+ tools.delay_time(10) # 10秒钟检查一次爬虫状态
+
+ except Exception as e:
+ msg = "《%s》主线程异常 爬虫结束 exception: %s" % (self.name, e)
+ log.error(msg)
+ self.send_msg(
+ msg, level="error", message_prefix="《%s》爬虫异常结束".format(self.name)
+ )
+
+ os._exit(137) # 使退出码为35072 方便爬虫管理器重启
+
+ @classmethod
+ def to_DebugTaskSpider(cls, *args, **kwargs):
+ # DebugBatchSpider 继承 cls
+ DebugTaskSpider.__bases__ = (cls,)
+ DebugTaskSpider.__name__ = cls.__name__
+ return DebugTaskSpider(*args, **kwargs)
+
+
+class DebugTaskSpider(TaskSpider):
+ """
+ Debug批次爬虫
+ """
+
+ __debug_custom_setting__ = dict(
+ COLLECTOR_TASK_COUNT=1,
+ # SPIDER
+ SPIDER_THREAD_COUNT=1,
+ SPIDER_SLEEP_TIME=0,
+ SPIDER_MAX_RETRY_TIMES=10,
+ REQUEST_LOST_TIMEOUT=600, # 10分钟
+ PROXY_ENABLE=False,
+ RETRY_FAILED_REQUESTS=False,
+ # 保存失败的request
+ SAVE_FAILED_REQUEST=False,
+ # 过滤
+ ITEM_FILTER_ENABLE=False,
+ REQUEST_FILTER_ENABLE=False,
+ OSS_UPLOAD_TABLES=(),
+ DELETE_KEYS=True,
+ )
+
+ def __init__(
+ self,
+ task_id=None,
+ task=None,
+ save_to_db=False,
+ update_task=False,
+ *args,
+ **kwargs,
+ ):
+ """
+ @param task_id: 任务id
+ @param task: 任务 task 与 task_id 二者选一即可。如 task = {"url":""}
+ @param save_to_db: 数据是否入库 默认否
+ @param update_task: 是否更新任务 默认否
+ @param args:
+ @param kwargs:
+ """
+ warnings.warn(
+ "您正处于debug模式下,该模式下不会更新任务状态及数据入库,仅用于调试。正式发布前请更改为正常模式", category=Warning
+ )
+
+ if not task and not task_id:
+ raise Exception("task_id 与 task 不能同时为空")
+
+ kwargs["redis_key"] = kwargs["redis_key"] + "_debug"
+ if not save_to_db:
+ self.__class__.__debug_custom_setting__["ITEM_PIPELINES"] = [
+ CONSOLE_PIPELINE_PATH
+ ]
+ self.__class__.__custom_setting__.update(
+ self.__class__.__debug_custom_setting__
+ )
+
+ super(DebugTaskSpider, self).__init__(*args, **kwargs)
+
+ self._task_id = task_id
+ self._task = task
+ self._update_task = update_task
+
+ def start_monitor_task(self):
+ """
+ @summary: 监控任务状态
+ ---------
+ ---------
+ @result:
+ """
+ if not self._parsers: # 不是多模版模式, 将自己注入到parsers,自己为模版
+ self._is_more_parsers = False
+ self._parsers.append(self)
+
+ elif len(self._parsers) <= 1:
+ self._is_more_parsers = False
+
+ if self._task:
+ self.distribute_task([self._task])
+ else:
+ tasks = self.get_todo_task_from_mysql()
+ if not tasks:
+ raise Exception("未获取到任务 请检查 task_id: {} 是否存在".format(self._task_id))
+ self.distribute_task(tasks)
+
+ log.debug("下发任务完毕")
+
+ def get_todo_task_from_mysql(self):
+ """
+ @summary: 取待做的任务
+ ---------
+ ---------
+ @result:
+ """
+
+ # 查询任务
+ task_keys = ", ".join([f"`{key}`" for key in self._task_keys])
+ sql = "select %s from %s where id=%s" % (
+ task_keys,
+ self._task_table,
+ self._task_id,
+ )
+ tasks = self._mysqldb.find(sql)
+
+ return tasks
+
+ def save_cached(self, request, response, table):
+ pass
+
+ def update_task_state(self, task_id, state=1, *args, **kwargs):
+ """
+ @summary: 更新任务表中任务状态,做完每个任务时代码逻辑中要主动调用。可能会重写
+ 调用方法为 yield lambda : self.update_task_state(task_id, state)
+ ---------
+ @param task_id:
+ @param state:
+ ---------
+ @result:
+ """
+ if self._update_task:
+ kwargs["id"] = task_id
+ kwargs[self._task_state] = state
+
+ sql = tools.make_update_sql(
+ self._task_table,
+ kwargs,
+ condition="id = {task_id}".format(task_id=task_id),
+ )
+
+ if self._mysqldb.update(sql):
+ log.debug("置任务%s状态成功" % task_id)
+ else:
+ log.error("置任务%s状态失败 sql=%s" % (task_id, sql))
+
+ def update_task_batch(self, task_id, state=1, *args, **kwargs):
+ """
+ 批量更新任务 多处调用,更新的字段必须一致
+ 注意:需要 写成 yield update_task_batch(...) 否则不会更新
+ @param task_id:
+ @param state:
+ @param kwargs:
+ @return:
+ """
+ if self._update_task:
+ kwargs["id"] = task_id
+ kwargs[self._task_state] = state
+
+ update_item = UpdateItem(**kwargs)
+ update_item.table_name = self._task_table
+ update_item.name_underline = self._task_table + "_item"
+
+ return update_item
+
+ def run(self):
+ self.start_monitor_task()
+
+ if not self._parsers: # 不是add_parser 模式
+ self._parsers.append(self)
+
+ self._start()
+
+ while True:
+ try:
+ if self.all_thread_is_done():
+ self._stop_all_thread()
+ break
+
+ except Exception as e:
+ log.exception(e)
+
+ tools.delay_time(1) # 1秒钟检查一次爬虫状态
+
+ self.delete_tables([self._redis_key + "*"])
diff --git a/feapder/db/memory_db.py b/feapder/db/memorydb.py
similarity index 54%
rename from feapder/db/memory_db.py
rename to feapder/db/memorydb.py
index 68e32403..99c8c7d6 100644
--- a/feapder/db/memory_db.py
+++ b/feapder/db/memorydb.py
@@ -9,18 +9,25 @@
"""
from queue import PriorityQueue
+from feapder import setting
+
class MemoryDB:
def __init__(self):
- self.priority_queue = PriorityQueue()
+ self.priority_queue = PriorityQueue(maxsize=setting.TASK_MAX_CACHED_SIZE)
- def add(self, item):
+ def add(self, item, ignore_max_size=False):
"""
添加任务
:param item: 数据: 支持小于号比较的类 或者 (priority, item)
+ :param ignore_max_size: queue满时是否等待,为True时无视队列的maxsize,直接往里塞
:return:
"""
- self.priority_queue.put(item)
+ if ignore_max_size:
+ self.priority_queue._put(item)
+ self.priority_queue.unfinished_tasks += 1
+ else:
+ self.priority_queue.put(item)
def get(self):
"""
@@ -28,7 +35,7 @@ def get(self):
:return:
"""
try:
- item = self.priority_queue.get_nowait()
+ item = self.priority_queue.get(timeout=1)
return item
except:
return
diff --git a/feapder/db/mongodb.py b/feapder/db/mongodb.py
index e826b2bb..791fe0d9 100644
--- a/feapder/db/mongodb.py
+++ b/feapder/db/mongodb.py
@@ -12,7 +12,7 @@
from urllib import parse
import pymongo
-from pymongo import MongoClient
+from pymongo import MongoClient, UpdateOne, UpdateMany
from pymongo.collection import Collection
from pymongo.database import Database
from pymongo.errors import DuplicateKeyError, BulkWriteError
@@ -23,30 +23,33 @@
class MongoDB:
def __init__(
- self,
- ip=None,
- port=None,
- db=None,
- user_name=None,
- user_pass=None,
- url=None,
- **kwargs,
+ self,
+ ip=None,
+ port=None,
+ db=None,
+ user_name=None,
+ user_pass=None,
+ url=None,
+ **kwargs,
):
+ if not ip:
+ ip = setting.MONGO_IP
+ if not port:
+ port = setting.MONGO_PORT
+ if not db:
+ db = setting.MONGO_DB
+ if not user_name:
+ user_name = setting.MONGO_USER_NAME
+ if not user_pass:
+ user_pass = setting.MONGO_USER_PASS
+ if not url:
+ url = setting.MONGO_URL
+
if url:
self.client = MongoClient(url, **kwargs)
else:
- if not ip:
- ip = setting.MONGO_IP
- if not port:
- port = setting.MONGO_PORT
- if not db:
- db = setting.MONGO_DB
- if not user_name:
- user_name = setting.MONGO_USER_NAME
- if not user_pass:
- user_pass = setting.MONGO_USER_PASS
self.client = MongoClient(
- host=ip, port=port, username=user_name, password=user_pass
+ host=ip, port=port, username=user_name, password=user_pass, **kwargs
)
self.db = self.get_database(db)
@@ -94,7 +97,7 @@ def get_collection(self, coll_name, **kwargs) -> Collection:
return self.db.get_collection(coll_name, **kwargs)
def find(
- self, coll_name: str, condition: Optional[Dict] = None, limit: int = 0, **kwargs
+ self, coll_name: str, condition: Optional[Dict] = None, limit: int = 0, **kwargs
) -> List[Dict]:
"""
@summary:
@@ -133,13 +136,13 @@ def find(
return dataset
def add(
- self,
- coll_name,
- data: Dict,
- replace=False,
- update_columns=(),
- update_columns_value=(),
- insert_ignore=False,
+ self,
+ coll_name,
+ data: Dict,
+ replace=False,
+ update_columns=(),
+ update_columns_value=(),
+ insert_ignore=False,
):
"""
添加单条数据
@@ -195,13 +198,13 @@ def add(
return affect_count
def add_batch(
- self,
- coll_name: str,
- datas: List[Dict],
- replace=False,
- update_columns=(),
- update_columns_value=(),
- condition_fields: dict = None,
+ self,
+ coll_name: str,
+ datas: List[Dict],
+ replace=False,
+ update_columns=(),
+ update_columns_value=(),
+ condition_fields: dict = None,
):
"""
批量添加数据
@@ -331,6 +334,70 @@ def update(self, coll_name, data: Dict, condition: Dict, upsert: bool = False):
else:
return True
+ def update_many(self, coll_name, data: Dict, condition: Dict, upsert: bool = False):
+ """
+ 批量更新
+ Args:
+ coll_name: 集合名
+ data: 单条数据 {"xxx":"xxx"}
+ condition: 更新条件 {"_id": "xxxx"}
+ upsert: 数据不存在则插入,默认为 False
+
+ Returns: True / False
+ """
+ try:
+ collection = self.get_collection(coll_name)
+ collection.update_many(condition, {"$set": data}, upsert=upsert)
+ except Exception as e:
+ log.error(
+ """
+ error:{}
+ condition: {}
+ """.format(
+ e, condition
+ )
+ )
+ return False
+ else:
+ return True
+
+ def update_batch(
+ self,
+ coll_name: str,
+ update_data_list: List[Dict],
+ condition_field: str,
+ upsert: bool = False,
+ ):
+ """
+ 批量更新数据
+ Args:
+ coll_name: 集合名
+ update_data_list: 更新数据列表
+ condition_field: 更新条件字段
+ upsert: 数据不存在则插入,默认为 False
+
+ Returns: 更新行数
+
+ """
+ if not update_data_list:
+ return 0
+
+ collection = self.get_collection(coll_name)
+ bulk_operations = []
+
+ for update_data in update_data_list:
+ condition = {condition_field: update_data.get(condition_field)}
+ update_operation = UpdateMany(
+ condition, {"$set": update_data}, upsert=upsert
+ )
+ bulk_operations.append(update_operation)
+ try:
+ result = collection.bulk_write(bulk_operations, ordered=False)
+ return result.modified_count + result.upserted_count
+ except BulkWriteError as e:
+ log.error(f"Bulk write error: {e.details}")
+ return 0
+
def delete(self, coll_name, condition: Dict) -> bool:
"""
删除
@@ -401,7 +468,7 @@ def get_index_key(self, coll_name, index_name):
return index_keys
def __get_update_condition(
- self, coll_name: str, data: dict, duplicate_errmsg: str
+ self, coll_name: str, data: dict, duplicate_errmsg: str
) -> dict:
"""
根据索引冲突的报错信息 获取更新条件
@@ -420,3 +487,15 @@ def __get_update_condition(
def __getattr__(self, name):
return getattr(self.db, name)
+
+
+if __name__ == "__main__":
+ update_data_list = [{"_id": "1", "status": 1}, {"_id": "2", "status": 1}]
+ mongo = MongoDB()
+ updated_count = mongo.update_batch("your_table_name", update_data_list, "_id")
+ print(f"Updated {updated_count} documents.")
+
+ id_list = ["1", "2"]
+ result = mongo.update_many(
+ "your_table_name", {"status": 1}, {"_id": {"$in": id_list}}
+ )
diff --git a/feapder/db/mysqldb.py b/feapder/db/mysqldb.py
index 2cda366c..9043bafe 100644
--- a/feapder/db/mysqldb.py
+++ b/feapder/db/mysqldb.py
@@ -41,7 +41,7 @@ def wapper(*args, **kwargs):
class MysqlDB:
def __init__(
- self, ip=None, port=None, db=None, user_name=None, user_pass=None, **kwargs
+ self, ip=None, port=None, db=None, user_name=None, user_pass=None, charset="utf8mb4", set_session=None, **kwargs
):
# 可能会改setting中的值,所以此处不能直接赋值为默认值,需要后加载赋值
if not ip:
@@ -68,8 +68,10 @@ def __init__(
user=user_name,
passwd=user_pass,
db=db,
- charset="utf8mb4",
+ charset=charset,
+ setsession=set_session,
cursorclass=cursors.SSCursor,
+ **kwargs
) # cursorclass 使用服务的游标,默认的在多线程下大批量插入数据会使内存递增
except Exception as e:
@@ -83,7 +85,7 @@ def __init__(
user_pass: {}
exception: {}
""".format(
- ip, port, db, user_name, user_pass, e
+ ip, port, db, user_name, user_pass, charset, e
)
)
else:
@@ -91,7 +93,15 @@ def __init__(
@classmethod
def from_url(cls, url, **kwargs):
- # mysql://username:password@ip:port/db?charset=utf8mb4
+ """
+
+ Args:
+ url: mysql://username:password@ip:port/db?charset=utf8mb4
+ **kwargs:
+
+ Returns:
+
+ """
url_parsed = parse.urlparse(url)
db_type = url_parsed.scheme.strip()
@@ -109,7 +119,9 @@ def from_url(cls, url, **kwargs):
"user_pass": url_parsed.password.strip(),
"db": url_parsed.path.strip("/").strip(),
}
-
+ # 解析 query 字符串参数,比如 ?charset=utf8
+ query_params = dict(parse.parse_qsl(url_parsed.query))
+ connect_params.update(query_params)
connect_params.update(kwargs)
return cls(**connect_params)
@@ -137,8 +149,10 @@ def get_connection(self):
return conn, cursor
def close_connection(self, conn, cursor):
- cursor.close()
- conn.close()
+ if conn:
+ conn.close()
+ if cursor:
+ cursor.close()
def size_of_connections(self):
"""
@@ -155,7 +169,7 @@ def size_of_connect_pool(self):
return len(self.connect_pool._idle_cache)
@auto_retry
- def find(self, sql, limit=0, to_json=False):
+ def find(self, sql, limit=0, to_json=False, conver_col=True):
"""
@summary:
无数据: 返回()
@@ -165,6 +179,7 @@ def find(self, sql, limit=0, to_json=False):
@param sql:
@param limit:
@param to_json 是否将查询结果转为json
+ @param conver_col 是否处理查询结果,如date类型转字符串,json字符串转成json。仅当to_json=True时生效
---------
@result:
"""
@@ -179,7 +194,7 @@ def find(self, sql, limit=0, to_json=False):
else:
result = cursor.fetchall()
- if to_json:
+ if to_json and result:
columns = [i[0] for i in cursor.description]
# 处理数据
@@ -187,7 +202,7 @@ def convert(col):
if isinstance(col, (datetime.date, datetime.time)):
return str(col)
elif isinstance(col, str) and (
- col.startswith("{") or col.startswith("[")
+ col.startswith("{") or col.startswith("[")
):
try:
# col = self.unescape_string(col)
@@ -199,10 +214,12 @@ def convert(col):
return col
if limit == 1:
- result = [convert(col) for col in result]
+ if conver_col:
+ result = [convert(col) for col in result]
result = dict(zip(columns, result))
else:
- result = [[convert(col) for col in row] for row in result]
+ if conver_col:
+ result = [[convert(col) for col in row] for row in result]
result = [dict(zip(columns, r)) for r in result]
self.close_connection(conn, cursor)
@@ -220,6 +237,7 @@ def add(self, sql, exception_callfunc=None):
"""
affect_count = None
+ conn, cursor = None, None
try:
conn, cursor = self.get_connection()
@@ -255,16 +273,18 @@ def add_smart(self, table, data: Dict, **kwargs):
sql = make_insert_sql(table, data, **kwargs)
return self.add(sql)
- def add_batch(self, sql, datas: List[Dict]):
+ def add_batch(self, sql, datas: List[List]):
"""
@summary: 批量添加数据
---------
- @ param sql: insert ignore into (xxx,xxx) values (%s, %s, %s)
- # param datas: 列表 [{}, {}, {}]
+ @ param sql: insert ignore into (xxx,xxx,xxx) values (%s, %s, %s)
+ @ param datas: 列表 [[v1,v2,v3], [v1,v2,v3]]
+ 列表里的值要和插入的key的顺序对应上
---------
@result: 添加行数
"""
affect_count = None
+ conn, cursor = None, None
try:
conn, cursor = self.get_connection()
@@ -284,7 +304,7 @@ def add_batch(self, sql, datas: List[Dict]):
return affect_count
- def add_batch_smart(self, table, datas: List[Dict], **kwargs):
+ def add_batch_smart(self, table, datas: List[Dict], **kwargs) -> int:
"""
批量添加数据, 直接传递list格式的数据,不用拼sql
Args:
@@ -298,12 +318,14 @@ def add_batch_smart(self, table, datas: List[Dict], **kwargs):
sql, datas = make_batch_sql(table, datas, **kwargs)
return self.add_batch(sql, datas)
- def update(self, sql):
+ def update(self, sql) -> int:
+ affect_count = None
+ conn, cursor = None, None
+
try:
conn, cursor = self.get_connection()
- cursor.execute(sql)
+ affect_count = cursor.execute(sql)
conn.commit()
-
except Exception as e:
log.error(
"""
@@ -312,13 +334,12 @@ def update(self, sql):
"""
% (e, sql)
)
- return False
- else:
- return True
finally:
self.close_connection(conn, cursor)
- def update_smart(self, table, data: Dict, condition):
+ return affect_count
+
+ def update_smart(self, table, data: Dict, condition) -> int:
"""
更新, 不用拼sql
Args:
@@ -326,26 +347,27 @@ def update_smart(self, table, data: Dict, condition):
data: 数据 {"xxx":"xxx"}
condition: 更新条件 where后面的条件,如 condition='status=1'
- Returns: True / False
+ Returns: 影响行数
"""
sql = make_update_sql(table, data, condition)
return self.update(sql)
- def delete(self, sql):
+ def delete(self, sql) -> int:
"""
删除
Args:
sql:
- Returns: True / False
+ Returns: 影响行数
"""
+ affect_count = None
+ conn, cursor = None, None
try:
conn, cursor = self.get_connection()
- cursor.execute(sql)
+ affect_count = cursor.execute(sql)
conn.commit()
-
except Exception as e:
log.error(
"""
@@ -354,18 +376,25 @@ def delete(self, sql):
"""
% (e, sql)
)
- return False
- else:
- return True
finally:
self.close_connection(conn, cursor)
- def execute(self, sql):
+ return affect_count
+
+ def execute(self, sql) -> int:
+ """
+
+ Args:
+ sql:
+
+ Returns: 影响行数
+ """
+ affect_count = None
+ conn, cursor = None, None
try:
conn, cursor = self.get_connection()
- cursor.execute(sql)
+ affect_count = cursor.execute(sql)
conn.commit()
-
except Exception as e:
log.error(
"""
@@ -374,8 +403,7 @@ def execute(self, sql):
"""
% (e, sql)
)
- return False
- else:
- return True
finally:
self.close_connection(conn, cursor)
+
+ return affect_count
diff --git a/feapder/db/redisdb.py b/feapder/db/redisdb.py
index 5b5f7436..d882e687 100644
--- a/feapder/db/redisdb.py
+++ b/feapder/db/redisdb.py
@@ -6,16 +6,15 @@
---------
@author: Boris
"""
-
+import os
import time
+from typing import Union, List
import redis
-from redis._compat import unicode, long, basestring
from redis.connection import Encoder as _Encoder
from redis.exceptions import ConnectionError, TimeoutError
from redis.exceptions import DataError
from redis.sentinel import Sentinel
-from rediscluster import RedisCluster
import feapder.setting as setting
from feapder.utils.log import log
@@ -34,19 +33,19 @@ def encode(self, value):
# )
elif isinstance(value, float):
value = repr(value).encode()
- elif isinstance(value, (int, long)):
+ elif isinstance(value, int):
# python 2 repr() on longs is '123L', so use str() instead
value = str(value).encode()
elif isinstance(value, (list, dict, tuple)):
- value = unicode(value)
- elif not isinstance(value, basestring):
+ value = str(value)
+ elif not isinstance(value, str):
# a value we don't know how to deal with. throw an error
typename = type(value).__name__
raise DataError(
"Invalid input of type: '%s'. Convert to a "
"bytes, string, int or float first." % typename
)
- if isinstance(value, unicode):
+ if isinstance(value, str):
value = value.encode(self.encoding, self.encoding_errors)
return value
@@ -63,7 +62,7 @@ def __init__(
url=None,
decode_responses=True,
service_name=None,
- max_connections=32,
+ max_connections=1000,
**kwargs,
):
"""
@@ -75,6 +74,7 @@ def __init__(
url:
decode_responses:
service_name: 适用于redis哨兵模式
+ max_connections: 同一个redis对象使用的并发数(连接池的最大连接数),超过这个数量会抛出redis.ConnectionError
"""
# 可能会改setting中的值,所以此处不能直接赋值为默认值,需要后加载赋值
@@ -86,6 +86,8 @@ def __init__(
user_pass = setting.REDISDB_USER_PASS
if service_name is None:
service_name = setting.REDISDB_SERVICE_NAME
+ if kwargs is None:
+ kwargs = setting.REDISDB_KWARGS
self._is_redis_cluster = False
@@ -155,6 +157,12 @@ def get_connect(self):
)
else:
+ try:
+ from rediscluster import RedisCluster
+ except ModuleNotFoundError as e:
+ log.error('请安装 pip install "feapder[all]"')
+ os._exit(0)
+
# log.debug("使用redis集群模式")
self._redis = RedisCluster(
startup_nodes=startup_nodes,
@@ -179,7 +187,7 @@ def get_connect(self):
self._is_redis_cluster = False
else:
self._redis = redis.StrictRedis.from_url(
- self._url, decode_responses=self._decode_responses
+ self._url, decode_responses=self._decode_responses, **self._kwargs
)
self._is_redis_cluster = False
@@ -582,18 +590,17 @@ def zexists(self, table, values):
return is_exists
def lpush(self, table, values):
-
if isinstance(values, list):
pipe = self._redis.pipeline()
if not self._is_redis_cluster:
pipe.multi()
for value in values:
- pipe.rpush(table, value)
+ pipe.lpush(table, value)
pipe.execute()
else:
- return self._redis.rpush(table, values)
+ return self._redis.lpush(table, values)
def lpop(self, table, count=1):
"""
@@ -606,8 +613,8 @@ def lpop(self, table, count=1):
"""
datas = None
-
- count = count if count <= self.lget_count(table) else self.lget_count(table)
+ lcount = self.lget_count(table)
+ count = count if count <= lcount else lcount
if count:
if count > 1:
@@ -737,27 +744,41 @@ def hget_count(self, table):
def hkeys(self, table):
return self._redis.hkeys(table)
- def setbit(self, table, offsets, values):
+ def hvals(self, key):
+ return self._redis.hvals(key)
+
+ def setbit(
+ self, table, offsets: Union[int, List[int]], values: Union[int, List[int]]
+ ):
"""
- 设置字符串数组某一位的值, 返回之前的值
- @param table:
+ 设置字符串数组某一位的值,返回之前的值
+ @param table: Redis key
@param offsets: 支持列表或单个值
@param values: 支持列表或单个值
@return: list / 单个值
"""
if isinstance(offsets, list):
- if not isinstance(values, list):
- values = [values] * len(offsets)
+ if isinstance(values, int):
+ # 使用lua脚本,数据是一起传给redis的,降低了网络开销,但redis会阻塞
+ script = """
+ local value = table.remove(ARGV, 1)
+ local offsets = ARGV
+ local results = {}
+ for i, offset in ipairs(offsets) do
+ results[i] = redis.call('SETBIT', KEYS[1], offset, value)
+ end
+ return results
+ """
+ return self._redis.eval(script, 1, table, values, *offsets)
else:
assert len(offsets) == len(values), "offsets值要与values值一一对应"
+ pipe = self._redis.pipeline()
+ pipe.multi()
- pipe = self._redis.pipeline()
- pipe.multi()
-
- for offset, value in zip(offsets, values):
- pipe.setbit(table, offset, value)
+ for offset, value in zip(offsets, values):
+ pipe.setbit(table, offset, value)
- return pipe.execute()
+ return pipe.execute()
else:
return self._redis.setbit(table, offsets, values)
@@ -784,6 +805,20 @@ def bitcount(self, table):
return self._redis.bitcount(table)
def strset(self, table, value, **kwargs):
+ """
+ 设置键值
+ Args:
+ table:
+ value:
+ **kwargs:
+ ex: Union[None, int, timedelta] = ..., 设置键的过期时间为 second 秒
+ px: Union[None, int, timedelta] = ..., 设置键的过期时间为 millisecond 毫秒
+ nx: bool = ..., 只有键不存在时,才对键进行设置操作
+ xx: bool = ..., 只有键已经存在时,才对键进行设置操作
+ keepttl: bool = ..., 保留键的过期时间
+ Returns:
+
+ """
return self._redis.set(table, value, **kwargs)
def str_incrby(self, table, value):
diff --git a/feapder/dedup/__init__.py b/feapder/dedup/__init__.py
index 817e244e..6b67ca4a 100644
--- a/feapder/dedup/__init__.py
+++ b/feapder/dedup/__init__.py
@@ -14,16 +14,18 @@
from feapder.utils.tools import get_md5
from .bloomfilter import BloomFilter, ScalableBloomFilter
from .expirefilter import ExpireFilter
+from .litefilter import LiteFilter
class Dedup:
BloomFilter = 1
MemoryFilter = 2
ExpireFilter = 3
+ LiteFilter = 4
def __init__(self, filter_type: int = BloomFilter, to_md5: bool = True, **kwargs):
"""
- 去重过滤器 集成BloomFilter、MemoryFilter、ExpireFilter
+ 去重过滤器 集成BloomFilter、MemoryFilter、ExpireFilter、MemoryLiteFilter
Args:
filter_type: 过滤器类型 BloomFilter
name: 过滤器名称 该名称会默认以dedup作为前缀 dedup:expire_set:[name]/dedup:bloomfilter:[name]。 默认ExpireFilter name=过期时间; BloomFilter name=dedup:bloomfilter:bloomfilter
@@ -57,6 +59,9 @@ def __init__(self, filter_type: int = BloomFilter, to_md5: bool = True, **kwargs
redis_url=kwargs.get("redis_url"),
)
+ elif filter_type == Dedup.LiteFilter:
+ self.dedup = LiteFilter()
+
else:
initial_capacity = kwargs.get("initial_capacity", 100000000)
error_rate = kwargs.get("error_rate", 0.00001)
diff --git a/feapder/dedup/basefilter.py b/feapder/dedup/basefilter.py
new file mode 100644
index 00000000..f221ba1d
--- /dev/null
+++ b/feapder/dedup/basefilter.py
@@ -0,0 +1,41 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/9/21 11:17 AM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+import abc
+from typing import List, Union
+
+
+class BaseFilter:
+ @abc.abstractmethod
+ def add(
+ self, keys: Union[List[str], str], *args, **kwargs
+ ) -> Union[List[bool], bool]:
+ """
+
+ Args:
+ keys: list / 单个值
+ *args:
+ **kwargs:
+
+ Returns:
+ list / 单个值 (如果数据已存在 返回 0 否则返回 1, 可以理解为是否添加成功)
+ """
+ pass
+
+ @abc.abstractmethod
+ def get(self, keys: Union[List[str], str]) -> Union[List[bool], bool]:
+ """
+ 检查数据是否存在
+ Args:
+ keys: list / 单个值
+
+ Returns:
+ list / 单个值 (如果数据已存在 返回 1 否则返回 0)
+ """
+ pass
diff --git a/feapder/dedup/bitarray.py b/feapder/dedup/bitarray.py
index 649cf4fb..348ceb46 100644
--- a/feapder/dedup/bitarray.py
+++ b/feapder/dedup/bitarray.py
@@ -48,7 +48,7 @@ def __init__(self, num_bits):
import bitarray
except Exception as e:
raise Exception(
- "需要安装feapder完整版\ncommand: pip install feapder[all]\n若安装出错,参考:https://boris.org.cn/feapder/#/question/%E5%AE%89%E8%A3%85%E9%97%AE%E9%A2%98"
+ '需要安装feapder完整版\ncommand: pip install "feapder[all]"\n若安装出错,参考:https://feapder.com/#/question/%E5%AE%89%E8%A3%85%E9%97%AE%E9%A2%98'
)
self.num_bits = num_bits
@@ -127,7 +127,18 @@ def set(self, offsets, values):
@param values: 支持列表或单个值
@return: list / 单个值
"""
- return self.redis_db.setbit(self.name, offsets, values)
+ # 对offsets进行分片,最大100000个
+ results = []
+ batch_size = 170000
+ for i in range(0, len(offsets), batch_size):
+ results.extend(
+ self.redis_db.setbit(
+ self.name,
+ offsets[i : i + batch_size],
+ values[i : i + batch_size] if isinstance(values, list) else values,
+ )
+ )
+ return results
def get(self, offsets):
return self.redis_db.getbit(self.name, offsets)
@@ -138,6 +149,6 @@ def count(self, value=True):
if count:
return int(count)
else:
- count = self.redis_db.bitcount(self.name)
+ count = self.redis_db.bitcount(self.name) # 被设置为 1 的比特位的数量
self.redis_db.strset(self.count_cached_name, count, ex=1800) # 半小时过期
return count
diff --git a/feapder/dedup/bloomfilter.py b/feapder/dedup/bloomfilter.py
index 924f98ac..0e1af813 100644
--- a/feapder/dedup/bloomfilter.py
+++ b/feapder/dedup/bloomfilter.py
@@ -14,6 +14,7 @@
import time
from struct import unpack, pack
+from feapder.dedup.basefilter import BaseFilter
from feapder.utils.redis_lock import RedisLock
from . import bitarray
@@ -145,24 +146,18 @@ def is_at_capacity(self):
比较耗时 半小时检查一次
@return:
"""
- # if self._is_at_capacity:
- # return self._is_at_capacity
- #
- # if not self._check_capacity_time or time.time() - self._check_capacity_time > 1800:
- # bit_count = self.bitarray.count()
- # if bit_count and bit_count / self.num_bits > 0.5:
- # self._is_at_capacity = True
- #
- # self._check_capacity_time = time.time()
- #
- # return self._is_at_capacity
-
if self._is_at_capacity:
return self._is_at_capacity
- bit_count = self.bitarray.count()
- if bit_count and bit_count / self.num_bits > 0.5:
- self._is_at_capacity = True
+ if (
+ not self._check_capacity_time
+ or time.time() - self._check_capacity_time > 1800
+ ):
+ bit_count = self.bitarray.count()
+ if bit_count and bit_count / self.num_bits > 0.5:
+ self._is_at_capacity = True
+
+ self._check_capacity_time = time.time()
return self._is_at_capacity
@@ -173,8 +168,8 @@ def add(self, keys):
@param keys: list or one key
@return:
"""
- if self.is_at_capacity:
- raise IndexError("BloomFilter is at capacity")
+ # if self.is_at_capacity:
+ # raise IndexError("BloomFilter is at capacity")
is_list = isinstance(keys, list)
@@ -196,7 +191,7 @@ def add(self, keys):
return is_added if is_list else is_added[0]
-class ScalableBloomFilter(object):
+class ScalableBloomFilter(BaseFilter):
"""
自动扩展空间的bloomfilter, 当一个filter满一半的时候,创建下一个
"""
diff --git a/feapder/dedup/expirefilter.py b/feapder/dedup/expirefilter.py
index 2c7d517c..12a4b12d 100644
--- a/feapder/dedup/expirefilter.py
+++ b/feapder/dedup/expirefilter.py
@@ -11,9 +11,10 @@
import time
from feapder.db.redisdb import RedisDB
+from feapder.dedup.basefilter import BaseFilter
-class ExpireFilter:
+class ExpireFilter(BaseFilter):
redis_db = None
def __init__(
@@ -55,7 +56,17 @@ def add(self, keys, *args, **kwargs):
return is_added
def get(self, keys):
- return self.redis_db.zexists(self.name, keys)
+ is_exist = self.redis_db.zexists(self.name, keys)
+ if isinstance(keys, list):
+ # 判断数据本身是否重复
+ temp_set = set()
+ for i, key in enumerate(keys):
+ if key in temp_set:
+ is_exist[i] = 1
+ else:
+ temp_set.add(key)
+
+ return is_exist
def del_expire_key(self):
self.redis_db.zremrangebyscore(
diff --git a/feapder/dedup/litefilter.py b/feapder/dedup/litefilter.py
new file mode 100644
index 00000000..da664190
--- /dev/null
+++ b/feapder/dedup/litefilter.py
@@ -0,0 +1,70 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/9/21 11:28 AM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+from typing import List, Union, Set
+
+from feapder.dedup.basefilter import BaseFilter
+
+
+class LiteFilter(BaseFilter):
+ def __init__(self):
+ self.datas: Set[str] = set()
+
+ def add(
+ self, keys: Union[List[str], str], *args, **kwargs
+ ) -> Union[List[int], int]:
+ """
+
+ Args:
+ keys: list / 单个值
+ *args:
+ **kwargs:
+
+ Returns:
+ list / 单个值 (如果数据已存在 返回 0 否则返回 1, 可以理解为是否添加成功)
+ """
+ if isinstance(keys, list):
+ is_add = []
+ for key in keys:
+ if key not in self.datas:
+ self.datas.add(key)
+ is_add.append(1)
+ else:
+ is_add.append(0)
+ else:
+ if keys not in self.datas:
+ is_add = 1
+ self.datas.add(keys)
+ else:
+ is_add = 0
+ return is_add
+
+ def get(self, keys: Union[List[str], str]) -> Union[List[int], int]:
+ """
+ 检查数据是否存在
+ Args:
+ keys: list / 单个值
+
+ Returns:
+ list / 单个值 (如果数据已存在 返回 1 否则返回 0)
+ """
+ if isinstance(keys, list):
+ temp_set = set()
+ is_exist = []
+ for key in keys:
+ # 数据本身重复或者数据在去重库里
+ if key in temp_set or key in self.datas:
+ is_exist.append(1)
+ else:
+ is_exist.append(0)
+ temp_set.add(key)
+
+ return is_exist
+ else:
+ return int(keys in self.datas)
diff --git a/feapder/network/downloader/__init__.py b/feapder/network/downloader/__init__.py
new file mode 100644
index 00000000..f036271e
--- /dev/null
+++ b/feapder/network/downloader/__init__.py
@@ -0,0 +1,12 @@
+from ._requests import RequestsDownloader
+from ._requests import RequestsSessionDownloader
+
+# 下面是非必要依赖
+try:
+ from ._selenium import SeleniumDownloader
+except ModuleNotFoundError:
+ pass
+try:
+ from ._playwright import PlaywrightDownloader
+except ModuleNotFoundError:
+ pass
diff --git a/feapder/network/downloader/_playwright.py b/feapder/network/downloader/_playwright.py
new file mode 100644
index 00000000..facc75cd
--- /dev/null
+++ b/feapder/network/downloader/_playwright.py
@@ -0,0 +1,105 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/9/7 4:05 PM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import feapder.setting as setting
+import feapder.utils.tools as tools
+from feapder.network.downloader.base import RenderDownloader
+from feapder.network.response import Response
+from feapder.utils.webdriver import WebDriverPool, PlaywrightDriver
+
+
+class PlaywrightDownloader(RenderDownloader):
+ webdriver_pool: WebDriverPool = None
+
+ @property
+ def _webdriver_pool(self):
+ if not self.__class__.webdriver_pool:
+ self.__class__.webdriver_pool = WebDriverPool(
+ **setting.PLAYWRIGHT, driver_cls=PlaywrightDriver, thread_safe=True
+ )
+
+ return self.__class__.webdriver_pool
+
+ def download(self, request) -> Response:
+ # 代理优先级 自定义 > 配置文件 > 随机
+ if request.custom_proxies:
+ proxy = request.get_proxy()
+ elif setting.PLAYWRIGHT.get("proxy"):
+ proxy = setting.PLAYWRIGHT.get("proxy")
+ else:
+ proxy = request.get_proxy()
+
+ # user_agent优先级 自定义 > 配置文件 > 随机
+ if request.custom_ua:
+ user_agent = request.get_user_agent()
+ elif setting.PLAYWRIGHT.get("user_agent"):
+ user_agent = setting.PLAYWRIGHT.get("user_agent")
+ else:
+ user_agent = request.get_user_agent()
+
+ cookies = request.get_cookies()
+ url = request.url
+ render_time = request.render_time or setting.PLAYWRIGHT.get("render_time")
+ wait_until = setting.PLAYWRIGHT.get("wait_until") or "domcontentloaded"
+ if request.get_params():
+ url = tools.joint_url(url, request.get_params())
+
+ driver: PlaywrightDriver = self._webdriver_pool.get(
+ user_agent=user_agent, proxy=proxy
+ )
+ try:
+ if cookies:
+ driver.url = url
+ driver.cookies = cookies
+ http_response = driver.page.goto(url, wait_until=wait_until)
+ status_code = http_response.status
+
+ if render_time:
+ tools.delay_time(render_time)
+
+ html = driver.page.content()
+ response = Response.from_dict(
+ {
+ "url": driver.page.url,
+ "cookies": driver.cookies,
+ "_content": html.encode(),
+ "status_code": status_code,
+ "elapsed": 666,
+ "headers": {
+ "User-Agent": driver.user_agent,
+ "Cookie": tools.cookies2str(driver.cookies),
+ },
+ }
+ )
+
+ response.driver = driver
+ response.browser = driver
+ return response
+ except Exception as e:
+ self._webdriver_pool.remove(driver)
+ raise e
+
+ def close(self, driver):
+ if driver:
+ self._webdriver_pool.remove(driver)
+
+ def put_back(self, driver):
+ """
+ 释放浏览器对象
+ """
+ self._webdriver_pool.put(driver)
+
+ def close_all(self):
+ """
+ 关闭所有浏览器
+ """
+ # 不支持
+ # self._webdriver_pool.close()
+ pass
diff --git a/feapder/network/downloader/_requests.py b/feapder/network/downloader/_requests.py
new file mode 100644
index 00000000..15342f93
--- /dev/null
+++ b/feapder/network/downloader/_requests.py
@@ -0,0 +1,46 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/4/10 5:57 下午
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import requests
+from requests.adapters import HTTPAdapter
+
+from feapder.network.downloader.base import Downloader
+from feapder.network.response import Response
+
+
+class RequestsDownloader(Downloader):
+ def download(self, request) -> Response:
+ response = requests.request(
+ request.method, request.url, **request.requests_kwargs
+ )
+ response = Response(response)
+ return response
+
+
+class RequestsSessionDownloader(Downloader):
+ session = None
+
+ @property
+ def _session(self):
+ if not self.__class__.session:
+ self.__class__.session = requests.Session()
+ # pool_connections – 缓存的 urllib3 连接池个数 pool_maxsize – 连接池中保存的最大连接数
+ http_adapter = HTTPAdapter(pool_connections=1000, pool_maxsize=1000)
+ # 任何使用该session会话的 HTTP 请求,只要其 URL 是以给定的前缀开头,该传输适配器就会被使用到。
+ self.__class__.session.mount("http", http_adapter)
+
+ return self.__class__.session
+
+ def download(self, request) -> Response:
+ response = self._session.request(
+ request.method, request.url, **request.requests_kwargs
+ )
+ response = Response(response)
+ return response
diff --git a/feapder/network/downloader/_selenium.py b/feapder/network/downloader/_selenium.py
new file mode 100644
index 00000000..682158da
--- /dev/null
+++ b/feapder/network/downloader/_selenium.py
@@ -0,0 +1,102 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/7/26 4:28 下午
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import feapder.setting as setting
+import feapder.utils.tools as tools
+from feapder.network.downloader.base import RenderDownloader
+from feapder.network.response import Response
+from feapder.utils.webdriver import WebDriverPool, SeleniumDriver
+
+
+class SeleniumDownloader(RenderDownloader):
+ webdriver_pool: WebDriverPool = None
+
+ @property
+ def _webdriver_pool(self):
+ if not self.__class__.webdriver_pool:
+ self.__class__.webdriver_pool = WebDriverPool(
+ **setting.WEBDRIVER, driver=SeleniumDriver
+ )
+
+ return self.__class__.webdriver_pool
+
+ def download(self, request) -> Response:
+ # 代理优先级 自定义 > 配置文件 > 随机
+ if request.custom_proxies:
+ proxy = request.get_proxy()
+ elif setting.WEBDRIVER.get("proxy"):
+ proxy = setting.WEBDRIVER.get("proxy")
+ else:
+ proxy = request.get_proxy()
+
+ # user_agent优先级 自定义 > 配置文件 > 随机
+ if request.custom_ua:
+ user_agent = request.get_user_agent()
+ elif setting.WEBDRIVER.get("user_agent"):
+ user_agent = setting.WEBDRIVER.get("user_agent")
+ else:
+ user_agent = request.get_user_agent()
+
+ cookies = request.get_cookies()
+ url = request.url
+ render_time = request.render_time or setting.WEBDRIVER.get("render_time")
+ if request.get_params():
+ url = tools.joint_url(url, request.get_params())
+
+ browser: SeleniumDriver = self._webdriver_pool.get(
+ user_agent=user_agent, proxy=proxy
+ )
+ try:
+ browser.get(url)
+ if cookies:
+ browser.cookies = cookies
+ # 刷新使cookie生效
+ browser.get(url)
+
+ if render_time:
+ tools.delay_time(render_time)
+
+ html = browser.page_source
+ response = Response.from_dict(
+ {
+ "url": browser.current_url,
+ "cookies": browser.cookies,
+ "_content": html.encode(),
+ "status_code": 200,
+ "elapsed": 666,
+ "headers": {
+ "User-Agent": browser.user_agent,
+ "Cookie": tools.cookies2str(browser.cookies),
+ },
+ }
+ )
+
+ response.driver = browser
+ response.browser = browser
+ return response
+ except Exception as e:
+ self._webdriver_pool.remove(browser)
+ raise e
+
+ def close(self, driver):
+ if driver:
+ self._webdriver_pool.remove(driver)
+
+ def put_back(self, driver):
+ """
+ 释放浏览器对象
+ """
+ self._webdriver_pool.put(driver)
+
+ def close_all(self):
+ """
+ 关闭所有浏览器
+ """
+ self._webdriver_pool.close()
diff --git a/feapder/network/downloader/base.py b/feapder/network/downloader/base.py
new file mode 100644
index 00000000..ff0fc3b4
--- /dev/null
+++ b/feapder/network/downloader/base.py
@@ -0,0 +1,41 @@
+import abc
+from abc import ABC
+
+from feapder.network.response import Response
+
+
+class Downloader:
+ @abc.abstractmethod
+ def download(self, request) -> Response:
+ """
+
+ Args:
+ request: feapder.Request
+
+ Returns: feapder.Response
+
+ """
+ raise NotImplementedError
+
+ def close(self, response: Response):
+ pass
+
+
+class RenderDownloader(Downloader, ABC):
+ def put_back(self, driver):
+ """
+ 释放浏览器对象
+ """
+ pass
+
+ def close(self, driver):
+ """
+ 关闭浏览器
+ """
+ pass
+
+ def close_all(self):
+ """
+ 关闭所有浏览器
+ """
+ pass
diff --git a/feapder/network/item.py b/feapder/network/item.py
index e7b9cf34..33eae79c 100644
--- a/feapder/network/item.py
+++ b/feapder/network/item.py
@@ -9,6 +9,7 @@
"""
import re
+from typing import List
import feapder.utils.tools as tools
@@ -20,12 +21,14 @@ def __new__(cls, name, bases, attrs):
attrs.setdefault("__name_underline__", None)
attrs.setdefault("__update_key__", None)
attrs.setdefault("__unique_key__", None)
+ attrs.setdefault("__pipelines__", None)
return type.__new__(cls, name, bases, attrs)
class Item(metaclass=ItemMetaclass):
- __unique_key__ = []
+ __unique_key__: List = []
+ __pipelines__: List = None
def __init__(self, **kwargs):
self.__dict__ = kwargs
@@ -39,6 +42,20 @@ def __getitem__(self, key):
def __setitem__(self, key, value):
self.__dict__[key] = value
+ def update(self, *args, **kwargs):
+ """
+ 更新字段,与字典使用方法一致
+ """
+ self.__dict__.update(*args, **kwargs)
+
+ def update_strict(self, *args, **kwargs):
+ """
+ 更新严格更新,只更新item中有的字段
+ """
+ for key, value in dict(*args, **kwargs).items():
+ if key in self.__dict__:
+ self.__dict__[key] = value
+
def pre_to_db(self):
"""
入库前的处理
@@ -50,11 +67,12 @@ def to_dict(self):
propertys = {}
for key, value in self.__dict__.items():
if key not in (
- "__name__",
- "__table_name__",
- "__name_underline__",
- "__update_key__",
- "__unique_key__",
+ "__name__",
+ "__table_name__",
+ "__name_underline__",
+ "__update_key__",
+ "__unique_key__",
+ "__pipelines__",
):
if key.startswith(f"_{self.__class__.__name__}"):
key = key.replace(f"_{self.__class__.__name__}", "")
@@ -109,13 +127,24 @@ def unique_key(self, keys):
else:
self.__unique_key__ = (keys,)
+ @property
+ def pipelines(self):
+ return self.__pipelines__ or self.__class__.__pipelines__
+
+ @pipelines.setter
+ def pipelines(self, pipelines):
+ if isinstance(pipelines, (tuple, list)):
+ self.__pipelines__ = pipelines
+ else:
+ self.__pipelines__ = (pipelines,)
+
@property
def fingerprint(self):
args = []
for key, value in self.to_dict.items():
if value:
if (self.unique_key and key in self.unique_key) or not self.unique_key:
- args.append(str(value))
+ args.append(key + str(value))
if args:
args = sorted(args)
diff --git a/feapder/network/proxy_pool/__init__.py b/feapder/network/proxy_pool/__init__.py
new file mode 100644
index 00000000..0a6935b6
--- /dev/null
+++ b/feapder/network/proxy_pool/__init__.py
@@ -0,0 +1,11 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2023/7/25 10:16
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+from .base import BaseProxyPool
+from .proxy_pool import ProxyPool
diff --git a/feapder/network/proxy_pool/base.py b/feapder/network/proxy_pool/base.py
new file mode 100644
index 00000000..0a2dc590
--- /dev/null
+++ b/feapder/network/proxy_pool/base.py
@@ -0,0 +1,43 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2023/7/25 10:03
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import abc
+
+from feapder.utils.log import log
+
+
+class BaseProxyPool:
+ @abc.abstractmethod
+ def get_proxy(self):
+ """
+ 获取代理
+ Returns:
+ {"http": "xxx", "https": "xxx"}
+ """
+ raise NotImplementedError
+
+ @abc.abstractmethod
+ def del_proxy(self, proxy):
+ """
+ @summary: 删除代理
+ ---------
+ @param proxy: ip:port
+ """
+ raise NotImplementedError
+
+ def tag_proxy(self, **kwargs):
+ """
+ @summary: 标记代理
+ ---------
+ @param kwargs:
+ @return:
+ """
+ log.warning("暂不支持标记代理")
+ pass
diff --git a/feapder/network/proxy_pool/proxy_pool.py b/feapder/network/proxy_pool/proxy_pool.py
new file mode 100644
index 00000000..ce492633
--- /dev/null
+++ b/feapder/network/proxy_pool/proxy_pool.py
@@ -0,0 +1,69 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/10/19 10:40 AM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+from queue import Queue
+
+import requests
+
+import feapder.setting as setting
+from feapder.network.proxy_pool.base import BaseProxyPool
+from feapder.utils import metrics
+from feapder.utils import tools
+
+
+class ProxyPool(BaseProxyPool):
+ """
+ 通过API提取代理,存储在内存中,无代理时会自动提取
+ API返回的代理以 \r\n 分隔
+ """
+
+ def __init__(self, proxy_api=None, **kwargs):
+ self.proxy_api = proxy_api or setting.PROXY_EXTRACT_API
+ self.proxy_queue = Queue()
+
+ def format_proxy(self, proxy):
+ return {"http": "http://" + proxy, "https": "http://" + proxy}
+
+ @tools.retry(3, interval=5)
+ def pull_proxies(self):
+ resp = requests.get(self.proxy_api)
+ proxies = resp.text.strip()
+ resp.close()
+ if "{" in proxies or not proxies:
+ raise Exception("获取代理失败", proxies)
+ # 使用 /r/n 分隔
+ return proxies.split("\r\n")
+
+ def get_proxy(self):
+ try:
+ if self.proxy_queue.empty():
+ proxies = self.pull_proxies()
+ for proxy in proxies:
+ self.proxy_queue.put_nowait(proxy)
+ metrics.emit_counter("total", 1, classify="proxy")
+
+ proxy = self.proxy_queue.get_nowait()
+ self.proxy_queue.put_nowait(proxy)
+
+ metrics.emit_counter("used_times", 1, classify="proxy")
+
+ return self.format_proxy(proxy)
+ except Exception as e:
+ tools.send_msg("获取代理失败", level="error")
+ raise Exception("获取代理失败", e)
+
+ def del_proxy(self, proxy):
+ """
+ @summary: 删除代理
+ ---------
+ @param proxy: ip:port
+ """
+ if proxy in self.proxy_queue.queue:
+ self.proxy_queue.queue.remove(proxy)
+ metrics.emit_counter("invalid", 1, classify="proxy")
diff --git a/feapder/network/proxy_pool.py b/feapder/network/proxy_pool_old.py
similarity index 98%
rename from feapder/network/proxy_pool.py
rename to feapder/network/proxy_pool_old.py
index c9f3c7fb..2e3bb6c1 100644
--- a/feapder/network/proxy_pool.py
+++ b/feapder/network/proxy_pool_old.py
@@ -20,7 +20,7 @@
# 建立本地缓存代理文件夹
proxy_path = os.path.join(os.path.dirname(__file__), "proxy_file")
if not os.path.exists(proxy_path):
- os.mkdir(proxy_path)
+ os.makedirs(proxy_path, exist_ok=True)
def get_proxies_by_host(host, port):
@@ -31,7 +31,7 @@ def get_proxies_by_host(host, port):
def get_proxies_by_id(proxy_id):
proxies = {
"http": "http://{}".format(proxy_id),
- "https": "https://{}".format(proxy_id),
+ "https": "http://{}".format(proxy_id),
}
return proxies
@@ -126,7 +126,7 @@ def get_proxy_from_file(filename, **kwargs):
ip = "{}@{}".format(auth, ip)
if not protocol:
proxies = {
- "https": "https://%s:%s" % (ip, port),
+ "https": "http://%s:%s" % (ip, port),
"http": "http://%s:%s" % (ip, port),
}
else:
@@ -144,7 +144,7 @@ def get_proxy_from_redis(proxy_source_url, **kwargs):
ip:port ts
@param kwargs:
{"redis_proxies_key": "xxx"}
- @return: [{'http':'http://xxx.xxx.xxx:xxx', 'https':'https://xxx.xxx.xxx.xxx:xxx'}]
+ @return: [{'http':'http://xxx.xxx.xxx:xxx', 'https':'http://xxx.xxx.xxx.xxx:xxx'}]
"""
redis_conn = redis.StrictRedis.from_url(proxy_source_url)
@@ -155,7 +155,7 @@ def get_proxy_from_redis(proxy_source_url, **kwargs):
for proxy in proxies:
proxy = proxy.decode()
proxies_list.append(
- {"https": "https://%s" % proxy, "http": "http://%s" % proxy}
+ {"https": "http://%s" % proxy, "http": "http://%s" % proxy}
)
return proxies_list
@@ -198,7 +198,7 @@ def check_proxy(
if not proxies:
proxies = {
"http": "http://{}:{}".format(ip, port),
- "https": "https://{}:{}".format(ip, port),
+ "https": "http://{}:{}".format(ip, port),
}
try:
r = requests.get(
diff --git a/feapder/network/request.py b/feapder/network/request.py
index 1affe7de..95e51604 100644
--- a/feapder/network/request.py
+++ b/feapder/network/request.py
@@ -8,8 +8,11 @@
@email: boris_liu@foxmail.com
"""
+import copy
+import os
+import re
+
import requests
-from requests.adapters import HTTPAdapter
from requests.cookies import RequestsCookieJar
from requests.packages.urllib3.exceptions import InsecureRequestWarning
@@ -17,30 +20,31 @@
import feapder.utils.tools as tools
from feapder.db.redisdb import RedisDB
from feapder.network import user_agent
-from feapder.network.proxy_pool import ProxyPool
+from feapder.network.downloader.base import Downloader, RenderDownloader
+from feapder.network.proxy_pool import BaseProxyPool
from feapder.network.response import Response
from feapder.utils.log import log
-from feapder.utils.webdriver import WebDriverPool
# 屏蔽warning信息
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
-class Request(object):
- session = None
- webdriver_pool: WebDriverPool = None
+class Request:
user_agent_pool = user_agent
- proxies_pool: ProxyPool = None
+ proxies_pool: BaseProxyPool = None
cache_db = None # redis / pika
cached_redis_key = None # 缓存response的文件文件夹 response_cached:cached_redis_key:md5
cached_expire_time = 1200 # 缓存过期时间
- local_filepath = None
- oss_handler = None
+ # 下载器
+ downloader: Downloader = None
+ session_downloader: Downloader = None
+ render_downloader: RenderDownloader = None
__REQUEST_ATTRS__ = {
- # 'method', 'url', 必须传递 不加入**kwargs中
+ # "method",
+ # "url",
"params",
"data",
"headers",
@@ -57,8 +61,9 @@ class Request(object):
"json",
}
- DEFAULT_KEY_VALUE = dict(
+ _DEFAULT_KEY_VALUE_ = dict(
url="",
+ method=None,
retry_times=0,
priority=300,
parser_name=None,
@@ -72,8 +77,15 @@ class Request(object):
is_abandoned=False,
render=False,
render_time=0,
+ make_absolute_links=None,
)
+ _CUSTOM_PROPERTIES_ = {
+ "requests_kwargs",
+ "custom_ua",
+ "custom_proxies",
+ }
+
def __init__(
self,
url="",
@@ -90,6 +102,7 @@ def __init__(
is_abandoned=False,
render=False,
render_time=0,
+ make_absolute_links=None,
**kwargs,
):
"""
@@ -110,6 +123,7 @@ def __init__(
@param is_abandoned: 当发生异常时是否放弃重试 True/False. 默认False
@param render: 是否用浏览器渲染
@param render_time: 渲染时长,即打开网页等待指定时间后再获取源码
+ @param make_absolute_links: 是否转成绝对连接,默认是
--
以下参数与requests参数使用方式一致
@param method: 请求方式,如POST或GET,默认根据data值是否为空来判断
@@ -133,6 +147,7 @@ def __init__(
"""
self.url = url
+ self.method = None
self.retry_times = retry_times
self.priority = priority
self.parser_name = parser_name
@@ -145,8 +160,14 @@ def __init__(
self.download_midware = download_midware
self.is_abandoned = is_abandoned
self.render = render
- self.render_time = render_time or setting.WEBDRIVER.get("render_time", 0)
+ self.render_time = render_time
+ self.make_absolute_links = (
+ make_absolute_links
+ if make_absolute_links is not None
+ else setting.MAKE_ABSOLUTE_LINKS
+ )
+ # 自定义属性,不参与序列化
self.requests_kwargs = {}
for key, value in kwargs.items():
if key in self.__class__.__REQUEST_ATTRS__: # 取requests参数
@@ -154,6 +175,9 @@ def __init__(
self.__dict__[key] = value
+ self.custom_ua = False
+ self.custom_proxies = False
+
def __repr__(self):
try:
return "".format(self.url)
@@ -172,36 +196,50 @@ def __setattr__(self, key, value):
if key in self.__class__.__REQUEST_ATTRS__:
self.requests_kwargs[key] = value
+ # def __getattr__(self, item):
+ # try:
+ # return self.__dict__[item]
+ # except:
+ # raise AttributeError("Request has no attribute %s" % item)
+
def __lt__(self, other):
return self.priority < other.priority
@property
- def _session(self):
- use_session = (
- setting.USE_SESSION if self.use_session is None else self.use_session
- ) # self.use_session 优先级高
- if use_session and not self.__class__.session:
- self.__class__.session = requests.Session()
- # pool_connections – 缓存的 urllib3 连接池个数 pool_maxsize – 连接池中保存的最大连接数
- http_adapter = HTTPAdapter(pool_connections=1000, pool_maxsize=1000)
- # 任何使用该session会话的 HTTP 请求,只要其 URL 是以给定的前缀开头,该传输适配器就会被使用到。
- self.__class__.session.mount("http", http_adapter)
+ def _proxies_pool(self):
+ if not self.__class__.proxies_pool:
+ self.__class__.proxies_pool = tools.import_cls(setting.PROXY_POOL)()
- return self.__class__.session
+ return self.__class__.proxies_pool
@property
- def _webdriver_pool(self):
- if not self.__class__.webdriver_pool:
- self.__class__.webdriver_pool = WebDriverPool(**setting.WEBDRIVER)
+ def _downloader(self):
+ if not self.__class__.downloader:
+ self.__class__.downloader = tools.import_cls(setting.DOWNLOADER)()
- return self.__class__.webdriver_pool
+ return self.__class__.downloader
@property
- def _proxies_pool(self):
- if not self.__class__.proxies_pool:
- self.__class__.proxies_pool = ProxyPool()
+ def _session_downloader(self):
+ if not self.__class__.session_downloader:
+ self.__class__.session_downloader = tools.import_cls(
+ setting.SESSION_DOWNLOADER
+ )()
- return self.__class__.proxies_pool
+ return self.__class__.session_downloader
+
+ @property
+ def _render_downloader(self):
+ if not self.__class__.render_downloader:
+ try:
+ self.__class__.render_downloader = tools.import_cls(
+ setting.RENDER_DOWNLOADER
+ )()
+ except AttributeError:
+ log.error('当前是渲染模式,请安装 pip install "feapder[render]"')
+ os._exit(0)
+
+ return self.__class__.render_downloader
@property
def to_dict(self):
@@ -212,28 +250,40 @@ def to_dict(self):
if callable(self.callback)
else self.callback
)
- self.download_midware = (
- getattr(self.download_midware, "__name__")
- if callable(self.download_midware)
- else self.download_midware
- )
+
+ if isinstance(self.download_midware, (tuple, list)):
+ self.download_midware = [
+ getattr(download_midware, "__name__")
+ if callable(download_midware)
+ and download_midware.__class__.__name__ == "method"
+ else download_midware
+ for download_midware in self.download_midware
+ ]
+ else:
+ self.download_midware = (
+ getattr(self.download_midware, "__name__")
+ if callable(self.download_midware)
+ and self.download_midware.__class__.__name__ == "method"
+ else self.download_midware
+ )
for key, value in self.__dict__.items():
if (
- key in self.__class__.DEFAULT_KEY_VALUE
- and self.__class__.DEFAULT_KEY_VALUE.get(key) == value
- or key == "requests_kwargs"
+ key in self.__class__._DEFAULT_KEY_VALUE_
+ and self.__class__._DEFAULT_KEY_VALUE_.get(key) == value
+ or key in self.__class__._CUSTOM_PROPERTIES_
):
continue
- if key in self.__class__.__REQUEST_ATTRS__:
- if not isinstance(
- value, (bytes, bool, float, int, str, tuple, list, dict)
- ):
- value = tools.dumps_obj(value)
- else:
- if not isinstance(value, (bytes, bool, float, int, str)):
- value = tools.dumps_obj(value)
+ if value is not None:
+ if key in self.__class__.__REQUEST_ATTRS__:
+ if not isinstance(
+ value, (bool, float, int, str, tuple, list, dict)
+ ):
+ value = tools.dumps_obj(value)
+ else:
+ if not isinstance(value, (bool, float, int, str)):
+ value = tools.dumps_obj(value)
request_dict[key] = value
@@ -247,11 +297,9 @@ def callback_name(self):
else self.callback
)
- def get_response(self, save_cached=False):
+ def make_requests_kwargs(self):
"""
- 获取带有selector功能的response
- @param save_cached: 保存缓存 方便调试时不用每次都重新下载
- @return:
+ 处理参数
"""
# 设置超时默认时间
self.requests_kwargs.setdefault(
@@ -259,7 +307,9 @@ def get_response(self, save_cached=False):
) # connect=22 read=22
# 设置stream
- # 默认情况下,当你进行网络请求后,响应体会立即被下载。你可以通过 stream 参数覆盖这个行为,推迟下载响应体直到访问 Response.content 属性。此时仅有响应头被下载下来了。缺点: stream 设为 True,Requests 无法将连接释放回连接池,除非你 消耗了所有的数据,或者调用了 Response.close。 这样会带来连接效率低下的问题。
+ # 默认情况下,当你进行网络请求后,响应体会立即被下载。
+ # stream=True是,调用Response.content 才会下载响应体,默认只返回header。
+ # 缺点: stream 设为 True,Requests 无法将连接释放回连接池,除非消耗了所有的数据,或者调用了 Response.close。 这样会带来连接效率低下的问题。
self.requests_kwargs.setdefault("stream", True)
# 关闭证书验证
@@ -272,42 +322,51 @@ def get_response(self, save_cached=False):
method = "POST"
else:
method = "GET"
+ self.method = method
- # 随机user—agent
+ # 设置user—agent
headers = self.requests_kwargs.get("headers", {})
if "user-agent" not in headers and "User-Agent" not in headers:
- if self.render: # 如果是渲染默认,优先使用WEBDRIVER中配置的ua
- ua = setting.WEBDRIVER.get(
- "user_agent"
- ) or self.__class__.user_agent_pool.get(setting.USER_AGENT_TYPE)
- else:
- ua = self.__class__.user_agent_pool.get(setting.USER_AGENT_TYPE)
-
if self.random_user_agent and setting.RANDOM_HEADERS:
+ # 随机user—agent
+ ua = self.__class__.user_agent_pool.get(setting.USER_AGENT_TYPE)
headers.update({"User-Agent": ua})
self.requests_kwargs.update(headers=headers)
+ else:
+ # 使用默认的user—agent
+ self.requests_kwargs.setdefault(
+ "headers", {"User-Agent": setting.DEFAULT_USERAGENT}
+ )
else:
- self.requests_kwargs.setdefault(
- "headers", {"User-Agent": setting.DEFAULT_USERAGENT}
- )
+ self.custom_ua = True
# 代理
proxies = self.requests_kwargs.get("proxies", -1)
if proxies == -1 and setting.PROXY_ENABLE and setting.PROXY_EXTRACT_API:
while True:
- proxies = self._proxies_pool.get()
+ proxies = self._proxies_pool.get_proxy()
if proxies:
self.requests_kwargs.update(proxies=proxies)
break
else:
log.debug("暂无可用代理 ...")
+ else:
+ self.custom_proxies = True
+
+ def get_response(self, save_cached=False):
+ """
+ 获取带有selector功能的response
+ @param save_cached: 保存缓存 方便调试时不用每次都重新下载
+ @return:
+ """
+ self.make_requests_kwargs()
log.debug(
"""
-------------- %srequest for ----------------
url = %s
method = %s
- body = %s
+ args = %s
"""
% (
""
@@ -324,7 +383,7 @@ def get_response(self, save_cached=False):
or "parse",
),
self.url,
- method,
+ self.method,
self.requests_kwargs,
)
)
@@ -334,76 +393,29 @@ def get_response(self, save_cached=False):
#
# self.requests_kwargs.update(hooks={'response': hooks})
+ # self.use_session 优先级高
use_session = (
setting.USE_SESSION if self.use_session is None else self.use_session
- ) # self.use_session 优先级高
+ )
if self.render:
- # 使用request的user_agent、cookies、proxy
- user_agent = headers.get("User-Agent") or headers.get("user-agent")
- cookies = self.requests_kwargs.get("cookies")
- if cookies and isinstance(cookies, RequestsCookieJar):
- cookies = cookies.get_dict()
-
- if not cookies:
- cookie_str = headers.get("Cookie") or headers.get("cookie")
- if cookie_str:
- cookies = tools.get_cookies_from_str(cookie_str)
-
- proxy = None
- if proxies and proxies != -1:
- proxy = proxies.get("http", "").strip("http://") or proxies.get(
- "https", ""
- ).strip("https://")
-
- browser = self._webdriver_pool.get(user_agent=user_agent, proxy=proxy)
-
- url = self.url
- if self.requests_kwargs.get("params"):
- url = tools.joint_url(self.url, self.requests_kwargs.get("params"))
-
- try:
- browser.get(url)
- if cookies:
- browser.cookies = cookies
- if self.render_time:
- tools.delay_time(self.render_time)
-
- html = browser.page_source
- response = Response.from_dict(
- {
- "url": browser.current_url,
- "cookies": browser.cookies,
- "_content": html.encode(),
- "status_code": 200,
- "elapsed": 666,
- "headers": {
- "User-Agent": browser.execute_script(
- "return navigator.userAgent"
- ),
- "Cookie": tools.cookies2str(browser.cookies),
- },
- }
- )
-
- response.browser = browser
- except Exception as e:
- self._webdriver_pool.remove(browser)
- raise e
-
+ response = self._render_downloader.download(self)
elif use_session:
- response = self._session.request(method, self.url, **self.requests_kwargs)
- response = Response(response)
+ response = self._session_downloader.download(self)
else:
- response = requests.request(method, self.url, **self.requests_kwargs)
- response = Response(response)
+ response = self._downloader.download(self)
+
+ response.make_absolute_links = self.make_absolute_links
if save_cached:
self.save_cached(response, expire_time=self.__class__.cached_expire_time)
return response
- def proxies(self):
+ def get_params(self):
+ return self.requests_kwargs.get("params")
+
+ def get_proxies(self) -> dict:
"""
Returns: {"https": "https://ip:port", "http": "http://ip:port"}
@@ -411,22 +423,44 @@ def proxies(self):
"""
return self.requests_kwargs.get("proxies")
- def proxy(self):
+ def get_proxy(self) -> str:
"""
Returns: ip:port
"""
- proxies = self.proxies()
+ proxies = self.get_proxies()
if proxies:
- return proxies.get("http", "").strip("http://") or proxies.get(
- "https", ""
- ).strip("https://")
+ return re.sub(
+ "http.*?//", "", proxies.get("http", "") or proxies.get("https", "")
+ )
+
+ def del_proxy(self):
+ proxy = self.get_proxy()
+ if proxy:
+ self._proxies_pool.del_proxy(proxy)
+ del self.requests_kwargs["proxies"]
- def user_agent(self):
- headers = self.requests_kwargs.get("headers")
- if headers:
- return headers.get("user_agent") or headers.get("User-Agent")
+ def get_headers(self) -> dict:
+ return self.requests_kwargs.get("headers", {})
+
+ def get_user_agent(self) -> str:
+ return self.get_headers().get("user_agent") or self.get_headers().get(
+ "User-Agent"
+ )
+
+ def get_cookies(self) -> dict:
+ cookies = self.requests_kwargs.get("cookies")
+ if cookies and isinstance(cookies, RequestsCookieJar):
+ cookies = cookies.get_dict()
+
+ if not cookies:
+ cookie_str = self.get_headers().get("Cookie") or self.get_headers().get(
+ "cookie"
+ )
+ if cookie_str:
+ cookies = tools.get_cookies_from_str(cookie_str)
+ return cookies
@property
def fingerprint(self):
@@ -506,4 +540,4 @@ def from_dict(cls, request_dict):
return cls(**request_dict)
def copy(self):
- return self.__class__.from_dict(self.to_dict)
+ return self.__class__.from_dict(copy.deepcopy(self.to_dict))
diff --git a/feapder/network/response.py b/feapder/network/response.py
index 6e9c4ef8..7f97861b 100644
--- a/feapder/network/response.py
+++ b/feapder/network/response.py
@@ -11,7 +11,8 @@
import datetime
import os
import re
-import time
+import tempfile
+import webbrowser
from urllib.parse import urlparse, urlunparse, urljoin
from bs4 import UnicodeDammit, BeautifulSoup
@@ -19,6 +20,7 @@
from requests.models import Response as res
from w3lib.encoding import http_content_type_encoding, html_body_declared_encoding
+from feapder import setting
from feapder.network.selector import Selector
from feapder.utils.log import log
@@ -36,10 +38,22 @@
class Response(res):
- def __init__(self, response):
+ def __init__(self, response, make_absolute_links=None):
+ """
+
+ Args:
+ response: requests请求返回的response
+ make_absolute_links: 是否自动补全url
+ """
super(Response, self).__init__()
self.__dict__.update(response.__dict__)
+ self.make_absolute_links = (
+ make_absolute_links
+ if make_absolute_links is not None
+ else setting.MAKE_ABSOLUTE_LINKS
+ )
+
self._cached_selector = None
self._cached_text = None
self._cached_json = None
@@ -47,6 +61,27 @@ def __init__(self, response):
self._encoding = None
self.encoding_errors = "strict" # strict / replace / ignore
+ self.browser = self.driver = None
+
+ @classmethod
+ def from_text(
+ cls,
+ text: str,
+ url: str = "",
+ cookies: dict = None,
+ headers: dict = None,
+ encoding="utf-8",
+ ):
+ response_dict = {
+ "_content": text.encode(encoding=encoding),
+ "cookies": cookies or {},
+ "encoding": encoding,
+ "headers": headers or {},
+ "status_code": 200,
+ "elapsed": 0,
+ "url": url,
+ }
+ return cls.from_dict(response_dict)
@classmethod
def from_dict(cls, response_dict):
@@ -176,10 +211,10 @@ def _make_absolute(self, link):
def _absolute_links(self, text):
regexs = [
- r'(<(?i)a.*?href\s*?=\s*?["\'])(.+?)(["\'])', # a
- r'(<(?i)img.*?src\s*?=\s*?["\'])(.+?)(["\'])', # img
- r'(<(?i)link.*?href\s*?=\s*?["\'])(.+?)(["\'])', # css
- r'(<(?i)script.*?src\s*?=\s*?["\'])(.+?)(["\'])', # js
+ r'( 标签后插入一个标签
+ repl = fr'\1'
+ body = re.sub(rb"(|\s.*?>))", repl.encode("utf-8"), body)
+
+ fd, fname = tempfile.mkstemp(".html")
+ os.write(fd, body)
+ os.close(fd)
+ return webbrowser.open(f"file://{fname}")
diff --git a/feapder/network/selector.py b/feapder/network/selector.py
index 381c6b7c..901f4eb5 100644
--- a/feapder/network/selector.py
+++ b/feapder/network/selector.py
@@ -9,10 +9,13 @@
"""
import re
+import parsel
import six
from lxml import etree
+from packaging import version
from parsel import Selector as ParselSelector
from parsel import SelectorList as ParselSelectorList
+from parsel import selector
from w3lib.html import replace_entities as w3lib_replace_entities
@@ -54,8 +57,7 @@ def extract_regex(regex, text, replace_entities=True, flags=0):
def create_root_node(text, parser_cls, base_url=None):
- """Create root node for text using given parser class.
- """
+ """Create root node for text using given parser class."""
body = text.strip().replace("\x00", "").encode("utf8") or b""
parser = parser_cls(recover=True, encoding="utf8", huge_tree=True)
root = etree.fromstring(body, parser=parser, base_url=base_url)
@@ -64,6 +66,10 @@ def create_root_node(text, parser_cls, base_url=None):
return root
+if version.parse(parsel.__version__) < version.parse("1.7.0"):
+ selector.create_root_node = create_root_node
+
+
class SelectorList(ParselSelectorList):
"""
The :class:`SelectorList` class is a subclass of the builtin ``list``
@@ -150,6 +156,3 @@ def re(self, regex, replace_entities=True, flags=re.S):
return extract_regex(
regex, self.get(), replace_entities=replace_entities, flags=flags
)
-
- def _get_root(self, text, base_url=None):
- return create_root_node(text, self._parser, base_url=base_url)
diff --git a/feapder/network/user_agent.py b/feapder/network/user_agent.py
index 28df6325..7f9024d4 100644
--- a/feapder/network/user_agent.py
+++ b/feapder/network/user_agent.py
@@ -61,6 +61,683 @@
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_2) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1309.0 Safari/537.17",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.15 (KHTML, like Gecko) Chrome/24.0.1295.0 Safari/537.15",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.14 (KHTML, like Gecko) Chrome/24.0.1292.0 Safari/537.14",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3215.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3790.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.92 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.63 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.24 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.136 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.0.3016 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36 Kinza/6.1.5",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.48 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.2.0.1713 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.47 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.2 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.819 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.41 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.785 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.9 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3235.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3409.85 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4371.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.9 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.43 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 CravingExplorer/2.4.1",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4121.813 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.107 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.9 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.158 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.58 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.140 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
+ "Mozilla/5.0 (Microsoft Windows NT 10.0.16299.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 (FTM)",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4500.0 Iron Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4427.5 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3835.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; ) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/82.0.4085.4 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.116 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.116 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.91 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.4000.0 Iron Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.41 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; ) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.116 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.41 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 5.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 ADG/11.0.2566 AOLBUILD/11.0.2566 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.108 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.152 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 ADG/11.0.2510 AOLBUILD/11.0.2510 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; ) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 AOLShield/83.0.4103.0",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 AOL/11.0 AOLBUILD/11.0.1839 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 ADG/11.0.2414 AOLBUILD/11.0.2414 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 ADG/11.0.2566 AOLBUILD/11.0.2566 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 AOLShield/83.0.4103.2",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.87 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/84.0.4147.105 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.183 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.152 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/90.0.4430.72 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 ADG/11.0.2510 AOLBUILD/11.0.2510 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 ADG/11.0.2566 AOLBUILD/11.0.2566 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.97 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/84.0.4147.105 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.182 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.108 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 ADG/11.0.2510 AOLBUILD/11.0.2510 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.101 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 AOL/11.0 AOLBUILD/11.0.1839 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 ADG/11.0.2470 AOLBUILD/11.0.2470 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 ADG/11.0.2566 AOLBUILD/11.0.2566 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 AOLShield/79.0.3945.5",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/77.0.3865.90 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/79.0.3945.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.162 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/84.0.4147.89 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.99 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.141 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.72 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.123 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4558.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; ) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.102 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4564.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.81 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.81 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3409.13 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.26 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.81 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4591.54 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.101.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.7113.93 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.49 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.1150.52 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4950.0 Iron Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4450.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 11.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4868.173 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.1483.27 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.3478.83 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.5118.205 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Agency/97.8.8247.48",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36",
+ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4137.1 SputnikBrowser/5.6.6280.0 (GOST) Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.43 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/82.0.4078.2 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.3538.77 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.5 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.6 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.1 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3409.631 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.3 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.101 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.2 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.93 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.8 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.5 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3409.1 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.44 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.779 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.19 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.6 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36\tChrome 79.0",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36\tChrome Generic",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.69 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.186 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4450.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_3_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/524.34",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.105 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.51 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.152 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.152 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.3538.77 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/77.0.3865.99 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/81.0.4044.108 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/83.0.4103.118 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/84.0.4147.108 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/84.0.4147.140 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/85.0.4183.122 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/87.0.4280.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/88.0.4324.175 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/89.0.4389.93 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/89.0.4389.127 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.75 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/79.0.3945.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.116 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/81.0.4044.113 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/84.0.4147.135 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.75 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.141 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.72 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.70 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.116 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.162 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.75 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.67 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.152 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/77.0.3865.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.108 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.87 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.162 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/83.0.4103.116 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/85.0.4183.83 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.99 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.198 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.141 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.182 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/90.0.4430.72 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/79.0.3945.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/79.0.3945.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/77.0.3865.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.108 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.122 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/81.0.4044.113 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/84.0.4147.89 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/85.0.4183.102 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.183 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.146 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.72 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.108 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.70 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.97 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/79.0.3945.130 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.108 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.87 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.149 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/84.0.4147.89 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.99 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.149 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/81.0.4044.122 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/84.0.4147.89 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.101 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/83.0.4103.97 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/84.0.4147.105 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.75 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/78.0.3904.87 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/83.0.4103.106 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/84.0.4147.125 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/85.0.4183.121 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.183 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.152 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/83.0.4103.116 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/85.0.4183.102 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.111 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.60 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.141 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.182 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/80.0.3987.116 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/86.0.4240.183 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.67 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.96 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.192 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.67 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.96 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.72 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.101 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.152 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/87.0.4280.101 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.182 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.146 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.72 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/88.0.4324.96 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.72 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_3_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/537.36 (KHTML, like Gecko, Mediapartners-Google) Chrome/89.0.4389.130 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_3_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.69 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4582.189 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/82.0.4083.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4612.206 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4702.147 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4691.94 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4889.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.79 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.79 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.9999.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.40 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4880.146 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.147 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4886.93 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/89.0.4389.105 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4886.148 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5163.147 Safari/537.36"
],
"opera": [
"Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16",
diff --git a/feapder/network/user_pool/base_user_pool.py b/feapder/network/user_pool/base_user_pool.py
index 41a9318d..631c3a63 100644
--- a/feapder/network/user_pool/base_user_pool.py
+++ b/feapder/network/user_pool/base_user_pool.py
@@ -149,7 +149,7 @@ def reset_use_times(self):
self.sycn_to_redis()
@property
- def get_use_times(self):
+ def use_times(self):
current_date = datetime.now().strftime("%Y-%m-%d")
if current_date != self._reset_use_times_date:
self.reset_use_times()
@@ -157,7 +157,7 @@ def get_use_times(self):
return self._use_times
def is_overwork(self):
- if self._use_times > self.max_use_times:
+ if self.use_times > self.max_use_times:
log.info("账号 {} 请求次数超限制".format(self.username))
return True
diff --git a/feapder/network/user_pool/guest_user_pool.py b/feapder/network/user_pool/guest_user_pool.py
index 8e935842..9d34aad3 100644
--- a/feapder/network/user_pool/guest_user_pool.py
+++ b/feapder/network/user_pool/guest_user_pool.py
@@ -16,7 +16,6 @@
from feapder.db.redisdb import RedisDB
from feapder.network.user_pool.base_user_pool import UserPoolInterface, GuestUser
from feapder.utils.log import log
-from feapder.utils.redis_lock import RedisLock
from feapder.utils.webdriver import WebDriver
@@ -46,7 +45,7 @@ def __init__(
user_agent: 字符串 或 无参函数,返回值为user_agent
proxy: xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless: 是否启用无头模式
- driver_type: CHROME 或 PHANTOMJS,FIREFOX
+ driver_type: CHROME,EDGE 或 PHANTOMJS,FIREFOX
timeout: 请求超时时间
window_size: # 窗口大小
executable_path: 浏览器路径,默认为默认路径
@@ -125,11 +124,8 @@ def get_user(self, block=True) -> Optional[GuestUser]:
if not user_id and block:
self._keep_alive = False
- with RedisLock(
- key=self._tab_user_pool, lock_timeout=3600, wait_timeout=0
- ) as _lock:
- if _lock.locked:
- self.run()
+ self._min_users = 1
+ self.run()
continue
return user_str and GuestUser(**eval(user_str))
diff --git a/feapder/network/user_pool/normal_user_pool.py b/feapder/network/user_pool/normal_user_pool.py
index f14c7656..63c99726 100644
--- a/feapder/network/user_pool/normal_user_pool.py
+++ b/feapder/network/user_pool/normal_user_pool.py
@@ -209,9 +209,9 @@ def run(self):
retry_times = 0
while retry_times <= self._login_retry_times:
try:
- user = self.login(user)
- if user:
- self.add_user(user)
+ login_user = self.login(user)
+ if login_user:
+ self.add_user(login_user)
else:
self.handle_login_failed_user(user)
break
diff --git a/feapder/pipelines/console_pipeline.py b/feapder/pipelines/console_pipeline.py
index 1eb95a0a..1ebb532e 100644
--- a/feapder/pipelines/console_pipeline.py
+++ b/feapder/pipelines/console_pipeline.py
@@ -10,6 +10,7 @@
from feapder.pipelines import BasePipeline
from typing import Dict, List, Tuple
+from feapder.utils.log import log
class ConsolePipeline(BasePipeline):
@@ -28,7 +29,7 @@ def save_items(self, table, items: List[Dict]) -> bool:
若False,不会将本批数据入到去重库,以便再次入库
"""
-
+ log.info("【调试输出】共导出 %s 条数据 到 %s" % (len(items), table))
return True
def update_items(self, table, items: List[Dict], update_keys=Tuple) -> bool:
@@ -43,5 +44,5 @@ def update_items(self, table, items: List[Dict], update_keys=Tuple) -> bool:
若False,不会将本批数据入到去重库,以便再次入库
"""
-
+ log.info("【调试输出】共导出 %s 条数据 到 %s" % (len(items), table))
return True
diff --git a/feapder/pipelines/csv_pipeline.py b/feapder/pipelines/csv_pipeline.py
new file mode 100644
index 00000000..922a77d3
--- /dev/null
+++ b/feapder/pipelines/csv_pipeline.py
@@ -0,0 +1,254 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2025-10-16
+---------
+@summary: CSV 数据导出Pipeline
+---------
+@author: 道长
+@email: ctrlf4@yeah.net
+"""
+
+import csv
+import os
+import threading
+from typing import Dict, List, Tuple
+
+from feapder.pipelines import BasePipeline
+from feapder.utils.log import log
+
+
+class CsvPipeline(BasePipeline):
+ """
+ CSV 数据导出Pipeline
+
+ 将爬虫数据保存为CSV文件。支持批量保存、并发写入控制、断点续爬等功能。
+
+ 特点:
+ - 单表单锁设计,避免全局锁带来的性能问题
+ - 自动创建导出目录
+ - 支持追加模式,便于断点续爬
+ - 通过fsync确保数据落盘
+ - 表级别的字段名缓存,确保跨批字段顺序一致
+ """
+
+ # 用于保护每个表的文件写入操作(Per-Table Lock)
+ _file_locks = {}
+
+ # 用于缓存每个表的字段名顺序(Per-Table Fieldnames Cache)
+ # 确保跨批次、跨线程的字段顺序一致
+ _table_fieldnames = {}
+
+ def __init__(self, csv_dir=None):
+ """
+ 初始化CSV Pipeline
+
+ Args:
+ csv_dir: CSV文件保存目录
+ - 如果不传,从 setting.CSV_EXPORT_PATH 读取
+ - 支持相对路径(如 "data/csv")
+ - 支持绝对路径(如 "/Users/xxx/exports/csv")
+ """
+ super().__init__()
+
+ # 如果未传入参数,从配置文件读取
+ if csv_dir is None:
+ import feapder.setting as setting
+ csv_dir = setting.CSV_EXPORT_PATH
+
+ # 支持绝对路径和相对路径,统一转换为绝对路径
+ self.csv_dir = os.path.abspath(csv_dir)
+ self._ensure_csv_dir_exists()
+
+ def _ensure_csv_dir_exists(self):
+ """确保CSV保存目录存在"""
+ if not os.path.exists(self.csv_dir):
+ try:
+ os.makedirs(self.csv_dir, exist_ok=True)
+ log.info(f"创建CSV保存目录: {self.csv_dir}")
+ except Exception as e:
+ log.error(f"创建CSV目录失败: {e}")
+ raise
+
+ @staticmethod
+ def _get_lock(table):
+ """
+ 获取表对应的文件锁
+
+ 采用Per-Table Lock设计,每个表都有独立的锁,避免锁竞争。
+ 这样设计既能保证单表的文件写入安全,又能充分利用多表并行写入的优势。
+
+ Args:
+ table: 表名
+
+ Returns:
+ threading.Lock: 该表对应的锁对象
+ """
+ if table not in CsvPipeline._file_locks:
+ CsvPipeline._file_locks[table] = threading.Lock()
+ return CsvPipeline._file_locks[table]
+
+ @staticmethod
+ def _get_and_cache_fieldnames(table, items):
+ """
+ 获取并缓存表对应的字段名顺序
+
+ 第一次调用时从items[0]提取字段名并缓存,后续调用直接返回缓存的字段名。
+ 这样设计确保:
+ 1. 跨批次的字段顺序保持一致(解决数据列错位问题)
+ 2. 多线程并发时字段顺序不被污染
+ 3. 避免重复提取,性能更优
+
+ Args:
+ table: 表名
+ items: 数据列表 [{},{},...]
+
+ Returns:
+ list: 字段名列表
+ """
+ # 如果该表已经缓存了字段名,直接返回缓存的
+ if table in CsvPipeline._table_fieldnames:
+ return CsvPipeline._table_fieldnames[table]
+
+ # 第一次调用,从items提取字段名并缓存
+ if not items:
+ return []
+
+ first_item = items[0]
+ fieldnames = list(first_item.keys()) if isinstance(first_item, dict) else []
+
+ if fieldnames:
+ # 缓存字段名(使用静态变量,跨实例共享)
+ CsvPipeline._table_fieldnames[table] = fieldnames
+ log.info(f"表 {table} 的字段名已缓存: {fieldnames}")
+
+ return fieldnames
+
+ def _get_csv_file_path(self, table):
+ """
+ 获取表对应的CSV文件路径
+
+ Args:
+ table: 表名
+
+ Returns:
+ str: CSV文件的完整路径
+ """
+ return os.path.join(self.csv_dir, f"{table}.csv")
+
+
+ def _file_exists_and_has_content(self, csv_file):
+ """
+ 检查CSV文件是否存在且有内容
+
+ Args:
+ csv_file: CSV文件路径
+
+ Returns:
+ bool: 文件存在且有内容返回True
+ """
+ return os.path.exists(csv_file) and os.path.getsize(csv_file) > 0
+
+ def save_items(self, table, items: List[Dict]) -> bool:
+ """
+ 保存数据到CSV文件
+
+ 采用追加模式打开文件,支持断点续爬。第一次写入时会自动添加表头。
+ 使用Per-Table Lock确保多线程写入时的数据一致性。
+ 使用缓存的字段名确保跨批次字段顺序一致,避免数据列错位。
+
+ Args:
+ table: 表名(对应CSV文件名)
+ items: 数据列表,[{}, {}, ...]
+
+ Returns:
+ bool: 保存成功返回True,失败返回False
+ 失败时ItemBuffer会自动重试(最多10次)
+ """
+ if not items:
+ return True
+
+ csv_file = self._get_csv_file_path(table)
+
+ # 使用缓存机制获取字段名(关键!确保跨批字段顺序一致)
+ fieldnames = self._get_and_cache_fieldnames(table, items)
+
+ if not fieldnames:
+ log.warning(f"无法提取字段名,items: {items}")
+ return False
+
+ try:
+ # 获取表级别的锁(关键!保证文件写入安全)
+ lock = self._get_lock(table)
+ with lock:
+ # 检查文件是否已存在且有内容
+ file_exists = self._file_exists_and_has_content(csv_file)
+
+ # 以追加模式打开文件
+ with open(
+ csv_file,
+ "a",
+ encoding="utf-8",
+ newline=""
+ ) as f:
+ writer = csv.DictWriter(f, fieldnames=fieldnames)
+
+ # 如果文件不存在或为空,写入表头
+ if not file_exists:
+ writer.writeheader()
+
+ # 批量写入数据行
+ # 使用缓存的fieldnames确保列顺序一致,避免跨批数据错位
+ writer.writerows(items)
+
+ # 刷新缓冲区到磁盘,确保数据不丢失
+ f.flush()
+ os.fsync(f.fileno())
+
+ # 记录导出日志
+ log.info(
+ f"共导出 {len(items)} 条数据 到 {table}.csv (文件路径: {csv_file})"
+ )
+ return True
+
+ except Exception as e:
+ log.error(
+ f"CSV写入失败. table: {table}, csv_file: {csv_file}, error: {e}"
+ )
+ return False
+
+ def update_items(self, table, items: List[Dict], update_keys=Tuple) -> bool:
+ """
+ 更新数据
+
+ 注意:CSV文件本身不支持真正的"更新"操作(需要查询后替换)。
+ 目前的实现是直接追加写入,相当于INSERT操作。
+
+ 如果需要真正的UPDATE操作,建议:
+ 1. 定期重新生成CSV文件
+ 2. 使用数据库(MySQL/MongoDB)来处理UPDATE
+ 3. 或在应用层进行去重和更新
+
+ Args:
+ table: 表名
+ items: 数据列表,[{}, {}, ...]
+ update_keys: 更新的字段(此实现中未使用)
+
+ Returns:
+ bool: 操作成功返回True
+ """
+ # 对于CSV,update操作实现为追加写入
+ # 若需要真正的UPDATE操作,建议在应用层处理
+ return self.save_items(table, items)
+
+ def close(self):
+ """
+ 关闭Pipeline,释放资源
+
+ 在爬虫结束时由ItemBuffer自动调用。
+ """
+ try:
+ # 清理文件锁字典(可选,用于释放内存)
+ # 在长期运行的场景下,可能需要定期清理
+ pass
+ except Exception as e:
+ log.error(f"关闭CSV Pipeline时出错: {e}")
diff --git a/feapder/pipelines/mysql_pipeline.py b/feapder/pipelines/mysql_pipeline.py
index 8899761b..3ffb3fc1 100644
--- a/feapder/pipelines/mysql_pipeline.py
+++ b/feapder/pipelines/mysql_pipeline.py
@@ -45,6 +45,8 @@ def save_items(self, table, items: List[Dict]) -> bool:
log.info(
"共导出 %s 条数据 到 %s, 重复 %s 条" % (datas_size, table, datas_size - add_count)
)
+ else:
+ log.debug("没有插入数据,可能全部重复")
return add_count != None
diff --git a/feapder/requirements.txt b/feapder/requirements.txt
index 11bac342..21717674 100644
--- a/feapder/requirements.txt
+++ b/feapder/requirements.txt
@@ -16,4 +16,6 @@ urllib3>=1.25.8
loguru>=0.5.3
influxdb>=5.3.1
pyperclip>=1.8.2
-webdriver-manager>=3.5.3
+webdriver-manager>=4.0.0
+terminal-layout>=2.1.3
+playwright
\ No newline at end of file
diff --git a/feapder/setting.py b/feapder/setting.py
index bdeff27c..c52b318c 100644
--- a/feapder/setting.py
+++ b/feapder/setting.py
@@ -4,15 +4,13 @@
# redis 表名
# 任务表模版
-TAB_REQUSETS = "{redis_key}:z_requsets"
+TAB_REQUESTS = "{redis_key}:z_requests"
# 任务失败模板
-TAB_FAILED_REQUSETS = "{redis_key}:z_failed_requsets"
+TAB_FAILED_REQUESTS = "{redis_key}:z_failed_requests"
# 数据保存失败模板
TAB_FAILED_ITEMS = "{redis_key}:s_failed_items"
# 爬虫状态表模版
-TAB_SPIDER_STATUS = "{redis_key}:z_spider_status"
-# 爬虫时间记录表
-TAB_SPIDER_TIME = "{redis_key}:h_spider_time"
+TAB_SPIDER_STATUS = "{redis_key}:h_spider_status"
# 用户池
TAB_USER_POOL = "{redis_key}:h_{user_type}_pool"
@@ -29,12 +27,15 @@
MONGO_DB = os.getenv("MONGO_DB")
MONGO_USER_NAME = os.getenv("MONGO_USER_NAME")
MONGO_USER_PASS = os.getenv("MONGO_USER_PASS")
+MONGO_URL = os.getenv("MONGO_URL")
# REDIS
# ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"]
REDISDB_IP_PORTS = os.getenv("REDISDB_IP_PORTS")
REDISDB_USER_PASS = os.getenv("REDISDB_USER_PASS")
REDISDB_DB = int(os.getenv("REDISDB_DB", 0))
+# 连接redis时携带的其他参数,如ssl=True
+REDISDB_KWARGS = dict()
# 适用于redis哨兵模式
REDISDB_SERVICE_NAME = os.getenv("REDISDB_SERVICE_NAME")
@@ -42,25 +43,24 @@
ITEM_PIPELINES = [
"feapder.pipelines.mysql_pipeline.MysqlPipeline",
# "feapder.pipelines.mongo_pipeline.MongoPipeline",
+ # "feapder.pipelines.csv_pipeline.CsvPipeline",
+ # "feapder.pipelines.console_pipeline.ConsolePipeline",
]
+CSV_EXPORT_PATH = "data/csv" # CSV文件保存路径,支持相对路径和绝对路径
EXPORT_DATA_MAX_FAILED_TIMES = 10 # 导出数据时最大的失败次数,包括保存和更新,超过这个次数报警
EXPORT_DATA_MAX_RETRY_TIMES = 10 # 导出数据时最大的重试次数,包括保存和更新,超过这个次数则放弃重试
# 爬虫相关
# COLLECTOR
-COLLECTOR_SLEEP_TIME = 1 # 从任务队列中获取任务到内存队列的间隔
-COLLECTOR_TASK_COUNT = 10 # 每次获取任务数量
+COLLECTOR_TASK_COUNT = 32 # 每次获取任务数量,追求速度推荐32
# SPIDER
-SPIDER_THREAD_COUNT = 1 # 爬虫并发数
-SPIDER_SLEEP_TIME = (
- 0 # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
-)
-SPIDER_TASK_COUNT = 1 # 每个parser从内存队列中获取任务的数量
-SPIDER_MAX_RETRY_TIMES = 100 # 每个请求最大重试次数
-SPIDER_AUTO_START_REQUESTS = (
- True # 是否主动执行添加 设置为False 需要手动调用start_monitor_task,适用于多进程情况下
-)
+SPIDER_THREAD_COUNT = 1 # 爬虫并发数,追求速度推荐32
+# 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
+SPIDER_SLEEP_TIME = 0
+SPIDER_MAX_RETRY_TIMES = 10 # 每个请求最大重试次数
+# 是否主动执行添加 设置为False 需要手动调用start_monitor_task,适用于多进程情况下
+SPIDER_AUTO_START_REQUESTS = True
KEEP_ALIVE = False # 爬虫是否常驻
# 浏览器渲染
@@ -70,24 +70,57 @@
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
- driver_type="CHROME", # CHROME、PHANTOMJS、FIREFOX
+ driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
- custom_argument=["--ignore-certificate-errors"], # 自定义浏览器渲染参数
+ custom_argument=[
+ "--ignore-certificate-errors",
+ "--disable-blink-features=AutomationControlled",
+ ], # 自定义浏览器渲染参数
xhr_url_regexes=None, # 拦截xhr接口,支持正则,数组类型
- auto_install_driver=False, # 自动下载浏览器驱动 支持chrome 和 firefox
+ auto_install_driver=True, # 自动下载浏览器驱动 支持chrome 和 firefox
+ download_path=None, # 下载文件的路径
+ use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+)
+
+PLAYWRIGHT = dict(
+ user_agent=None, # 字符串 或 无参函数,返回值为user_agent
+ proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+ headless=False, # 是否为无头浏览器
+ driver_type="chromium", # chromium、firefox、webkit
+ timeout=30, # 请求超时时间
+ window_size=(1024, 800), # 窗口大小
+ executable_path=None, # 浏览器路径,默认为默认路径
+ download_path=None, # 下载文件的路径
+ render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
+ wait_until="networkidle", # 等待页面加载完成的事件,可选值:"commit", "domcontentloaded", "load", "networkidle"
+ use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+ page_on_event_callback=None, # page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()}
+ storage_state_path=None, # 保存浏览器状态的路径
+ url_regexes=None, # 拦截接口,支持正则,数组类型
+ save_all=False, # 是否保存所有拦截的接口, 配合url_regexes使用,为False时只保存最后一次拦截的接口
)
# 爬虫启动时,重新抓取失败的requests
RETRY_FAILED_REQUESTS = False
+# 爬虫启动时,重新入库失败的item
+RETRY_FAILED_ITEMS = False
# 保存失败的request
SAVE_FAILED_REQUEST = True
# request防丢机制。(指定的REQUEST_LOST_TIMEOUT时间内request还没做完,会重新下发 重做)
REQUEST_LOST_TIMEOUT = 600 # 10分钟
# request网络请求超时时间
REQUEST_TIMEOUT = 22 # 等待服务器响应的超时时间,浮点数,或(connect timeout, read timeout)元组
+# item在内存队列中最大缓存数量
+ITEM_MAX_CACHED_COUNT = 5000
+# item每批入库的最大数量
+ITEM_UPLOAD_BATCH_MAX_SIZE = 1000
+# item入库时间间隔
+ITEM_UPLOAD_INTERVAL = 1
+# 内存任务队列最大缓存的任务数,默认不限制;仅对AirSpider有效。
+TASK_MAX_CACHED_SIZE = 0
# 下载缓存 利用redis缓存,但由于内存大小限制,所以建议仅供开发调试代码时使用,防止每次debug都需要网络请求
RESPONSE_CACHED_ENABLE = False # 是否启用下载缓存 成本高的数据或容易变需求的数据,建议设置为True
@@ -102,32 +135,48 @@
# 设置代理
PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n
PROXY_ENABLE = True
+PROXY_MAX_FAILED_TIMES = 5 # 代理最大失败次数,超过则不使用,自动删除
+PROXY_POOL = "feapder.network.proxy_pool.ProxyPool" # 代理池
# 随机headers
RANDOM_HEADERS = True
# UserAgent类型 支持 'chrome', 'opera', 'firefox', 'internetexplorer', 'safari','mobile' 若不指定则随机类型
USER_AGENT_TYPE = "chrome"
-# 默认使用的浏览器头 RANDOM_HEADERS=True时不生效
+# 默认使用的浏览器头
DEFAULT_USERAGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
# requests 使用session
USE_SESSION = False
+# 下载
+DOWNLOADER = "feapder.network.downloader.RequestsDownloader" # 请求下载器
+SESSION_DOWNLOADER = "feapder.network.downloader.RequestsSessionDownloader"
+RENDER_DOWNLOADER = "feapder.network.downloader.SeleniumDownloader" # 渲染下载器
+# RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader"
+MAKE_ABSOLUTE_LINKS = True # 自动转成绝对连接
+
# 去重
ITEM_FILTER_ENABLE = False # item 去重
ITEM_FILTER_SETTING = dict(
- filter_type=1 # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3
+ filter_type=1 # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4
)
REQUEST_FILTER_ENABLE = False # request 去重
REQUEST_FILTER_SETTING = dict(
- filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3
+ filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4
expire_time=2592000, # 过期时间1个月
)
-# 报警 支持钉钉、企业微信、邮件
+# 报警 支持钉钉、飞书、企业微信、邮件
# 钉钉报警
DINGDING_WARNING_URL = "" # 钉钉机器人api
-DINGDING_WARNING_PHONE = "" # 报警人 支持列表,可指定多个
+DINGDING_WARNING_PHONE = "" # 被@的群成员手机号,支持列表,可指定多个。
+DINGDING_WARNING_USER_ID = "" # 被@的群成员userId,支持列表,可指定多个
DINGDING_WARNING_ALL = False # 是否提示所有人, 默认为False
+DINGDING_WARNING_SECRET = None # 加签密钥
+# 飞书报警
+# https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN#e1cdee9f
+FEISHU_WARNING_URL = "" # 飞书机器人api
+FEISHU_WARNING_USER = None # 报警人 {"open_id":"ou_xxxxx", "name":"xxxx"} 或 [{"open_id":"ou_xxxxx", "name":"xxxx"}]
+FEISHU_WARNING_ALL = False # 是否提示所有人, 默认为False
# 邮件报警
EMAIL_SENDER = "" # 发件人
EMAIL_PASSWORD = "" # 授权码
@@ -137,15 +186,20 @@
WECHAT_WARNING_URL = "" # 企业微信机器人api
WECHAT_WARNING_PHONE = "" # 报警人 将会在群内@此人, 支持列表,可指定多人
WECHAT_WARNING_ALL = False # 是否提示所有人, 默认为False
+# QMSG报警
+QMSG_WARNING_URL = "" # qmsg机器人api
+QMSG_WARNING_QQ = "" # 指定要接收消息的QQ号或者QQ群。多个以英文逗号分割,例如:12345,12346,支持列表,可指定多人
+QMSG_WARNING_BOT = "" # 机器人的QQ号
# 时间间隔
WARNING_INTERVAL = 3600 # 相同报警的报警时间间隔,防止刷屏; 0表示不去重
-WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / ERROR
+WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / INFO / ERROR
WARNING_FAILED_COUNT = 1000 # 任务失败数 超过WARNING_FAILED_COUNT则报警
+WARNING_CHECK_TASK_COUNT_INTERVAL = 1200 # 检查已做任务数量的时间间隔,若两次时间间隔之间,任务数无变化则报警
# 日志
LOG_NAME = os.path.basename(os.getcwd())
LOG_PATH = "log/%s.log" % LOG_NAME # log存储路径
-LOG_LEVEL = "DEBUG"
+LOG_LEVEL = os.getenv("LOG_LEVEL", "DEBUG") # 日志级别
LOG_COLOR = True # 是否带有颜色
LOG_IS_WRITE_TO_CONSOLE = True # 是否打印到控制台
LOG_IS_WRITE_TO_FILE = False # 是否写文件
diff --git a/feapder/templates/batch_spider_template.tmpl b/feapder/templates/batch_spider_template.tmpl
index 52a8bae9..9802e994 100644
--- a/feapder/templates/batch_spider_template.tmpl
+++ b/feapder/templates/batch_spider_template.tmpl
@@ -8,6 +8,7 @@ Created on {DATE}
"""
import feapder
+from feapder import ArgumentParser
class ${spider_name}(feapder.BatchSpider):
@@ -18,9 +19,9 @@ class ${spider_name}(feapder.BatchSpider):
REDISDB_DB=0,
MYSQL_IP="localhost",
MYSQL_PORT=3306,
- MYSQL_DB="feapder",
- MYSQL_USER_NAME="feapder",
- MYSQL_USER_PASS="feapder123",
+ MYSQL_DB="",
+ MYSQL_USER_NAME="",
+ MYSQL_USER_PASS="",
)
def start_requests(self, task):
@@ -36,7 +37,7 @@ class ${spider_name}(feapder.BatchSpider):
if __name__ == "__main__":
spider = ${spider_name}(
- redis_key="xxx:xxxx", # redis中存放任务等信息的根key
+ redis_key="xxx:xxxx", # 分布式爬虫调度信息存储位置
task_table="", # mysql中的任务表
task_keys=["id", "xxx"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
@@ -45,5 +46,24 @@ if __name__ == "__main__":
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
- # spider.start_monitor_task() # 下发及监控任务
- spider.start() # 采集
+ parser = ArgumentParser(description="${spider_name}爬虫")
+
+ parser.add_argument(
+ "--start_master",
+ action="store_true",
+ help="添加任务",
+ function=spider.start_monitor_task,
+ )
+ parser.add_argument(
+ "--start_worker", action="store_true", help="启动爬虫", function=spider.start
+ )
+
+ parser.start()
+
+ # 直接启动
+ # spider.start() # 启动爬虫
+ # spider.start_monitor_task() # 添加任务
+
+ # 通过命令行启动
+ # python ${file_name} --start_master # 添加任务
+ # python ${file_name} --start_worker # 启动爬虫
diff --git a/feapder/templates/project_template/setting.py b/feapder/templates/project_template/setting.py
index 87537951..140aaa07 100644
--- a/feapder/templates/project_template/setting.py
+++ b/feapder/templates/project_template/setting.py
@@ -16,12 +16,15 @@
# MONGO_DB = ""
# MONGO_USER_NAME = ""
# MONGO_USER_PASS = ""
+# MONGO_URL = "
#
# # REDIS
# # ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"]
# REDISDB_IP_PORTS = "localhost:6379"
# REDISDB_USER_PASS = ""
# REDISDB_DB = 0
+# # 连接redis时携带的其他参数,如ssl=True
+# REDISDB_KWARGS = dict()
# # 适用于redis哨兵模式
# REDISDB_SERVICE_NAME = ""
#
@@ -29,24 +32,31 @@
# ITEM_PIPELINES = [
# "feapder.pipelines.mysql_pipeline.MysqlPipeline",
# # "feapder.pipelines.mongo_pipeline.MongoPipeline",
+# # "feapder.pipelines.csv_pipeline.CsvPipeline",
+# # "feapder.pipelines.console_pipeline.ConsolePipeline",
# ]
+# CSV_EXPORT_PATH = "data/csv" # CSV文件保存路径,支持相对路径和绝对路径
# EXPORT_DATA_MAX_FAILED_TIMES = 10 # 导出数据时最大的失败次数,包括保存和更新,超过这个次数报警
# EXPORT_DATA_MAX_RETRY_TIMES = 10 # 导出数据时最大的重试次数,包括保存和更新,超过这个次数则放弃重试
#
# # 爬虫相关
# # COLLECTOR
-# COLLECTOR_SLEEP_TIME = 1 # 从任务队列中获取任务到内存队列的间隔
-# COLLECTOR_TASK_COUNT = 10 # 每次获取任务数量
+# COLLECTOR_TASK_COUNT = 32 # 每次获取任务数量,追求速度推荐32
#
# # SPIDER
-# SPIDER_THREAD_COUNT = 1 # 爬虫并发数
-# SPIDER_SLEEP_TIME = (
-# 0 # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
-# )
-# SPIDER_TASK_COUNT = 1 # 每个parser从内存队列中获取任务的数量
-# SPIDER_MAX_RETRY_TIMES = 100 # 每个请求最大重试次数
+# SPIDER_THREAD_COUNT = 1 # 爬虫并发数,追求速度推荐32
+# # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
+# SPIDER_SLEEP_TIME = 0
+# SPIDER_MAX_RETRY_TIMES = 10 # 每个请求最大重试次数
# KEEP_ALIVE = False # 爬虫是否常驻
-#
+
+# 下载
+# DOWNLOADER = "feapder.network.downloader.RequestsDownloader" # 请求下载器
+# SESSION_DOWNLOADER = "feapder.network.downloader.RequestsSessionDownloader"
+# RENDER_DOWNLOADER = "feapder.network.downloader.SeleniumDownloader" # 渲染下载器
+# # RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader"
+# MAKE_ABSOLUTE_LINKS = True # 自动转成绝对连接
+
# # 浏览器渲染
# WEBDRIVER = dict(
# pool_size=1, # 浏览器的数量
@@ -54,24 +64,57 @@
# user_agent=None, # 字符串 或 无参函数,返回值为user_agent
# proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
# headless=False, # 是否为无头浏览器
-# driver_type="CHROME", # CHROME、PHANTOMJS、FIREFOX
+# driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
# timeout=30, # 请求超时时间
# window_size=(1024, 800), # 窗口大小
# executable_path=None, # 浏览器路径,默认为默认路径
# render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
-# custom_argument=["--ignore-certificate-errors"], # 自定义浏览器渲染参数
+# custom_argument=[
+# "--ignore-certificate-errors",
+# "--disable-blink-features=AutomationControlled",
+# ], # 自定义浏览器渲染参数
# xhr_url_regexes=None, # 拦截xhr接口,支持正则,数组类型
-# auto_install_driver=False, # 自动下载浏览器驱动 支持chrome 和 firefox
+# auto_install_driver=True, # 自动下载浏览器驱动 支持chrome 和 firefox
+# download_path=None, # 下载文件的路径
+# use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+# )
+#
+# PLAYWRIGHT = dict(
+# user_agent=None, # 字符串 或 无参函数,返回值为user_agent
+# proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+# headless=False, # 是否为无头浏览器
+# driver_type="chromium", # chromium、firefox、webkit
+# timeout=30, # 请求超时时间
+# window_size=(1024, 800), # 窗口大小
+# executable_path=None, # 浏览器路径,默认为默认路径
+# download_path=None, # 下载文件的路径
+# render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
+# wait_until="networkidle", # 等待页面加载完成的事件,可选值:"commit", "domcontentloaded", "load", "networkidle"
+# use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+# page_on_event_callback=None, # page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()}
+# storage_state_path=None, # 保存浏览器状态的路径
+# url_regexes=None, # 拦截接口,支持正则,数组类型
+# save_all=False, # 是否保存所有拦截的接口, 配合url_regexes使用,为False时只保存最后一次拦截的接口
# )
#
# # 爬虫启动时,重新抓取失败的requests
# RETRY_FAILED_REQUESTS = False
+# # 爬虫启动时,重新入库失败的item
+# RETRY_FAILED_ITEMS = False
# # 保存失败的request
# SAVE_FAILED_REQUEST = True
# # request防丢机制。(指定的REQUEST_LOST_TIMEOUT时间内request还没做完,会重新下发 重做)
# REQUEST_LOST_TIMEOUT = 600 # 10分钟
# # request网络请求超时时间
# REQUEST_TIMEOUT = 22 # 等待服务器响应的超时时间,浮点数,或(connect timeout, read timeout)元组
+# # item在内存队列中最大缓存数量
+# ITEM_MAX_CACHED_COUNT = 5000
+# # item每批入库的最大数量
+# ITEM_UPLOAD_BATCH_MAX_SIZE = 1000
+# # item入库时间间隔
+# ITEM_UPLOAD_INTERVAL = 1
+# # 内存任务队列最大缓存的任务数,默认不限制;仅对AirSpider有效。
+# TASK_MAX_CACHED_SIZE = 0
#
# # 下载缓存 利用redis缓存,但由于内存大小限制,所以建议仅供开发调试代码时使用,防止每次debug都需要网络请求
# RESPONSE_CACHED_ENABLE = False # 是否启用下载缓存 成本高的数据或容易变需求的数据,建议设置为True
@@ -81,12 +124,14 @@
# # 设置代理
# PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n
# PROXY_ENABLE = True
+# PROXY_MAX_FAILED_TIMES = 5 # 代理最大失败次数,超过则不使用,自动删除
+# PROXY_POOL = "feapder.network.proxy_pool.ProxyPool" # 代理池
#
# # 随机headers
# RANDOM_HEADERS = True
# # UserAgent类型 支持 'chrome', 'opera', 'firefox', 'internetexplorer', 'safari','mobile' 若不指定则随机类型
# USER_AGENT_TYPE = "chrome"
-# # 默认使用的浏览器头 RANDOM_HEADERS=True时不生效
+# # 默认使用的浏览器头
# DEFAULT_USERAGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
# # requests 使用session
# USE_SESSION = False
@@ -95,18 +140,25 @@
# ITEM_FILTER_ENABLE = False # item 去重
# REQUEST_FILTER_ENABLE = False # request 去重
# ITEM_FILTER_SETTING = dict(
-# filter_type=1 # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3
+# filter_type=1 # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4
# )
# REQUEST_FILTER_SETTING = dict(
-# filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3
+# filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4
# expire_time=2592000, # 过期时间1个月
# )
#
-# # 报警 支持钉钉、企业微信、邮件
+# # 报警 支持钉钉、飞书、企业微信、邮件
# # 钉钉报警
# DINGDING_WARNING_URL = "" # 钉钉机器人api
-# DINGDING_WARNING_PHONE = "" # 报警人 支持列表,可指定多个
+# DINGDING_WARNING_PHONE = "" # 被@的群成员手机号,支持列表,可指定多个。
+# DINGDING_WARNING_USER_ID = "" # 被@的群成员userId,支持列表,可指定多个
# DINGDING_WARNING_ALL = False # 是否提示所有人, 默认为False
+# DINGDING_WARNING_SECRET = None # 加签密钥
+# # 飞书报警
+# # https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN#e1cdee9f
+# FEISHU_WARNING_URL = "" # 飞书机器人api
+# FEISHU_WARNING_USER = None # 报警人 {"open_id":"ou_xxxxx", "name":"xxxx"} 或 [{"open_id":"ou_xxxxx", "name":"xxxx"}]
+# FEISHU_WARNING_ALL = False # 是否提示所有人, 默认为False
# # 邮件报警
# EMAIL_SENDER = "" # 发件人
# EMAIL_PASSWORD = "" # 授权码
@@ -116,9 +168,13 @@
# WECHAT_WARNING_URL = "" # 企业微信机器人api
# WECHAT_WARNING_PHONE = "" # 报警人 将会在群内@此人, 支持列表,可指定多人
# WECHAT_WARNING_ALL = False # 是否提示所有人, 默认为False
+# # QMSG报警
+# QMSG_WARNING_URL = "" # qmsg机器人api
+# QMSG_WARNING_QQ = "" # 指定要接收消息的QQ号或者QQ群。多个以英文逗号分割,例如:12345,12346,支持列表,可指定多人
+# QMSG_WARNING_BOT = "" # 机器人的QQ号
# # 时间间隔
# WARNING_INTERVAL = 3600 # 相同报警的报警时间间隔,防止刷屏; 0表示不去重
-# WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / ERROR
+# WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / INFO / ERROR
# WARNING_FAILED_COUNT = 1000 # 任务失败数 超过WARNING_FAILED_COUNT则报警
#
# LOG_NAME = os.path.basename(os.getcwd())
diff --git a/feapder/templates/task_spider_template.tmpl b/feapder/templates/task_spider_template.tmpl
new file mode 100644
index 00000000..66bbbba1
--- /dev/null
+++ b/feapder/templates/task_spider_template.tmpl
@@ -0,0 +1,79 @@
+# -*- coding: utf-8 -*-
+"""
+Created on {DATE}
+---------
+@summary:
+---------
+@author: {USER}
+"""
+
+import feapder
+from feapder import ArgumentParser
+
+
+class ${spider_name}(feapder.TaskSpider):
+ # 自定义数据库,若项目中有setting.py文件,此自定义可删除
+ __custom_setting__ = dict(
+ REDISDB_IP_PORTS="localhost:6379",
+ REDISDB_USER_PASS="",
+ REDISDB_DB=0,
+ MYSQL_IP="localhost",
+ MYSQL_PORT=3306,
+ MYSQL_DB="",
+ MYSQL_USER_NAME="",
+ MYSQL_USER_PASS="",
+ )
+
+ def start_requests(self, task):
+ task_id = task.id
+ url = task.url
+ yield feapder.Request(url, task_id=task_id)
+
+ def parse(self, request, response):
+ # 提取网站title
+ print(response.xpath("//title/text()").extract_first())
+ # 提取网站描述
+ print(response.xpath("//meta[@name='description']/@content").extract_first())
+ print("网站地址: ", response.url)
+
+ # mysql 需要更新任务状态为做完 即 state=1
+ yield self.update_task_batch(request.task_id)
+
+
+if __name__ == "__main__":
+ # 用mysql做任务表,需要先建好任务任务表
+ spider = ${spider_name}(
+ redis_key="xxx:xxx", # 分布式爬虫调度信息存储位置
+ task_table="", # mysql中的任务表
+ task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
+ task_state="state", # mysql中任务状态字段
+ )
+
+ # 用redis做任务表
+ # spider = ${spider_name}(
+ # redis_key="xxx:xxxx", # 分布式爬虫调度信息存储位置
+ # task_table="", # 任务表名
+ # task_table_type="redis", # 任务表类型为redis
+ # )
+
+ parser = ArgumentParser(description="${spider_name}爬虫")
+
+ parser.add_argument(
+ "--start_master",
+ action="store_true",
+ help="添加任务",
+ function=spider.start_monitor_task,
+ )
+ parser.add_argument(
+ "--start_worker", action="store_true", help="启动爬虫", function=spider.start
+ )
+
+ parser.start()
+
+ # 直接启动
+ # spider.start() # 启动爬虫
+ # spider.start_monitor_task() # 添加任务
+
+ # 通过命令行启动
+ # python ${file_name} --start_master # 添加任务
+ # python ${file_name} --start_worker # 启动爬虫
\ No newline at end of file
diff --git a/feapder/templates/update_item_template.tmpl b/feapder/templates/update_item_template.tmpl
new file mode 100644
index 00000000..a65f478d
--- /dev/null
+++ b/feapder/templates/update_item_template.tmpl
@@ -0,0 +1,22 @@
+# -*- coding: utf-8 -*-
+"""
+Created on {DATE}
+---------
+@summary:
+---------
+@author: {USER}
+"""
+
+from feapder import UpdateItem
+
+
+class ${item_name}Item(UpdateItem):
+ """
+ This class was generated by feapder
+ command: feapder create -i ${command}
+ """
+
+ __table_name__ = "${table_name}"
+
+ def __init__(self, *args, **kwargs):
+ ${propertys}
diff --git a/feapder/utils/js/stealth.min.js b/feapder/utils/js/stealth.min.js
index e9d51ee8..91784572 100644
--- a/feapder/utils/js/stealth.min.js
+++ b/feapder/utils/js/stealth.min.js
@@ -1,7 +1,7 @@
/*!
* Note: Auto-generated, do not update manually.
* Generated by: https://github.com/berstend/puppeteer-extra/tree/master/packages/extract-stealth-evasions
- * Generated on: Sat, 07 Aug 2021 11:21:42 GMT
+ * Generated on: Sun, 24 Apr 2022 12:07:11 GMT
* License: MIT
*/
-(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:'utils => {\n if (!window.chrome) {\n // Use the exact property descriptor found in headful Chrome\n // fetch it via `Object.getOwnPropertyDescriptor(window, \'chrome\')`\n Object.defineProperty(window, \'chrome\', {\n writable: true,\n enumerable: true,\n configurable: false, // note!\n value: {} // We\'ll extend that later\n })\n }\n\n // That means we\'re running headful and don\'t need to mock anything\n if (\'app\' in window.chrome) {\n return // Nothing to do here\n }\n\n const makeError = {\n ErrorInInvocation: fn => {\n const err = new TypeError(`Error in invocation of app.${fn}()`)\n return utils.stripErrorWithAnchor(\n err,\n `at ${fn} (eval at `\n )\n }\n }\n\n // There\'s a some static data in that property which doesn\'t seem to change,\n // we should periodically check for updates: `JSON.stringify(window.app, null, 2)`\n const STATIC_DATA = JSON.parse(\n `\n{\n "isInstalled": false,\n "InstallState": {\n "DISABLED": "disabled",\n "INSTALLED": "installed",\n "NOT_INSTALLED": "not_installed"\n },\n "RunningState": {\n "CANNOT_RUN": "cannot_run",\n "READY_TO_RUN": "ready_to_run",\n "RUNNING": "running"\n }\n}\n `.trim()\n )\n\n window.chrome.app = {\n ...STATIC_DATA,\n\n get isInstalled() {\n return false\n },\n\n getDetails: function getDetails() {\n if (arguments.length) {\n throw makeError.ErrorInInvocation(`getDetails`)\n }\n return null\n },\n getIsInstalled: function getDetails() {\n if (arguments.length) {\n throw makeError.ErrorInInvocation(`getIsInstalled`)\n }\n return false\n },\n runningState: function getDetails() {\n if (arguments.length) {\n throw makeError.ErrorInInvocation(`runningState`)\n }\n return \'cannot_run\'\n }\n }\n utils.patchToStringNested(window.chrome.app)\n }',_args:[]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"utils => {\n if (!window.chrome) {\n // Use the exact property descriptor found in headful Chrome\n // fetch it via `Object.getOwnPropertyDescriptor(window, 'chrome')`\n Object.defineProperty(window, 'chrome', {\n writable: true,\n enumerable: true,\n configurable: false, // note!\n value: {} // We'll extend that later\n })\n }\n\n // That means we're running headful and don't need to mock anything\n if ('csi' in window.chrome) {\n return // Nothing to do here\n }\n\n // Check that the Navigation Timing API v1 is available, we need that\n if (!window.performance || !window.performance.timing) {\n return\n }\n\n const { timing } = window.performance\n\n window.chrome.csi = function() {\n return {\n onloadT: timing.domContentLoadedEventEnd,\n startE: timing.navigationStart,\n pageT: Date.now() - timing.navigationStart,\n tran: 15 // Transition type or something\n }\n }\n utils.patchToString(window.chrome.csi)\n }",_args:[]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"(utils, { opts }) => {\n if (!window.chrome) {\n // Use the exact property descriptor found in headful Chrome\n // fetch it via `Object.getOwnPropertyDescriptor(window, 'chrome')`\n Object.defineProperty(window, 'chrome', {\n writable: true,\n enumerable: true,\n configurable: false, // note!\n value: {} // We'll extend that later\n })\n }\n\n // That means we're running headful and don't need to mock anything\n if ('loadTimes' in window.chrome) {\n return // Nothing to do here\n }\n\n // Check that the Navigation Timing API v1 + v2 is available, we need that\n if (\n !window.performance ||\n !window.performance.timing ||\n !window.PerformancePaintTiming\n ) {\n return\n }\n\n const { performance } = window\n\n // Some stuff is not available on about:blank as it requires a navigation to occur,\n // let's harden the code to not fail then:\n const ntEntryFallback = {\n nextHopProtocol: 'h2',\n type: 'other'\n }\n\n // The API exposes some funky info regarding the connection\n const protocolInfo = {\n get connectionInfo() {\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ntEntry.nextHopProtocol\n },\n get npnNegotiatedProtocol() {\n // NPN is deprecated in favor of ALPN, but this implementation returns the\n // HTTP/2 or HTTP2+QUIC/39 requests negotiated via ALPN.\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ['h2', 'hq'].includes(ntEntry.nextHopProtocol)\n ? ntEntry.nextHopProtocol\n : 'unknown'\n },\n get navigationType() {\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ntEntry.type\n },\n get wasAlternateProtocolAvailable() {\n // The Alternate-Protocol header is deprecated in favor of Alt-Svc\n // (https://www.mnot.net/blog/2016/03/09/alt-svc), so technically this\n // should always return false.\n return false\n },\n get wasFetchedViaSpdy() {\n // SPDY is deprecated in favor of HTTP/2, but this implementation returns\n // true for HTTP/2 or HTTP2+QUIC/39 as well.\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ['h2', 'hq'].includes(ntEntry.nextHopProtocol)\n },\n get wasNpnNegotiated() {\n // NPN is deprecated in favor of ALPN, but this implementation returns true\n // for HTTP/2 or HTTP2+QUIC/39 requests negotiated via ALPN.\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ['h2', 'hq'].includes(ntEntry.nextHopProtocol)\n }\n }\n\n const { timing } = window.performance\n\n // Truncate number to specific number of decimals, most of the `loadTimes` stuff has 3\n function toFixed(num, fixed) {\n var re = new RegExp('^-?\\\\d+(?:.\\\\d{0,' + (fixed || -1) + '})?')\n return num.toString().match(re)[0]\n }\n\n const timingInfo = {\n get firstPaintAfterLoadTime() {\n // This was never actually implemented and always returns 0.\n return 0\n },\n get requestTime() {\n return timing.navigationStart / 1000\n },\n get startLoadTime() {\n return timing.navigationStart / 1000\n },\n get commitLoadTime() {\n return timing.responseStart / 1000\n },\n get finishDocumentLoadTime() {\n return timing.domContentLoadedEventEnd / 1000\n },\n get finishLoadTime() {\n return timing.loadEventEnd / 1000\n },\n get firstPaintTime() {\n const fpEntry = performance.getEntriesByType('paint')[0] || {\n startTime: timing.loadEventEnd / 1000 // Fallback if no navigation occured (`about:blank`)\n }\n return toFixed(\n (fpEntry.startTime + performance.timeOrigin) / 1000,\n 3\n )\n }\n }\n\n window.chrome.loadTimes = function() {\n return {\n ...protocolInfo,\n ...timingInfo\n }\n }\n utils.patchToString(window.chrome.loadTimes)\n }",_args:[{opts:{}}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"(utils, { opts, STATIC_DATA }) => {\n if (!window.chrome) {\n // Use the exact property descriptor found in headful Chrome\n // fetch it via `Object.getOwnPropertyDescriptor(window, 'chrome')`\n Object.defineProperty(window, 'chrome', {\n writable: true,\n enumerable: true,\n configurable: false, // note!\n value: {} // We'll extend that later\n })\n }\n\n // That means we're running headful and don't need to mock anything\n const existsAlready = 'runtime' in window.chrome\n // `chrome.runtime` is only exposed on secure origins\n const isNotSecure = !window.location.protocol.startsWith('https')\n if (existsAlready || (isNotSecure && !opts.runOnInsecureOrigins)) {\n return // Nothing to do here\n }\n\n window.chrome.runtime = {\n // There's a bunch of static data in that property which doesn't seem to change,\n // we should periodically check for updates: `JSON.stringify(window.chrome.runtime, null, 2)`\n ...STATIC_DATA,\n // `chrome.runtime.id` is extension related and returns undefined in Chrome\n get id() {\n return undefined\n },\n // These two require more sophisticated mocks\n connect: null,\n sendMessage: null\n }\n\n const makeCustomRuntimeErrors = (preamble, method, extensionId) => ({\n NoMatchingSignature: new TypeError(\n preamble + `No matching signature.`\n ),\n MustSpecifyExtensionID: new TypeError(\n preamble +\n `${method} called from a webpage must specify an Extension ID (string) for its first argument.`\n ),\n InvalidExtensionID: new TypeError(\n preamble + `Invalid extension id: '${extensionId}'`\n )\n })\n\n // Valid Extension IDs are 32 characters in length and use the letter `a` to `p`:\n // https://source.chromium.org/chromium/chromium/src/+/master:components/crx_file/id_util.cc;drc=14a055ccb17e8c8d5d437fe080faba4c6f07beac;l=90\n const isValidExtensionID = str =>\n str.length === 32 && str.toLowerCase().match(/^[a-p]+$/)\n\n /** Mock `chrome.runtime.sendMessage` */\n const sendMessageHandler = {\n apply: function(target, ctx, args) {\n const [extensionId, options, responseCallback] = args || []\n\n // Define custom errors\n const errorPreamble = `Error in invocation of runtime.sendMessage(optional string extensionId, any message, optional object options, optional function responseCallback): `\n const Errors = makeCustomRuntimeErrors(\n errorPreamble,\n `chrome.runtime.sendMessage()`,\n extensionId\n )\n\n // Check if the call signature looks ok\n const noArguments = args.length === 0\n const tooManyArguments = args.length > 4\n const incorrectOptions = options && typeof options !== 'object'\n const incorrectResponseCallback =\n responseCallback && typeof responseCallback !== 'function'\n if (\n noArguments ||\n tooManyArguments ||\n incorrectOptions ||\n incorrectResponseCallback\n ) {\n throw Errors.NoMatchingSignature\n }\n\n // At least 2 arguments are required before we even validate the extension ID\n if (args.length < 2) {\n throw Errors.MustSpecifyExtensionID\n }\n\n // Now let's make sure we got a string as extension ID\n if (typeof extensionId !== 'string') {\n throw Errors.NoMatchingSignature\n }\n\n if (!isValidExtensionID(extensionId)) {\n throw Errors.InvalidExtensionID\n }\n\n return undefined // Normal behavior\n }\n }\n utils.mockWithProxy(\n window.chrome.runtime,\n 'sendMessage',\n function sendMessage() {},\n sendMessageHandler\n )\n\n /**\n * Mock `chrome.runtime.connect`\n *\n * @see https://developer.chrome.com/apps/runtime#method-connect\n */\n const connectHandler = {\n apply: function(target, ctx, args) {\n const [extensionId, connectInfo] = args || []\n\n // Define custom errors\n const errorPreamble = `Error in invocation of runtime.connect(optional string extensionId, optional object connectInfo): `\n const Errors = makeCustomRuntimeErrors(\n errorPreamble,\n `chrome.runtime.connect()`,\n extensionId\n )\n\n // Behavior differs a bit from sendMessage:\n const noArguments = args.length === 0\n const emptyStringArgument = args.length === 1 && extensionId === ''\n if (noArguments || emptyStringArgument) {\n throw Errors.MustSpecifyExtensionID\n }\n\n const tooManyArguments = args.length > 2\n const incorrectConnectInfoType =\n connectInfo && typeof connectInfo !== 'object'\n\n if (tooManyArguments || incorrectConnectInfoType) {\n throw Errors.NoMatchingSignature\n }\n\n const extensionIdIsString = typeof extensionId === 'string'\n if (extensionIdIsString && extensionId === '') {\n throw Errors.MustSpecifyExtensionID\n }\n if (extensionIdIsString && !isValidExtensionID(extensionId)) {\n throw Errors.InvalidExtensionID\n }\n\n // There's another edge-case here: extensionId is optional so we might find a connectInfo object as first param, which we need to validate\n const validateConnectInfo = ci => {\n // More than a first param connectInfo as been provided\n if (args.length > 1) {\n throw Errors.NoMatchingSignature\n }\n // An empty connectInfo has been provided\n if (Object.keys(ci).length === 0) {\n throw Errors.MustSpecifyExtensionID\n }\n // Loop over all connectInfo props an check them\n Object.entries(ci).forEach(([k, v]) => {\n const isExpected = ['name', 'includeTlsChannelId'].includes(k)\n if (!isExpected) {\n throw new TypeError(\n errorPreamble + `Unexpected property: '${k}'.`\n )\n }\n const MismatchError = (propName, expected, found) =>\n TypeError(\n errorPreamble +\n `Error at property '${propName}': Invalid type: expected ${expected}, found ${found}.`\n )\n if (k === 'name' && typeof v !== 'string') {\n throw MismatchError(k, 'string', typeof v)\n }\n if (k === 'includeTlsChannelId' && typeof v !== 'boolean') {\n throw MismatchError(k, 'boolean', typeof v)\n }\n })\n }\n if (typeof extensionId === 'object') {\n validateConnectInfo(extensionId)\n throw Errors.MustSpecifyExtensionID\n }\n\n // Unfortunately even when the connect fails Chrome will return an object with methods we need to mock as well\n return utils.patchToStringNested(makeConnectResponse())\n }\n }\n utils.mockWithProxy(\n window.chrome.runtime,\n 'connect',\n function connect() {},\n connectHandler\n )\n\n function makeConnectResponse() {\n const onSomething = () => ({\n addListener: function addListener() {},\n dispatch: function dispatch() {},\n hasListener: function hasListener() {},\n hasListeners: function hasListeners() {\n return false\n },\n removeListener: function removeListener() {}\n })\n\n const response = {\n name: '',\n sender: undefined,\n disconnect: function disconnect() {},\n onDisconnect: onSomething(),\n onMessage: onSomething(),\n postMessage: function postMessage() {\n if (!arguments.length) {\n throw new TypeError(`Insufficient number of arguments.`)\n }\n throw new Error(`Attempting to use a disconnected port object`)\n }\n }\n return response\n }\n }",_args:[{opts:{runOnInsecureOrigins:!1},STATIC_DATA:{OnInstalledReason:{CHROME_UPDATE:"chrome_update",INSTALL:"install",SHARED_MODULE_UPDATE:"shared_module_update",UPDATE:"update"},OnRestartRequiredReason:{APP_UPDATE:"app_update",OS_UPDATE:"os_update",PERIODIC:"periodic"},PlatformArch:{ARM:"arm",ARM64:"arm64",MIPS:"mips",MIPS64:"mips64",X86_32:"x86-32",X86_64:"x86-64"},PlatformNaclArch:{ARM:"arm",MIPS:"mips",MIPS64:"mips64",X86_32:"x86-32",X86_64:"x86-64"},PlatformOs:{ANDROID:"android",CROS:"cros",LINUX:"linux",MAC:"mac",OPENBSD:"openbsd",WIN:"win"},RequestUpdateCheckStatus:{NO_UPDATE:"no_update",THROTTLED:"throttled",UPDATE_AVAILABLE:"update_available"}}}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"utils => {\n /**\n * Input might look funky, we need to normalize it so e.g. whitespace isn't an issue for our spoofing.\n *\n * @example\n * video/webm; codecs=\"vp8, vorbis\"\n * video/mp4; codecs=\"avc1.42E01E\"\n * audio/x-m4a;\n * audio/ogg; codecs=\"vorbis\"\n * @param {String} arg\n */\n const parseInput = arg => {\n const [mime, codecStr] = arg.trim().split(';')\n let codecs = []\n if (codecStr && codecStr.includes('codecs=\"')) {\n codecs = codecStr\n .trim()\n .replace(`codecs=\"`, '')\n .replace(`\"`, '')\n .trim()\n .split(',')\n .filter(x => !!x)\n .map(x => x.trim())\n }\n return {\n mime,\n codecStr,\n codecs\n }\n }\n\n const canPlayType = {\n // Intercept certain requests\n apply: function(target, ctx, args) {\n if (!args || !args.length) {\n return target.apply(ctx, args)\n }\n const { mime, codecs } = parseInput(args[0])\n // This specific mp4 codec is missing in Chromium\n if (mime === 'video/mp4') {\n if (codecs.includes('avc1.42E01E')) {\n return 'probably'\n }\n }\n // This mimetype is only supported if no codecs are specified\n if (mime === 'audio/x-m4a' && !codecs.length) {\n return 'maybe'\n }\n\n // This mimetype is only supported if no codecs are specified\n if (mime === 'audio/aac' && !codecs.length) {\n return 'probably'\n }\n // Everything else as usual\n return target.apply(ctx, args)\n }\n }\n\n /* global HTMLMediaElement */\n utils.replaceWithProxy(\n HTMLMediaElement.prototype,\n 'canPlayType',\n canPlayType\n )\n }",_args:[]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"(utils, { opts }) => {\n utils.replaceGetterWithProxy(\n Object.getPrototypeOf(navigator),\n 'hardwareConcurrency',\n utils.makeHandler().getterValue(opts.hardwareConcurrency)\n )\n }",_args:[{opts:{hardwareConcurrency:4}}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"(utils, { opts }) => {\n const languages = opts.languages.length\n ? opts.languages\n : ['en-US', 'en']\n utils.replaceGetterWithProxy(\n Object.getPrototypeOf(navigator),\n 'languages',\n utils.makeHandler().getterValue(Object.freeze([...languages]))\n )\n }",_args:[{opts:{languages:[]}}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"(utils, opts) => {\n const isSecure = document.location.protocol.startsWith('https')\n\n // In headful on secure origins the permission should be \"default\", not \"denied\"\n if (isSecure) {\n utils.replaceGetterWithProxy(Notification, 'permission', {\n apply() {\n return 'default'\n }\n })\n }\n\n // Another weird behavior:\n // On insecure origins in headful the state is \"denied\",\n // whereas in headless it's \"prompt\"\n if (!isSecure) {\n const handler = {\n apply(target, ctx, args) {\n const param = (args || [])[0]\n\n const isNotifications =\n param && param.name && param.name === 'notifications'\n if (!isNotifications) {\n return utils.cache.Reflect.apply(...arguments)\n }\n\n return Promise.resolve(\n Object.setPrototypeOf(\n {\n state: 'denied',\n onchange: null\n },\n PermissionStatus.prototype\n )\n )\n }\n }\n // Note: Don't use `Object.getPrototypeOf` here\n utils.replaceWithProxy(Permissions.prototype, 'query', handler)\n }\n }",_args:[{}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"(utils, { fns, data }) => {\n fns = utils.materializeFns(fns)\n\n // That means we're running headful\n const hasPlugins = 'plugins' in navigator && navigator.plugins.length\n if (hasPlugins) {\n return // nothing to do here\n }\n\n const mimeTypes = fns.generateMimeTypeArray(utils, fns)(data.mimeTypes)\n const plugins = fns.generatePluginArray(utils, fns)(data.plugins)\n\n // Plugin and MimeType cross-reference each other, let's do that now\n // Note: We're looping through `data.plugins` here, not the generated `plugins`\n for (const pluginData of data.plugins) {\n pluginData.__mimeTypes.forEach((type, index) => {\n plugins[pluginData.name][index] = mimeTypes[type]\n\n Object.defineProperty(plugins[pluginData.name], type, {\n value: mimeTypes[type],\n writable: false,\n enumerable: false, // Not enumerable\n configurable: true\n })\n Object.defineProperty(mimeTypes[type], 'enabledPlugin', {\n value:\n type === 'application/x-pnacl'\n ? mimeTypes['application/x-nacl'].enabledPlugin // these reference the same plugin, so we need to re-use the Proxy in order to avoid leaks\n : new Proxy(plugins[pluginData.name], {}), // Prevent circular references\n writable: false,\n enumerable: false, // Important: `JSON.stringify(navigator.plugins)`\n configurable: true\n })\n })\n }\n\n const patchNavigator = (name, value) =>\n utils.replaceProperty(Object.getPrototypeOf(navigator), name, {\n get() {\n return value\n }\n })\n\n patchNavigator('mimeTypes', mimeTypes)\n patchNavigator('plugins', plugins)\n\n // All done\n }",_args:[{fns:{generateMimeTypeArray:"(utils, fns) => mimeTypesData => {\n return fns.generateMagicArray(utils, fns)(\n mimeTypesData,\n MimeTypeArray.prototype,\n MimeType.prototype,\n 'type'\n )\n}",generatePluginArray:"(utils, fns) => pluginsData => {\n return fns.generateMagicArray(utils, fns)(\n pluginsData,\n PluginArray.prototype,\n Plugin.prototype,\n 'name'\n )\n}",generateMagicArray:"(utils, fns) =>\n function(\n dataArray = [],\n proto = MimeTypeArray.prototype,\n itemProto = MimeType.prototype,\n itemMainProp = 'type'\n ) {\n // Quick helper to set props with the same descriptors vanilla is using\n const defineProp = (obj, prop, value) =>\n Object.defineProperty(obj, prop, {\n value,\n writable: false,\n enumerable: false, // Important for mimeTypes & plugins: `JSON.stringify(navigator.mimeTypes)`\n configurable: true\n })\n\n // Loop over our fake data and construct items\n const makeItem = data => {\n const item = {}\n for (const prop of Object.keys(data)) {\n if (prop.startsWith('__')) {\n continue\n }\n defineProp(item, prop, data[prop])\n }\n return patchItem(item, data)\n }\n\n const patchItem = (item, data) => {\n let descriptor = Object.getOwnPropertyDescriptors(item)\n\n // Special case: Plugins have a magic length property which is not enumerable\n // e.g. `navigator.plugins[i].length` should always be the length of the assigned mimeTypes\n if (itemProto === Plugin.prototype) {\n descriptor = {\n ...descriptor,\n length: {\n value: data.__mimeTypes.length,\n writable: false,\n enumerable: false,\n configurable: true // Important to be able to use the ownKeys trap in a Proxy to strip `length`\n }\n }\n }\n\n // We need to spoof a specific `MimeType` or `Plugin` object\n const obj = Object.create(itemProto, descriptor)\n\n // Virtually all property keys are not enumerable in vanilla\n const blacklist = [...Object.keys(data), 'length', 'enabledPlugin']\n return new Proxy(obj, {\n ownKeys(target) {\n return Reflect.ownKeys(target).filter(k => !blacklist.includes(k))\n },\n getOwnPropertyDescriptor(target, prop) {\n if (blacklist.includes(prop)) {\n return undefined\n }\n return Reflect.getOwnPropertyDescriptor(target, prop)\n }\n })\n }\n\n const magicArray = []\n\n // Loop through our fake data and use that to create convincing entities\n dataArray.forEach(data => {\n magicArray.push(makeItem(data))\n })\n\n // Add direct property access based on types (e.g. `obj['application/pdf']`) afterwards\n magicArray.forEach(entry => {\n defineProp(magicArray, entry[itemMainProp], entry)\n })\n\n // This is the best way to fake the type to make sure this is false: `Array.isArray(navigator.mimeTypes)`\n const magicArrayObj = Object.create(proto, {\n ...Object.getOwnPropertyDescriptors(magicArray),\n\n // There's one ugly quirk we unfortunately need to take care of:\n // The `MimeTypeArray` prototype has an enumerable `length` property,\n // but headful Chrome will still skip it when running `Object.getOwnPropertyNames(navigator.mimeTypes)`.\n // To strip it we need to make it first `configurable` and can then overlay a Proxy with an `ownKeys` trap.\n length: {\n value: magicArray.length,\n writable: false,\n enumerable: false,\n configurable: true // Important to be able to use the ownKeys trap in a Proxy to strip `length`\n }\n })\n\n // Generate our functional function mocks :-)\n const functionMocks = fns.generateFunctionMocks(utils)(\n proto,\n itemMainProp,\n magicArray\n )\n\n // We need to overlay our custom object with a JS Proxy\n const magicArrayObjProxy = new Proxy(magicArrayObj, {\n get(target, key = '') {\n // Redirect function calls to our custom proxied versions mocking the vanilla behavior\n if (key === 'item') {\n return functionMocks.item\n }\n if (key === 'namedItem') {\n return functionMocks.namedItem\n }\n if (proto === PluginArray.prototype && key === 'refresh') {\n return functionMocks.refresh\n }\n // Everything else can pass through as normal\n return utils.cache.Reflect.get(...arguments)\n },\n ownKeys(target) {\n // There are a couple of quirks where the original property demonstrates \"magical\" behavior that makes no sense\n // This can be witnessed when calling `Object.getOwnPropertyNames(navigator.mimeTypes)` and the absense of `length`\n // My guess is that it has to do with the recent change of not allowing data enumeration and this being implemented weirdly\n // For that reason we just completely fake the available property names based on our data to match what regular Chrome is doing\n // Specific issues when not patching this: `length` property is available, direct `types` props (e.g. `obj['application/pdf']`) are missing\n const keys = []\n const typeProps = magicArray.map(mt => mt[itemMainProp])\n typeProps.forEach((_, i) => keys.push(`${i}`))\n typeProps.forEach(propName => keys.push(propName))\n return keys\n },\n getOwnPropertyDescriptor(target, prop) {\n if (prop === 'length') {\n return undefined\n }\n return Reflect.getOwnPropertyDescriptor(target, prop)\n }\n })\n\n return magicArrayObjProxy\n }",generateFunctionMocks:"utils => (\n proto,\n itemMainProp,\n dataArray\n) => ({\n /** Returns the MimeType object with the specified index. */\n item: utils.createProxy(proto.item, {\n apply(target, ctx, args) {\n if (!args.length) {\n throw new TypeError(\n `Failed to execute 'item' on '${\n proto[Symbol.toStringTag]\n }': 1 argument required, but only 0 present.`\n )\n }\n // Special behavior alert:\n // - Vanilla tries to cast strings to Numbers (only integers!) and use them as property index lookup\n // - If anything else than an integer (including as string) is provided it will return the first entry\n const isInteger = args[0] && Number.isInteger(Number(args[0])) // Cast potential string to number first, then check for integer\n // Note: Vanilla never returns `undefined`\n return (isInteger ? dataArray[Number(args[0])] : dataArray[0]) || null\n }\n }),\n /** Returns the MimeType object with the specified name. */\n namedItem: utils.createProxy(proto.namedItem, {\n apply(target, ctx, args) {\n if (!args.length) {\n throw new TypeError(\n `Failed to execute 'namedItem' on '${\n proto[Symbol.toStringTag]\n }': 1 argument required, but only 0 present.`\n )\n }\n return dataArray.find(mt => mt[itemMainProp] === args[0]) || null // Not `undefined`!\n }\n }),\n /** Does nothing and shall return nothing */\n refresh: proto.refresh\n ? utils.createProxy(proto.refresh, {\n apply(target, ctx, args) {\n return undefined\n }\n })\n : undefined\n})"},data:{mimeTypes:[{type:"application/pdf",suffixes:"pdf",description:"",__pluginName:"Chrome PDF Viewer"},{type:"application/x-google-chrome-pdf",suffixes:"pdf",description:"Portable Document Format",__pluginName:"Chrome PDF Plugin"},{type:"application/x-nacl",suffixes:"",description:"Native Client Executable",__pluginName:"Native Client"},{type:"application/x-pnacl",suffixes:"",description:"Portable Native Client Executable",__pluginName:"Native Client"}],plugins:[{name:"Chrome PDF Plugin",filename:"internal-pdf-viewer",description:"Portable Document Format",__mimeTypes:["application/x-google-chrome-pdf"]},{name:"Chrome PDF Viewer",filename:"mhjfbmdgcfjbbpaeojofohoefgiehjai",description:"",__mimeTypes:["application/pdf"]},{name:"Native Client",filename:"internal-nacl-plugin",description:"",__mimeTypes:["application/x-nacl","application/x-pnacl"]}]}}]}),!1===navigator.webdriver||void 0===navigator.webdriver||delete Object.getPrototypeOf(navigator).webdriver,(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"(utils, opts) => {\n const getParameterProxyHandler = {\n apply: function(target, ctx, args) {\n const param = (args || [])[0]\n const result = utils.cache.Reflect.apply(target, ctx, args)\n // UNMASKED_VENDOR_WEBGL\n if (param === 37445) {\n return opts.vendor || 'Intel Inc.' // default in headless: Google Inc.\n }\n // UNMASKED_RENDERER_WEBGL\n if (param === 37446) {\n return opts.renderer || 'Intel Iris OpenGL Engine' // default in headless: Google SwiftShader\n }\n return result\n }\n }\n\n // There's more than one WebGL rendering context\n // https://developer.mozilla.org/en-US/docs/Web/API/WebGL2RenderingContext#Browser_compatibility\n // To find out the original values here: Object.getOwnPropertyDescriptors(WebGLRenderingContext.prototype.getParameter)\n const addProxy = (obj, propName) => {\n utils.replaceWithProxy(obj, propName, getParameterProxyHandler)\n }\n // For whatever weird reason loops don't play nice with Object.defineProperty, here's the next best thing:\n addProxy(WebGLRenderingContext.prototype, 'getParameter')\n addProxy(WebGL2RenderingContext.prototype, 'getParameter')\n }",_args:[{}]}),(()=>{try{if(window.outerWidth&&window.outerHeight)return;const n=85;window.outerWidth=window.innerWidth,window.outerHeight=window.innerHeight+n}catch(n){}})(),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {}\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n const ret = utils.cache.Reflect.apply(...arguments)\n if (args && args.length === 0) {\n return value\n }\n return ret\n }\n })\n})"},_mainFunction:"(utils, opts) => {\n try {\n // Adds a contentWindow proxy to the provided iframe element\n const addContentWindowProxy = iframe => {\n const contentWindowProxy = {\n get(target, key) {\n // Now to the interesting part:\n // We actually make this thing behave like a regular iframe window,\n // by intercepting calls to e.g. `.self` and redirect it to the correct thing. :)\n // That makes it possible for these assertions to be correct:\n // iframe.contentWindow.self === window.top // must be false\n if (key === 'self') {\n return this\n }\n // iframe.contentWindow.frameElement === iframe // must be true\n if (key === 'frameElement') {\n return iframe\n }\n return Reflect.get(target, key)\n }\n }\n\n if (!iframe.contentWindow) {\n const proxy = new Proxy(window, contentWindowProxy)\n Object.defineProperty(iframe, 'contentWindow', {\n get() {\n return proxy\n },\n set(newValue) {\n return newValue // contentWindow is immutable\n },\n enumerable: true,\n configurable: false\n })\n }\n }\n\n // Handles iframe element creation, augments `srcdoc` property so we can intercept further\n const handleIframeCreation = (target, thisArg, args) => {\n const iframe = target.apply(thisArg, args)\n\n // We need to keep the originals around\n const _iframe = iframe\n const _srcdoc = _iframe.srcdoc\n\n // Add hook for the srcdoc property\n // We need to be very surgical here to not break other iframes by accident\n Object.defineProperty(iframe, 'srcdoc', {\n configurable: true, // Important, so we can reset this later\n get: function() {\n return _iframe.srcdoc\n },\n set: function(newValue) {\n addContentWindowProxy(this)\n // Reset property, the hook is only needed once\n Object.defineProperty(iframe, 'srcdoc', {\n configurable: false,\n writable: false,\n value: _srcdoc\n })\n _iframe.srcdoc = newValue\n }\n })\n return iframe\n }\n\n // Adds a hook to intercept iframe creation events\n const addIframeCreationSniffer = () => {\n /* global document */\n const createElementHandler = {\n // Make toString() native\n get(target, key) {\n return Reflect.get(target, key)\n },\n apply: function(target, thisArg, args) {\n const isIframe =\n args && args.length && `${args[0]}`.toLowerCase() === 'iframe'\n if (!isIframe) {\n // Everything as usual\n return target.apply(thisArg, args)\n } else {\n return handleIframeCreation(target, thisArg, args)\n }\n }\n }\n // All this just due to iframes with srcdoc bug\n utils.replaceWithProxy(\n document,\n 'createElement',\n createElementHandler\n )\n }\n\n // Let's go\n addIframeCreationSniffer()\n } catch (err) {\n // console.warn(err)\n }\n }",_args:[]});
\ No newline at end of file
+(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:'utils => {\n if (!window.chrome) {\n // Use the exact property descriptor found in headful Chrome\n // fetch it via `Object.getOwnPropertyDescriptor(window, \'chrome\')`\n Object.defineProperty(window, \'chrome\', {\n writable: true,\n enumerable: true,\n configurable: false, // note!\n value: {} // We\'ll extend that later\n })\n }\n\n // That means we\'re running headful and don\'t need to mock anything\n if (\'app\' in window.chrome) {\n return // Nothing to do here\n }\n\n const makeError = {\n ErrorInInvocation: fn => {\n const err = new TypeError(`Error in invocation of app.${fn}()`)\n return utils.stripErrorWithAnchor(\n err,\n `at ${fn} (eval at `\n )\n }\n }\n\n // There\'s a some static data in that property which doesn\'t seem to change,\n // we should periodically check for updates: `JSON.stringify(window.app, null, 2)`\n const STATIC_DATA = JSON.parse(\n `\n{\n "isInstalled": false,\n "InstallState": {\n "DISABLED": "disabled",\n "INSTALLED": "installed",\n "NOT_INSTALLED": "not_installed"\n },\n "RunningState": {\n "CANNOT_RUN": "cannot_run",\n "READY_TO_RUN": "ready_to_run",\n "RUNNING": "running"\n }\n}\n `.trim()\n )\n\n window.chrome.app = {\n ...STATIC_DATA,\n\n get isInstalled() {\n return false\n },\n\n getDetails: function getDetails() {\n if (arguments.length) {\n throw makeError.ErrorInInvocation(`getDetails`)\n }\n return null\n },\n getIsInstalled: function getDetails() {\n if (arguments.length) {\n throw makeError.ErrorInInvocation(`getIsInstalled`)\n }\n return false\n },\n runningState: function getDetails() {\n if (arguments.length) {\n throw makeError.ErrorInInvocation(`runningState`)\n }\n return \'cannot_run\'\n }\n }\n utils.patchToStringNested(window.chrome.app)\n }',_args:[]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"utils => {\n if (!window.chrome) {\n // Use the exact property descriptor found in headful Chrome\n // fetch it via `Object.getOwnPropertyDescriptor(window, 'chrome')`\n Object.defineProperty(window, 'chrome', {\n writable: true,\n enumerable: true,\n configurable: false, // note!\n value: {} // We'll extend that later\n })\n }\n\n // That means we're running headful and don't need to mock anything\n if ('csi' in window.chrome) {\n return // Nothing to do here\n }\n\n // Check that the Navigation Timing API v1 is available, we need that\n if (!window.performance || !window.performance.timing) {\n return\n }\n\n const { timing } = window.performance\n\n window.chrome.csi = function() {\n return {\n onloadT: timing.domContentLoadedEventEnd,\n startE: timing.navigationStart,\n pageT: Date.now() - timing.navigationStart,\n tran: 15 // Transition type or something\n }\n }\n utils.patchToString(window.chrome.csi)\n }",_args:[]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"(utils, { opts }) => {\n if (!window.chrome) {\n // Use the exact property descriptor found in headful Chrome\n // fetch it via `Object.getOwnPropertyDescriptor(window, 'chrome')`\n Object.defineProperty(window, 'chrome', {\n writable: true,\n enumerable: true,\n configurable: false, // note!\n value: {} // We'll extend that later\n })\n }\n\n // That means we're running headful and don't need to mock anything\n if ('loadTimes' in window.chrome) {\n return // Nothing to do here\n }\n\n // Check that the Navigation Timing API v1 + v2 is available, we need that\n if (\n !window.performance ||\n !window.performance.timing ||\n !window.PerformancePaintTiming\n ) {\n return\n }\n\n const { performance } = window\n\n // Some stuff is not available on about:blank as it requires a navigation to occur,\n // let's harden the code to not fail then:\n const ntEntryFallback = {\n nextHopProtocol: 'h2',\n type: 'other'\n }\n\n // The API exposes some funky info regarding the connection\n const protocolInfo = {\n get connectionInfo() {\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ntEntry.nextHopProtocol\n },\n get npnNegotiatedProtocol() {\n // NPN is deprecated in favor of ALPN, but this implementation returns the\n // HTTP/2 or HTTP2+QUIC/39 requests negotiated via ALPN.\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ['h2', 'hq'].includes(ntEntry.nextHopProtocol)\n ? ntEntry.nextHopProtocol\n : 'unknown'\n },\n get navigationType() {\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ntEntry.type\n },\n get wasAlternateProtocolAvailable() {\n // The Alternate-Protocol header is deprecated in favor of Alt-Svc\n // (https://www.mnot.net/blog/2016/03/09/alt-svc), so technically this\n // should always return false.\n return false\n },\n get wasFetchedViaSpdy() {\n // SPDY is deprecated in favor of HTTP/2, but this implementation returns\n // true for HTTP/2 or HTTP2+QUIC/39 as well.\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ['h2', 'hq'].includes(ntEntry.nextHopProtocol)\n },\n get wasNpnNegotiated() {\n // NPN is deprecated in favor of ALPN, but this implementation returns true\n // for HTTP/2 or HTTP2+QUIC/39 requests negotiated via ALPN.\n const ntEntry =\n performance.getEntriesByType('navigation')[0] || ntEntryFallback\n return ['h2', 'hq'].includes(ntEntry.nextHopProtocol)\n }\n }\n\n const { timing } = window.performance\n\n // Truncate number to specific number of decimals, most of the `loadTimes` stuff has 3\n function toFixed(num, fixed) {\n var re = new RegExp('^-?\\\\d+(?:.\\\\d{0,' + (fixed || -1) + '})?')\n return num.toString().match(re)[0]\n }\n\n const timingInfo = {\n get firstPaintAfterLoadTime() {\n // This was never actually implemented and always returns 0.\n return 0\n },\n get requestTime() {\n return timing.navigationStart / 1000\n },\n get startLoadTime() {\n return timing.navigationStart / 1000\n },\n get commitLoadTime() {\n return timing.responseStart / 1000\n },\n get finishDocumentLoadTime() {\n return timing.domContentLoadedEventEnd / 1000\n },\n get finishLoadTime() {\n return timing.loadEventEnd / 1000\n },\n get firstPaintTime() {\n const fpEntry = performance.getEntriesByType('paint')[0] || {\n startTime: timing.loadEventEnd / 1000 // Fallback if no navigation occured (`about:blank`)\n }\n return toFixed(\n (fpEntry.startTime + performance.timeOrigin) / 1000,\n 3\n )\n }\n }\n\n window.chrome.loadTimes = function() {\n return {\n ...protocolInfo,\n ...timingInfo\n }\n }\n utils.patchToString(window.chrome.loadTimes)\n }",_args:[{opts:{}}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"(utils, { opts, STATIC_DATA }) => {\n if (!window.chrome) {\n // Use the exact property descriptor found in headful Chrome\n // fetch it via `Object.getOwnPropertyDescriptor(window, 'chrome')`\n Object.defineProperty(window, 'chrome', {\n writable: true,\n enumerable: true,\n configurable: false, // note!\n value: {} // We'll extend that later\n })\n }\n\n // That means we're running headful and don't need to mock anything\n const existsAlready = 'runtime' in window.chrome\n // `chrome.runtime` is only exposed on secure origins\n const isNotSecure = !window.location.protocol.startsWith('https')\n if (existsAlready || (isNotSecure && !opts.runOnInsecureOrigins)) {\n return // Nothing to do here\n }\n\n window.chrome.runtime = {\n // There's a bunch of static data in that property which doesn't seem to change,\n // we should periodically check for updates: `JSON.stringify(window.chrome.runtime, null, 2)`\n ...STATIC_DATA,\n // `chrome.runtime.id` is extension related and returns undefined in Chrome\n get id() {\n return undefined\n },\n // These two require more sophisticated mocks\n connect: null,\n sendMessage: null\n }\n\n const makeCustomRuntimeErrors = (preamble, method, extensionId) => ({\n NoMatchingSignature: new TypeError(\n preamble + `No matching signature.`\n ),\n MustSpecifyExtensionID: new TypeError(\n preamble +\n `${method} called from a webpage must specify an Extension ID (string) for its first argument.`\n ),\n InvalidExtensionID: new TypeError(\n preamble + `Invalid extension id: '${extensionId}'`\n )\n })\n\n // Valid Extension IDs are 32 characters in length and use the letter `a` to `p`:\n // https://source.chromium.org/chromium/chromium/src/+/master:components/crx_file/id_util.cc;drc=14a055ccb17e8c8d5d437fe080faba4c6f07beac;l=90\n const isValidExtensionID = str =>\n str.length === 32 && str.toLowerCase().match(/^[a-p]+$/)\n\n /** Mock `chrome.runtime.sendMessage` */\n const sendMessageHandler = {\n apply: function(target, ctx, args) {\n const [extensionId, options, responseCallback] = args || []\n\n // Define custom errors\n const errorPreamble = `Error in invocation of runtime.sendMessage(optional string extensionId, any message, optional object options, optional function responseCallback): `\n const Errors = makeCustomRuntimeErrors(\n errorPreamble,\n `chrome.runtime.sendMessage()`,\n extensionId\n )\n\n // Check if the call signature looks ok\n const noArguments = args.length === 0\n const tooManyArguments = args.length > 4\n const incorrectOptions = options && typeof options !== 'object'\n const incorrectResponseCallback =\n responseCallback && typeof responseCallback !== 'function'\n if (\n noArguments ||\n tooManyArguments ||\n incorrectOptions ||\n incorrectResponseCallback\n ) {\n throw Errors.NoMatchingSignature\n }\n\n // At least 2 arguments are required before we even validate the extension ID\n if (args.length < 2) {\n throw Errors.MustSpecifyExtensionID\n }\n\n // Now let's make sure we got a string as extension ID\n if (typeof extensionId !== 'string') {\n throw Errors.NoMatchingSignature\n }\n\n if (!isValidExtensionID(extensionId)) {\n throw Errors.InvalidExtensionID\n }\n\n return undefined // Normal behavior\n }\n }\n utils.mockWithProxy(\n window.chrome.runtime,\n 'sendMessage',\n function sendMessage() {},\n sendMessageHandler\n )\n\n /**\n * Mock `chrome.runtime.connect`\n *\n * @see https://developer.chrome.com/apps/runtime#method-connect\n */\n const connectHandler = {\n apply: function(target, ctx, args) {\n const [extensionId, connectInfo] = args || []\n\n // Define custom errors\n const errorPreamble = `Error in invocation of runtime.connect(optional string extensionId, optional object connectInfo): `\n const Errors = makeCustomRuntimeErrors(\n errorPreamble,\n `chrome.runtime.connect()`,\n extensionId\n )\n\n // Behavior differs a bit from sendMessage:\n const noArguments = args.length === 0\n const emptyStringArgument = args.length === 1 && extensionId === ''\n if (noArguments || emptyStringArgument) {\n throw Errors.MustSpecifyExtensionID\n }\n\n const tooManyArguments = args.length > 2\n const incorrectConnectInfoType =\n connectInfo && typeof connectInfo !== 'object'\n\n if (tooManyArguments || incorrectConnectInfoType) {\n throw Errors.NoMatchingSignature\n }\n\n const extensionIdIsString = typeof extensionId === 'string'\n if (extensionIdIsString && extensionId === '') {\n throw Errors.MustSpecifyExtensionID\n }\n if (extensionIdIsString && !isValidExtensionID(extensionId)) {\n throw Errors.InvalidExtensionID\n }\n\n // There's another edge-case here: extensionId is optional so we might find a connectInfo object as first param, which we need to validate\n const validateConnectInfo = ci => {\n // More than a first param connectInfo as been provided\n if (args.length > 1) {\n throw Errors.NoMatchingSignature\n }\n // An empty connectInfo has been provided\n if (Object.keys(ci).length === 0) {\n throw Errors.MustSpecifyExtensionID\n }\n // Loop over all connectInfo props an check them\n Object.entries(ci).forEach(([k, v]) => {\n const isExpected = ['name', 'includeTlsChannelId'].includes(k)\n if (!isExpected) {\n throw new TypeError(\n errorPreamble + `Unexpected property: '${k}'.`\n )\n }\n const MismatchError = (propName, expected, found) =>\n TypeError(\n errorPreamble +\n `Error at property '${propName}': Invalid type: expected ${expected}, found ${found}.`\n )\n if (k === 'name' && typeof v !== 'string') {\n throw MismatchError(k, 'string', typeof v)\n }\n if (k === 'includeTlsChannelId' && typeof v !== 'boolean') {\n throw MismatchError(k, 'boolean', typeof v)\n }\n })\n }\n if (typeof extensionId === 'object') {\n validateConnectInfo(extensionId)\n throw Errors.MustSpecifyExtensionID\n }\n\n // Unfortunately even when the connect fails Chrome will return an object with methods we need to mock as well\n return utils.patchToStringNested(makeConnectResponse())\n }\n }\n utils.mockWithProxy(\n window.chrome.runtime,\n 'connect',\n function connect() {},\n connectHandler\n )\n\n function makeConnectResponse() {\n const onSomething = () => ({\n addListener: function addListener() {},\n dispatch: function dispatch() {},\n hasListener: function hasListener() {},\n hasListeners: function hasListeners() {\n return false\n },\n removeListener: function removeListener() {}\n })\n\n const response = {\n name: '',\n sender: undefined,\n disconnect: function disconnect() {},\n onDisconnect: onSomething(),\n onMessage: onSomething(),\n postMessage: function postMessage() {\n if (!arguments.length) {\n throw new TypeError(`Insufficient number of arguments.`)\n }\n throw new Error(`Attempting to use a disconnected port object`)\n }\n }\n return response\n }\n }",_args:[{opts:{runOnInsecureOrigins:!1},STATIC_DATA:{OnInstalledReason:{CHROME_UPDATE:"chrome_update",INSTALL:"install",SHARED_MODULE_UPDATE:"shared_module_update",UPDATE:"update"},OnRestartRequiredReason:{APP_UPDATE:"app_update",OS_UPDATE:"os_update",PERIODIC:"periodic"},PlatformArch:{ARM:"arm",ARM64:"arm64",MIPS:"mips",MIPS64:"mips64",X86_32:"x86-32",X86_64:"x86-64"},PlatformNaclArch:{ARM:"arm",MIPS:"mips",MIPS64:"mips64",X86_32:"x86-32",X86_64:"x86-64"},PlatformOs:{ANDROID:"android",CROS:"cros",LINUX:"linux",MAC:"mac",OPENBSD:"openbsd",WIN:"win"},RequestUpdateCheckStatus:{NO_UPDATE:"no_update",THROTTLED:"throttled",UPDATE_AVAILABLE:"update_available"}}}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"utils => {\n /**\n * Input might look funky, we need to normalize it so e.g. whitespace isn't an issue for our spoofing.\n *\n * @example\n * video/webm; codecs=\"vp8, vorbis\"\n * video/mp4; codecs=\"avc1.42E01E\"\n * audio/x-m4a;\n * audio/ogg; codecs=\"vorbis\"\n * @param {String} arg\n */\n const parseInput = arg => {\n const [mime, codecStr] = arg.trim().split(';')\n let codecs = []\n if (codecStr && codecStr.includes('codecs=\"')) {\n codecs = codecStr\n .trim()\n .replace(`codecs=\"`, '')\n .replace(`\"`, '')\n .trim()\n .split(',')\n .filter(x => !!x)\n .map(x => x.trim())\n }\n return {\n mime,\n codecStr,\n codecs\n }\n }\n\n const canPlayType = {\n // Intercept certain requests\n apply: function(target, ctx, args) {\n if (!args || !args.length) {\n return target.apply(ctx, args)\n }\n const { mime, codecs } = parseInput(args[0])\n // This specific mp4 codec is missing in Chromium\n if (mime === 'video/mp4') {\n if (codecs.includes('avc1.42E01E')) {\n return 'probably'\n }\n }\n // This mimetype is only supported if no codecs are specified\n if (mime === 'audio/x-m4a' && !codecs.length) {\n return 'maybe'\n }\n\n // This mimetype is only supported if no codecs are specified\n if (mime === 'audio/aac' && !codecs.length) {\n return 'probably'\n }\n // Everything else as usual\n return target.apply(ctx, args)\n }\n }\n\n /* global HTMLMediaElement */\n utils.replaceWithProxy(\n HTMLMediaElement.prototype,\n 'canPlayType',\n canPlayType\n )\n }",_args:[]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"(utils, { opts }) => {\n utils.replaceGetterWithProxy(\n Object.getPrototypeOf(navigator),\n 'hardwareConcurrency',\n utils.makeHandler().getterValue(opts.hardwareConcurrency)\n )\n }",_args:[{opts:{hardwareConcurrency:4}}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"(utils, { opts }) => {\n const languages = opts.languages.length\n ? opts.languages\n : ['en-US', 'en']\n utils.replaceGetterWithProxy(\n Object.getPrototypeOf(navigator),\n 'languages',\n utils.makeHandler().getterValue(Object.freeze([...languages]))\n )\n }",_args:[{opts:{languages:[]}}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"(utils, opts) => {\n const isSecure = document.location.protocol.startsWith('https')\n\n // In headful on secure origins the permission should be \"default\", not \"denied\"\n if (isSecure) {\n utils.replaceGetterWithProxy(Notification, 'permission', {\n apply() {\n return 'default'\n }\n })\n }\n\n // Another weird behavior:\n // On insecure origins in headful the state is \"denied\",\n // whereas in headless it's \"prompt\"\n if (!isSecure) {\n const handler = {\n apply(target, ctx, args) {\n const param = (args || [])[0]\n\n const isNotifications =\n param && param.name && param.name === 'notifications'\n if (!isNotifications) {\n return utils.cache.Reflect.apply(...arguments)\n }\n\n return Promise.resolve(\n Object.setPrototypeOf(\n {\n state: 'denied',\n onchange: null\n },\n PermissionStatus.prototype\n )\n )\n }\n }\n // Note: Don't use `Object.getPrototypeOf` here\n utils.replaceWithProxy(Permissions.prototype, 'query', handler)\n }\n }",_args:[{}]}),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"(utils, { fns, data }) => {\n fns = utils.materializeFns(fns)\n\n // That means we're running headful\n const hasPlugins = 'plugins' in navigator && navigator.plugins.length\n if (hasPlugins) {\n return // nothing to do here\n }\n\n const mimeTypes = fns.generateMimeTypeArray(utils, fns)(data.mimeTypes)\n const plugins = fns.generatePluginArray(utils, fns)(data.plugins)\n\n // Plugin and MimeType cross-reference each other, let's do that now\n // Note: We're looping through `data.plugins` here, not the generated `plugins`\n for (const pluginData of data.plugins) {\n pluginData.__mimeTypes.forEach((type, index) => {\n plugins[pluginData.name][index] = mimeTypes[type]\n\n Object.defineProperty(plugins[pluginData.name], type, {\n value: mimeTypes[type],\n writable: false,\n enumerable: false, // Not enumerable\n configurable: true\n })\n Object.defineProperty(mimeTypes[type], 'enabledPlugin', {\n value:\n type === 'application/x-pnacl'\n ? mimeTypes['application/x-nacl'].enabledPlugin // these reference the same plugin, so we need to re-use the Proxy in order to avoid leaks\n : new Proxy(plugins[pluginData.name], {}), // Prevent circular references\n writable: false,\n enumerable: false, // Important: `JSON.stringify(navigator.plugins)`\n configurable: true\n })\n })\n }\n\n const patchNavigator = (name, value) =>\n utils.replaceProperty(Object.getPrototypeOf(navigator), name, {\n get() {\n return value\n }\n })\n\n patchNavigator('mimeTypes', mimeTypes)\n patchNavigator('plugins', plugins)\n\n // All done\n }",_args:[{fns:{generateMimeTypeArray:"(utils, fns) => mimeTypesData => {\n return fns.generateMagicArray(utils, fns)(\n mimeTypesData,\n MimeTypeArray.prototype,\n MimeType.prototype,\n 'type'\n )\n}",generatePluginArray:"(utils, fns) => pluginsData => {\n return fns.generateMagicArray(utils, fns)(\n pluginsData,\n PluginArray.prototype,\n Plugin.prototype,\n 'name'\n )\n}",generateMagicArray:"(utils, fns) =>\n function(\n dataArray = [],\n proto = MimeTypeArray.prototype,\n itemProto = MimeType.prototype,\n itemMainProp = 'type'\n ) {\n // Quick helper to set props with the same descriptors vanilla is using\n const defineProp = (obj, prop, value) =>\n Object.defineProperty(obj, prop, {\n value,\n writable: false,\n enumerable: false, // Important for mimeTypes & plugins: `JSON.stringify(navigator.mimeTypes)`\n configurable: true\n })\n\n // Loop over our fake data and construct items\n const makeItem = data => {\n const item = {}\n for (const prop of Object.keys(data)) {\n if (prop.startsWith('__')) {\n continue\n }\n defineProp(item, prop, data[prop])\n }\n return patchItem(item, data)\n }\n\n const patchItem = (item, data) => {\n let descriptor = Object.getOwnPropertyDescriptors(item)\n\n // Special case: Plugins have a magic length property which is not enumerable\n // e.g. `navigator.plugins[i].length` should always be the length of the assigned mimeTypes\n if (itemProto === Plugin.prototype) {\n descriptor = {\n ...descriptor,\n length: {\n value: data.__mimeTypes.length,\n writable: false,\n enumerable: false,\n configurable: true // Important to be able to use the ownKeys trap in a Proxy to strip `length`\n }\n }\n }\n\n // We need to spoof a specific `MimeType` or `Plugin` object\n const obj = Object.create(itemProto, descriptor)\n\n // Virtually all property keys are not enumerable in vanilla\n const blacklist = [...Object.keys(data), 'length', 'enabledPlugin']\n return new Proxy(obj, {\n ownKeys(target) {\n return Reflect.ownKeys(target).filter(k => !blacklist.includes(k))\n },\n getOwnPropertyDescriptor(target, prop) {\n if (blacklist.includes(prop)) {\n return undefined\n }\n return Reflect.getOwnPropertyDescriptor(target, prop)\n }\n })\n }\n\n const magicArray = []\n\n // Loop through our fake data and use that to create convincing entities\n dataArray.forEach(data => {\n magicArray.push(makeItem(data))\n })\n\n // Add direct property access based on types (e.g. `obj['application/pdf']`) afterwards\n magicArray.forEach(entry => {\n defineProp(magicArray, entry[itemMainProp], entry)\n })\n\n // This is the best way to fake the type to make sure this is false: `Array.isArray(navigator.mimeTypes)`\n const magicArrayObj = Object.create(proto, {\n ...Object.getOwnPropertyDescriptors(magicArray),\n\n // There's one ugly quirk we unfortunately need to take care of:\n // The `MimeTypeArray` prototype has an enumerable `length` property,\n // but headful Chrome will still skip it when running `Object.getOwnPropertyNames(navigator.mimeTypes)`.\n // To strip it we need to make it first `configurable` and can then overlay a Proxy with an `ownKeys` trap.\n length: {\n value: magicArray.length,\n writable: false,\n enumerable: false,\n configurable: true // Important to be able to use the ownKeys trap in a Proxy to strip `length`\n }\n })\n\n // Generate our functional function mocks :-)\n const functionMocks = fns.generateFunctionMocks(utils)(\n proto,\n itemMainProp,\n magicArray\n )\n\n // We need to overlay our custom object with a JS Proxy\n const magicArrayObjProxy = new Proxy(magicArrayObj, {\n get(target, key = '') {\n // Redirect function calls to our custom proxied versions mocking the vanilla behavior\n if (key === 'item') {\n return functionMocks.item\n }\n if (key === 'namedItem') {\n return functionMocks.namedItem\n }\n if (proto === PluginArray.prototype && key === 'refresh') {\n return functionMocks.refresh\n }\n // Everything else can pass through as normal\n return utils.cache.Reflect.get(...arguments)\n },\n ownKeys(target) {\n // There are a couple of quirks where the original property demonstrates \"magical\" behavior that makes no sense\n // This can be witnessed when calling `Object.getOwnPropertyNames(navigator.mimeTypes)` and the absense of `length`\n // My guess is that it has to do with the recent change of not allowing data enumeration and this being implemented weirdly\n // For that reason we just completely fake the available property names based on our data to match what regular Chrome is doing\n // Specific issues when not patching this: `length` property is available, direct `types` props (e.g. `obj['application/pdf']`) are missing\n const keys = []\n const typeProps = magicArray.map(mt => mt[itemMainProp])\n typeProps.forEach((_, i) => keys.push(`${i}`))\n typeProps.forEach(propName => keys.push(propName))\n return keys\n },\n getOwnPropertyDescriptor(target, prop) {\n if (prop === 'length') {\n return undefined\n }\n return Reflect.getOwnPropertyDescriptor(target, prop)\n }\n })\n\n return magicArrayObjProxy\n }",generateFunctionMocks:"utils => (\n proto,\n itemMainProp,\n dataArray\n) => ({\n /** Returns the MimeType object with the specified index. */\n item: utils.createProxy(proto.item, {\n apply(target, ctx, args) {\n if (!args.length) {\n throw new TypeError(\n `Failed to execute 'item' on '${\n proto[Symbol.toStringTag]\n }': 1 argument required, but only 0 present.`\n )\n }\n // Special behavior alert:\n // - Vanilla tries to cast strings to Numbers (only integers!) and use them as property index lookup\n // - If anything else than an integer (including as string) is provided it will return the first entry\n const isInteger = args[0] && Number.isInteger(Number(args[0])) // Cast potential string to number first, then check for integer\n // Note: Vanilla never returns `undefined`\n return (isInteger ? dataArray[Number(args[0])] : dataArray[0]) || null\n }\n }),\n /** Returns the MimeType object with the specified name. */\n namedItem: utils.createProxy(proto.namedItem, {\n apply(target, ctx, args) {\n if (!args.length) {\n throw new TypeError(\n `Failed to execute 'namedItem' on '${\n proto[Symbol.toStringTag]\n }': 1 argument required, but only 0 present.`\n )\n }\n return dataArray.find(mt => mt[itemMainProp] === args[0]) || null // Not `undefined`!\n }\n }),\n /** Does nothing and shall return nothing */\n refresh: proto.refresh\n ? utils.createProxy(proto.refresh, {\n apply(target, ctx, args) {\n return undefined\n }\n })\n : undefined\n})"},data:{mimeTypes:[{type:"application/pdf",suffixes:"pdf",description:"",__pluginName:"Chrome PDF Viewer"},{type:"application/x-google-chrome-pdf",suffixes:"pdf",description:"Portable Document Format",__pluginName:"Chrome PDF Plugin"},{type:"application/x-nacl",suffixes:"",description:"Native Client Executable",__pluginName:"Native Client"},{type:"application/x-pnacl",suffixes:"",description:"Portable Native Client Executable",__pluginName:"Native Client"}],plugins:[{name:"Chrome PDF Plugin",filename:"internal-pdf-viewer",description:"Portable Document Format",__mimeTypes:["application/x-google-chrome-pdf"]},{name:"Chrome PDF Viewer",filename:"mhjfbmdgcfjbbpaeojofohoefgiehjai",description:"",__mimeTypes:["application/pdf"]},{name:"Native Client",filename:"internal-nacl-plugin",description:"",__mimeTypes:["application/x-nacl","application/x-pnacl"]}]}}]}),!1===navigator.webdriver||void 0===navigator.webdriver||delete Object.getPrototypeOf(navigator).webdriver,(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"(utils, opts) => {\n const getParameterProxyHandler = {\n apply: function(target, ctx, args) {\n const param = (args || [])[0]\n const result = utils.cache.Reflect.apply(target, ctx, args)\n // UNMASKED_VENDOR_WEBGL\n if (param === 37445) {\n return opts.vendor || 'Intel Inc.' // default in headless: Google Inc.\n }\n // UNMASKED_RENDERER_WEBGL\n if (param === 37446) {\n return opts.renderer || 'Intel Iris OpenGL Engine' // default in headless: Google SwiftShader\n }\n return result\n }\n }\n\n // There's more than one WebGL rendering context\n // https://developer.mozilla.org/en-US/docs/Web/API/WebGL2RenderingContext#Browser_compatibility\n // To find out the original values here: Object.getOwnPropertyDescriptors(WebGLRenderingContext.prototype.getParameter)\n const addProxy = (obj, propName) => {\n utils.replaceWithProxy(obj, propName, getParameterProxyHandler)\n }\n // For whatever weird reason loops don't play nice with Object.defineProperty, here's the next best thing:\n addProxy(WebGLRenderingContext.prototype, 'getParameter')\n addProxy(WebGL2RenderingContext.prototype, 'getParameter')\n }",_args:[{}]}),(()=>{try{if(window.outerWidth&&window.outerHeight)return;const n=85;window.outerWidth=window.innerWidth,window.outerHeight=window.innerHeight+n}catch(n){}})(),(({_utilsFns:_utilsFns,_mainFunction:_mainFunction,_args:_args})=>{const utils=Object.fromEntries(Object.entries(_utilsFns).map((([key,value])=>[key,eval(value)])));utils.init(),eval(_mainFunction)(utils,..._args)})({_utilsFns:{init:"() => {\n utils.preloadCache()\n}",stripProxyFromErrors:"(handler = {}) => {\n const newHandler = {\n setPrototypeOf: function (target, proto) {\n if (proto === null)\n throw new TypeError('Cannot convert object to primitive value')\n if (Object.getPrototypeOf(target) === Object.getPrototypeOf(proto)) {\n throw new TypeError('Cyclic __proto__ value')\n }\n return Reflect.setPrototypeOf(target, proto)\n }\n }\n // We wrap each trap in the handler in a try/catch and modify the error stack if they throw\n const traps = Object.getOwnPropertyNames(handler)\n traps.forEach(trap => {\n newHandler[trap] = function () {\n try {\n // Forward the call to the defined proxy handler\n return handler[trap].apply(this, arguments || [])\n } catch (err) {\n // Stack traces differ per browser, we only support chromium based ones currently\n if (!err || !err.stack || !err.stack.includes(`at `)) {\n throw err\n }\n\n // When something throws within one of our traps the Proxy will show up in error stacks\n // An earlier implementation of this code would simply strip lines with a blacklist,\n // but it makes sense to be more surgical here and only remove lines related to our Proxy.\n // We try to use a known \"anchor\" line for that and strip it with everything above it.\n // If the anchor line cannot be found for some reason we fall back to our blacklist approach.\n\n const stripWithBlacklist = (stack, stripFirstLine = true) => {\n const blacklist = [\n `at Reflect.${trap} `, // e.g. Reflect.get or Reflect.apply\n `at Object.${trap} `, // e.g. Object.get or Object.apply\n `at Object.newHandler. [as ${trap}] ` // caused by this very wrapper :-)\n ]\n return (\n err.stack\n .split('\\n')\n // Always remove the first (file) line in the stack (guaranteed to be our proxy)\n .filter((line, index) => !(index === 1 && stripFirstLine))\n // Check if the line starts with one of our blacklisted strings\n .filter(line => !blacklist.some(bl => line.trim().startsWith(bl)))\n .join('\\n')\n )\n }\n\n const stripWithAnchor = (stack, anchor) => {\n const stackArr = stack.split('\\n')\n anchor = anchor || `at Object.newHandler. [as ${trap}] ` // Known first Proxy line in chromium\n const anchorIndex = stackArr.findIndex(line =>\n line.trim().startsWith(anchor)\n )\n if (anchorIndex === -1) {\n return false // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n return stackArr.join('\\n')\n }\n\n // Special cases due to our nested toString proxies\n err.stack = err.stack.replace(\n 'at Object.toString (',\n 'at Function.toString ('\n )\n if ((err.stack || '').includes('at Function.toString (')) {\n err.stack = stripWithBlacklist(err.stack, false)\n throw err\n }\n\n // Try using the anchor method, fallback to blacklist if necessary\n err.stack = stripWithAnchor(err.stack) || stripWithBlacklist(err.stack)\n\n throw err // Re-throw our now sanitized error\n }\n }\n })\n return newHandler\n}",stripErrorWithAnchor:"(err, anchor) => {\n const stackArr = err.stack.split('\\n')\n const anchorIndex = stackArr.findIndex(line => line.trim().startsWith(anchor))\n if (anchorIndex === -1) {\n return err // 404, anchor not found\n }\n // Strip everything from the top until we reach the anchor line (remove anchor line as well)\n // Note: We're keeping the 1st line (zero index) as it's unrelated (e.g. `TypeError`)\n stackArr.splice(1, anchorIndex)\n err.stack = stackArr.join('\\n')\n return err\n}",replaceProperty:"(obj, propName, descriptorOverrides = {}) => {\n return Object.defineProperty(obj, propName, {\n // Copy over the existing descriptors (writable, enumerable, configurable, etc)\n ...(Object.getOwnPropertyDescriptor(obj, propName) || {}),\n // Add our overrides (e.g. value, get())\n ...descriptorOverrides\n })\n}",preloadCache:"() => {\n if (utils.cache) {\n return\n }\n utils.cache = {\n // Used in our proxies\n Reflect: {\n get: Reflect.get.bind(Reflect),\n apply: Reflect.apply.bind(Reflect)\n },\n // Used in `makeNativeString`\n nativeToStringStr: Function.toString + '' // => `function toString() { [native code] }`\n }\n}",makeNativeString:"(name = '') => {\n return utils.cache.nativeToStringStr.replace('toString', name || '')\n}",patchToString:"(obj, str = '') => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n // `toString` targeted at our proxied Object detected\n if (ctx === obj) {\n // We either return the optional string verbatim or derive the most desired result automatically\n return str || utils.makeNativeString(obj.name)\n }\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",patchToStringNested:"(obj = {}) => {\n return utils.execRecursively(obj, ['function'], utils.patchToString)\n}",redirectToString:"(proxyObj, originalObj) => {\n const handler = {\n apply: function (target, ctx) {\n // This fixes e.g. `HTMLMediaElement.prototype.canPlayType.toString + \"\"`\n if (ctx === Function.prototype.toString) {\n return utils.makeNativeString('toString')\n }\n\n // `toString` targeted at our proxied Object detected\n if (ctx === proxyObj) {\n const fallback = () =>\n originalObj && originalObj.name\n ? utils.makeNativeString(originalObj.name)\n : utils.makeNativeString(proxyObj.name)\n\n // Return the toString representation of our original object if possible\n return originalObj + '' || fallback()\n }\n\n if (typeof ctx === 'undefined' || ctx === null) {\n return target.call(ctx)\n }\n\n // Check if the toString protype of the context is the same as the global prototype,\n // if not indicates that we are doing a check across different windows., e.g. the iframeWithdirect` test case\n const hasSameProto = Object.getPrototypeOf(\n Function.prototype.toString\n ).isPrototypeOf(ctx.toString) // eslint-disable-line no-prototype-builtins\n if (!hasSameProto) {\n // Pass the call on to the local Function.prototype.toString instead\n return ctx.toString()\n }\n\n return target.call(ctx)\n }\n }\n\n const toStringProxy = new Proxy(\n Function.prototype.toString,\n utils.stripProxyFromErrors(handler)\n )\n utils.replaceProperty(Function.prototype, 'toString', {\n value: toStringProxy\n })\n}",replaceWithProxy:"(obj, propName, handler) => {\n const originalObj = obj[propName]\n const proxyObj = new Proxy(obj[propName], utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.redirectToString(proxyObj, originalObj)\n\n return true\n}",replaceGetterWithProxy:"(obj, propName, handler) => {\n const fn = Object.getOwnPropertyDescriptor(obj, propName).get\n const fnStr = fn.toString() // special getter function string\n const proxyObj = new Proxy(fn, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { get: proxyObj })\n utils.patchToString(proxyObj, fnStr)\n\n return true\n}",mockWithProxy:"(obj, propName, pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n\n utils.replaceProperty(obj, propName, { value: proxyObj })\n utils.patchToString(proxyObj)\n\n return true\n}",createProxy:"(pseudoTarget, handler) => {\n const proxyObj = new Proxy(pseudoTarget, utils.stripProxyFromErrors(handler))\n utils.patchToString(proxyObj)\n\n return proxyObj\n}",splitObjPath:"objPath => ({\n // Remove last dot entry (property) ==> `HTMLMediaElement.prototype`\n objName: objPath.split('.').slice(0, -1).join('.'),\n // Extract last dot entry ==> `canPlayType`\n propName: objPath.split('.').slice(-1)[0]\n})",replaceObjPathWithProxy:"(objPath, handler) => {\n const { objName, propName } = utils.splitObjPath(objPath)\n const obj = eval(objName) // eslint-disable-line no-eval\n return utils.replaceWithProxy(obj, propName, handler)\n}",execRecursively:"(obj = {}, typeFilter = [], fn) => {\n function recurse(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n continue\n }\n if (obj[key] && typeof obj[key] === 'object') {\n recurse(obj[key])\n } else {\n if (obj[key] && typeFilter.includes(typeof obj[key])) {\n fn.call(this, obj[key])\n }\n }\n }\n }\n recurse(obj)\n return obj\n}",stringifyFns:"(fnObj = { hello: () => 'world' }) => {\n // Object.fromEntries() ponyfill (in 6 lines) - supported only in Node v12+, modern browsers are fine\n // https://github.com/feross/fromentries\n function fromEntries(iterable) {\n return [...iterable].reduce((obj, [key, val]) => {\n obj[key] = val\n return obj\n }, {})\n }\n return (Object.fromEntries || fromEntries)(\n Object.entries(fnObj)\n .filter(([key, value]) => typeof value === 'function')\n .map(([key, value]) => [key, value.toString()]) // eslint-disable-line no-eval\n )\n}",materializeFns:"(fnStrObj = { hello: \"() => 'world'\" }) => {\n return Object.fromEntries(\n Object.entries(fnStrObj).map(([key, value]) => {\n if (value.startsWith('function')) {\n // some trickery is needed to make oldschool functions work :-)\n return [key, eval(`() => ${value}`)()] // eslint-disable-line no-eval\n } else {\n // arrow functions just work\n return [key, eval(value)] // eslint-disable-line no-eval\n }\n })\n )\n}",makeHandler:"() => ({\n // Used by simple `navigator` getter evasions\n getterValue: value => ({\n apply(target, ctx, args) {\n // Let's fetch the value first, to trigger and escalate potential errors\n // Illegal invocations like `navigator.__proto__.vendor` will throw here\n utils.cache.Reflect.apply(...arguments)\n return value\n }\n })\n})"},_mainFunction:"(utils, opts) => {\n try {\n // Adds a contentWindow proxy to the provided iframe element\n const addContentWindowProxy = iframe => {\n const contentWindowProxy = {\n get(target, key) {\n // Now to the interesting part:\n // We actually make this thing behave like a regular iframe window,\n // by intercepting calls to e.g. `.self` and redirect it to the correct thing. :)\n // That makes it possible for these assertions to be correct:\n // iframe.contentWindow.self === window.top // must be false\n if (key === 'self') {\n return this\n }\n // iframe.contentWindow.frameElement === iframe // must be true\n if (key === 'frameElement') {\n return iframe\n }\n // Intercept iframe.contentWindow[0] to hide the property 0 added by the proxy.\n if (key === '0') {\n return undefined\n }\n return Reflect.get(target, key)\n }\n }\n\n if (!iframe.contentWindow) {\n const proxy = new Proxy(window, contentWindowProxy)\n Object.defineProperty(iframe, 'contentWindow', {\n get() {\n return proxy\n },\n set(newValue) {\n return newValue // contentWindow is immutable\n },\n enumerable: true,\n configurable: false\n })\n }\n }\n\n // Handles iframe element creation, augments `srcdoc` property so we can intercept further\n const handleIframeCreation = (target, thisArg, args) => {\n const iframe = target.apply(thisArg, args)\n\n // We need to keep the originals around\n const _iframe = iframe\n const _srcdoc = _iframe.srcdoc\n\n // Add hook for the srcdoc property\n // We need to be very surgical here to not break other iframes by accident\n Object.defineProperty(iframe, 'srcdoc', {\n configurable: true, // Important, so we can reset this later\n get: function() {\n return _srcdoc\n },\n set: function(newValue) {\n addContentWindowProxy(this)\n // Reset property, the hook is only needed once\n Object.defineProperty(iframe, 'srcdoc', {\n configurable: false,\n writable: false,\n value: _srcdoc\n })\n _iframe.srcdoc = newValue\n }\n })\n return iframe\n }\n\n // Adds a hook to intercept iframe creation events\n const addIframeCreationSniffer = () => {\n /* global document */\n const createElementHandler = {\n // Make toString() native\n get(target, key) {\n return Reflect.get(target, key)\n },\n apply: function(target, thisArg, args) {\n const isIframe =\n args && args.length && `${args[0]}`.toLowerCase() === 'iframe'\n if (!isIframe) {\n // Everything as usual\n return target.apply(thisArg, args)\n } else {\n return handleIframeCreation(target, thisArg, args)\n }\n }\n }\n // All this just due to iframes with srcdoc bug\n utils.replaceWithProxy(\n document,\n 'createElement',\n createElementHandler\n )\n }\n\n // Let's go\n addIframeCreationSniffer()\n } catch (err) {\n // console.warn(err)\n }\n }",_args:[]});
\ No newline at end of file
diff --git a/feapder/utils/log.py b/feapder/utils/log.py
index d11ed5ea..e993f760 100644
--- a/feapder/utils/log.py
+++ b/feapder/utils/log.py
@@ -67,7 +67,6 @@ def doRollover(self):
self.stream = self._open()
def shouldRollover(self, record):
-
if self.stream is None: # delay was set...
self.stream = self._open()
if self.max_bytes > 0: # are we rolling over?
@@ -213,9 +212,9 @@ def get_logger(
]
# 关闭日志打印
+OTHERS_LOG_LEVAL = eval("logging." + setting.OTHERS_LOG_LEVAL)
for STOP_LOG in STOP_LOGS:
- log_level = eval("logging." + setting.OTHERS_LOG_LEVAL)
- logging.getLogger(STOP_LOG).setLevel(log_level)
+ logging.getLogger(STOP_LOG).setLevel(OTHERS_LOG_LEVAL)
# print(logging.Logger.manager.loggerDict) # 取使用debug模块的name
@@ -225,6 +224,13 @@ def get_logger(
class Log:
log = None
+ def func(self, log_level):
+ def wrapper(msg, *args, **kwargs):
+ if self.isEnabledFor(log_level):
+ self._log(log_level, msg, args, **kwargs)
+
+ return wrapper
+
def __getattr__(self, name):
# 调用log时再初始化,为了加载最新的setting
if self.__class__.log is None:
@@ -239,6 +245,12 @@ def debug(self):
def info(self):
return self.__class__.log.info
+ @property
+ def success(self):
+ log_level = logging.INFO + 1
+ logging.addLevelName(log_level, "success".upper())
+ return self.func(log_level)
+
@property
def warning(self):
return self.__class__.log.warning
diff --git a/feapder/utils/metrics.py b/feapder/utils/metrics.py
index f2112b24..ab88ee1e 100644
--- a/feapder/utils/metrics.py
+++ b/feapder/utils/metrics.py
@@ -4,6 +4,7 @@
import queue
import random
import socket
+import string
import threading
import time
from collections import Counter
@@ -36,7 +37,6 @@ def __init__(
add_hostname=False,
max_points=10240,
default_tags=None,
- time_precision="s",
):
"""
Args:
@@ -49,7 +49,6 @@ def __init__(
debug: 是否打印调试日志
add_hostname: 是否添加 hostname 作为 tag
max_points: 本地 buffer 最多累计多少个点
- time_precision: 打点精度 默认 s
"""
self.pending_points = queue.Queue()
self.batch_size = batch_size
@@ -66,7 +65,6 @@ def __init__(
self.add_hostname = add_hostname
self.ratio = ratio
self.default_tags = default_tags or {}
- self.time_precision = time_precision
def define_tagkv(self, tagk, tagvs):
self.tagkv[tagk] = set(tagvs)
@@ -74,6 +72,19 @@ def define_tagkv(self, tagk, tagvs):
def _point_tagset(self, p):
return f"{p['measurement']}-{sorted(p['tags'].items())}-{p['time']}"
+ def _make_time_to_ns(self, _time):
+ """
+ 将时间转换为 ns 级别的时间戳,补足长度 19 位
+ Args:
+ _time:
+
+ Returns:
+
+ """
+ time_len = len(str(_time))
+ random_str = "".join(random.sample(string.digits, 19 - time_len))
+ return int(str(_time) + random_str)
+
def _accumulate_points(self, points):
"""
对于处于同一个 key 的点做聚合
@@ -104,15 +115,22 @@ def _accumulate_points(self, points):
continue
# 增加 _seq tag,以便区分不同的点
point["tags"]["_seq"] = timer_seqs[tagset]
+ point["time"] = self._make_time_to_ns(point["time"])
timer_seqs[tagset] += 1
new_points.append(point)
else:
if self.ratio < 1.0 and random.random() > self.ratio:
continue
+ point["time"] = self._make_time_to_ns(point["time"])
new_points.append(point)
- # 把累加得到的 counter 值添加进来
- new_points.extend(counters.values())
+ for point in counters.values():
+ # 修改下counter类型的点的时间戳,补足19位, 伪装成纳秒级时间戳,防止influxdb对同一秒内的数据进行覆盖
+ point["time"] = self._make_time_to_ns(point["time"])
+ new_points.append(point)
+
+ # 把拟合后的 counter 值添加进来
+ new_points.append(point)
return new_points
def _get_ready_emit(self, force=False):
@@ -167,10 +185,11 @@ def emit(self, point=None, force=False):
if not points:
return
try:
+ # h(hour) m(minutes), s(seconds), ms(milliseconds), u(microseconds), n(nanoseconds)
self.influxdb.write_points(
points,
batch_size=self.batch_size,
- time_precision=self.time_precision,
+ time_precision="n",
retention_policy=self.retention_policy,
)
except Exception:
@@ -295,12 +314,13 @@ def init(
retention_policy=None,
retention_policy_duration="180d",
emit_interval=60,
- batch_size=10,
+ batch_size=100,
debug=False,
use_udp=False,
- timeout=10,
- time_precision="s",
+ timeout=22,
ssl=False,
+ retention_policy_replication: str = "1",
+ set_retention_policy_default=True,
**kwargs,
):
"""
@@ -320,8 +340,9 @@ def init(
debug: 是否开启调试
use_udp: 是否使用udp协议打点
timeout: 与influxdb建立连接时的超时时间
- time_precision: 打点精度 默认秒
ssl: 是否使用https协议
+ retention_policy_replication: 保留策略的副本数, 确保数据的可靠性和高可用性。如果一个节点发生故障,其他节点可以继续提供服务,从而避免数据丢失和服务不可用的情况
+ set_retention_policy_default: 是否设置为默认的保留策略,当retention_policy初次创建时有效
**kwargs: 可传递MetricsEmitter类的参数
Returns:
@@ -372,8 +393,8 @@ def init(
influxdb_client.create_retention_policy(
retention_policy,
retention_policy_duration,
- replication="1",
- default=True,
+ replication=retention_policy_replication,
+ default=set_retention_policy_default,
)
except Exception as e:
log.error("metrics init falied: {}".format(e))
@@ -383,7 +404,6 @@ def init(
influxdb_client,
debug=debug,
batch_size=batch_size,
- time_precision=time_precision,
retention_policy=retention_policy,
emit_interval=emit_interval,
**kwargs,
@@ -407,7 +427,7 @@ def emit_any(
fields: influxdb的field的字段和值
classify: 点的类别
measurement: 存储的表
- timestamp: 点的时间搓,默认为当前时间
+ timestamp: 点的时间戳,默认为当前时间
Returns:
@@ -438,7 +458,7 @@ def emit_counter(
classify: 点的类别
tags: influxdb的tag的字段和值
measurement: 存储的表
- timestamp: 点的时间搓,默认为当前时间
+ timestamp: 点的时间戳,默认为当前时间
Returns:
@@ -469,7 +489,7 @@ def emit_timer(
classify: 点的类别
tags: influxdb的tag的字段和值
measurement: 存储的表
- timestamp: 点的时间搓,默认为当前时间
+ timestamp: 点的时间戳,默认为当前时间
Returns:
@@ -500,7 +520,7 @@ def emit_store(
classify: 点的类别
tags: influxdb的tag的字段和值
measurement: 存储的表
- timestamp: 点的时间搓,默认为当前时间
+ timestamp: 点的时间戳,默认为当前时间
Returns:
diff --git a/feapder/utils/redis_lock.py b/feapder/utils/redis_lock.py
index 4e972c66..9df0b85d 100644
--- a/feapder/utils/redis_lock.py
+++ b/feapder/utils/redis_lock.py
@@ -53,15 +53,17 @@ def redis_conn(self):
@redis_conn.setter
def redis_conn(self, cli):
- self.__class__.redis_cli = cli
+ if cli:
+ self.__class__.redis_cli = cli
def __enter__(self):
if not self.locked:
self.acquire()
- # 延长锁的时间
- thread = threading.Thread(target=self.prolong_life)
- thread.setDaemon(True)
- thread.start()
+ if self.locked:
+ # 延长锁的时间
+ thread = threading.Thread(target=self.prolong_life)
+ thread.daemon = True
+ thread.start()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
@@ -81,11 +83,12 @@ def acquire(self):
if self.wait_timeout > 0:
if time.time() - start > self.wait_timeout:
- log.info("加锁失败")
+ log.debug("获取锁失败")
break
else:
+ log.debug("获取锁失败")
break
- log.debug("等待加锁: {} wait:{}".format(self, time.time() - start))
+ log.debug("等待锁: {} wait:{}".format(self, time.time() - start))
if self.wait_timeout > 10:
time.sleep(5)
else:
diff --git a/feapder/utils/tail_thread.py b/feapder/utils/tail_thread.py
new file mode 100644
index 00000000..eda266d5
--- /dev/null
+++ b/feapder/utils/tail_thread.py
@@ -0,0 +1,33 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2024/3/19 20:00
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+import sys
+import threading
+
+
+class TailThread(threading.Thread):
+ """
+ 所有子线程结束后,主线程才会退出
+ """
+
+ def start(self) -> None:
+ """
+ 解决python3.12 RuntimeError: cannot join thread before it is started的报错
+ """
+ super().start()
+
+ if sys.version_info.minor >= 12 and sys.version_info.major >= 3:
+ for thread in threading.enumerate():
+ if (
+ thread.daemon
+ or thread is threading.current_thread()
+ or not thread.is_alive()
+ ):
+ continue
+ thread.join()
diff --git a/feapder/utils/tools.py b/feapder/utils/tools.py
index c865241c..31952876 100644
--- a/feapder/utils/tools.py
+++ b/feapder/utils/tools.py
@@ -15,12 +15,15 @@
import datetime
import functools
import hashlib
+import hmac
import html
+import importlib
import json
import os
import pickle
import random
import re
+import signal
import socket
import ssl
import string
@@ -38,7 +41,6 @@
from urllib import request
from urllib.parse import urljoin
-import execjs # pip install PyExecJS
import redis
import requests
import six
@@ -50,6 +52,11 @@
from feapder.utils.email_sender import EmailSender
from feapder.utils.log import log
+try:
+ import execjs # pip install PyExecJS
+except Exception as e:
+ pass
+
os.environ["EXECJS_RUNTIME"] = "Node" # 设置使用node执行js
# 全局取消ssl证书验证
@@ -80,6 +87,23 @@ def __call__(self, *args, **kwargs):
return self._instance[self._cls]
+class LazyProperty:
+ """
+ 属性延时初始化,且只初始化一次
+ """
+
+ def __init__(self, func):
+ self.func = func
+
+ def __get__(self, instance, owner):
+ if instance is None:
+ return self
+ else:
+ value = self.func(instance)
+ setattr(instance, self.func.__name__, value)
+ return value
+
+
def log_function_time(func):
try:
@@ -135,6 +159,100 @@ def new_method(self, *args, **kwargs):
return new_method
+def retry(retry_times=3, interval=0):
+ """
+ 普通函数的重试装饰器
+ Args:
+ retry_times: 重试次数
+ interval: 每次重试之间的间隔
+
+ Returns:
+
+ """
+
+ def _retry(func):
+ @functools.wraps(func) # 将函数的原来属性付给新函数
+ def wapper(*args, **kwargs):
+ for i in range(retry_times):
+ try:
+ return func(*args, **kwargs)
+ except Exception as e:
+ log.error(
+ "函数 {} 执行失败 重试 {} 次. error {}".format(func.__name__, i + 1, e)
+ )
+ time.sleep(interval)
+ if i + 1 >= retry_times:
+ raise e
+
+ return wapper
+
+ return _retry
+
+
+def retry_asyncio(retry_times=3, interval=0):
+ """
+ 协程的重试装饰器
+ Args:
+ retry_times: 重试次数
+ interval: 每次重试之间的间隔
+
+ Returns:
+
+ """
+
+ def _retry(func):
+ @functools.wraps(func) # 将函数的原来属性付给新函数
+ async def wapper(*args, **kwargs):
+ for i in range(retry_times):
+ try:
+ return await func(*args, **kwargs)
+ except Exception as e:
+ log.error(
+ "函数 {} 执行失败 重试 {} 次. error {}".format(func.__name__, i + 1, e)
+ )
+ await asyncio.sleep(interval)
+ if i + 1 >= retry_times:
+ raise e
+
+ return wapper
+
+ return _retry
+
+
+def func_timeout(timeout):
+ """
+ 函数运行时间限制装饰器
+ 注: 不支持window
+ Args:
+ timeout: 超时的时间
+
+ Eg:
+ @set_timeout(3)
+ def test():
+ ...
+
+ Returns:
+
+ """
+
+ def wapper(func):
+ def handle(
+ signum, frame
+ ): # 收到信号 SIGALRM 后的回调函数,第一个参数是信号的数字,第二个参数是the interrupted stack frame.
+ raise TimeoutError
+
+ def new_method(*args, **kwargs):
+ signal.signal(signal.SIGALRM, handle) # 设置信号和回调函数
+ signal.alarm(timeout) # 设置 timeout 秒的闹钟
+ r = func(*args, **kwargs)
+ signal.alarm(0) # 关闭闹钟
+ return r
+
+ return new_method
+
+ return wapper
+
+
########################【网页解析相关】###############################
@@ -390,12 +508,63 @@ def fit_url(urls, identis):
def get_param(url, key):
- params = url.split("?")[-1].split("&")
+ pattern = r"(?:[?&])" + re.escape(key) + r"=([^&]+)"
+ match = re.search(pattern, url)
+ if match:
+ return match.group(1)
+ return None
+
+
+def get_all_params(url):
+ """
+ >>> get_all_params("https://www.baidu.com/s?wd=feapder")
+ {'wd': 'feapder'}
+ """
+ params_json = {}
+ params = url.split("?", 1)[-1].split("&")
for param in params:
key_value = param.split("=", 1)
- if key == key_value[0]:
- return key_value[1]
- return None
+ if len(key_value) == 2:
+ params_json[key_value[0]] = unquote_url(key_value[1])
+ else:
+ params_json[key_value[0]] = ""
+
+ return params_json
+
+
+def parse_url_params(url):
+ """
+ 解析url参数
+ :param url:
+ :return:
+
+ >>> parse_url_params("https://www.baidu.com/s?wd=%E4%BD%A0%E5%A5%BD")
+ ('https://www.baidu.com/s', {'wd': '你好'})
+ >>> parse_url_params("wd=%E4%BD%A0%E5%A5%BD")
+ ('', {'wd': '你好'})
+ >>> parse_url_params("https://www.baidu.com/s?wd=%E4%BD%A0%E5%A5%BD&pn=10")
+ ('https://www.baidu.com/s', {'wd': '你好', 'pn': '10'})
+ >>> parse_url_params("wd=%E4%BD%A0%E5%A5%BD&pn=10")
+ ('', {'wd': '你好', 'pn': '10'})
+ >>> parse_url_params("https://www.baidu.com")
+ ('https://www.baidu.com', {})
+ >>> parse_url_params("https://www.spidertools.cn/#/")
+ ('https://www.spidertools.cn/#/', {})
+ """
+ root_url = ""
+ params = {}
+ if "?" not in url:
+ if re.search("[&=]", url) and not re.search("/", url):
+ # 只有参数
+ params = get_all_params(url)
+ else:
+ root_url = url
+
+ else:
+ root_url = url.split("?", 1)[0]
+ params = get_all_params(url)
+
+ return root_url, params
def urlencode(params):
@@ -424,7 +593,7 @@ def urldecode(url):
params_json = {}
params = url.split("?")[-1].split("&")
for param in params:
- key, value = param.split("=")
+ key, value = param.split("=", 1)
params_json[key] = unquote_url(value)
return params_json
@@ -594,20 +763,8 @@ def get_form_data(form):
return data
-# mac上不好使
-# def get_domain(url):
-# domain = ''
-# try:
-# domain = get_tld(url)
-# except Exception as e:
-# log.debug(e)
-# return domain
-
-
def get_domain(url):
- proto, rest = urllib.parse.splittype(url)
- domain, rest = urllib.parse.splithost(rest)
- return domain
+ return urllib.parse.urlparse(url).netloc
def get_index_url(url):
@@ -708,36 +865,46 @@ def get_text(soup, *args):
return ""
-def del_html_tag(content, except_line_break=False, save_img=False, white_replaced=""):
+def del_html_tag(content, save_line_break=True, save_p=False, save_img=False):
"""
删除html标签
@param content: html内容
- @param except_line_break: 保留p标签
- @param save_img: 保留图片
- @param white_replaced: 空白符替换
+ @param save_p: 保留p标签
+ @param save_img: 保留图片标签
+ @param save_line_break: 保留\n换行
@return:
"""
- content = replace_str(content, "(?i)") # (?)忽略大小写
- content = replace_str(content, "(?i)")
- content = replace_str(content, "")
- content = replace_str(
- content, "(?!&[a-z]+=)&[a-z]+;?"
- ) # 干掉 等无用的字符 但&xxx= 这种表示参数的除外
- if except_line_break:
- content = content.replace("", "/p")
- content = replace_str(content, "<[^p].*?>")
- content = content.replace("/p", "")
- content = replace_str(content, "[ \f\r\t\v]")
-
+ if not content:
+ return content
+ # js
+ content = re.sub("(?i)", "", content) # (?)忽略大小写
+ # css
+ content = re.sub("(?i)", "", content) # (?)忽略大小写
+ # 注释
+ content = re.sub("", "", content)
+ # 干掉 等无用的字符 但&xxx= 这种表示参数的除外
+ content = re.sub("(?!&[a-z]+=)&[a-z]+;?", "", content)
+
+ if save_p and save_img:
+ content = re.sub("<(?!(p[ >]|/p>|img ))(.|\n)+?>", "", content)
+ elif save_p:
+ content = re.sub("<(?!(p[ >]|/p>))(.|\n)+?>", "", content)
elif save_img:
- content = replace_str(content, "(?!)<.+?>") # 替换掉除图片外的其他标签
- content = replace_str(content, "(?! +)\s+", "\n") # 保留空格
- content = content.strip()
+ content = re.sub("<(?!img )(.|\n)+?>", "", content)
+ elif save_line_break:
+ content = re.sub("<(?!/p>)(.|\n)+?>", "", content)
+ content = re.sub("", "\n", content)
+ else:
+ content = re.sub("<(.|\n)*?>", "", content)
+ if save_line_break:
+ # 把非换行符的空白符替换为一个空格
+ content = re.sub("[^\S\n]+", " ", content)
+ # 把多个换行符替换为一个换行符 如\n\n\n 或 \n \n \n 替换为\n
+ content = re.sub("(\n ?)+", "\n", content)
else:
- content = replace_str(content, "<(.|\n)*?>")
- content = replace_str(content, "\s", white_replaced)
- content = content.strip()
+ content = re.sub("\s+", " ", content)
+ content = content.strip()
return content
@@ -949,6 +1116,26 @@ def mkdir(path):
pass
+def get_cache_path(filename, root_dir=None, local=False):
+ """
+ Args:
+ filename:
+ root_dir:
+ local: 是否存储到当前目录
+
+ Returns:
+
+ """
+ if root_dir is None:
+ if local:
+ root_dir = os.path.join(sys.path[0], ".cache")
+ else:
+ root_dir = os.path.join(os.path.expanduser("~"), ".feapder/cache")
+ file_path = f"{root_dir}{os.sep}{filename}"
+ os.makedirs(os.path.dirname(file_path), exist_ok=True)
+ return f"{root_dir}{os.sep}{filename}"
+
+
def write_file(filename, content, mode="w", encoding="utf-8"):
"""
@summary: 写文件
@@ -989,10 +1176,10 @@ def read_file(filename, readlines=False, encoding="utf-8"):
def get_oss_file_list(oss_handler, prefix, date_range_min, date_range_max=None):
"""
获取文件列表
- @param prefix: 路径前缀 如 data/car_service_line/yiche/yiche_serial_zongshu_info
+ @param prefix: 路径前缀 如 xxx/xxx
@param date_range_min: 时间范围 最小值 日期分隔符为/ 如 2019/03/01 或 2019/03/01/00/00/00
@param date_range_max: 时间范围 最大值 日期分隔符为/ 如 2019/03/01 或 2019/03/01/00/00/00
- @return: 每个文件路径 如 html/e_commerce_service_line/alibaba/alibaba_shop_info/2019/03/22/15/53/15/8ca8b9e4-4c77-11e9-9dee-acde48001122.json.snappy
+ @return: 每个文件路径 如 html/xxx/xxx/2019/03/22/15/53/15/8ca8b9e4-4c77-11e9-9dee-acde48001122.json.snappy
"""
# 计算时间范围
@@ -1202,8 +1389,6 @@ def compile_js(js_func):
return ctx.call
-###############################################
-
#############################################
@@ -1882,7 +2067,7 @@ def get_method(obj, name):
return None
-def witch_workspace(project_path):
+def switch_workspace(project_path):
"""
@summary:
---------
@@ -2010,7 +2195,7 @@ def make_batch_sql(
if not datas:
return
- keys = list(datas[0].keys())
+ keys = list(set([key for data in datas for key in data]))
values_placeholder = ["%s"] * len(keys)
values = []
@@ -2283,12 +2468,43 @@ def reach_freq_limit(rate_limit, *key):
def dingding_warning(
- message, message_prefix=None, rate_limit=None, url=None, user_phone=None
+ message,
+ *,
+ message_prefix=None,
+ rate_limit=None,
+ url=None,
+ user_phone=None,
+ user_id=None,
+ secret=None,
):
+ """
+ 钉钉报警,user_phone与user_id 二选一即可
+ Args:
+ message:
+ message_prefix: 消息摘要,用于去重
+ rate_limit: 包名频率,单位秒,相同的报警内容在rate_limit时间内只会报警一次
+ url: 钉钉报警url
+ user_phone: 被@的群成员手机号,支持列表,可指定多个。
+ user_id: 被@的群成员userId,支持列表,可指定多个
+ secret: 钉钉报警加签密钥
+ Returns:
+
+ """
# 为了加载最新的配置
rate_limit = rate_limit if rate_limit is not None else setting.WARNING_INTERVAL
url = url or setting.DINGDING_WARNING_URL
user_phone = user_phone or setting.DINGDING_WARNING_PHONE
+ user_id = user_id or setting.DINGDING_WARNING_USER_ID
+ secret = secret or setting.DINGDING_WARNING_SECRET
+ if secret:
+ timestamp = str(round(time.time() * 1000))
+ secret_enc = secret.encode("utf-8")
+ string_to_sign_enc = f"{timestamp}\n{secret}".encode("utf-8")
+ hmac_code = hmac.new(
+ secret_enc, string_to_sign_enc, digestmod=hashlib.sha256
+ ).digest()
+ sign = urllib.parse.quote_plus(base64.b64encode(hmac_code))
+ url = f"{url}×tamp={timestamp}&sign={sign}"
if not all([url, message]):
return
@@ -2300,10 +2516,17 @@ def dingding_warning(
if isinstance(user_phone, str):
user_phone = [user_phone] if user_phone else []
+ if isinstance(user_id, str):
+ user_id = [user_id] if user_id else []
+
data = {
"msgtype": "text",
"text": {"content": message},
- "at": {"atMobiles": user_phone, "isAtAll": setting.DINGDING_WARNING_ALL},
+ "at": {
+ "atMobiles": user_phone,
+ "atUserIds": user_id,
+ "isAtAll": setting.DINGDING_WARNING_ALL,
+ },
}
headers = {"Content-Type": "application/json"}
@@ -2438,13 +2661,115 @@ def wechat_warning(
return False
-def send_msg(msg, level="DEBUG", message_prefix=""):
+def feishu_warning(message, message_prefix=None, rate_limit=None, url=None, user=None):
+ """
+
+ Args:
+ message:
+ message_prefix:
+ rate_limit:
+ url:
+ user: {"open_id":"ou_xxxxx", "name":"xxxx"} 或 [{"open_id":"ou_xxxxx", "name":"xxxx"}]
+
+ Returns:
+
+ """
+ # 为了加载最新的配置
+ rate_limit = rate_limit if rate_limit is not None else setting.WARNING_INTERVAL
+ url = url or setting.FEISHU_WARNING_URL
+ user = user or setting.FEISHU_WARNING_USER
+
+ if not all([url, message]):
+ return
+
+ if reach_freq_limit(rate_limit, url, user, message_prefix or message):
+ log.info("报警时间间隔过短,此次报警忽略。 内容 {}".format(message))
+ return
+
+ if isinstance(user, dict):
+ user = [user] if user else []
+
+ at = ""
+ if setting.FEISHU_WARNING_ALL:
+ at = '所有人'
+ elif user:
+ at = " ".join(
+ [f'{u.get("name")}' for u in user]
+ )
+
+ data = {"msg_type": "text", "content": {"text": at + message}}
+ headers = {"Content-Type": "application/json"}
+
+ try:
+ response = requests.post(
+ url, headers=headers, data=json.dumps(data).encode("utf8")
+ )
+ result = response.json()
+ response.close()
+ if result.get("StatusCode") == 0:
+ return True
+ else:
+ raise Exception(result.get("msg"))
+ except Exception as e:
+ log.error("报警发送失败。 报警内容 {}, error: {}".format(message, e))
+ return False
+
+
+def qmsg_warning(
+ message,
+ message_prefix=None,
+ rate_limit=None,
+ url=None,
+ user_qq=None,
+ bot_qq=None
+):
+ """qmsg报警"""
+
+ # 为了加载最新的配置
+ rate_limit = rate_limit if rate_limit is not None else setting.WARNING_INTERVAL
+ url = url or setting.QMSG_WARNING_URL
+ user_qq = user_qq or setting.QMSG_WARNING_QQ
+ bot_qq = bot_qq or setting.QMSG_WARNING_BOT
+
+ if isinstance(user_qq, list):
+ user_qq = ','.join(map(str, user_qq))
+
+ if not all([url, message]):
+ return
+
+ if reach_freq_limit(rate_limit, url, user_qq, message_prefix or message):
+ log.info("报警时间间隔过短,此次报警忽略。 内容 {}".format(message))
+ return
+
+ data = {
+ "msg": message,
+ "qq": user_qq,
+ "bot": bot_qq,
+ }
+
+ headers = {"Content-Type": "application/json"}
+
+ try:
+ response = requests.post(
+ url, headers=headers, data=json.dumps(data).encode("utf8")
+ )
+ result = response.json()
+ response.close()
+ if result.get("code") == 0:
+ return True
+ else:
+ raise Exception(result.get("reason"))
+ except Exception as e:
+ log.error("报警发送失败。 报警内容 {}, error: {}".format(message, e))
+ return False
+
+
+def send_msg(msg, level="DEBUG", message_prefix="", keyword="feapder报警系统\n"):
if setting.WARNING_LEVEL == "ERROR":
if level.upper() != "ERROR":
return
if setting.DINGDING_WARNING_URL:
- keyword = "feapder报警系统\n"
dingding_warning(keyword + msg, message_prefix=message_prefix)
if setting.EMAIL_RECEIVER:
@@ -2454,9 +2779,14 @@ def send_msg(msg, level="DEBUG", message_prefix=""):
email_warning(msg, message_prefix=message_prefix, title=title)
if setting.WECHAT_WARNING_URL:
- keyword = "feapder报警系统\n"
wechat_warning(keyword + msg, message_prefix=message_prefix)
+ if setting.FEISHU_WARNING_URL:
+ feishu_warning(keyword + msg, message_prefix=message_prefix)
+
+ if setting.QMSG_WARNING_URL:
+ qmsg_warning(keyword + msg, message_prefix=message_prefix)
+
###################
@@ -2537,3 +2867,9 @@ def ensure_float(n):
if not n:
return 0.0
return float(n)
+
+
+def import_cls(cls_info):
+ module, class_name = cls_info.rsplit(".", 1)
+ cls = importlib.import_module(module).__getattribute__(class_name)
+ return cls
diff --git a/feapder/utils/webdriver.py b/feapder/utils/webdriver.py
deleted file mode 100644
index c25438d8..00000000
--- a/feapder/utils/webdriver.py
+++ /dev/null
@@ -1,439 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-Created on 2021/3/18 4:59 下午
----------
-@summary:
----------
-@author: Boris
-@email: boris_liu@foxmail.com
-"""
-
-import json
-import os
-import queue
-import threading
-from typing import Optional, Union
-
-from selenium import webdriver
-from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
-from selenium.webdriver.remote.webdriver import WebDriver as RemoteWebDriver
-from webdriver_manager.chrome import ChromeDriverManager
-from webdriver_manager.firefox import GeckoDriverManager
-
-from feapder.utils.log import log
-from feapder.utils.tools import Singleton
-
-DEFAULT_USERAGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
-
-
-class XhrRequest:
- def __init__(self, url, data, headers):
- self.url = url
- self.data = data
- self.headers = headers
-
-
-class XhrResponse:
- def __init__(self, request: XhrRequest, url, headers, content, status_code):
- self.request = request
- self.url = url
- self.headers = headers
- self.content = content
- self.status_code = status_code
-
-
-class WebDriver(RemoteWebDriver):
- CHROME = "CHROME"
- PHANTOMJS = "PHANTOMJS"
- FIREFOX = "FIREFOX"
-
- def __init__(
- self,
- load_images=True,
- user_agent=None,
- proxy=None,
- headless=False,
- driver_type=CHROME,
- timeout=16,
- window_size=(1024, 800),
- executable_path=None,
- custom_argument=None,
- xhr_url_regexes: list = None,
- download_path=None,
- auto_install_driver=False,
- **kwargs,
- ):
- """
- webdirver 封装,支持chrome、phantomjs 和 firefox
- Args:
- load_images: 是否加载图片
- user_agent: 字符串 或 无参函数,返回值为user_agent
- proxy: xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
- headless: 是否启用无头模式
- driver_type: CHROME 或 PHANTOMJS,FIREFOX
- timeout: 请求超时时间
- window_size: # 窗口大小
- executable_path: 浏览器路径,默认为默认路径
- xhr_url_regexes: 拦截xhr接口,支持正则,数组类型
- download_path: 文件下载保存路径;如果指定,不再出现“保留”“放弃”提示,仅对Chrome有效
- auto_install_driver: 自动下载浏览器驱动 支持chrome 和 firefox
- **kwargs:
- """
- self._load_images = load_images
- self._user_agent = user_agent or DEFAULT_USERAGENT
- self._proxy = proxy
- self._headless = headless
- self._timeout = timeout
- self._window_size = window_size
- self._executable_path = executable_path
- self._custom_argument = custom_argument
- self._xhr_url_regexes = xhr_url_regexes
- self._download_path = download_path
- self._auto_install_driver = auto_install_driver
-
- if self._xhr_url_regexes and driver_type != WebDriver.CHROME:
- raise Exception(
- "xhr_url_regexes only support by chrome now! eg: driver_type=WebDriver.CHROME"
- )
-
- if driver_type == WebDriver.CHROME:
- self.driver = self.chrome_driver()
-
- elif driver_type == WebDriver.PHANTOMJS:
- self.driver = self.phantomjs_driver()
-
- elif driver_type == WebDriver.FIREFOX:
- self.driver = self.firefox_driver()
-
- else:
- raise TypeError(
- "dirver_type must be one of CHROME or PHANTOMJS or FIREFOX, but received {}".format(
- type(driver_type)
- )
- )
-
- # driver.get(url)一直不返回,但也不报错的问题,这时程序会卡住,设置超时选项能解决这个问题。
- self.driver.set_page_load_timeout(self._timeout)
- # 设置10秒脚本超时时间
- self.driver.set_script_timeout(self._timeout)
-
- def __enter__(self):
- return self
-
- def __exit__(self, exc_type, exc_val, exc_tb):
- if exc_val:
- log.error(exc_val)
-
- self.quit()
- return True
-
- def get_driver(self):
- return self.driver
-
- def firefox_driver(self):
- firefox_profile = webdriver.FirefoxProfile()
- firefox_options = webdriver.FirefoxOptions()
- firefox_capabilities = webdriver.DesiredCapabilities.FIREFOX
-
- if self._proxy:
- proxy = self._proxy() if callable(self._proxy) else self._proxy
- firefox_capabilities["marionette"] = True
- firefox_capabilities["proxy"] = {
- "proxyType": "MANUAL",
- "httpProxy": proxy,
- "ftpProxy": proxy,
- "sslProxy": proxy,
- }
-
- if self._user_agent:
- firefox_profile.set_preference(
- "general.useragent.override",
- self._user_agent() if callable(self._user_agent) else self._user_agent,
- )
-
- if not self._load_images:
- firefox_profile.set_preference("permissions.default.image", 2)
-
- if self._headless:
- firefox_options.add_argument("--headless")
- firefox_options.add_argument("--disable-gpu")
-
- # 添加自定义的配置参数
- if self._custom_argument:
- for arg in self._custom_argument:
- firefox_options.add_argument(arg)
-
- if self._executable_path:
- driver = webdriver.Firefox(
- capabilities=firefox_capabilities,
- options=firefox_options,
- firefox_profile=firefox_profile,
- executable_path=self._executable_path,
- )
- elif self._auto_install_driver:
- driver = webdriver.Firefox(
- capabilities=firefox_capabilities,
- options=firefox_options,
- firefox_profile=firefox_profile,
- executable_path=GeckoDriverManager(print_first_line=False).install(),
- )
- else:
- driver = webdriver.Firefox(
- capabilities=firefox_capabilities,
- options=firefox_options,
- firefox_profile=firefox_profile,
- )
-
- if self._window_size:
- driver.set_window_size(*self._window_size)
-
- return driver
-
- def chrome_driver(self):
- chrome_options = webdriver.ChromeOptions()
- # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
- chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])
- chrome_options.add_experimental_option("useAutomationExtension", False)
- # docker 里运行需要
- chrome_options.add_argument("--no-sandbox")
-
- if self._proxy:
- chrome_options.add_argument(
- "--proxy-server={}".format(
- self._proxy() if callable(self._proxy) else self._proxy
- )
- )
- if self._user_agent:
- chrome_options.add_argument(
- "user-agent={}".format(
- self._user_agent()
- if callable(self._user_agent)
- else self._user_agent
- )
- )
- if not self._load_images:
- chrome_options.add_experimental_option(
- "prefs", {"profile.managed_default_content_settings.images": 2}
- )
-
- if self._headless:
- chrome_options.add_argument("--headless")
- chrome_options.add_argument("--disable-gpu")
-
- if self._window_size:
- chrome_options.add_argument(
- "--window-size={},{}".format(self._window_size[0], self._window_size[1])
- )
-
- if self._download_path:
- os.makedirs(self._download_path, exist_ok=True)
- prefs = {
- "download.prompt_for_download": False,
- "download.default_directory": self._download_path,
- }
- chrome_options.add_experimental_option("prefs", prefs)
-
- # 添加自定义的配置参数
- if self._custom_argument:
- for arg in self._custom_argument:
- chrome_options.add_argument(arg)
-
- if self._executable_path:
- driver = webdriver.Chrome(
- options=chrome_options, executable_path=self._executable_path
- )
- elif self._auto_install_driver:
- driver = webdriver.Chrome(
- options=chrome_options,
- executable_path=ChromeDriverManager(print_first_line=False).install(),
- )
- else:
- driver = webdriver.Chrome(options=chrome_options)
-
- # 隐藏浏览器特征
- with open(os.path.join(os.path.dirname(__file__), "./js/stealth.min.js")) as f:
- js = f.read()
- driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": js})
-
- if self._xhr_url_regexes:
- assert isinstance(self._xhr_url_regexes, list)
- with open(
- os.path.join(os.path.dirname(__file__), "./js/intercept.js")
- ) as f:
- js = f.read()
- driver.execute_cdp_cmd(
- "Page.addScriptToEvaluateOnNewDocument", {"source": js}
- )
- js = f"window.__urlRegexes = {self._xhr_url_regexes}"
- driver.execute_cdp_cmd(
- "Page.addScriptToEvaluateOnNewDocument", {"source": js}
- )
-
- if self._download_path:
- driver.command_executor._commands["send_command"] = (
- "POST",
- "/session/$sessionId/chromium/send_command",
- )
- params = {
- "cmd": "Page.setDownloadBehavior",
- "params": {"behavior": "allow", "downloadPath": self._download_path},
- }
- driver.execute("send_command", params)
-
- return driver
-
- def phantomjs_driver(self):
- import warnings
-
- warnings.filterwarnings("ignore")
-
- service_args = []
- dcap = DesiredCapabilities.PHANTOMJS
-
- if self._proxy:
- service_args.append(
- "--proxy=%s" % self._proxy() if callable(self._proxy) else self._proxy
- )
- if self._user_agent:
- dcap["phantomjs.page.settings.userAgent"] = (
- self._user_agent() if callable(self._user_agent) else self._user_agent
- )
- if not self._load_images:
- service_args.append("--load-images=no")
-
- # 添加自定义的配置参数
- if self._custom_argument:
- for arg in self._custom_argument:
- service_args.append(arg)
-
- if self._executable_path:
- driver = webdriver.PhantomJS(
- service_args=service_args,
- desired_capabilities=dcap,
- executable_path=self._executable_path,
- )
- else:
- driver = webdriver.PhantomJS(
- service_args=service_args, desired_capabilities=dcap
- )
-
- if self._window_size:
- driver.set_window_size(self._window_size[0], self._window_size[1])
-
- del warnings
-
- return driver
-
- @property
- def cookies(self):
- cookies_json = {}
- for cookie in self.driver.get_cookies():
- cookies_json[cookie["name"]] = cookie["value"]
-
- return cookies_json
-
- @cookies.setter
- def cookies(self, val: dict):
- """
- 设置cookie
- Args:
- val: {"key":"value", "key2":"value2"}
-
- Returns:
-
- """
- for key, value in val.items():
- self.driver.add_cookie({"name": key, "value": value})
-
- @property
- def user_agent(self):
- return self.driver.execute_script("return navigator.userAgent;")
-
- def xhr_response(self, xhr_url_regex) -> Optional[XhrResponse]:
- data = self.driver.execute_script(
- f'return window.__ajaxData["{xhr_url_regex}"];'
- )
- if not data:
- return None
-
- request = XhrRequest(**data["request"])
- response = XhrResponse(request, **data["response"])
- return response
-
- def xhr_data(self, xhr_url_regex) -> Union[str, dict, None]:
- response = self.xhr_response(xhr_url_regex)
- if not response:
- return None
- return response.content
-
- def xhr_text(self, xhr_url_regex) -> Optional[str]:
- response = self.xhr_response(xhr_url_regex)
- if not response:
- return None
- if isinstance(response.content, dict):
- return json.dumps(response.content, ensure_ascii=False)
- return response.content
-
- def xhr_json(self, xhr_url_regex) -> Optional[dict]:
- text = self.xhr_text(xhr_url_regex)
- return json.loads(text)
-
- def __getattr__(self, name):
- if self.driver:
- return getattr(self.driver, name)
- else:
- raise AttributeError
-
- # def __del__(self):
- # self.quit()
-
-
-@Singleton
-class WebDriverPool:
- def __init__(self, pool_size=5, **kwargs):
- self.queue = queue.Queue(maxsize=pool_size)
- self.kwargs = kwargs
- self.lock = threading.RLock()
- self.driver_count = 0
-
- @property
- def is_full(self):
- return self.driver_count >= self.queue.maxsize
-
- def get(self, user_agent: str = None, proxy: str = None) -> WebDriver:
- """
- 获取webdriver
- 当webdriver为新实例时会使用 user_agen, proxy, cookie参数来创建
- Args:
- user_agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36
- proxy: xxx.xxx.xxx.xxx
- Returns:
-
- """
- if not self.is_full:
- with self.lock:
- if not self.is_full:
- kwargs = self.kwargs.copy()
- if user_agent:
- kwargs["user_agent"] = user_agent
- if proxy:
- kwargs["proxy"] = proxy
- driver = WebDriver(**kwargs)
- self.queue.put(driver)
- self.driver_count += 1
-
- driver = self.queue.get()
- return driver
-
- def put(self, driver):
- self.queue.put(driver)
-
- def remove(self, driver):
- driver.quit()
- self.driver_count -= 1
-
- def close(self):
- while not self.queue.empty():
- driver = self.queue.get()
- driver.quit()
- self.driver_count -= 1
diff --git a/feapder/utils/webdriver/__init__.py b/feapder/utils/webdriver/__init__.py
new file mode 100644
index 00000000..16f8bd93
--- /dev/null
+++ b/feapder/utils/webdriver/__init__.py
@@ -0,0 +1,16 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/9/7 4:39 PM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+from .playwright_driver import PlaywrightDriver
+from .selenium_driver import SeleniumDriver
+from .webdirver import InterceptRequest, InterceptResponse
+from .webdriver_pool import WebDriverPool
+
+# 为了兼容老代码
+WebDriver = SeleniumDriver
diff --git a/feapder/utils/webdriver/playwright_driver.py b/feapder/utils/webdriver/playwright_driver.py
new file mode 100644
index 00000000..fe7e5062
--- /dev/null
+++ b/feapder/utils/webdriver/playwright_driver.py
@@ -0,0 +1,298 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/9/7 4:11 PM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import json
+import os
+import re
+from collections import defaultdict
+from typing import Union, List
+
+try:
+ from typing import Literal # python >= 3.8
+except ImportError: # python <3.8
+ from typing_extensions import Literal
+
+
+from playwright.sync_api import Page, BrowserContext, ViewportSize, ProxySettings
+from playwright.sync_api import Playwright, Browser
+from playwright.sync_api import Response
+from playwright.sync_api import sync_playwright
+
+from feapder.utils import tools
+from feapder.utils.log import log
+from feapder.utils.webdriver.webdirver import *
+
+
+class PlaywrightDriver(WebDriver):
+ def __init__(
+ self,
+ *,
+ page_on_event_callback: dict = None,
+ storage_state_path: str = None,
+ driver_type: Literal["chromium", "firefox", "webkit"] = "chromium",
+ url_regexes: list = None,
+ save_all: bool = False,
+ **kwargs
+ ):
+ """
+
+ Args:
+ page_on_event_callback: page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()}
+ storage_state_path: 保存浏览器状态的路径
+ driver_type: 浏览器类型 chromium, firefox, webkit
+ url_regexes: 拦截接口,支持正则,数组类型
+ save_all: 是否保存所有拦截的接口, 默认只保存最后一个
+ **kwargs:
+ """
+ super(PlaywrightDriver, self).__init__(**kwargs)
+ self.driver: Playwright = None
+ self.browser: Browser = None
+ self.context: BrowserContext = None
+ self.page: Page = None
+ self.url = None
+ self.storage_state_path = storage_state_path
+
+ self._driver_type = driver_type or "chromium"
+ self._page_on_event_callback = page_on_event_callback
+ self._url_regexes = url_regexes
+ self._save_all = save_all
+
+ if self._save_all and self._url_regexes:
+ log.warning(
+ "获取完拦截的数据后, 请主动调用PlaywrightDriver的clear_cache()方法清空拦截的数据,否则数据会一直累加,导致内存溢出"
+ )
+ self._cache_data = defaultdict(list)
+ else:
+ self._cache_data = {}
+
+ self._setup()
+
+ def _setup(self):
+ # 处理参数
+ if self._proxy:
+ proxy = self._proxy() if callable(self._proxy) else self._proxy
+ proxy = self.format_context_proxy(proxy)
+ else:
+ proxy = None
+
+ user_agent = (
+ self._user_agent() if callable(self._user_agent) else self._user_agent
+ )
+
+ view_size = ViewportSize(
+ width=self._window_size[0], height=self._window_size[1]
+ )
+
+ # 初始化浏览器对象
+ self.driver = sync_playwright().start()
+ self.browser = getattr(self.driver, self._driver_type).launch(
+ headless=self._headless,
+ args=["--no-sandbox"],
+ proxy=proxy,
+ executable_path=self._executable_path,
+ downloads_path=self._download_path,
+ )
+
+ if self.storage_state_path and os.path.exists(self.storage_state_path):
+ self.context = self.browser.new_context(
+ user_agent=user_agent,
+ screen=view_size,
+ viewport=view_size,
+ proxy=proxy,
+ storage_state=self.storage_state_path,
+ )
+ else:
+ self.context = self.browser.new_context(
+ user_agent=user_agent,
+ screen=view_size,
+ viewport=view_size,
+ proxy=proxy,
+ )
+
+ if self._use_stealth_js:
+ path = os.path.join(os.path.dirname(__file__), "../js/stealth.min.js")
+ self.context.add_init_script(path=path)
+
+ self.page = self.context.new_page()
+ self.page.set_default_timeout(self._timeout * 1000)
+
+ if self._page_on_event_callback:
+ for event, callback in self._page_on_event_callback.items():
+ self.page.on(event, callback)
+
+ if self._url_regexes:
+ self.page.on("response", self.on_response)
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ if exc_val:
+ log.error(exc_val)
+
+ self.quit()
+ return True
+
+ def format_context_proxy(self, proxy) -> ProxySettings:
+ """
+ Args:
+ proxy: username:password@ip:port / ip:port
+ Returns:
+ {
+ "server": "ip:port"
+ "username": username,
+ "password": password,
+ }
+ server: http://ip:port or socks5://ip:port. Short form ip:port is considered an HTTP proxy.
+ """
+
+ if "@" in proxy:
+ certification, _proxy = proxy.split("@")
+ username, password = certification.split(":")
+
+ context_proxy = ProxySettings(
+ server=_proxy,
+ username=username,
+ password=password,
+ )
+ else:
+ context_proxy = ProxySettings(server=proxy)
+
+ return context_proxy
+
+ def save_storage_stage(self):
+ if self.storage_state_path:
+ os.makedirs(os.path.dirname(self.storage_state_path), exist_ok=True)
+ self.context.storage_state(path=self.storage_state_path)
+
+ def quit(self):
+ self.page.close()
+ self.context.close()
+ self.browser.close()
+ self.driver.stop()
+
+ @property
+ def domain(self):
+ return tools.get_domain(self.url or self.page.url)
+
+ @property
+ def cookies(self):
+ cookies_json = {}
+ for cookie in self.page.context.cookies():
+ cookies_json[cookie["name"]] = cookie["value"]
+
+ return cookies_json
+
+ @cookies.setter
+ def cookies(self, val: Union[dict, List[dict]]):
+ """
+ 设置cookie
+ Args:
+ val: List[{name: str, value: str, url: Union[str, NoneType], domain: Union[str, NoneType], path: Union[str, NoneType], expires: Union[float, NoneType], httpOnly: Union[bool, NoneType], secure: Union[bool, NoneType], sameSite: Union["Lax", "None", "Strict", NoneType]}]
+
+ Returns:
+
+ """
+ if isinstance(val, list):
+ self.page.context.add_cookies(val)
+ else:
+ cookies = []
+ for key, value in val.items():
+ cookies.append(
+ {"name": key, "value": value, "url": self.url or self.page.url}
+ )
+ self.page.context.add_cookies(cookies)
+
+ @property
+ def user_agent(self):
+ return self.page.evaluate("() => navigator.userAgent")
+
+ def on_response(self, response: Response):
+ for regex in self._url_regexes:
+ if re.search(regex, response.request.url):
+ intercept_request = InterceptRequest(
+ url=response.request.url,
+ headers=response.request.headers,
+ data=response.request.post_data,
+ )
+
+ intercept_response = InterceptResponse(
+ request=intercept_request,
+ url=response.url,
+ headers=response.headers,
+ content=response.body(),
+ status_code=response.status,
+ )
+ if self._save_all:
+ self._cache_data[regex].append(intercept_response)
+ else:
+ self._cache_data[regex] = intercept_response
+
+ def get_response(self, url_regex) -> InterceptResponse:
+ if self._save_all:
+ response_list = self._cache_data.get(url_regex)
+ if response_list:
+ return response_list[-1]
+ return self._cache_data.get(url_regex)
+
+ def get_all_response(self, url_regex) -> List[InterceptResponse]:
+ """
+ 获取所有匹配的响应, 仅在save_all=True时有效
+ Args:
+ url_regex:
+
+ Returns:
+
+ """
+ response_list = self._cache_data.get(url_regex, [])
+ if not isinstance(response_list, list):
+ return [response_list]
+ return response_list
+
+ def get_text(self, url_regex):
+ return (
+ self.get_response(url_regex).content.decode()
+ if self.get_response(url_regex)
+ else None
+ )
+
+ def get_all_text(self, url_regex):
+ """
+ 获取所有匹配的响应文本, 仅在save_all=True时有效
+ Args:
+ url_regex:
+
+ Returns:
+
+ """
+ return [
+ response.content.decode() for response in self.get_all_response(url_regex)
+ ]
+
+ def get_json(self, url_regex):
+ return (
+ json.loads(self.get_text(url_regex))
+ if self.get_response(url_regex)
+ else None
+ )
+
+ def get_all_json(self, url_regex):
+ """
+ 获取所有匹配的响应json, 仅在save_all=True时有效
+ Args:
+ url_regex:
+
+ Returns:
+
+ """
+ return [json.loads(text) for text in self.get_all_text(url_regex)]
+
+ def clear_cache(self):
+ self._cache_data = defaultdict(list)
diff --git a/feapder/utils/webdriver/selenium_driver.py b/feapder/utils/webdriver/selenium_driver.py
new file mode 100644
index 00000000..9f46d54b
--- /dev/null
+++ b/feapder/utils/webdriver/selenium_driver.py
@@ -0,0 +1,530 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2021/3/18 4:59 下午
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import json
+import logging
+import os
+from typing import Optional, Union, List
+
+from selenium import webdriver
+from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
+from selenium.webdriver.remote.webdriver import WebDriver as RemoteWebDriver
+from webdriver_manager.chrome import ChromeDriverManager
+from webdriver_manager.firefox import GeckoDriverManager
+
+from feapder.utils import tools
+from feapder.utils.log import log, OTHERS_LOG_LEVAL
+from feapder.utils.webdriver.webdirver import *
+
+# 屏蔽webdriver_manager日志
+logging.getLogger("WDM").setLevel(OTHERS_LOG_LEVAL)
+
+
+class SeleniumDriver(WebDriver, RemoteWebDriver):
+ CHROME = "CHROME"
+ EDGE = "EDGE"
+ PHANTOMJS = "PHANTOMJS"
+ FIREFOX = "FIREFOX"
+
+ __CHROME_ATTRS__ = {
+ "executable_path",
+ "port",
+ "options",
+ "service_args",
+ "desired_capabilities",
+ "service_log_path",
+ "chrome_options",
+ "keep_alive",
+ }
+
+ __EDGE_ATTRS__ = __CHROME_ATTRS__
+
+ __FIREFOX_ATTRS__ = {
+ "firefox_profile",
+ "firefox_binary",
+ "timeout",
+ "capabilities",
+ "proxy",
+ "executable_path",
+ "options",
+ "service_log_path",
+ "firefox_options",
+ "service_args",
+ "desired_capabilities",
+ "log_path",
+ "keep_alive",
+ }
+ __PHANTOMJS_ATTRS__ = {
+ "executable_path",
+ "port",
+ "desired_capabilities",
+ "service_args",
+ "service_log_path",
+ }
+
+ def __init__(self, xhr_url_regexes: list = None, **kwargs):
+ """
+
+ Args:
+ xhr_url_regexes: 拦截xhr接口,支持正则,数组类型
+ **kwargs:
+ """
+ super(SeleniumDriver, self).__init__(**kwargs)
+ self._xhr_url_regexes = xhr_url_regexes
+ self._driver_type = self._driver_type or SeleniumDriver.CHROME
+
+ if self._xhr_url_regexes and self._driver_type != SeleniumDriver.CHROME:
+ raise Exception(
+ "xhr_url_regexes only support by chrome now! eg: driver_type=SeleniumDriver.CHROME"
+ )
+
+ if self._driver_type == SeleniumDriver.CHROME:
+ self.driver = self.chrome_driver()
+
+ elif self._driver_type == SeleniumDriver.EDGE:
+ self.driver = self.edge_driver()
+
+ elif self._driver_type == SeleniumDriver.PHANTOMJS:
+ self.driver = self.phantomjs_driver()
+
+ elif self._driver_type == SeleniumDriver.FIREFOX:
+ self.driver = self.firefox_driver()
+
+ else:
+ raise TypeError(
+ "dirver_type must be one of CHROME or PHANTOMJS or FIREFOX, but received {}".format(
+ type(self._driver_type)
+ )
+ )
+
+ # driver.get(url)一直不返回,但也不报错的问题,这时程序会卡住,设置超时选项能解决这个问题。
+ self.driver.set_page_load_timeout(self._timeout)
+ # 设置10秒脚本超时时间
+ self.driver.set_script_timeout(self._timeout)
+ self.url = None
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ if exc_val:
+ log.error(exc_val)
+
+ self.quit()
+ return True
+
+ def filter_kwargs(self, kwargs: dict, driver_attrs: set):
+ if not kwargs:
+ return {}
+
+ data = {}
+ for key, value in kwargs.items():
+ if key in driver_attrs:
+ data[key] = value
+
+ return data
+
+ def get_driver(self):
+ return self.driver
+
+ def firefox_driver(self):
+ if webdriver.__version__ >= "4.0.0":
+ raise Exception(
+ f"暂未适配selenium=={webdriver.__version__}版本的firefox API,建议安装selenium==3.141.0版本或使用CHROME浏览器"
+ )
+
+ firefox_profile = webdriver.FirefoxProfile()
+ firefox_options = webdriver.FirefoxOptions()
+ firefox_capabilities = webdriver.DesiredCapabilities.FIREFOX
+ try:
+ from selenium.webdriver.firefox.service import Service
+ except (ImportError, ModuleNotFoundError):
+ Service = None
+
+ if self._proxy:
+ proxy = self._proxy() if callable(self._proxy) else self._proxy
+ firefox_capabilities["marionette"] = True
+ firefox_capabilities["proxy"] = {
+ "proxyType": "MANUAL",
+ "httpProxy": proxy,
+ "ftpProxy": proxy,
+ "sslProxy": proxy,
+ }
+
+ if self._user_agent:
+ firefox_profile.set_preference(
+ "general.useragent.override",
+ self._user_agent() if callable(self._user_agent) else self._user_agent,
+ )
+
+ if not self._load_images:
+ firefox_profile.set_preference("permissions.default.image", 2)
+
+ if self._headless:
+ firefox_options.add_argument("--headless")
+ firefox_options.add_argument("--disable-gpu")
+
+ # 添加自定义的配置参数
+ if self._custom_argument:
+ for arg in self._custom_argument:
+ firefox_options.add_argument(arg)
+
+ kwargs = self.filter_kwargs(self._kwargs, self.__FIREFOX_ATTRS__)
+
+ if Service is None:
+ if self._executable_path:
+ kwargs.update(executable_path=self._executable_path)
+ elif self._auto_install_driver:
+ kwargs.update(executable_path=GeckoDriverManager().install())
+ else:
+ if self._executable_path:
+ kwargs.update(service=Service(self._executable_path))
+ elif self._auto_install_driver:
+ kwargs.update(service=Service(GeckoDriverManager().install()))
+
+ driver = webdriver.Firefox(
+ capabilities=firefox_capabilities,
+ options=firefox_options,
+ firefox_profile=firefox_profile,
+ **kwargs,
+ )
+
+ if self._window_size:
+ driver.set_window_size(*self._window_size)
+
+ return driver
+
+ def chrome_driver(self):
+ chrome_options = webdriver.ChromeOptions()
+ # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
+ chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])
+ chrome_options.add_experimental_option("useAutomationExtension", False)
+ # docker 里运行需要
+ chrome_options.add_argument("--no-sandbox")
+ try:
+ from selenium.webdriver.chrome.service import Service
+ except (ImportError, ModuleNotFoundError):
+ Service = None
+
+ if self._proxy:
+ chrome_options.add_argument(
+ "--proxy-server={}".format(
+ self._proxy() if callable(self._proxy) else self._proxy
+ )
+ )
+ if self._user_agent:
+ chrome_options.add_argument(
+ "user-agent={}".format(
+ self._user_agent()
+ if callable(self._user_agent)
+ else self._user_agent
+ )
+ )
+ if not self._load_images:
+ chrome_options.add_experimental_option(
+ "prefs", {"profile.managed_default_content_settings.images": 2}
+ )
+
+ if self._headless:
+ chrome_options.add_argument("--headless")
+ chrome_options.add_argument("--disable-gpu")
+
+ if self._window_size:
+ chrome_options.add_argument(
+ "--window-size={},{}".format(self._window_size[0], self._window_size[1])
+ )
+
+ if self._download_path:
+ os.makedirs(self._download_path, exist_ok=True)
+ prefs = {
+ "download.prompt_for_download": False,
+ "download.default_directory": self._download_path,
+ }
+ chrome_options.add_experimental_option("prefs", prefs)
+
+ # 添加自定义的配置参数
+ if self._custom_argument:
+ for arg in self._custom_argument:
+ chrome_options.add_argument(arg)
+
+ kwargs = self.filter_kwargs(self._kwargs, self.__CHROME_ATTRS__)
+ if Service is None:
+ if self._executable_path:
+ kwargs.update(executable_path=self._executable_path)
+ elif self._auto_install_driver:
+ kwargs.update(executable_path=ChromeDriverManager().install())
+ else:
+ if self._executable_path:
+ kwargs.update(service=Service(self._executable_path))
+ elif self._auto_install_driver:
+ kwargs.update(service=Service(ChromeDriverManager().install()))
+
+ driver = webdriver.Chrome(options=chrome_options, **kwargs)
+
+ # 隐藏浏览器特征
+ if self._use_stealth_js:
+ with open(
+ os.path.join(os.path.dirname(__file__), "../js/stealth.min.js")
+ ) as f:
+ js = f.read()
+ driver.execute_cdp_cmd(
+ "Page.addScriptToEvaluateOnNewDocument", {"source": js}
+ )
+
+ if self._xhr_url_regexes:
+ assert isinstance(self._xhr_url_regexes, list)
+ with open(
+ os.path.join(os.path.dirname(__file__), "../js/intercept.js")
+ ) as f:
+ js = f.read()
+ driver.execute_cdp_cmd(
+ "Page.addScriptToEvaluateOnNewDocument", {"source": js}
+ )
+ js = f"window.__urlRegexes = {self._xhr_url_regexes}"
+ driver.execute_cdp_cmd(
+ "Page.addScriptToEvaluateOnNewDocument", {"source": js}
+ )
+
+ if self._download_path:
+ driver.command_executor._commands["send_command"] = (
+ "POST",
+ "/session/$sessionId/chromium/send_command",
+ )
+ params = {
+ "cmd": "Page.setDownloadBehavior",
+ "params": {"behavior": "allow", "downloadPath": self._download_path},
+ }
+ driver.execute("send_command", params)
+
+ return driver
+
+ def edge_driver(self):
+ edge_options = webdriver.EdgeOptions()
+ # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
+ edge_options.add_experimental_option("excludeSwitches", ["enable-automation"])
+ edge_options.add_experimental_option("useAutomationExtension", False)
+ # docker 里运行需要
+ edge_options.add_argument("--no-sandbox")
+ try:
+ from selenium.webdriver.edge.service import Service
+ except (ImportError, ModuleNotFoundError):
+ Service = None
+
+ if self._proxy:
+ edge_options.add_argument(
+ "--proxy-server={}".format(
+ self._proxy() if callable(self._proxy) else self._proxy
+ )
+ )
+ if self._user_agent:
+ edge_options.add_argument(
+ "user-agent={}".format(
+ self._user_agent()
+ if callable(self._user_agent)
+ else self._user_agent
+ )
+ )
+ if not self._load_images:
+ edge_options.add_experimental_option(
+ "prefs", {"profile.managed_default_content_settings.images": 2}
+ )
+
+ if self._headless:
+ edge_options.add_argument("--headless")
+ edge_options.add_argument("--disable-gpu")
+
+ if self._window_size:
+ edge_options.add_argument(
+ "--window-size={},{}".format(self._window_size[0], self._window_size[1])
+ )
+
+ if self._download_path:
+ os.makedirs(self._download_path, exist_ok=True)
+ prefs = {
+ "download.prompt_for_download": False,
+ "download.default_directory": self._download_path,
+ }
+ edge_options.add_experimental_option("prefs", prefs)
+
+ # 添加自定义的配置参数
+ if self._custom_argument:
+ for arg in self._custom_argument:
+ edge_options.add_argument(arg)
+
+ kwargs = self.filter_kwargs(self._kwargs, self.__CHROME_ATTRS__)
+ if Service is None:
+ if self._executable_path:
+ kwargs.update(executable_path=self._executable_path)
+ elif self._auto_install_driver:
+ raise NotImplementedError("edge not support auto install driver")
+ else:
+ if self._executable_path:
+ kwargs.update(service=Service(self._executable_path))
+ elif self._auto_install_driver:
+ raise NotImplementedError("edge not support auto install driver")
+
+ driver = webdriver.Edge(options=edge_options, **kwargs)
+
+ # 隐藏浏览器特征
+ if self._use_stealth_js:
+ with open(
+ os.path.join(os.path.dirname(__file__), "../js/stealth.min.js")
+ ) as f:
+ js = f.read()
+ driver.execute_cdp_cmd(
+ "Page.addScriptToEvaluateOnNewDocument", {"source": js}
+ )
+
+ if self._xhr_url_regexes:
+ assert isinstance(self._xhr_url_regexes, list)
+ with open(
+ os.path.join(os.path.dirname(__file__), "../js/intercept.js")
+ ) as f:
+ js = f.read()
+ driver.execute_cdp_cmd(
+ "Page.addScriptToEvaluateOnNewDocument", {"source": js}
+ )
+ js = f"window.__urlRegexes = {self._xhr_url_regexes}"
+ driver.execute_cdp_cmd(
+ "Page.addScriptToEvaluateOnNewDocument", {"source": js}
+ )
+
+ if self._download_path:
+ driver.command_executor._commands["send_command"] = (
+ "POST",
+ "/session/$sessionId/chromium/send_command",
+ )
+ params = {
+ "cmd": "Page.setDownloadBehavior",
+ "params": {"behavior": "allow", "downloadPath": self._download_path},
+ }
+ driver.execute("send_command", params)
+
+ return driver
+
+ def phantomjs_driver(self):
+ import warnings
+
+ warnings.filterwarnings("ignore")
+
+ service_args = []
+ dcap = DesiredCapabilities.PHANTOMJS
+
+ if self._proxy:
+ service_args.append(
+ "--proxy=%s" % self._proxy() if callable(self._proxy) else self._proxy
+ )
+ if self._user_agent:
+ dcap["phantomjs.page.settings.userAgent"] = (
+ self._user_agent() if callable(self._user_agent) else self._user_agent
+ )
+ if not self._load_images:
+ service_args.append("--load-images=no")
+
+ # 添加自定义的配置参数
+ if self._custom_argument:
+ for arg in self._custom_argument:
+ service_args.append(arg)
+
+ kwargs = self.filter_kwargs(self._kwargs, self.__PHANTOMJS_ATTRS__)
+
+ if self._executable_path:
+ kwargs.update(executable_path=self._executable_path)
+
+ driver = webdriver.PhantomJS(
+ service_args=service_args, desired_capabilities=dcap, **kwargs
+ )
+
+ if self._window_size:
+ driver.set_window_size(self._window_size[0], self._window_size[1])
+
+ del warnings
+
+ return driver
+
+ @property
+ def domain(self):
+ return tools.get_domain(self.url or self.driver.current_url)
+
+ @property
+ def cookies(self):
+ cookies_json = {}
+ for cookie in self.driver.get_cookies():
+ cookies_json[cookie["name"]] = cookie["value"]
+
+ return cookies_json
+
+ @cookies.setter
+ def cookies(self, val: Union[dict, List[dict]]):
+ """
+ 设置cookie
+ Args:
+ val: {"key":"value", "key2":"value2"}
+
+ Returns:
+
+ """
+ if isinstance(val, list):
+ for cookie in val:
+ # "path", "domain", "secure", "expiry"
+ _cookie = {
+ "name": cookie.get("name"),
+ "value": cookie.get("value"),
+ "domain": cookie.get("domain"),
+ "path": cookie.get("path"),
+ "expires": cookie.get("expires"),
+ "secure": cookie.get("secure"),
+ }
+ self.driver.add_cookie(_cookie)
+ else:
+ for key, value in val.items():
+ self.driver.add_cookie({"name": key, "value": value})
+
+ @property
+ def user_agent(self):
+ return self.driver.execute_script("return navigator.userAgent;")
+
+ def xhr_response(self, xhr_url_regex) -> Optional[InterceptResponse]:
+ data = self.driver.execute_script(
+ f'return window.__ajaxData["{xhr_url_regex}"];'
+ )
+ if not data:
+ return None
+
+ request = InterceptRequest(**data["request"])
+ response = InterceptResponse(request, **data["response"])
+ return response
+
+ def xhr_data(self, xhr_url_regex) -> Union[str, dict, None]:
+ response = self.xhr_response(xhr_url_regex)
+ if not response:
+ return None
+ return response.content
+
+ def xhr_text(self, xhr_url_regex) -> Optional[str]:
+ response = self.xhr_response(xhr_url_regex)
+ if not response:
+ return None
+ if isinstance(response.content, dict):
+ return json.dumps(response.content, ensure_ascii=False)
+ return response.content
+
+ def xhr_json(self, xhr_url_regex) -> Optional[dict]:
+ text = self.xhr_text(xhr_url_regex)
+ return json.loads(text)
+
+ def __getattr__(self, name):
+ if self.driver:
+ return getattr(self.driver, name)
+ else:
+ raise AttributeError
+
+ # def __del__(self):
+ # self.quit()
diff --git a/feapder/utils/webdriver/webdirver.py b/feapder/utils/webdriver/webdirver.py
new file mode 100644
index 00000000..8fa2a34e
--- /dev/null
+++ b/feapder/utils/webdriver/webdirver.py
@@ -0,0 +1,81 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/9/7 4:27 PM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+import abc
+
+from feapder import setting
+
+
+class InterceptRequest:
+ def __init__(self, url, data, headers):
+ self.url = url
+ self.data = data
+ self.headers = headers
+
+
+class InterceptResponse:
+ def __init__(self, request: InterceptRequest, url, headers, content, status_code):
+ self.request = request
+ self.url = url
+ self.headers = headers
+ self.content = content
+ self.status_code = status_code
+
+
+class WebDriver:
+ def __init__(
+ self,
+ load_images=True,
+ user_agent=None,
+ proxy=None,
+ headless=False,
+ driver_type=None,
+ timeout=16,
+ window_size=(1024, 800),
+ executable_path=None,
+ custom_argument=None,
+ download_path=None,
+ auto_install_driver=True,
+ use_stealth_js=True,
+ **kwargs,
+ ):
+ """
+ webdirver 封装,支持chrome、phantomjs 和 firefox
+ Args:
+ load_images: 是否加载图片
+ user_agent: 字符串 或 无参函数,返回值为user_agent
+ proxy: xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+ headless: 是否启用无头模式
+ driver_type: CHROME,EDGE 或 PHANTOMJS,FIREFOX
+ timeout: 请求超时时间
+ window_size: # 窗口大小
+ executable_path: 浏览器路径,默认为默认路径
+ custom_argument: 自定义参数 用于webdriver.Chrome(options=chrome_options, **kwargs)
+ download_path: 文件下载保存路径;如果指定,不再出现“保留”“放弃”提示,仅对Chrome有效
+ auto_install_driver: 自动下载浏览器驱动 支持chrome 和 firefox
+ use_stealth_js: 使用stealth.min.js隐藏浏览器特征
+ **kwargs:
+ """
+ self._load_images = load_images
+ self._user_agent = user_agent or setting.DEFAULT_USERAGENT
+ self._proxy = proxy
+ self._headless = headless
+ self._timeout = timeout
+ self._window_size = window_size
+ self._executable_path = executable_path
+ self._custom_argument = custom_argument
+ self._download_path = download_path
+ self._auto_install_driver = auto_install_driver
+ self._use_stealth_js = use_stealth_js
+ self._driver_type = driver_type
+ self._kwargs = kwargs
+
+ @abc.abstractmethod
+ def quit(self):
+ pass
diff --git a/feapder/utils/webdriver/webdriver_pool.py b/feapder/utils/webdriver/webdriver_pool.py
new file mode 100644
index 00000000..c9ecc5a9
--- /dev/null
+++ b/feapder/utils/webdriver/webdriver_pool.py
@@ -0,0 +1,115 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2021/3/18 4:59 下午
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import queue
+import threading
+
+from feapder.utils.log import log
+from feapder.utils.tools import Singleton
+from feapder.utils.webdriver.selenium_driver import SeleniumDriver
+
+
+@Singleton
+class WebDriverPool:
+ def __init__(
+ self, pool_size=5, driver_cls=SeleniumDriver, thread_safe=False, **kwargs
+ ):
+ """
+
+ Args:
+ pool_size: driver池的大小
+ driver: 驱动类型
+ thread_safe: 是否线程安全
+ 是则每个线程拥有一个driver,pool_size无效,driver数量为线程数
+ 否则每个线程从池中获取driver
+ **kwargs:
+ """
+ self.pool_size = pool_size
+ self.driver_cls = driver_cls
+ self.thread_safe = thread_safe
+ self.kwargs = kwargs
+
+ self.queue = queue.Queue(maxsize=pool_size)
+ self.lock = threading.RLock()
+ self.driver_count = 0
+ self.ctx = threading.local()
+
+ @property
+ def driver(self):
+ if not hasattr(self.ctx, "driver"):
+ self.ctx.driver = None
+ return self.ctx.driver
+
+ @driver.setter
+ def driver(self, driver):
+ self.ctx.driver = driver
+
+ @property
+ def is_full(self):
+ return self.driver_count >= self.pool_size
+
+ def create_driver(self, user_agent: str = None, proxy: str = None):
+ kwargs = self.kwargs.copy()
+ if user_agent:
+ kwargs["user_agent"] = user_agent
+ if proxy:
+ kwargs["proxy"] = proxy
+ return self.driver_cls(**kwargs)
+
+ def get(self, user_agent: str = None, proxy: str = None):
+ """
+ 获取webdriver
+ 当webdriver为新实例时会使用 user_agen, proxy, cookie参数来创建
+ Args:
+ user_agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36
+ proxy: xxx.xxx.xxx.xxx
+ Returns:
+
+ """
+ if not self.is_full and not self.thread_safe:
+ with self.lock:
+ if not self.is_full:
+ driver = self.create_driver(user_agent, proxy)
+ self.queue.put(driver)
+ self.driver_count += 1
+ elif self.thread_safe:
+ if not self.driver:
+ driver = self.create_driver(user_agent, proxy)
+ self.driver = driver
+ self.driver_count += 1
+
+ if self.thread_safe:
+ driver = self.driver
+ else:
+ driver = self.queue.get()
+
+ return driver
+
+ def put(self, driver):
+ if not self.thread_safe:
+ self.queue.put(driver)
+
+ def remove(self, driver):
+ if self.thread_safe:
+ if self.driver:
+ self.driver.quit()
+ self.driver = None
+ else:
+ driver.quit()
+ self.driver_count -= 1
+
+ def close(self):
+ if self.thread_safe:
+ log.info("暂不支持关闭需线程安全的driver")
+
+ while not self.queue.empty():
+ driver = self.queue.get()
+ driver.quit()
+ self.driver_count -= 1
diff --git a/setup.py b/setup.py
index a6dbd8bb..cf4fe542 100644
--- a/setup.py
+++ b/setup.py
@@ -16,10 +16,10 @@
if version_info < (3, 6, 0):
raise SystemExit("Sorry! feapder requires python 3.6.0 or later.")
-with open(join(dirname(__file__), "feapder/VERSION"), "rb") as f:
- version = f.read().decode("ascii").strip()
+with open(join(dirname(__file__), "feapder/VERSION"), "rb") as fh:
+ version = fh.read().decode("ascii").strip()
-with open("README.md", "r") as fh:
+with open("README.md", "r", encoding="utf8") as fh:
long_description = fh.read()
packages = setuptools.find_packages()
@@ -37,25 +37,31 @@
"better-exceptions>=0.2.2",
"DBUtils>=2.0",
"parsel>=1.5.2",
- "PyExecJS>=1.5.1",
"PyMySQL>=0.9.3",
"redis>=2.10.6,<4.0.0",
"requests>=2.22.0",
"bs4>=0.0.1",
"ipython>=7.14.0",
- "redis-py-cluster>=2.1.0",
"cryptography>=3.3.2",
- "selenium>=3.141.0",
- "pymongo>=3.10.1",
"urllib3>=1.25.8",
"loguru>=0.5.3",
"influxdb>=5.3.1",
"pyperclip>=1.8.2",
- "webdriver-manager>=3.5.3",
+ "terminal-layout>=2.1.3",
+]
+
+render_requires = [
+ "webdriver-manager>=4.0.0",
+ "playwright",
+ "selenium>=3.141.0",
]
-memory_dedup_requires = ["bitarray>=1.5.3"]
-all_requires = memory_dedup_requires
+all_requires = [
+ "bitarray>=1.5.3",
+ "PyExecJS>=1.5.1",
+ "pymongo>=3.10.1",
+ "redis-py-cluster>=2.1.0",
+] + render_requires
setuptools.setup(
name="feapder",
@@ -64,11 +70,11 @@
license="MIT",
author_email="feapder@qq.com",
python_requires=">=3.6",
- description="feapder是一款支持分布式、批次采集、任务防丢、报警丰富的python爬虫框架",
+ description="feapder是一款支持分布式、批次采集、数据防丢、报警丰富的python爬虫框架",
long_description=long_description,
long_description_content_type="text/markdown",
install_requires=requires,
- extras_require={"all": all_requires},
+ extras_require={"all": all_requires, "render": render_requires},
entry_points={"console_scripts": ["feapder = feapder.commands.cmdline:execute"]},
url="https://github.com/Boris-code/feapder.git",
packages=packages,
diff --git a/tests/air-spider/qiushibaike_spider.py b/tests/air-spider/qiushibaike_spider.py
deleted file mode 100644
index 06c6caba..00000000
--- a/tests/air-spider/qiushibaike_spider.py
+++ /dev/null
@@ -1,39 +0,0 @@
-import feapder
-
-
-class QiushibaikeSpider(feapder.AirSpider):
- def start_requests(self):
- for i in range(1, 15):
- yield feapder.Request("https://www.qiushibaike.com/8hr/page/{}/".format(i))
-
- def parse(self, request, response):
- article_list = response.xpath('//a[@class="recmd-content"]')
- for article in article_list:
- title = article.xpath("./text()").extract_first()
- url = article.xpath("./@href").extract_first()
-
- yield feapder.Request(
- url, callback=self.parse_detail, title=title
- ) # callback 为回调函数
-
- def parse_detail(self, request, response):
- """
- 解析详情
- """
- response.encoding_errors = "ignore"
- # 取url
- url = request.url
- # 取title
- title = request.title
- # 解析正文
- content = response.xpath(
- 'string(//div[@class="content"])'
- ).extract_first() # string 表达式是取某个标签下的文本,包括子标签文本
-
- print("url", url)
- print("title", title)
- print("content", content)
-
-
-if __name__ == "__main__":
- QiushibaikeSpider(thread_count=50).start()
diff --git a/tests/air-spider/test_air_spider.py b/tests/air-spider/test_air_spider.py
index 51dcd1f5..597bfe48 100644
--- a/tests/air-spider/test_air_spider.py
+++ b/tests/air-spider/test_air_spider.py
@@ -12,9 +12,10 @@
class TestAirSpider(feapder.AirSpider):
- # __custom_setting__ = dict(
- # LOG_LEVEL = "INFO"
- # )
+ __custom_setting__ = dict(
+ USE_SESSION=True,
+ TASK_MAX_CACHED_SIZE=10,
+ )
def start_callback(self):
print("爬虫开始")
@@ -23,7 +24,9 @@ def end_callback(self):
print("爬虫结束")
def start_requests(self, *args, **kws):
- yield feapder.Request("https://www.baidu.com")
+ for i in range(1):
+ print(i)
+ yield feapder.Request("https://www.baidu.com")
def download_midware(self, request):
# request.headers = {'User-Agent': ""}
@@ -33,16 +36,15 @@ def download_midware(self, request):
def validate(self, request, response):
if response.status_code != 200:
- raise Exception("response code not 200") # 重试
+ raise Exception("response code not 200") # 重试
# if "哈哈" not in response.text:
# return False # 抛弃当前请求
-
def parse(self, request, response):
print(response.bs4().title)
print(response.xpath("//title").extract_first())
if __name__ == "__main__":
- TestAirSpider().start()
+ TestAirSpider(thread_count=1).start()
diff --git a/tests/air-spider/test_air_spider_filter.py b/tests/air-spider/test_air_spider_filter.py
new file mode 100644
index 00000000..a57065d2
--- /dev/null
+++ b/tests/air-spider/test_air_spider_filter.py
@@ -0,0 +1,35 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2020/4/22 10:41 PM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import feapder
+
+
+class TestAirSpider(feapder.AirSpider):
+ __custom_setting__ = dict(
+ REQUEST_FILTER_ENABLE=True, # request 去重
+ # REQUEST_FILTER_SETTING=dict(
+ # filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4
+ # expire_time=2592000, # 过期时间1个月
+ # ),
+ REQUEST_FILTER_SETTING=dict(
+ filter_type=4, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4
+ ),
+ )
+
+ def start_requests(self, *args, **kws):
+ for i in range(200):
+ yield feapder.Request("https://www.baidu.com")
+
+ def parse(self, request, response):
+ print(response.bs4().title)
+
+
+if __name__ == "__main__":
+ TestAirSpider(thread_count=1).start()
diff --git a/tests/air-spider/test_air_spider_item.py b/tests/air-spider/test_air_spider_item.py
index fbdaabcb..cd61ed6e 100644
--- a/tests/air-spider/test_air_spider_item.py
+++ b/tests/air-spider/test_air_spider_item.py
@@ -18,6 +18,10 @@ class TestAirSpiderItem(feapder.AirSpider):
MYSQL_DB="feapder",
MYSQL_USER_NAME="feapder",
MYSQL_USER_PASS="feapder123",
+ ITEM_FILTER_ENABLE=True, # item 去重
+ ITEM_FILTER_SETTING = dict(
+ filter_type=4 # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4
+ )
)
def start_requests(self):
@@ -25,11 +29,12 @@ def start_requests(self):
def parse(self, request, response):
title = response.xpath("string(//title)").extract_first()
- item = Item()
- item.table_name = "spider_data"
- item.url = request.url
- item.title = title
- yield item
+ for i in range(3):
+ item = Item()
+ item.table_name = "spider_data"
+ item.url = request.url
+ item.title = title
+ yield item
if __name__ == "__main__":
diff --git a/tests/air-spider/test_render_spider.py b/tests/air-spider/test_render_spider.py
new file mode 100644
index 00000000..3067a443
--- /dev/null
+++ b/tests/air-spider/test_render_spider.py
@@ -0,0 +1,29 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2020/4/22 10:41 PM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import feapder
+
+
+class TestAirSpider(feapder.AirSpider):
+ def start_requests(self, *args, **kws):
+ yield feapder.Request("https://www.baidu.com", render=True)
+
+ # def download_midware(self, request):
+ # request.proxies = {
+ # "http": "http://xxx.xxx.xxx.xxx:8888",
+ # "https": "http://xxx.xxx.xxx.xxx:8888",
+ # }
+
+ def parse(self, request, response):
+ print(response.bs4().title)
+
+
+if __name__ == "__main__":
+ TestAirSpider(thread_count=1).start()
diff --git a/tests/batch-spider/main.py b/tests/batch-spider/main.py
index 78c23056..cf7e858e 100644
--- a/tests/batch-spider/main.py
+++ b/tests/batch-spider/main.py
@@ -13,7 +13,7 @@
def crawl_test(args):
spider = test_spider.TestSpider(
- redis_key="feapder:test_batch_spider", # redis中存放任务等信息的根key
+ redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置
task_table="batch_spider_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
@@ -30,7 +30,7 @@ def crawl_test(args):
def test_debug():
spider = test_spider.TestSpider.to_DebugBatchSpider(
task_id=1,
- redis_key="feapder:test_batch_spider", # redis中存放任务等信息的根key
+ redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置
task_table="batch_spider_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
diff --git a/tests/batch-spider/spiders/test_spider.py b/tests/batch-spider/spiders/test_spider.py
index bc213e78..684961bb 100644
--- a/tests/batch-spider/spiders/test_spider.py
+++ b/tests/batch-spider/spiders/test_spider.py
@@ -18,7 +18,7 @@ class TestSpider(feapder.BatchSpider):
def start_requests(self, task):
# task 为在任务表中取出的每一条任务
id, url = task # id, url为所取的字段,main函数中指定的
- yield feapder.Request(url, task_id=id)
+ yield feapder.Request(url, task_id=id, render=True) # task_id为任务id,用于更新任务状态
def parse(self, request, response):
title = response.xpath('//title/text()').extract_first() # 取标题
diff --git a/tests/spider/main.py b/tests/spider/main.py
index f91728dc..80bbe762 100644
--- a/tests/spider/main.py
+++ b/tests/spider/main.py
@@ -10,5 +10,5 @@
from spiders import *
if __name__ == "__main__":
- spider = test_spider.TestSpider(redis_key="feapder3:test_spider", thread_count=1)
+ spider = test_spider.TestSpider(redis_key="feapder3:test_spider", thread_count=100, keep_alive=False)
spider.start()
\ No newline at end of file
diff --git a/tests/spider/setting.py b/tests/spider/setting.py
index 9730bb67..75470361 100644
--- a/tests/spider/setting.py
+++ b/tests/spider/setting.py
@@ -22,8 +22,8 @@
COLLECTOR_TASK_COUNT = 100 # 每次获取任务数量
#
# # SPIDER
-SPIDER_THREAD_COUNT = 1 # 爬虫并发数
-# SPIDER_SLEEP_TIME = 0 # 下载时间间隔(解析完一个response后休眠时间)
+SPIDER_THREAD_COUNT = 100 # 爬虫并发数
+SPIDER_SLEEP_TIME = 0 # 下载时间间隔(解析完一个response后休眠时间)
# SPIDER_MAX_RETRY_TIMES = 100 # 每个请求最大重试次数
# # 重新尝试失败的requests 当requests重试次数超过允许的最大重试次数算失败
@@ -67,3 +67,11 @@
# LOG_LEVEL = "DEBUG"
# LOG_IS_WRITE_TO_FILE = False
# OTHERS_LOG_LEVAL = "ERROR" # 第三方库的log等级
+REQUEST_FILTER_ENABLE=True # request 去重
+# REQUEST_FILTER_SETTING=dict(
+# filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4
+# expire_time=2592000, # 过期时间1个月
+# ),
+REQUEST_FILTER_SETTING=dict(
+ filter_type=4, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4
+)
\ No newline at end of file
diff --git a/tests/task-spider/test_task_spider.py b/tests/task-spider/test_task_spider.py
new file mode 100644
index 00000000..3a361633
--- /dev/null
+++ b/tests/task-spider/test_task_spider.py
@@ -0,0 +1,80 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022-06-10 14:30:54
+---------
+@summary:
+---------
+@author: Boris
+"""
+
+import feapder
+from feapder import ArgumentParser
+
+
+class TestTaskSpider(feapder.TaskSpider):
+ def add_task(self):
+ # 加种子任务 框架会调用这个函数,方便往redis里塞任务,但不能写成死循环。实际业务中可以自己写个脚本往redis里塞任务
+ self._redisdb.zadd(self._task_table, {"id": 1, "url": "https://www.baidu.com"})
+
+ def start_requests(self, task):
+ task_id, url = task
+ yield feapder.Request(url, task_id=task_id)
+
+ def parse(self, request, response):
+ # 提取网站title
+ print(response.xpath("//title/text()").extract_first())
+ # 提取网站描述
+ print(response.xpath("//meta[@name='description']/@content").extract_first())
+ print("网站地址: ", response.url)
+
+ # mysql 需要更新任务状态为做完 即 state=1
+ # yield self.update_task_batch(request.task_id)
+
+
+def start(args):
+ """
+ 用mysql做种子表
+ """
+ spider = TestTaskSpider(
+ task_table="spider_task",
+ task_keys=["id", "url"],
+ redis_key="test:task_spider",
+ keep_alive=True,
+ )
+ if args == 1:
+ spider.start_monitor_task()
+ else:
+ spider.start()
+
+
+def start2(args):
+ """
+ 用redis做种子表
+ """
+ spider = TestTaskSpider(
+ task_table="spider_task2",
+ task_table_type="redis",
+ redis_key="test:task_spider",
+ keep_alive=True,
+ use_mysql=False,
+ )
+ if args == 1:
+ spider.start_monitor_task()
+ else:
+ spider.start()
+
+
+if __name__ == "__main__":
+ parser = ArgumentParser(description="测试TaskSpider")
+
+ parser.add_argument(
+ "--start", type=int, nargs=1, help="用mysql做种子表 (1|2)", function=start
+ )
+ parser.add_argument(
+ "--start2", type=int, nargs=1, help="用redis做种子表 (1|2)", function=start2
+ )
+
+ parser.start()
+
+ # 下发任务 python3 test_task_spider.py --start 1
+ # 采集 python3 test_task_spider.py --start 2
diff --git a/tests/test-debugger/README.md b/tests/test-debugger/README.md
new file mode 100644
index 00000000..c160ae2c
--- /dev/null
+++ b/tests/test-debugger/README.md
@@ -0,0 +1,8 @@
+# xxx爬虫文档
+## 调研
+
+## 数据库设计
+
+## 爬虫逻辑
+
+## 项目架构
\ No newline at end of file
diff --git a/tests/test-debugger/items/__init__.py b/tests/test-debugger/items/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/tests/test-debugger/main.py b/tests/test-debugger/main.py
new file mode 100644
index 00000000..929f347b
--- /dev/null
+++ b/tests/test-debugger/main.py
@@ -0,0 +1,19 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2023-06-09 20:26:29
+---------
+@summary: 爬虫入口
+---------
+@author: Boris
+"""
+
+import feapder
+
+from spiders import *
+
+
+if __name__ == "__main__":
+ test_debugger.TestDebugger.to_DebugSpider(
+ request=feapder.Request("https://spidertools.cn", render=True),
+ redis_key="test:xxx",
+ ).start()
diff --git a/tests/test-debugger/setting.py b/tests/test-debugger/setting.py
new file mode 100644
index 00000000..2191f57c
--- /dev/null
+++ b/tests/test-debugger/setting.py
@@ -0,0 +1,185 @@
+# -*- coding: utf-8 -*-
+"""爬虫配置文件"""
+# import os
+# import sys
+#
+# # MYSQL
+# MYSQL_IP = "localhost"
+# MYSQL_PORT = 3306
+# MYSQL_DB = ""
+# MYSQL_USER_NAME = ""
+# MYSQL_USER_PASS = ""
+#
+# # MONGODB
+# MONGO_IP = "localhost"
+# MONGO_PORT = 27017
+# MONGO_DB = ""
+# MONGO_USER_NAME = ""
+# MONGO_USER_PASS = ""
+#
+# # REDIS
+# # ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"]
+# REDISDB_IP_PORTS = "localhost:6379"
+# REDISDB_USER_PASS = ""
+# REDISDB_DB = 0
+# # 连接redis时携带的其他参数,如ssl=True
+# REDISDB_KWARGS = dict()
+# # 适用于redis哨兵模式
+# REDISDB_SERVICE_NAME = ""
+#
+# # 数据入库的pipeline,可自定义,默认MysqlPipeline
+# ITEM_PIPELINES = [
+# "feapder.pipelines.mysql_pipeline.MysqlPipeline",
+# # "feapder.pipelines.mongo_pipeline.MongoPipeline",
+# # "feapder.pipelines.console_pipeline.ConsolePipeline",
+# ]
+# EXPORT_DATA_MAX_FAILED_TIMES = 10 # 导出数据时最大的失败次数,包括保存和更新,超过这个次数报警
+# EXPORT_DATA_MAX_RETRY_TIMES = 10 # 导出数据时最大的重试次数,包括保存和更新,超过这个次数则放弃重试
+#
+# # 爬虫相关
+# # COLLECTOR
+# COLLECTOR_TASK_COUNT = 32 # 每次获取任务数量,追求速度推荐32
+#
+# # SPIDER
+# SPIDER_THREAD_COUNT = 1 # 爬虫并发数,追求速度推荐32
+# # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
+# SPIDER_SLEEP_TIME = 0
+# SPIDER_MAX_RETRY_TIMES = 10 # 每个请求最大重试次数
+# KEEP_ALIVE = False # 爬虫是否常驻
+
+# 下载
+# DOWNLOADER = "feapder.network.downloader.RequestsDownloader"
+# SESSION_DOWNLOADER = "feapder.network.downloader.RequestsSessionDownloader"
+# RENDER_DOWNLOADER = "feapder.network.downloader.SeleniumDownloader"
+# # RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader"
+# MAKE_ABSOLUTE_LINKS = True # 自动转成绝对连接
+
+# # 浏览器渲染
+WEBDRIVER = dict(
+ pool_size=1, # 浏览器的数量
+ load_images=True, # 是否加载图片
+ user_agent=None, # 字符串 或 无参函数,返回值为user_agent
+ proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+ headless=False, # 是否为无头浏览器
+ driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
+ timeout=30, # 请求超时时间
+ window_size=(1024, 800), # 窗口大小
+ executable_path=None, # 浏览器路径,默认为默认路径
+ render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
+ custom_argument=[
+ "--ignore-certificate-errors",
+ "--disable-blink-features=AutomationControlled",
+ ], # 自定义浏览器渲染参数
+ xhr_url_regexes=None, # 拦截xhr接口,支持正则,数组类型
+ auto_install_driver=True, # 自动下载浏览器驱动 支持chrome 和 firefox
+ download_path=None, # 下载文件的路径
+ use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+)
+
+# PLAYWRIGHT = dict(
+# user_agent=None, # 字符串 或 无参函数,返回值为user_agent
+# proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+# headless=False, # 是否为无头浏览器
+# driver_type="chromium", # chromium、firefox、webkit
+# timeout=30, # 请求超时时间
+# window_size=(1024, 800), # 窗口大小
+# executable_path=None, # 浏览器路径,默认为默认路径
+# download_path=None, # 下载文件的路径
+# render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
+# wait_until="networkidle", # 等待页面加载完成的事件,可选值:"commit", "domcontentloaded", "load", "networkidle"
+# use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+# page_on_event_callback=None, # page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()}
+# storage_state_path=None, # 保存浏览器状态的路径
+# url_regexes=None, # 拦截接口,支持正则,数组类型
+# save_all=False, # 是否保存所有拦截的接口, 配合url_regexes使用,为False时只保存最后一次拦截的接口
+# )
+#
+# # 爬虫启动时,重新抓取失败的requests
+# RETRY_FAILED_REQUESTS = False
+# # 爬虫启动时,重新入库失败的item
+# RETRY_FAILED_ITEMS = False
+# # 保存失败的request
+# SAVE_FAILED_REQUEST = True
+# # request防丢机制。(指定的REQUEST_LOST_TIMEOUT时间内request还没做完,会重新下发 重做)
+# REQUEST_LOST_TIMEOUT = 600 # 10分钟
+# # request网络请求超时时间
+# REQUEST_TIMEOUT = 22 # 等待服务器响应的超时时间,浮点数,或(connect timeout, read timeout)元组
+# # item在内存队列中最大缓存数量
+# ITEM_MAX_CACHED_COUNT = 5000
+# # item每批入库的最大数量
+# ITEM_UPLOAD_BATCH_MAX_SIZE = 1000
+# # item入库时间间隔
+# ITEM_UPLOAD_INTERVAL = 1
+# # 内存任务队列最大缓存的任务数,默认不限制;仅对AirSpider有效。
+# TASK_MAX_CACHED_SIZE = 0
+#
+# # 下载缓存 利用redis缓存,但由于内存大小限制,所以建议仅供开发调试代码时使用,防止每次debug都需要网络请求
+# RESPONSE_CACHED_ENABLE = False # 是否启用下载缓存 成本高的数据或容易变需求的数据,建议设置为True
+# RESPONSE_CACHED_EXPIRE_TIME = 3600 # 缓存时间 秒
+# RESPONSE_CACHED_USED = False # 是否使用缓存 补采数据时可设置为True
+#
+# # 设置代理
+# PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n
+# PROXY_ENABLE = True
+#
+# # 随机headers
+# RANDOM_HEADERS = True
+# # UserAgent类型 支持 'chrome', 'opera', 'firefox', 'internetexplorer', 'safari','mobile' 若不指定则随机类型
+# USER_AGENT_TYPE = "chrome"
+# # 默认使用的浏览器头
+# DEFAULT_USERAGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
+# # requests 使用session
+# USE_SESSION = False
+#
+# # 去重
+# ITEM_FILTER_ENABLE = False # item 去重
+# REQUEST_FILTER_ENABLE = False # request 去重
+# ITEM_FILTER_SETTING = dict(
+# filter_type=1 # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4
+# )
+# REQUEST_FILTER_SETTING = dict(
+# filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4
+# expire_time=2592000, # 过期时间1个月
+# )
+#
+# # 报警 支持钉钉、飞书、企业微信、邮件
+# # 钉钉报警
+# DINGDING_WARNING_URL = "" # 钉钉机器人api
+# DINGDING_WARNING_PHONE = "" # 报警人 支持列表,可指定多个
+# DINGDING_WARNING_ALL = False # 是否提示所有人, 默认为False
+# # 飞书报警
+# # https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN#e1cdee9f
+# FEISHU_WARNING_URL = "" # 飞书机器人api
+# FEISHU_WARNING_USER = None # 报警人 {"open_id":"ou_xxxxx", "name":"xxxx"} 或 [{"open_id":"ou_xxxxx", "name":"xxxx"}]
+# FEISHU_WARNING_ALL = False # 是否提示所有人, 默认为False
+# # 邮件报警
+# EMAIL_SENDER = "" # 发件人
+# EMAIL_PASSWORD = "" # 授权码
+# EMAIL_RECEIVER = "" # 收件人 支持列表,可指定多个
+# EMAIL_SMTPSERVER = "smtp.163.com" # 邮件服务器 默认为163邮箱
+# # 企业微信报警
+# WECHAT_WARNING_URL = "" # 企业微信机器人api
+# WECHAT_WARNING_PHONE = "" # 报警人 将会在群内@此人, 支持列表,可指定多人
+# WECHAT_WARNING_ALL = False # 是否提示所有人, 默认为False
+# # 时间间隔
+# WARNING_INTERVAL = 3600 # 相同报警的报警时间间隔,防止刷屏; 0表示不去重
+# WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / INFO / ERROR
+# WARNING_FAILED_COUNT = 1000 # 任务失败数 超过WARNING_FAILED_COUNT则报警
+#
+# LOG_NAME = os.path.basename(os.getcwd())
+# LOG_PATH = "log/%s.log" % LOG_NAME # log存储路径
+# LOG_LEVEL = "DEBUG"
+# LOG_COLOR = True # 是否带有颜色
+# LOG_IS_WRITE_TO_CONSOLE = True # 是否打印到控制台
+# LOG_IS_WRITE_TO_FILE = False # 是否写文件
+# LOG_MODE = "w" # 写文件的模式
+# LOG_MAX_BYTES = 10 * 1024 * 1024 # 每个日志文件的最大字节数
+# LOG_BACKUP_COUNT = 20 # 日志文件保留数量
+# LOG_ENCODING = "utf8" # 日志文件编码
+# OTHERS_LOG_LEVAL = "ERROR" # 第三方库的log等级
+#
+# # 切换工作路径为当前项目路径
+# project_path = os.path.abspath(os.path.dirname(__file__))
+# os.chdir(project_path) # 切换工作路经
+# sys.path.insert(0, project_path)
+# print("当前工作路径为 " + os.getcwd())
diff --git a/tests/test-debugger/spiders/__init__.py b/tests/test-debugger/spiders/__init__.py
new file mode 100644
index 00000000..4243fbe2
--- /dev/null
+++ b/tests/test-debugger/spiders/__init__.py
@@ -0,0 +1,3 @@
+__all__ = [
+ "test_debugger"
+]
\ No newline at end of file
diff --git a/tests/test-debugger/spiders/test_debugger.py b/tests/test-debugger/spiders/test_debugger.py
new file mode 100644
index 00000000..2ef73f56
--- /dev/null
+++ b/tests/test-debugger/spiders/test_debugger.py
@@ -0,0 +1,28 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2023-06-09 20:26:47
+---------
+@summary:
+---------
+@author: Boris
+"""
+
+import feapder
+
+
+class TestDebugger(feapder.Spider):
+ def start_requests(self):
+ yield feapder.Request("https://spidertools.cn", render=True)
+
+ def parse(self, request, response):
+ # 提取网站title
+ print(response.xpath("//title/text()").extract_first())
+ # 提取网站描述
+ print(response.xpath("//meta[@name='description']/@content").extract_first())
+ print("网站地址: ", response.url)
+
+
+if __name__ == "__main__":
+ TestDebugger.to_DebugSpider(
+ request=feapder.Request("https://spidertools.cn", render=True), redis_key="test:xxx"
+ ).start()
diff --git a/tests/test-pipeline/items/spider_data_item.py b/tests/test-pipeline/items/spider_data_item.py
index 3072d9a5..1960649a 100644
--- a/tests/test-pipeline/items/spider_data_item.py
+++ b/tests/test-pipeline/items/spider_data_item.py
@@ -8,6 +8,7 @@
"""
from feapder import Item
+from feapder.pipelines.csv_pipeline import CsvPipeline
class SpiderDataItem(Item):
@@ -15,6 +16,7 @@ class SpiderDataItem(Item):
This class was generated by feapder.
command: feapder create -i spider_data.
"""
+ __pipelines__ = [CsvPipeline()]
def __init__(self, *args, **kwargs):
# self.id = None # type : int(10) unsigned | allow_null : NO | key : PRI | default_value : None | extra : auto_increment | column_comment :
diff --git a/tests/test-pipeline/main.py b/tests/test-pipeline/main.py
index 4ab8b0fe..c6454dd9 100644
--- a/tests/test-pipeline/main.py
+++ b/tests/test-pipeline/main.py
@@ -13,7 +13,7 @@
def crawl_test(args):
spider = test_spider.TestSpider(
- redis_key="feapder:test_batch_spider", # redis中存放任务等信息的根key
+ redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置
task_table="batch_spider_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
diff --git a/tests/test-pipeline/setting.py b/tests/test-pipeline/setting.py
index ca852ad4..ba985f09 100644
--- a/tests/test-pipeline/setting.py
+++ b/tests/test-pipeline/setting.py
@@ -19,7 +19,8 @@
# 数据入库的pipeline,可自定义,默认MysqlPipeline
ITEM_PIPELINES = [
- "pipeline.Pipeline"
+ "pipeline.Pipeline",
+ # "feapder.pipelines.csv_pipeline.CsvPipeline"
]
# # 爬虫相关
diff --git a/tests/test-pipeline/spiders/test_csv_pipeline_spider.py b/tests/test-pipeline/spiders/test_csv_pipeline_spider.py
new file mode 100644
index 00000000..83d4b842
--- /dev/null
+++ b/tests/test-pipeline/spiders/test_csv_pipeline_spider.py
@@ -0,0 +1,28 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2025-12-16 14:52:29
+---------
+@summary:
+---------
+@author: Boris
+"""
+
+import feapder
+from items import *
+
+
+class TestCsvPipelineSpider(feapder.AirSpider):
+ def start_requests(self):
+ for i in range(100):
+ yield feapder.Request("https://baidu.com", page=i)
+
+ def parse(self, request, response):
+ # 提取网站title
+ title = response.xpath("//title/text()").extract_first()
+ item = spider_data_item.SpiderDataItem() # 声明一个item
+ item.title = title # 给item属性赋值
+ yield item # 返回item, item会自动批量入库
+
+
+if __name__ == "__main__":
+ TestCsvPipelineSpider().start()
diff --git a/tests/test_csv_pipeline/test_functionality.py b/tests/test_csv_pipeline/test_functionality.py
new file mode 100644
index 00000000..190c9137
--- /dev/null
+++ b/tests/test_csv_pipeline/test_functionality.py
@@ -0,0 +1,454 @@
+# -*- coding: utf-8 -*-
+"""
+CSV Pipeline 功能测试
+
+测试内容:
+1. 基础功能测试
+2. 异常处理测试
+3. 边界条件测试
+4. 兼容性测试
+
+Created on 2025-10-16
+@author: 道长
+@email: ctrlf4@yeah.net
+"""
+
+import csv
+import os
+import sys
+import shutil
+from pathlib import Path
+
+# 添加项目路径
+sys.path.insert(0, str(Path(__file__).parent.parent.parent))
+
+from feapder.pipelines.csv_pipeline import CsvPipeline
+
+
+class FunctionalityTester:
+ """CSV Pipeline 功能测试器"""
+
+ def __init__(self, test_dir="test_output"):
+ """初始化测试器"""
+ self.test_dir = test_dir
+ self.pipeline = None
+ self.passed = 0
+ self.failed = 0
+
+ def setup(self):
+ """测试前准备"""
+ if os.path.exists(self.test_dir):
+ shutil.rmtree(self.test_dir)
+
+ os.makedirs(self.test_dir, exist_ok=True)
+
+ csv_dir = os.path.join(self.test_dir, "csv")
+ self.pipeline = CsvPipeline(csv_dir=csv_dir)
+
+ print(f"✅ 测试环境准备完成")
+
+ def teardown(self):
+ """测试后清理"""
+ if self.pipeline:
+ self.pipeline.close()
+
+ def assert_true(self, condition, message):
+ """断言真"""
+ if condition:
+ print(f" ✅ {message}")
+ self.passed += 1
+ else:
+ print(f" ❌ {message}")
+ self.failed += 1
+
+ def assert_false(self, condition, message):
+ """断言假"""
+ self.assert_true(not condition, message)
+
+ def assert_equal(self, actual, expected, message):
+ """断言相等"""
+ if actual == expected:
+ print(f" ✅ {message}")
+ self.passed += 1
+ else:
+ print(f" ❌ {message} (期望: {expected}, 实际: {actual})")
+ self.failed += 1
+
+ def test_basic_save(self):
+ """测试基础保存功能"""
+ print("\n" + "=" * 80)
+ print("测试 1: 基础保存功能")
+ print("=" * 80)
+
+ # 测试保存单条数据
+ item = {"id": 1, "name": "Test Product", "price": 99.99}
+ result = self.pipeline.save_items("product", [item])
+ self.assert_true(result, "保存单条数据")
+
+ # 检查文件是否创建
+ csv_file = os.path.join(self.pipeline.csv_dir, "product.csv")
+ self.assert_true(os.path.exists(csv_file), "CSV 文件已创建")
+
+ # 检查数据是否正确
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ rows = list(reader)
+ self.assert_equal(len(rows), 1, "文件中有 1 条数据")
+ if rows:
+ self.assert_equal(rows[0]["id"], "1", "数据 ID 正确")
+ self.assert_equal(rows[0]["name"], "Test Product", "数据名称正确")
+
+ def test_batch_save(self):
+ """测试批量保存"""
+ print("\n" + "=" * 80)
+ print("测试 2: 批量保存功能")
+ print("=" * 80)
+
+ # 生成测试数据
+ items = []
+ for i in range(10):
+ items.append({
+ "id": i + 1,
+ "name": f"Product_{i + 1}",
+ "price": 100 + i,
+ })
+
+ result = self.pipeline.save_items("batch_test", items)
+ self.assert_true(result, "批量保存 10 条数据")
+
+ # 检查数据行数
+ csv_file = os.path.join(self.pipeline.csv_dir, "batch_test.csv")
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ rows = list(reader)
+ self.assert_equal(len(rows), 10, "批量保存数据行数正确")
+
+ def test_empty_items(self):
+ """测试空数据处理"""
+ print("\n" + "=" * 80)
+ print("测试 3: 空数据处理")
+ print("=" * 80)
+
+ result = self.pipeline.save_items("empty_test", [])
+ self.assert_true(result, "空数据列表返回 True")
+
+ def test_special_characters(self):
+ """测试特殊字符处理"""
+ print("\n" + "=" * 80)
+ print("测试 4: 特殊字符处理")
+ print("=" * 80)
+
+ items = [
+ {
+ "id": 1,
+ "name": "产品名称",
+ "description": 'Contains "quotes" and, commas',
+ "emoji": "😀🎉🚀",
+ "newline": "Line1\nLine2",
+ }
+ ]
+
+ result = self.pipeline.save_items("special_chars", items)
+ self.assert_true(result, "保存包含特殊字符的数据")
+
+ # 读取并检查
+ csv_file = os.path.join(self.pipeline.csv_dir, "special_chars.csv")
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ rows = list(reader)
+ if rows:
+ self.assert_equal(rows[0]["name"], "产品名称", "中文字符正确")
+ self.assert_equal(
+ rows[0].get("emoji", ""),
+ "😀🎉🚀",
+ "Emoji 正确"
+ )
+
+ def test_multiple_tables(self):
+ """测试多表存储"""
+ print("\n" + "=" * 80)
+ print("测试 5: 多表存储")
+ print("=" * 80)
+
+ tables = ["product", "user", "order"]
+ for table in tables:
+ item = {"id": 1, "name": f"Test {table}"}
+ result = self.pipeline.save_items(table, [item])
+ self.assert_true(result, f"保存到表 {table}")
+
+ # 检查所有文件
+ for table in tables:
+ csv_file = os.path.join(self.pipeline.csv_dir, f"{table}.csv")
+ self.assert_true(os.path.exists(csv_file), f"表 {table} 的 CSV 文件存在")
+
+ def test_header_only_once(self):
+ """测试表头只写一次"""
+ print("\n" + "=" * 80)
+ print("测试 6: 表头只写一次")
+ print("=" * 80)
+
+ table = "header_test"
+
+ # 第一次写入
+ items1 = [{"id": 1, "name": "Product 1"}]
+ self.pipeline.save_items(table, items1)
+
+ # 第二次写入
+ items2 = [{"id": 2, "name": "Product 2"}]
+ self.pipeline.save_items(table, items2)
+
+ # 检查表头行数
+ csv_file = os.path.join(self.pipeline.csv_dir, f"{table}.csv")
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ lines = f.readlines()
+ # 应该是:1 个表头 + 2 条数据
+ self.assert_equal(len(lines), 3, "文件中只有 1 行表头和 2 行数据")
+
+ def test_numeric_values(self):
+ """测试数值类型"""
+ print("\n" + "=" * 80)
+ print("测试 7: 数值类型处理")
+ print("=" * 80)
+
+ items = [
+ {
+ "id": 1,
+ "price": 99.99,
+ "stock": 100,
+ "rating": 4.5,
+ "active": True,
+ }
+ ]
+
+ result = self.pipeline.save_items("numeric_test", items)
+ self.assert_true(result, "保存包含各类数值的数据")
+
+ # 读取并检查
+ csv_file = os.path.join(self.pipeline.csv_dir, "numeric_test.csv")
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ rows = list(reader)
+ if rows:
+ self.assert_equal(rows[0]["price"], "99.99", "浮点数正确")
+ self.assert_equal(rows[0]["stock"], "100", "整数正确")
+ self.assert_equal(rows[0]["rating"], "4.5", "小数正确")
+
+ def test_large_values(self):
+ """测试大值处理"""
+ print("\n" + "=" * 80)
+ print("测试 8: 大值处理")
+ print("=" * 80)
+
+ large_text = "x" * 10000 # 10KB 的文本
+ items = [
+ {
+ "id": 1,
+ "name": "Large Content",
+ "content": large_text,
+ }
+ ]
+
+ result = self.pipeline.save_items("large_test", items)
+ self.assert_true(result, "保存大内容数据")
+
+ # 检查数据完整性
+ csv_file = os.path.join(self.pipeline.csv_dir, "large_test.csv")
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ rows = list(reader)
+ if rows:
+ self.assert_equal(
+ len(rows[0]["content"]),
+ len(large_text),
+ "大内容数据完整"
+ )
+
+ def test_update_items_fallback(self):
+ """测试 update_items 降级为 save"""
+ print("\n" + "=" * 80)
+ print("测试 9: update_items 降级为 save")
+ print("=" * 80)
+
+ items = [{"id": 1, "name": "Product 1", "price": 100}]
+ result = self.pipeline.update_items("update_test", items, ("price",))
+ self.assert_true(result, "update_items 返回 True")
+
+ # 检查数据是否存在
+ csv_file = os.path.join(self.pipeline.csv_dir, "update_test.csv")
+ self.assert_true(os.path.exists(csv_file), "update_items 创建了 CSV 文件")
+
+ def test_file_operations(self):
+ """测试文件操作"""
+ print("\n" + "=" * 80)
+ print("测试 10: 文件操作")
+ print("=" * 80)
+
+ items = [{"id": 1, "name": "Test"}]
+ table = "file_test"
+
+ result = self.pipeline.save_items(table, items)
+ self.assert_true(result, "保存数据")
+
+ csv_file = os.path.join(self.pipeline.csv_dir, f"{table}.csv")
+
+ # 检查文件是否可读
+ try:
+ with open(csv_file, 'r', encoding='utf-8') as f:
+ f.read()
+ self.assert_true(True, "CSV 文件可读")
+ except Exception as e:
+ self.assert_true(False, f"CSV 文件可读 ({e})")
+
+ # 检查文件大小
+ file_size = os.path.getsize(csv_file)
+ self.assert_true(file_size > 0, f"CSV 文件大小 > 0 ({file_size} 字节)")
+
+ def test_concurrent_same_table(self):
+ """测试同表并发写入"""
+ print("\n" + "=" * 80)
+ print("测试 11: 同表并发写入(Per-Table Lock)")
+ print("=" * 80)
+
+ import threading
+
+ table = "concurrent_same_table"
+ errors = []
+
+ def write_data(thread_id):
+ try:
+ items = [{"id": thread_id, "name": f"Item_{thread_id}"}]
+ result = self.pipeline.save_items(table, items)
+ if not result:
+ errors.append(f"线程{thread_id}写入失败")
+ except Exception as e:
+ errors.append(f"线程{thread_id}异常: {e}")
+
+ # 创建多个线程
+ threads = []
+ for i in range(5):
+ t = threading.Thread(target=write_data, args=(i,))
+ t.start()
+ threads.append(t)
+
+ # 等待所有线程完成
+ for t in threads:
+ t.join()
+
+ self.assert_equal(len(errors), 0, "并发写入无错误")
+
+ # 检查数据完整性
+ csv_file = os.path.join(self.pipeline.csv_dir, f"{table}.csv")
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ rows = list(reader)
+ self.assert_true(len(rows) > 0, "并发写入产生了数据")
+
+ def test_directory_creation(self):
+ """测试目录自动创建"""
+ print("\n" + "=" * 80)
+ print("测试 12: 目录自动创建")
+ print("=" * 80)
+
+ # 创建新的 pipeline 实例,指定不存在的目录
+ new_csv_dir = os.path.join(self.test_dir, "new_csv_dir")
+ self.assert_false(os.path.exists(new_csv_dir), "新目录不存在")
+
+ new_pipeline = CsvPipeline(csv_dir=new_csv_dir)
+ self.assert_true(os.path.exists(new_csv_dir), "目录自动创建")
+
+ new_pipeline.close()
+
+ def test_none_values(self):
+ """测试 None 值处理"""
+ print("\n" + "=" * 80)
+ print("测试 13: None 值处理")
+ print("=" * 80)
+
+ items = [
+ {
+ "id": 1,
+ "name": "Product",
+ "description": None,
+ "optional_field": "",
+ }
+ ]
+
+ result = self.pipeline.save_items("none_test", items)
+ self.assert_true(result, "保存包含 None 值的数据")
+
+ # 检查文件
+ csv_file = os.path.join(self.pipeline.csv_dir, "none_test.csv")
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ rows = list(reader)
+ if rows:
+ # None 会被转换为字符串 "None"
+ self.assert_true("None" in rows[0]["description"],
+ "None 值被正确处理")
+
+ def run_all_tests(self):
+ """运行所有测试"""
+ print("\n")
+ print("╔" + "═" * 78 + "╗")
+ print("║" + " CSV Pipeline 功能测试 ".center(78) + "║")
+ print("║" + " 作者: 道长 | 日期: 2025-10-16 ".center(78) + "║")
+ print("╚" + "═" * 78 + "╝")
+
+ try:
+ self.setup()
+
+ # 运行所有测试
+ self.test_basic_save()
+ self.test_batch_save()
+ self.test_empty_items()
+ self.test_special_characters()
+ self.test_multiple_tables()
+ self.test_header_only_once()
+ self.test_numeric_values()
+ self.test_large_values()
+ self.test_update_items_fallback()
+ self.test_file_operations()
+ self.test_concurrent_same_table()
+ self.test_directory_creation()
+ self.test_none_values()
+
+ # 打印总结
+ self.print_summary()
+
+ return self.failed == 0
+
+ except Exception as e:
+ print(f"\n❌ 测试过程中出错: {e}")
+ import traceback
+ traceback.print_exc()
+ return False
+
+ finally:
+ self.teardown()
+
+ def print_summary(self):
+ """打印测试总结"""
+ print("\n" + "=" * 80)
+ print("测试总结")
+ print("=" * 80)
+ print(f"✅ 通过: {self.passed}")
+ print(f"❌ 失败: {self.failed}")
+ print(f"总计: {self.passed + self.failed}")
+
+ if self.failed == 0:
+ print("\n🎉 所有测试通过!")
+ else:
+ print(f"\n⚠️ 有 {self.failed} 个测试失败")
+
+ print("=" * 80)
+
+
+def main():
+ """主函数"""
+ tester = FunctionalityTester(test_dir="tests/test_csv_pipeline/test_output_func")
+ success = tester.run_all_tests()
+ return 0 if success else 1
+
+
+if __name__ == "__main__":
+ sys.exit(main())
diff --git a/tests/test_csv_pipeline/test_performance.py b/tests/test_csv_pipeline/test_performance.py
new file mode 100644
index 00000000..94eb64a7
--- /dev/null
+++ b/tests/test_csv_pipeline/test_performance.py
@@ -0,0 +1,537 @@
+# -*- coding: utf-8 -*-
+"""
+CSV Pipeline 性能测试
+
+测试内容:
+1. 批量写入性能
+2. 并发写入性能
+3. 内存占用情况
+4. 文件大小和数据完整性
+
+Created on 2025-10-16
+@author: 道长
+@email: ctrlf4@yeah.net
+"""
+
+import csv
+import os
+import sys
+import time
+import shutil
+import threading
+import psutil
+from pathlib import Path
+from typing import List, Dict
+
+# 添加项目路径
+sys.path.insert(0, str(Path(__file__).parent.parent.parent))
+
+from feapder.pipelines.csv_pipeline import CsvPipeline
+
+
+class PerformanceTester:
+ """CSV Pipeline 性能测试器"""
+
+ def __init__(self, test_dir="test_output"):
+ """初始化测试器"""
+ self.test_dir = test_dir
+ self.pipeline = None
+ self.process = psutil.Process()
+ self.test_results = {}
+
+ def setup(self):
+ """测试前准备"""
+ # 清理历史测试目录
+ if os.path.exists(self.test_dir):
+ shutil.rmtree(self.test_dir)
+
+ # 创建测试输出目录
+ os.makedirs(self.test_dir, exist_ok=True)
+
+ # 初始化 Pipeline
+ csv_dir = os.path.join(self.test_dir, "csv")
+ self.pipeline = CsvPipeline(csv_dir=csv_dir)
+
+ print(f"✅ 测试环境准备完成,输出目录: {self.test_dir}")
+
+ def teardown(self):
+ """测试后清理"""
+ if self.pipeline:
+ self.pipeline.close()
+
+ def generate_test_data(self, count: int) -> List[Dict]:
+ """生成测试数据"""
+ data = []
+ for i in range(count):
+ data.append({
+ "id": i + 1,
+ "name": f"Product_{i + 1}",
+ "price": 99.99 + i * 0.1,
+ "category": "Electronics",
+ "url": f"https://example.com/product/{i + 1}",
+ "stock": 100 - (i % 50),
+ "rating": 4.5 + (i % 5) * 0.1,
+ "description": f"Description for product {i + 1}" * 3,
+ })
+ return data
+
+ def test_single_batch_performance(self):
+ """测试单批写入性能"""
+ print("\n" + "=" * 80)
+ print("测试 1: 单批写入性能")
+ print("=" * 80)
+
+ batch_sizes = [100, 500, 1000, 5000]
+ results = {}
+
+ for batch_size in batch_sizes:
+ data = self.generate_test_data(batch_size)
+
+ # 测试写入时间
+ start_time = time.time()
+ success = self.pipeline.save_items("product", data)
+ elapsed = time.time() - start_time
+
+ # 测试结果
+ results[batch_size] = {
+ "success": success,
+ "elapsed_time": elapsed,
+ "throughput": batch_size / elapsed if elapsed > 0 else 0,
+ }
+
+ print(f"批量大小: {batch_size:5d} | "
+ f"耗时: {elapsed:.4f}s | "
+ f"吞吐量: {results[batch_size]['throughput']:.0f} 条/秒 | "
+ f"状态: {'✅' if success else '❌'}")
+
+ self.test_results["single_batch"] = results
+ return results
+
+ def test_concurrent_write_performance(self):
+ """测试并发写入性能"""
+ print("\n" + "=" * 80)
+ print("测试 2: 并发写入性能(模拟多爬虫线程)")
+ print("=" * 80)
+
+ thread_counts = [1, 2, 4, 8]
+ results = {}
+
+ for thread_count in thread_counts:
+ # 每个线程写入的数据条数
+ items_per_thread = 100
+ total_items = thread_count * items_per_thread
+
+ def write_thread(thread_id):
+ """线程工作函数"""
+ data = self.generate_test_data(items_per_thread)
+ # 为了模拟不同表,使用不同的表名
+ table_name = f"product_thread_{thread_id}"
+ return self.pipeline.save_items(table_name, data)
+
+ # 记录初始内存
+ mem_before = self.process.memory_info().rss / 1024 / 1024
+
+ # 并发执行
+ start_time = time.time()
+ threads = []
+ for i in range(thread_count):
+ t = threading.Thread(target=write_thread, args=(i,))
+ t.start()
+ threads.append(t)
+
+ # 等待所有线程完成
+ for t in threads:
+ t.join()
+
+ elapsed = time.time() - start_time
+ mem_after = self.process.memory_info().rss / 1024 / 1024
+ mem_delta = mem_after - mem_before
+
+ results[thread_count] = {
+ "total_items": total_items,
+ "elapsed_time": elapsed,
+ "throughput": total_items / elapsed if elapsed > 0 else 0,
+ "memory_delta_mb": mem_delta,
+ }
+
+ print(f"线程数: {thread_count} | "
+ f"总数据: {total_items:5d} | "
+ f"耗时: {elapsed:.4f}s | "
+ f"吞吐量: {results[thread_count]['throughput']:.0f} 条/秒 | "
+ f"内存增长: {mem_delta:.2f}MB")
+
+ self.test_results["concurrent_write"] = results
+ return results
+
+ def test_memory_usage(self):
+ """测试内存占用"""
+ print("\n" + "=" * 80)
+ print("测试 3: 内存占用情况")
+ print("=" * 80)
+
+ # 测试不同数量的数据对内存的影响
+ test_counts = [1000, 5000, 10000, 50000]
+ results = {}
+
+ for count in test_counts:
+ data = self.generate_test_data(count)
+
+ # 记录内存
+ mem_before = self.process.memory_info().rss / 1024 / 1024
+
+ # 执行写入
+ start_time = time.time()
+ self.pipeline.save_items("product_memory", data)
+ elapsed = time.time() - start_time
+
+ mem_after = self.process.memory_info().rss / 1024 / 1024
+ mem_used = mem_after - mem_before
+ mem_per_item = mem_used / count if count > 0 else 0
+
+ results[count] = {
+ "memory_before_mb": mem_before,
+ "memory_after_mb": mem_after,
+ "memory_used_mb": mem_used,
+ "memory_per_item_kb": mem_per_item * 1024,
+ "elapsed_time": elapsed,
+ }
+
+ print(f"数据条数: {count:6d} | "
+ f"内存占用: {mem_used:6.2f}MB | "
+ f"每条数据: {mem_per_item * 1024:.2f}KB | "
+ f"耗时: {elapsed:.4f}s")
+
+ self.test_results["memory_usage"] = results
+ return results
+
+ def test_file_integrity(self):
+ """测试文件完整性"""
+ print("\n" + "=" * 80)
+ print("测试 4: 文件完整性检查")
+ print("=" * 80)
+
+ # 写入测试数据
+ test_data = self.generate_test_data(1000)
+ table_name = "product_integrity"
+
+ success = self.pipeline.save_items(table_name, test_data)
+
+ if not success:
+ print("❌ 写入失败")
+ return {"status": "failed"}
+
+ # 检查文件是否存在
+ csv_file = os.path.join(self.pipeline.csv_dir, f"{table_name}.csv")
+ if not os.path.exists(csv_file):
+ print("❌ CSV 文件不存在")
+ return {"status": "file_not_found"}
+
+ # 读取 CSV 文件并检查数据完整性
+ read_data = []
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ for row in reader:
+ read_data.append(row)
+
+ # 对比数据
+ if len(read_data) != len(test_data):
+ print(f"❌ 数据条数不符: 写入{len(test_data)}条,读取{len(read_data)}条")
+ return {
+ "status": "count_mismatch",
+ "written": len(test_data),
+ "read": len(read_data),
+ }
+
+ # 检查字段是否完整
+ expected_fields = set(test_data[0].keys())
+ actual_fields = set(read_data[0].keys())
+ if expected_fields != actual_fields:
+ print(f"❌ 字段不符\n期望: {expected_fields}\n实际: {actual_fields}")
+ return {
+ "status": "field_mismatch",
+ "expected": list(expected_fields),
+ "actual": list(actual_fields),
+ }
+
+ # 检查数据值是否正确(抽样检查)
+ sample_indices = [0, len(test_data) // 2, len(test_data) - 1]
+ for idx in sample_indices:
+ original = test_data[idx]
+ read = read_data[idx]
+
+ for key in original.keys():
+ if str(original[key]) != read.get(key, ""):
+ print(f"❌ 数据不符 (第{idx}行, 字段{key})\n"
+ f"期望: {original[key]}\n"
+ f"实际: {read.get(key)}")
+ return {"status": "data_mismatch", "index": idx, "field": key}
+
+ print(f"✅ 文件完整性检查通过")
+ print(f" 总条数: {len(read_data)}")
+ print(f" 字段数: {len(actual_fields)}")
+ print(f" 文件大小: {os.path.getsize(csv_file) / 1024:.2f}KB")
+
+ return {
+ "status": "passed",
+ "total_rows": len(read_data),
+ "total_fields": len(actual_fields),
+ "file_size_kb": os.path.getsize(csv_file) / 1024,
+ }
+
+ def test_append_mode(self):
+ """测试追加模式(断点续爬)"""
+ print("\n" + "=" * 80)
+ print("测试 5: 追加模式(断点续爬)")
+ print("=" * 80)
+
+ table_name = "product_append"
+
+ # 第一次写入
+ data1 = self.generate_test_data(100)
+ self.pipeline.save_items(table_name, data1)
+
+ csv_file = os.path.join(self.pipeline.csv_dir, f"{table_name}.csv")
+ size_after_first = os.path.getsize(csv_file) if os.path.exists(csv_file) else 0
+
+ # 第二次写入(追加)
+ data2 = self.generate_test_data(100)
+ self.pipeline.save_items(table_name, data2)
+
+ size_after_second = os.path.getsize(csv_file) if os.path.exists(csv_file) else 0
+
+ # 读取文件检查数据
+ read_data = []
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ for row in reader:
+ read_data.append(row)
+
+ # 检查是否正确追加
+ if len(read_data) == len(data1) + len(data2):
+ print(f"✅ 追加模式正常")
+ print(f" 第一次写入: {len(data1)} 条")
+ print(f" 第二次写入: {len(data2)} 条")
+ print(f" 最终总数: {len(read_data)} 条")
+ print(f" 第一次后大小: {size_after_first / 1024:.2f}KB")
+ print(f" 第二次后大小: {size_after_second / 1024:.2f}KB")
+
+ return {
+ "status": "passed",
+ "first_write": len(data1),
+ "second_write": len(data2),
+ "total": len(read_data),
+ "size_growth_kb": (size_after_second - size_after_first) / 1024,
+ }
+ else:
+ print(f"❌ 追加模式异常: 期望{len(data1) + len(data2)}条,实际{len(read_data)}条")
+ return {
+ "status": "failed",
+ "expected": len(data1) + len(data2),
+ "actual": len(read_data),
+ }
+
+ def test_concurrent_safety(self):
+ """测试并发安全性(Per-Table Lock)"""
+ print("\n" + "=" * 80)
+ print("测试 6: 并发安全性(Per-Table Lock)")
+ print("=" * 80)
+
+ table_name = "product_concurrent_safety"
+ thread_count = 4
+ items_per_thread = 250
+
+ errors = []
+ lock = threading.Lock()
+
+ def write_thread(thread_id):
+ """线程工作函数"""
+ try:
+ data = self.generate_test_data(items_per_thread)
+ success = self.pipeline.save_items(table_name, data)
+ if not success:
+ with lock:
+ errors.append(f"线程{thread_id}写入失败")
+ except Exception as e:
+ with lock:
+ errors.append(f"线程{thread_id}异常: {e}")
+
+ # 并发执行
+ threads = []
+ start_time = time.time()
+ for i in range(thread_count):
+ t = threading.Thread(target=write_thread, args=(i,))
+ t.start()
+ threads.append(t)
+
+ for t in threads:
+ t.join()
+
+ elapsed = time.time() - start_time
+
+ # 检查文件
+ csv_file = os.path.join(self.pipeline.csv_dir, f"{table_name}.csv")
+ read_data = []
+ with open(csv_file, 'r', encoding='utf-8', newline='') as f:
+ reader = csv.DictReader(f)
+ for row in reader:
+ read_data.append(row)
+
+ expected_total = thread_count * items_per_thread
+
+ if len(errors) == 0 and len(read_data) == expected_total:
+ print(f"✅ 并发安全性测试通过")
+ print(f" 线程数: {thread_count}")
+ print(f" 每线程数据: {items_per_thread}")
+ print(f" 期望总数: {expected_total}")
+ print(f" 实际总数: {len(read_data)}")
+ print(f" 耗时: {elapsed:.4f}s")
+ print(f" 吞吐量: {expected_total / elapsed:.0f} 条/秒")
+
+ return {
+ "status": "passed",
+ "thread_count": thread_count,
+ "items_per_thread": items_per_thread,
+ "expected_total": expected_total,
+ "actual_total": len(read_data),
+ "elapsed_time": elapsed,
+ "throughput": expected_total / elapsed,
+ }
+ else:
+ print(f"❌ 并发安全性测试失败")
+ if errors:
+ for error in errors:
+ print(f" {error}")
+ if len(read_data) != expected_total:
+ print(f" 数据条数不符: 期望{expected_total}条,实际{len(read_data)}条")
+
+ return {
+ "status": "failed",
+ "errors": errors,
+ "expected_total": expected_total,
+ "actual_total": len(read_data),
+ }
+
+ def test_multiple_tables(self):
+ """测试多表存储"""
+ print("\n" + "=" * 80)
+ print("测试 7: 多表存储")
+ print("=" * 80)
+
+ tables = ["product", "user", "order"]
+ rows_per_table = 500
+ results = {}
+
+ start_time = time.time()
+
+ for table in tables:
+ data = self.generate_test_data(rows_per_table)
+ success = self.pipeline.save_items(table, data)
+
+ csv_file = os.path.join(self.pipeline.csv_dir, f"{table}.csv")
+ file_size = os.path.getsize(csv_file) / 1024 if os.path.exists(csv_file) else 0
+
+ results[table] = {
+ "success": success,
+ "file_size_kb": file_size,
+ }
+
+ print(f"表: {table:10s} | 状态: {'✅' if success else '❌'} | "
+ f"文件大小: {file_size:.2f}KB")
+
+ elapsed = time.time() - start_time
+
+ # 检查所有文件
+ csv_dir = self.pipeline.csv_dir
+ files = [f for f in os.listdir(csv_dir) if f.endswith('.csv')]
+
+ print(f"\n✅ 多表存储测试完成")
+ print(f" 表数: {len(tables)}")
+ print(f" 每表行数: {rows_per_table}")
+ print(f" 生成的 CSV 文件: {len(files)}")
+ print(f" 耗时: {elapsed:.4f}s")
+
+ return {
+ "status": "passed",
+ "tables": results,
+ "file_count": len(files),
+ "elapsed_time": elapsed,
+ }
+
+ def run_all_tests(self):
+ """运行所有测试"""
+ print("\n")
+ print("╔" + "═" * 78 + "╗")
+ print("║" + " CSV Pipeline 性能和功能测试 ".center(78) + "║")
+ print("║" + " 作者: 道长 | 日期: 2025-10-16 ".center(78) + "║")
+ print("╚" + "═" * 78 + "╝")
+
+ try:
+ self.setup()
+
+ # 运行所有测试
+ self.test_single_batch_performance()
+ self.test_concurrent_write_performance()
+ self.test_memory_usage()
+ self.test_file_integrity()
+ self.test_append_mode()
+ self.test_concurrent_safety()
+ self.test_multiple_tables()
+
+ # 打印总结
+ self.print_summary()
+
+ return True
+
+ except Exception as e:
+ print(f"\n❌ 测试过程中出错: {e}")
+ import traceback
+ traceback.print_exc()
+ return False
+
+ finally:
+ self.teardown()
+
+ def print_summary(self):
+ """打印测试总结"""
+ print("\n" + "=" * 80)
+ print("测试总结")
+ print("=" * 80)
+
+ # 单批性能总结
+ if "single_batch" in self.test_results:
+ print("\n1. 单批写入性能:")
+ results = self.test_results["single_batch"]
+ for batch_size, data in results.items():
+ print(f" {batch_size:5d} 条: {data['throughput']:.0f} 条/秒, "
+ f"耗时 {data['elapsed_time']:.4f}s")
+
+ # 并发性能总结
+ if "concurrent_write" in self.test_results:
+ print("\n2. 并发写入性能:")
+ results = self.test_results["concurrent_write"]
+ for thread_count, data in results.items():
+ print(f" {thread_count} 线程: {data['throughput']:.0f} 条/秒, "
+ f"内存增长 {data['memory_delta_mb']:.2f}MB")
+
+ # 内存占用总结
+ if "memory_usage" in self.test_results:
+ print("\n3. 内存占用情况:")
+ results = self.test_results["memory_usage"]
+ for count, data in results.items():
+ print(f" {count:6d} 条: {data['memory_used_mb']:.2f}MB, "
+ f"每条 {data['memory_per_item_kb']:.2f}KB")
+
+ print("\n" + "=" * 80)
+ print("✅ 所有测试完成!")
+ print("=" * 80)
+
+
+def main():
+ """主函数"""
+ tester = PerformanceTester(test_dir="tests/test_csv_pipeline/test_output")
+ success = tester.run_all_tests()
+ return 0 if success else 1
+
+
+if __name__ == "__main__":
+ sys.exit(main())
diff --git a/tests/test_dedup.py b/tests/test_dedup.py
index 943afd1a..84d4131f 100644
--- a/tests/test_dedup.py
+++ b/tests/test_dedup.py
@@ -1,56 +1,104 @@
-from feapder.dedup import Dedup
-
-data = {"xxx": 123, "xxxx": "xxxx"}
-
-datas = ["xxx", "bbb"]
-
-
-def test_MemoryFilter():
- dedup = Dedup(Dedup.MemoryFilter) # 表名为test 历史数据3秒有效期
-
- # 逐条去重
- assert dedup.add(data) == 1
- assert dedup.get(data) == 1
-
- # 批量去重
- assert dedup.add(datas) == [1, 1]
- assert dedup.get(datas) == [1, 1]
-
+import unittest
-def test_ExpireFilter():
- dedup = Dedup(
- Dedup.ExpireFilter, expire_time=10, redis_url="redis://@localhost:6379/0"
- )
+from redis import Redis
- # 逐条去重
- assert dedup.add(data) == 1
- assert dedup.get(data) == 1
-
- # 批量去重
- assert dedup.add(datas) == [1, 1]
- assert dedup.get(datas) == [1, 1]
-
-
-def test_BloomFilter():
- dedup = Dedup(Dedup.BloomFilter, redis_url="redis://@localhost:6379/0")
-
- # 逐条去重
- assert dedup.add(data) == 1
- assert dedup.get(data) == 1
-
- # 批量去重
- assert dedup.add(datas) == [1, 1]
- assert dedup.get(datas) == [1, 1]
-
-
-def test_filter():
- dedup = Dedup(Dedup.BloomFilter, redis_url="redis://@localhost:6379/0")
+from feapder.dedup import Dedup
- # 制造已存在数据
- datas = ["xxx", "bbb"]
- dedup.add(datas)
- # 过滤掉已存在数据 "xxx", "bbb"
- datas = ["xxx", "bbb", "ccc"]
- dedup.filter_exist_data(datas)
- assert datas == ["ccc"]
+class TestDedup(unittest.TestCase):
+ def clear(self):
+ self.absolute_name = "test_dedup"
+ redis = Redis.from_url("redis://@localhost:6379/0", decode_responses=True)
+ keys = redis.keys(self.absolute_name + "*")
+ if keys:
+ redis.delete(*keys)
+
+ def setUp(self) -> None:
+ self.clear()
+ self.mock_data()
+
+ def tearDown(self) -> None:
+ self.clear()
+
+ def mock_data(self):
+ self.data = {"xxx": 123, "xxxx": "xxxx"}
+ self.datas = ["xxx", "bbb", "xxx"]
+
+ def test_MemoryFilter(self):
+ dedup = Dedup(
+ Dedup.MemoryFilter, absolute_name=self.absolute_name
+ ) # 表名为test 历史数据3秒有效期
+
+ # 逐条去重
+ self.assertEqual(dedup.add(self.data), 1)
+ self.assertEqual(dedup.get(self.data), 1)
+
+ # 批量去重
+ self.assertEqual(dedup.get(self.datas), [0, 0, 1])
+ self.assertEqual(dedup.add(self.datas), [1, 1, 0])
+ self.assertEqual(dedup.get(self.datas), [1, 1, 1])
+
+ def test_ExpireFilter(self):
+ dedup = Dedup(
+ Dedup.ExpireFilter,
+ expire_time=10,
+ redis_url="redis://@localhost:6379/0",
+ absolute_name=self.absolute_name,
+ )
+
+ # 逐条去重
+ self.assertEqual(dedup.add(self.data), 1)
+ self.assertEqual(dedup.get(self.data), 1)
+
+ # 批量去重
+ self.assertEqual(dedup.get(self.datas), [0, 0, 1])
+ self.assertEqual(dedup.add(self.datas), [1, 1, 0])
+ self.assertEqual(dedup.get(self.datas), [1, 1, 1])
+
+ def test_BloomFilter(self):
+ dedup = Dedup(
+ Dedup.BloomFilter,
+ redis_url="redis://@localhost:6379/0",
+ absolute_name=self.absolute_name,
+ )
+
+ # 逐条去重
+ self.assertEqual(dedup.add(self.data), 1)
+ self.assertEqual(dedup.get(self.data), 1)
+
+ # 批量去重
+ self.assertEqual(dedup.get(self.datas), [0, 0, 1])
+ self.assertEqual(dedup.add(self.datas), [1, 1, 0])
+ self.assertEqual(dedup.get(self.datas), [1, 1, 1])
+
+ def test_LiteFilter(self):
+ dedup = Dedup(
+ Dedup.LiteFilter,
+ )
+
+ # 逐条去重
+ self.assertEqual(dedup.add(self.data), 1)
+ self.assertEqual(dedup.get(self.data), 1)
+
+ # 批量去重
+ self.assertEqual(dedup.get(self.datas), [0, 0, 1])
+ self.assertEqual(dedup.add(self.datas), [1, 1, 0])
+ self.assertEqual(dedup.get(self.datas), [1, 1, 1])
+
+ def test_filter(self):
+ dedup = Dedup(
+ Dedup.BloomFilter,
+ redis_url="redis://@localhost:6379/0",
+ to_md5=True,
+ absolute_name=self.absolute_name,
+ )
+
+ # 制造已存在数据
+ self.datas = ["xxx", "bbb"]
+ result = dedup.add(self.datas)
+ self.assertEqual(result, [1, 1])
+
+ # 过滤掉已存在数据 "xxx", "bbb"
+ self.datas = ["xxx", "bbb", "ccc"]
+ dedup.filter_exist_data(self.datas)
+ self.assertEqual(self.datas, ["ccc"])
diff --git a/tests/test_download_midware.py b/tests/test_download_midware.py
new file mode 100644
index 00000000..1accbaf7
--- /dev/null
+++ b/tests/test_download_midware.py
@@ -0,0 +1,45 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2023/9/21 13:59
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import feapder
+
+
+def download_midware(request):
+ print("outter download_midware")
+ return request
+
+
+class TestAirSpider(feapder.AirSpider):
+ def start_requests(self):
+ yield feapder.Request(
+ "https://www.baidu.com", download_midware=download_midware
+ )
+
+ def parse(self, request, response):
+ print(request, response)
+
+
+class TestSpiderSpider(feapder.Spider):
+ def start_requests(self):
+ yield feapder.Request(
+ "https://www.baidu.com", download_midware=[download_midware, self.download_midware]
+ )
+
+ def download_midware(self, request):
+ print("class download_midware")
+ return request
+
+ def parse(self, request, response):
+ print(request, response)
+
+
+if __name__ == "__main__":
+ # TestAirSpider().start()
+ TestSpiderSpider(redis_key="test").start()
diff --git a/tests/test_log.py b/tests/test_log.py
index 3ec0ac31..c044a238 100644
--- a/tests/test_log.py
+++ b/tests/test_log.py
@@ -10,4 +10,10 @@
from feapder.utils.log import log
-log.debug(1)
\ No newline at end of file
+log.debug("debug")
+log.info("info")
+log.success("success")
+log.warning("warning")
+log.error("error")
+log.critical("critical")
+log.exception("exception")
\ No newline at end of file
diff --git a/tests/test_metrics.py b/tests/test_metrics.py
index f058a973..308c2711 100644
--- a/tests/test_metrics.py
+++ b/tests/test_metrics.py
@@ -1,8 +1,52 @@
+import asyncio
+
from feapder.utils import metrics
# 初始化打点系统
-metrics.init()
+metrics.init(
+ influxdb_host="localhost",
+ influxdb_port="8086",
+ influxdb_udp_port="8089",
+ influxdb_database="feapder",
+ influxdb_user="***",
+ influxdb_password="***",
+ influxdb_measurement="test_metrics",
+ debug=True,
+)
+
+
+async def test_counter_async():
+ for i in range(100):
+ await metrics.aemit_counter("total count", count=100, classify="test5")
+ for j in range(100):
+ await metrics.aemit_counter("key", count=1, classify="test5")
+
+
+def test_counter():
+ for i in range(100):
+ metrics.emit_counter("total count", count=100, classify="test5")
+ for j in range(100):
+ metrics.emit_counter("key", count=1, classify="test5")
+
+
+def test_store():
+ metrics.emit_store("total", 100, classify="cookie_count")
+
+
+def test_time():
+ metrics.emit_timer("total", 100, classify="time")
+
+
+def test_any():
+ metrics.emit_any(
+ tags={"_key": "total", "_type": "any"}, fields={"_value": 100}, classify="time"
+ )
-metrics.emit_counter("key", count=1, classify="test")
-metrics.close()
+if __name__ == "__main__":
+ asyncio.run(test_counter_async())
+ test_counter_async()
+ test_store()
+ test_time()
+ test_any()
+ metrics.close()
diff --git a/tests/test_mysqldb.py b/tests/test_mysqldb.py
index 7d59ce70..1fdd9c09 100644
--- a/tests/test_mysqldb.py
+++ b/tests/test_mysqldb.py
@@ -2,7 +2,10 @@
db = MysqlDB(
- ip="localhost", port=3306, db="feapder", user_name="feapder", user_pass="feapder123"
+ ip="localhost", port=3306, db="feapder", user_name="feapder", user_pass="feapder123", set_session=["SET time_zone='+08:00'"]
)
-MysqlDB.from_url("mysql://feapder:feapder123@localhost:3306/feapder?charset=utf8mb4")
\ No newline at end of file
+MysqlDB.from_url("mysql://feapder:feapder123@localhost:3306/feapder?charset=utf8mb4")
+
+result = db.find("SELECT @@global.time_zone, @@session.time_zone, date_format(NOW(), '%Y-%m-%d %H:%i:%s')")
+print(f"Database timezone info: {result}")
\ No newline at end of file
diff --git a/tests/test_playwright.py b/tests/test_playwright.py
new file mode 100644
index 00000000..91668c9e
--- /dev/null
+++ b/tests/test_playwright.py
@@ -0,0 +1,43 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/9/15 8:47 PM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+import time
+
+from playwright.sync_api import Page
+
+import feapder
+from feapder.utils.webdriver import PlaywrightDriver
+
+
+class TestPlaywright(feapder.AirSpider):
+ __custom_setting__ = dict(
+ RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader",
+ )
+
+ def start_requests(self):
+ yield feapder.Request("https://www.baidu.com", render=True)
+
+ def parse(self, reqeust, response):
+ driver: PlaywrightDriver = response.driver
+ page: Page = driver.page
+
+ page.type("#kw", "feapder")
+ page.click("#su")
+ page.wait_for_load_state("networkidle")
+ time.sleep(1)
+
+ html = page.content()
+ response.text = html # 使response加载最新的页面
+ for data_container in response.xpath("//div[@class='c-container']"):
+ print(data_container.xpath("string(.//h3)").extract_first())
+
+
+if __name__ == "__main__":
+ TestPlaywright(thread_count=1).run()
diff --git a/tests/test_playwright2.py b/tests/test_playwright2.py
new file mode 100644
index 00000000..fefeb897
--- /dev/null
+++ b/tests/test_playwright2.py
@@ -0,0 +1,92 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022/9/15 8:47 PM
+---------
+@summary:
+---------
+@author: Boris
+@email: boris_liu@foxmail.com
+"""
+
+from playwright.sync_api import Response
+from feapder.utils.webdriver import (
+ PlaywrightDriver,
+ InterceptResponse,
+ InterceptRequest,
+)
+
+import feapder
+
+
+def on_response(response: Response):
+ print(response.url)
+
+
+class TestPlaywright(feapder.AirSpider):
+ __custom_setting__ = dict(
+ RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader",
+ PLAYWRIGHT=dict(
+ user_agent=None, # 字符串 或 无参函数,返回值为user_agent
+ proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
+ headless=False, # 是否为无头浏览器
+ driver_type="chromium", # chromium、firefox、webkit
+ timeout=30, # 请求超时时间
+ window_size=(1024, 800), # 窗口大小
+ executable_path=None, # 浏览器路径,默认为默认路径
+ download_path=None, # 下载文件的路径
+ render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
+ wait_until="networkidle", # 等待页面加载完成的事件,可选值:"commit", "domcontentloaded", "load", "networkidle"
+ use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
+ # page_on_event_callback=dict(response=on_response), # 监听response事件
+ # page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()}
+ storage_state_path=None, # 保存浏览器状态的路径
+ url_regexes=["wallpaper/list"], # 拦截接口,支持正则,数组类型
+ save_all=True, # 是否保存所有拦截的接口
+ ),
+ )
+
+ def start_requests(self):
+ yield feapder.Request(
+ "http://www.soutushenqi.com/image/search/?searchWord=%E6%A0%91%E5%8F%B6",
+ render=True,
+ )
+
+ def parse(self, reqeust, response):
+ driver: PlaywrightDriver = response.driver
+
+ intercept_response: InterceptResponse = driver.get_response("wallpaper/list")
+ intercept_request: InterceptRequest = intercept_response.request
+
+ req_url = intercept_request.url
+ req_header = intercept_request.headers
+ req_data = intercept_request.data
+ print("请求url", req_url)
+ print("请求header", req_header)
+ print("请求data", req_data)
+
+ data = driver.get_json("wallpaper/list")
+ print("接口返回的数据", data)
+
+ print("------ 测试save_all=True ------- ")
+
+ # 测试save_all=True
+ all_intercept_response: list = driver.get_all_response("wallpaper/list")
+ for intercept_response in all_intercept_response:
+ intercept_request: InterceptRequest = intercept_response.request
+ req_url = intercept_request.url
+ req_header = intercept_request.headers
+ req_data = intercept_request.data
+ print("请求url", req_url)
+ print("请求header", req_header)
+ print("请求data", req_data)
+
+ all_intercept_json = driver.get_all_json("wallpaper/list")
+ for intercept_json in all_intercept_json:
+ print("接口返回的数据", intercept_json)
+
+ # 千万别忘了
+ driver.clear_cache()
+
+
+if __name__ == "__main__":
+ TestPlaywright(thread_count=1).run()
diff --git a/tests/test_proxies_pool.py b/tests/test_proxies_pool.py
deleted file mode 100644
index 5c63758e..00000000
--- a/tests/test_proxies_pool.py
+++ /dev/null
@@ -1,39 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-Created on 2021/4/3 4:25 下午
----------
-@summary:
----------
-@author: Boris
-@email: boris_liu@foxmail.com
-"""
-from feapder.network.proxy_pool import ProxyPool, check_proxy
-import requests
-
-url = "http://tunnel-api.apeyun.com/h?id=2020120800184471713&secret=3U1fEJPuabi3y2QJ&limit=10&format=txt&auth_mode=auto"
-
-proxy_pool = ProxyPool(size=-1, proxy_source_url=url)
-
-print(proxy_pool.get())
-#
-# headers = {
-# "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
-# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
-# "Accept-Encoding": "gzip, deflate, br",
-# "Accept-Language": "zh-CN,zh;q=0.9",
-# "Connection": "keep-alive",
-# }
-#
-#
-# resp = requests.get(
-# "http://www.baidu.com",
-# headers=headers,
-# proxies={
-# "https": "https://182.106.136.67:13586",
-# "http": "http://182.106.136.67:13586",
-# },
-# )
-# print(resp.text)
-#
-# a = check_proxy("182.106.136.67", "13586", show_error_log=True, type=1)
-# print(a)
diff --git a/tests/test_rander.py b/tests/test_rander.py
index 6516a7ac..12bdab09 100644
--- a/tests/test_rander.py
+++ b/tests/test_rander.py
@@ -4,7 +4,7 @@
class XueQiuSpider(feapder.AirSpider):
def start_requests(self):
for i in range(10):
- yield feapder.Request("https://news.qq.com/#{}".format(i), render=True)
+ yield feapder.Request("https://baidu.com/#{}".format(i), render=True)
def parse(self, request, response):
print(response.cookies.get_dict())
@@ -19,4 +19,4 @@ def parse(self, request, response):
if __name__ == "__main__":
- XueQiuSpider(thread_count=10).start()
+ XueQiuSpider(thread_count=1).start()
diff --git a/tests/test_rander_xhr.py b/tests/test_rander_xhr.py
index 534e5c57..15fe2da8 100644
--- a/tests/test_rander_xhr.py
+++ b/tests/test_rander_xhr.py
@@ -12,7 +12,7 @@ class TestRender(feapder.AirSpider):
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
- driver_type="CHROME", # CHROME、PHANTOMJS、FIREFOX
+ driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
diff --git a/tests/test_request.py b/tests/test_request.py
index 890c4742..15626457 100644
--- a/tests/test_request.py
+++ b/tests/test_request.py
@@ -8,17 +8,39 @@
@email: boris_liu@foxmail.com
"""
-from feapder import Request
-
-request = Request("https://www.baidu.com?a=1&b=2", data={}, params=None)
-response = request.get_response()
-print(response)
+from feapder import Request, Response
def test_selector():
+ request = Request("https://www.baidu.com?a=1&b=2", data={}, params=None)
+ response = request.get_response()
+ print(response)
+
print(response.xpath("//a/@href"))
print(response.css("a::attr(href)"))
print(response.css("a::attr(href)").extract_first())
content = response.re("
+
+
+
+
+
+
+
+
+ """
+
+ resp = Response.from_text(text=text, url="http://feapder.com/#/README")
+ print(resp.text)
+ print(resp)
+ print(resp.xpath("//script"))
+
+def test_to_dict():
+ request = Request("https://www.baidu.com?a=1&b=2", data={"a":1}, params="k=1", callback="test", task_id=1, cookies={"a":1})
+ print(request.to_dict)
\ No newline at end of file
diff --git a/tests/test_task.py b/tests/test_task.py
index 00399ea0..1b92c0af 100644
--- a/tests/test_task.py
+++ b/tests/test_task.py
@@ -13,10 +13,10 @@
task_key = ["id", "url"]
task = [1, "http://www.badu.com"]
-task = Task(_dict=dict(zip(task_key, task)), _values=task)
+task = PerfectDict(_dict=dict(zip(task_key, task)), _values=task)
-task = Task(id=1, url="http://www.badu.com")
-task = Task({"id":"1", "url":"http://www.badu.com"})
+task = PerfectDict(id=1, url="http://www.badu.com")
+task = PerfectDict({"id":"1", "url":"http://www.badu.com"})
print(task)
id, url = task
diff --git a/tests/test_template/test_spider.py b/tests/test_template/test_spider.py
new file mode 100644
index 00000000..c46136d8
--- /dev/null
+++ b/tests/test_template/test_spider.py
@@ -0,0 +1,79 @@
+# -*- coding: utf-8 -*-
+"""
+Created on 2022-08-04 17:58:45
+---------
+@summary:
+---------
+@author: Boris
+"""
+
+import feapder
+from feapder import ArgumentParser
+
+
+class TestSpider(feapder.TaskSpider):
+ # 自定义数据库,若项目中有setting.py文件,此自定义可删除
+ __custom_setting__ = dict(
+ REDISDB_IP_PORTS="localhost:6379",
+ REDISDB_USER_PASS="",
+ REDISDB_DB=0,
+ MYSQL_IP="localhost",
+ MYSQL_PORT=3306,
+ MYSQL_DB="",
+ MYSQL_USER_NAME="",
+ MYSQL_USER_PASS="",
+ )
+
+ def start_requests(self, task):
+ task_id = task.id
+ url = task.url
+ yield feapder.Request(url, task_id=task_id)
+
+ def parse(self, request, response):
+ # 提取网站title
+ print(response.xpath("//title/text()").extract_first())
+ # 提取网站描述
+ print(response.xpath("//meta[@name='description']/@content").extract_first())
+ print("网站地址: ", response.url)
+
+ # mysql 需要更新任务状态为做完 即 state=1
+ yield self.update_task_batch(request.task_id)
+
+
+if __name__ == "__main__":
+ # 用mysql做任务表,需要先建好任务任务表
+ spider = TestSpider(
+ redis_key="xxx:xxx", # 分布式爬虫调度信息存储位置
+ task_table="", # mysql中的任务表
+ task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
+ task_state="state", # mysql中任务状态字段
+ )
+
+ # 用redis做任务表
+ # spider = TestSpider(
+ # redis_key="xxx:xxxx", # 分布式爬虫调度信息存储位置
+ # task_table="", # 任务表名
+ # task_table_type="redis", # 任务表类型为redis
+ # )
+
+ parser = ArgumentParser(description="TestSpider爬虫")
+
+ parser.add_argument(
+ "--start_master",
+ action="store_true",
+ help="添加任务",
+ function=spider.start_monitor_task,
+ )
+ parser.add_argument(
+ "--start_worker", action="store_true", help="启动爬虫", function=spider.start
+ )
+
+ parser.start()
+
+ # 直接启动
+ # spider.start() # 启动爬虫
+ # spider.start_monitor_task() # 添加任务
+
+ # 通过命令行启动
+ # python test_spider.py --start_master # 添加任务
+ # python test_spider.py --start_worker # 启动爬虫
\ No newline at end of file